DART: Difficulty-Adaptive Routing for Zero-Shot Video Temporal Grounding
Pith reviewed 2026-07-02 14:24 UTC · model grok-4.3
The pith
Difficulty-adaptive routing via query-conditioned DPP bridges the reasoning gap in zero-shot video temporal grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
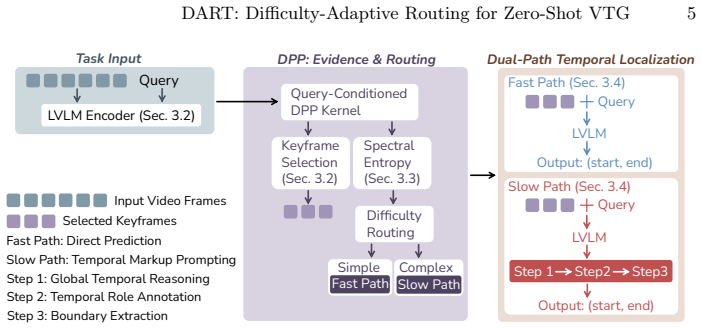
DART couples a query-conditioned Determinantal Point Process for keyframe selection and spectral-entropy difficulty measurement with a routing decision that sends simple queries to direct prediction and complex queries to Temporal Markup Prompting, producing state-of-the-art zero-shot mIoU on standard benchmarks while using over seven times fewer frames.
What carries the argument
Query-conditioned Determinantal Point Process (DPP) that both selects diverse query-relevant keyframes and supplies spectral entropy to decide Fast versus Slow routing, with the Slow path using Temporal Markup Prompting.
If this is right
- Complex multi-stage queries receive explicit decomposition into global event analysis, per-frame temporal role annotation, and boundary extraction.
- Overall frame processing drops by a factor greater than seven relative to non-routed baselines.
- Performance gains hold across both identically distributed and multiple out-of-distribution test settings on Charades-STA and ActivityNet Captions.
Where Pith is reading between the lines
- The same entropy-driven routing could be tested on other video-language tasks whose queries vary in temporal complexity.
- Replacing the DPP with a cheaper diversity or uncertainty estimator might preserve most gains at lower overhead.
- Applying the slow-path markup prompting to non-routed baselines would isolate how much of the reported lift comes from the prompting alone.
Load-bearing premise
Spectral entropy from the DPP correctly measures query difficulty and the routing decision actually improves performance on the queries it flags as hard.
What would settle it
A set of queries pre-labeled by humans for complexity where the DPP entropy shows no correlation with the labels or where routing high-entropy queries to the fast path produces equal or higher accuracy than the slow path.
Figures

read the original abstract
Zero-shot video temporal grounding (VTG) localizes events in untrimmed videos from natural language queries without task-specific training. Existing methods rely on frame-query feature matching, which suffices for simple events but struggles with complex multi-stage queries that require understanding temporal ordering and causal structure -- a disparity we call the reasoning gap. We propose DART (Difficulty-Adaptive Routing for Temporal Grounding), which bridges this gap by coupling difficulty-aware routing with structured reasoning in large vision-language models. A query-conditioned Determinantal Point Process (DPP) serves a dual role: selecting diverse, query-relevant keyframes as temporal evidence, and providing spectral entropy as a difficulty indicator. Simple queries are routed to a Fast path for direct prediction, while complex queries follow a Slow path with Temporal Markup Prompting, which decomposes localization into global event analysis, per-frame temporal role annotation, and boundary extraction. On Charades-STA and ActivityNet Captions, DART achieves state-of-the-art zero-shot performance across both identically distributed and multiple out-of-distribution settings, improving mIoU by up to 3.5 points over the strongest baseline while using over 7 times fewer frames. The project homepage is available at https://dart-vtg.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DART for zero-shot video temporal grounding. It uses a query-conditioned Determinantal Point Process (DPP) both to select diverse query-relevant keyframes and to compute spectral entropy as a difficulty indicator. Simple queries are routed to a Fast path for direct prediction while complex queries are routed to a Slow path that applies Temporal Markup Prompting (global event analysis, per-frame temporal role annotation, boundary extraction) inside a VLM. The method is claimed to achieve state-of-the-art zero-shot results on Charades-STA and ActivityNet Captions under both in-distribution and out-of-distribution settings, with up to 3.5 mIoU gain over the strongest baseline while using over 7 times fewer frames.
Significance. If the adaptive routing mechanism is shown to correctly identify queries that require multi-stage temporal/causal reasoning and the prompting step demonstrably closes the reasoning gap, the work would provide a practical way to allocate expensive VLM reasoning only where needed, improving both accuracy and efficiency in zero-shot VTG. The dual use of DPP for keyframe selection and difficulty measurement is a compact design choice that could be reusable.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the reported 3.5 mIoU gain and 7× frame reduction are presented without any description of the exact baselines, number of runs, statistical significance tests, or how the entropy threshold for routing is chosen or tuned; these omissions make it impossible to determine whether the gains are attributable to the difficulty-adaptive routing or to other factors.
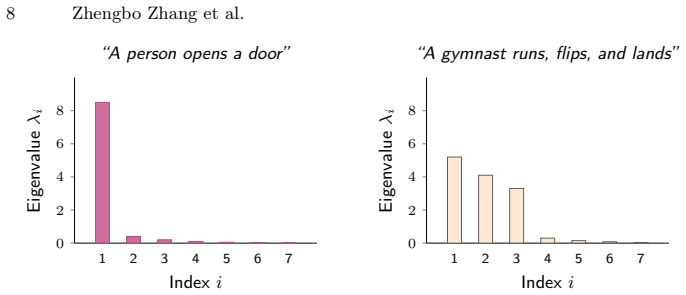
- [§3.2] §3.2 (Difficulty-Aware Routing): no quantitative evidence is supplied that spectral entropy of the query-conditioned DPP correlates with query complexity (e.g., number of temporal stages, relation density, or causal depth); without such validation the routing decision remains ungrounded and the central claim that the Slow path “bridges the reasoning gap” cannot be evaluated.
- [§4.3] §4.3 (Ablations): the manuscript contains no ablation that compares the full adaptive routing against (a) fixed Fast-path only, (b) fixed Slow-path only, or (c) random routing on the same DPP-selected keyframes; therefore it is impossible to isolate the contribution of the entropy-based routing decision from the effects of keyframe diversity or prompting alone.
minor comments (2)
- [§3.1] Notation for the DPP kernel and the precise definition of spectral entropy should be stated explicitly (currently only referenced in passing).
- [Abstract] The project page URL is given but no supplementary material or code is referenced; adding a pointer to released code or prompts would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental transparency and validation. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results and the grounding of the routing mechanism.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported 3.5 mIoU gain and 7× frame reduction are presented without any description of the exact baselines, number of runs, statistical significance tests, or how the entropy threshold for routing is chosen or tuned; these omissions make it impossible to determine whether the gains are attributable to the difficulty-adaptive routing or to other factors.
Authors: We agree that these details are necessary for reproducibility and attribution of gains. In the revised manuscript we will expand both the abstract and §4 to list the precise baselines (including model variants and prompting configurations), report mean performance and standard deviation across three independent runs, include statistical significance tests (paired t-tests with p-values), and describe the entropy threshold selection (determined on a held-out validation split to balance mIoU and frame usage). revision: yes
-
Referee: [§3.2] §3.2 (Difficulty-Aware Routing): no quantitative evidence is supplied that spectral entropy of the query-conditioned DPP correlates with query complexity (e.g., number of temporal stages, relation density, or causal depth); without such validation the routing decision remains ungrounded and the central claim that the Slow path “bridges the reasoning gap” cannot be evaluated.
Authors: We concur that explicit validation of the entropy-difficulty correlation is required. We will add a new analysis subsection (or appendix) presenting quantitative evidence, including Pearson/Spearman correlations and scatter plots between spectral entropy and query complexity annotations (number of temporal stages, relation density, causal depth) computed on a representative sample of queries from both datasets. revision: yes
-
Referee: [§4.3] §4.3 (Ablations): the manuscript contains no ablation that compares the full adaptive routing against (a) fixed Fast-path only, (b) fixed Slow-path only, or (c) random routing on the same DPP-selected keyframes; therefore it is impossible to isolate the contribution of the entropy-based routing decision from the effects of keyframe diversity or prompting alone.
Authors: We acknowledge the absence of these isolating ablations. In the revised §4.3 we will add the requested comparisons: full adaptive DART versus (a) fixed Fast-path, (b) fixed Slow-path, and (c) random routing, all using identical DPP-selected keyframes, with results reported on Charades-STA and ActivityNet Captions. revision: yes
Circularity Check
No significant circularity; derivation is self-contained algorithmic proposal
full rationale
The paper defines an explicit pipeline: query-conditioned DPP for keyframe selection plus spectral entropy computation, followed by threshold-based routing to either direct prediction (Fast) or Temporal Markup Prompting (Slow). These components are introduced as design choices with no equations showing outputs equivalent to inputs by construction, no fitted parameters renamed as predictions, and no load-bearing self-citations. Performance numbers are reported as empirical results on external benchmarks (Charades-STA, ActivityNet Captions) rather than derived tautologically. The chain remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2201.02848 (2022)
Bao, P., Mu, Y.: Learning sample importance for cross-scenario video temporal grounding. arXiv preprint arXiv:2201.02848 (2022)
-
[2]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Cai, S.: Iieu: Rethinking neural feature activation from decision-making. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 5796–5806 (October 2023)
2023
-
[3]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Cai, S.: Adashift: Learning discriminative self-gated neural feature activation with an adaptive shift factor. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 5947–5956 (June 2024)
2024
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cai, S., Yuan, S., Chen, B., Mao, R., Wang, B.: Selection-as-nonlinearity: Bridging attention and activation via a joint game-decision lens for interpretable, discrim- inative visual representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11621–11631 (2026)
2026
-
[5]
In: International Conference on Learning Representations (ICLR) (2026)
Cai, S., Zheng, S., Chen, B., Yuan, S., Xiao, C., Qin, J., WANG, B.: Toward prin- cipled flexible scaling for self-gated neural activation. In: International Conference on Learning Representations (ICLR) (2026)
2026
-
[6]
In: CVPR
Chen, B., Xu, Z., Kirmani, S., Ichter, B., Sadigh, D., Guibas, L., Xia, F.: Spa- tialVLM: Endowing vision-language models with spatial reasoning capabilities. In: CVPR. pp. 14455–14465 (2024)
2024
-
[7]
In: EMNLP
Chen, J., Chen, X., Ma, L., Jie, Z., Chua, T.S.: Temporally grounding natural sentence in video. In: EMNLP. pp. 162–171 (2018)
2018
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Lv, Z., Wu, S., Lin, K.Q., Song, C., Gao, D., Liu, J.W., Gao, Z., Mao, D., Shou, M.Z.: Videollm-online: Online video large language model for streaming video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18407–18418 (2024)
2024
-
[9]
Cheng, S., Zhang, J., Song, Q., Liu, S., Guo, Z., Zhang, X., Zhang, C., Li, X., Tu, Z.: Unison: Harmonizing motion, speech, and sound for human-centric audio-video generation (2026),https://arxiv.org/abs/2605.08729
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Cheng, S., Zhang, J., Liu, Y., Xiao, A., Tu, Z.: Owlsight: A robust illumination adaptation framework for dark video human action recognition. IEEE Transactions on Circuits and Systems for Video Technology36(4), 4550–4564 (2025).https: //doi.org/10.1109/TCSVT.2025.3632359
-
[11]
NeurIPS31(2018)
Duan, X., Huang, W., Gan, C., Wang, J., Zhu, W., Huang, J.: Weakly supervised dense event captioning in videos. NeurIPS31(2018)
2018
-
[12]
In: ICCV
Gao, J., Sun, C., Yang, Z., Nevatia, R.: TALL: Temporal activity localization via language query. In: ICCV. pp. 5267–5275 (2017)
2017
-
[13]
IEEE TCSVT32(3), 1646–1657 (2021)
Gao, J., Xu, C.: Learning video moment retrieval without a single annotated video. IEEE TCSVT32(3), 1646–1657 (2021)
2021
-
[14]
arXiv preprint arXiv:1909.00239 (2019)
Gao, M., Davis, L.S., Socher, R., Xiong, C.: WSLLN: Weakly supervised natural language localization networks. arXiv preprint arXiv:1909.00239 (2019)
-
[15]
2025 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp
Hu, K., Gao, F., Nie, X., Zhou, P., Tran, S., Neiman, T., Wang, L., Shah, M., Hamid, R., Yin, B., Chilimbi, T.M.: M-llm based video frame selection for efficient video understanding. 2025 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp. 13702–13712 (2025),https://api. semanticscholar.org/CorpusID:276647361
2025
-
[16]
In: CVPR
Huang, B., Wang, X., Chen, H., Song, Z., Zhu, W.: VTimeLLM: Empower LLM to grasp video moments. In: CVPR. pp. 14271–14280 (2024)
2024
-
[17]
In: ECCV
Huang, J., Jin, H., Gong, S., Liu, Y.: Video activity localisation with uncertainties in temporal boundary. In: ECCV. pp. 724–740 (2022) 16 Zhengbo Zhang et al
2022
-
[18]
In: ICCV
Huang, J., Liu, Y., Gong, S., Jin, H.: Cross-sentence temporal and semantic rela- tions in video activity localisation. In: ICCV. pp. 7199–7208 (2021)
2021
-
[19]
In: CVPR
Huang, Y., Yang, L., Sato, Y.: Weakly supervised temporal sentence grounding with uncertainty-guided self-training. In: CVPR. pp. 18908–18918 (2023)
2023
-
[20]
In: ICCV
Jang, J., Park, J., Kim, J., Kwon, H., Sohn, K.: Knowing where to focus: Event- aware transformer for video grounding. In: ICCV. pp. 13846–13856 (2023)
2023
-
[21]
IEEE Access13, 167439–167448 (2025),https://api.semanticscholar
Jeon, M., Ma, M., Kim, J.: Dbcon: Dual bias control in zero-shot video moment re- trieval. IEEE Access13, 167439–167448 (2025),https://api.semanticscholar. org/CorpusID:281516316
2025
-
[22]
In: AAAI (2026)
Jeon, M., Yoon, S., Kim, J., Kim, J.: GranAlign: Granularity-aware alignment framework for zero-shot video moment retrieval. In: AAAI (2026)
2026
-
[23]
In: WACV
Kim, D., Park, J., Lee, J., Park, S., Sohn, K.: Language-free training for zero-shot video grounding. In: WACV. pp. 2539–2548 (2023)
2023
-
[24]
In: ICCV (2017)
Krishna, R., Hata, K., Ren, F., Fei-Fei, L., Niebles, J.C.: Dense-captioning events in videos. In: ICCV (2017)
2017
-
[25]
Foun- dations and Trends in Machine Learning5(2–3), 123–286 (2012)
Kulesza, A., Taskar, B.: Determinantal point processes for machine learning. Foun- dations and Trends in Machine Learning5(2–3), 123–286 (2012)
2012
-
[26]
Decision Sciences24(6), 1171–1185 (1993)
Kuo, C.C., Glover, F., Dhir, K.S.: Analyzing and modeling the maximum diversity problem by zero-one programming. Decision Sciences24(6), 1171–1185 (1993). https://doi.org/10.1111/j.1540-5915.1993.tb00509.x
-
[27]
ArXivabs/2508.07925(2025),https://api.semanticscholar.org/CorpusID: 280567060
Lee, J.S., Lee, S., Ahn, J.C., Choi, Y., Lee, J.H.: Tag: A simple yet effective temporal-aware approach for zero-shot video temporal grounding. ArXivabs/2508.07925(2025),https://api.semanticscholar.org/CorpusID: 280567060
-
[28]
In: NeurIPS
Lei, J., Berg, T.L., Bansal, M.: Detecting moments and highlights in videos via natural language queries. In: NeurIPS. pp. 11846–11858 (2021)
2021
-
[29]
In: EMNLP
Lei, J., Yu, L., Bansal, M., Berg, T.L.: TVQA: Localized, compositional video question answering. In: EMNLP. pp. 1369–1379 (2018)
2018
-
[30]
In: Findings of the Association for Computational Linguistics: EMNLP 2022
Lei, W., Gao, D., Wang, Y., Mao, D., Liang, Z., Ran, L., Shou, M.Z.: Assistsr: Task-oriented video segment retrieval for personal ai assistant. In: Findings of the Association for Computational Linguistics: EMNLP 2022. pp. 319–338 (2022)
2022
-
[31]
In: CVPR
Li, J., Xie, J., Qian, L., Zhu, L., Tang, S., Wu, F., Yang, Y., Zhuang, Y., Wang, X.E.: Compositional temporal grounding with structured variational cross-graph correspondence learning. In: CVPR. pp. 3032–3041 (2022)
2022
-
[32]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[33]
Science China Information Sciences 68(2023),https://api.semanticscholar.org/CorpusID:258588306
Li, K., He, Y., Wang, Y., Li, Y., Wang, W., Luo, P., Wang, Y., Wang, L., Qiao, Y.: Videochat: chat-centric video understanding. Science China Information Sciences 68(2023),https://api.semanticscholar.org/CorpusID:258588306
2023
-
[34]
arXiv preprint arXiv:2401.06071 (2024)
Li, Z., Xu, Q., Zhang, D., Song, H., Cai, Y., Qi, Q., Zhou, R., Pan, J., Li, Z., Vu, V.T., et al.: GroundingGPT: Language enhanced multi-modal grounding model. arXiv preprint arXiv:2401.06071 (2024)
- [35]
-
[36]
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: LLaVA-NeXT: Im- proved reasoning, OCR, and world knowledge (January 2024),https://llava- vl.github.io/blog/2024-01-30-llava-next/ DART: Difficulty-Adaptive Routing for Zero-Shot VTG 17
2024
-
[37]
In: ICML (2025)
Liu, R., Geng, J., Wu, A.J., Sucholutsky, I., Lombrozo, T., Griffiths, T.L.: Mind your step (by step): Chain-of-thought can reduce performance on tasks where thinking makes humans worse. In: ICML (2025)
2025
-
[38]
In: CVPR
Luo, D., Huang, J., Gong, S., Jin, H., Liu, Y.: Towards generalisable video mo- ment retrieval: Visual-dynamic injection to image-text pre-training. In: CVPR. pp. 23045–23055 (2023)
2023
-
[39]
2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) pp
Luo, D., Huang, J., Gong, S., Jin, H., Liu, Y.: Zero-shot video moment re- trieval from frozen vision-language models. 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) pp. 5452–5461 (2023),https: //api.semanticscholar.org/CorpusID:261531052
2024
-
[40]
In: Annual Meeting of the Association for Computational Linguistics (2023),https://api
Maaz, M., Rasheed, H.A., Khan, S.H., Khan, F.S.: Video-chatgpt: Towards de- tailed video understanding via large vision and language models. In: Annual Meeting of the Association for Computational Linguistics (2023),https://api. semanticscholar.org/CorpusID:259108333
2023
-
[41]
In: CVPR
Mithun, N.C., Paul, S., Roy-Chowdhury, A.K.: Weakly supervised video moment retrieval from text queries. In: CVPR. pp. 11592–11601 (2019)
2019
-
[42]
In: CVPR
Mun, J., Cho, M., Han, B.: Local-global video-text interactions for temporal grounding. In: CVPR. pp. 10810–10819 (2020)
2020
-
[43]
In: ICCV
Nam, J., Ahn, D., Kang, D., Ha, S.J., Choi, J.: Zero-shot natural language video localization. In: ICCV. pp. 1470–1479 (2021)
2021
-
[44]
Learning Transferable Visual Models From Natural Language Supervision
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. ArXivabs/2103.00020(2021), https://api.semanticscholar.org/CorpusID:231591445
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[45]
2007 15th European Signal Processing Conference pp
Roy, O., Vetterli, M.: The effective rank: A measure of effective dimensionality. 2007 15th European Signal Processing Conference pp. 606–610 (2007),https: //api.semanticscholar.org/CorpusID:12184201
2007
-
[46]
In: ECCV
Sigurdsson, G.A., Varol, G., Wang, X., Farhadi, A., Laptev, I., Gupta, A.: Hol- lywood in homes: Crowdsourcing data collection for activity understanding. In: ECCV. pp. 510–526 (2016)
2016
-
[47]
Song, Q., He, Y., Zhang, Y., Cheng, S., He, Z., Guo, Z., Zhang, C., Li, X., Jiang, C.: Interactiveavatar: Real-time streaming video generation for consistent and intent- aware avatars (2026),https://arxiv.org/abs/2606.22905
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
In: Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Tang, J., Zhao, H.H., Wu, L., Zhang, Z., Tao, Y., Mao, D., Wan, Y., Tan, J., Zeng, M., Li, M., et al.: From charts to code: A hierarchical benchmark for multi- modal models. In: Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13467–13566 (2026)
2026
-
[49]
IEEE Trans- actions on Image Processing34, 7335–7346 (2025)
Tu, Z., Zhang, Z., Gong, J., Yuan, J., Du, B.: Informative sample selection model for skeleton-based action recognition with limited training samples. IEEE Trans- actions on Image Processing34, 7335–7346 (2025)
2025
-
[50]
In: ACM MM
Wang,G.,Wu,X.,Liu,Z.,Yan,J.:Prompt-basedzero-shotvideomomentretrieval. In: ACM MM. pp. 413–421 (2022)
2022
-
[51]
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding
Wang, Y., Xu, B., Yue, Z., Xiao, Z., Wang, Z., Zhang, L., Yang, D., Wang, W., Jin, Q.: Timezero: Temporal video grounding with reasoning-guided lvlm. ArXivabs/2503.13377(2025),https://api.semanticscholar.org/CorpusID: 281707035
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
In: ECCV (2024)
Wang, Y., Li, K., Li, X., Yu, J., He, Y., Chen, G., Pei, B., Zheng, R., Xu, J., Wang, Z., et al.: InternVideo2: Scaling foundation models for multimodal video understanding. In: ECCV (2024)
2024
-
[53]
In: AAAI
Wang, Z., Wang, L., Wu, T., Li, T., Wu, G.: Negative sample matters: A renais- sance of metric learning for temporal grounding. In: AAAI. pp. 2613–2621 (2022) 18 Zhengbo Zhang et al
2022
-
[54]
In: International Symposium on Visual Comput- ing
Wattasseril, J.I., Shekhar, S., Döllner, J., Trapp, M.: Zero-shot video moment re- trieval using BLIP-based models. In: International Symposium on Visual Comput- ing. pp. 160–171 (2023)
2023
-
[55]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E.H., Xia, F., Le, Q., Zhou, D.: Chain of thought prompting elicits reasoning in large language models. ArXivabs/2201.11903(2022),https://api.semanticscholar.org/CorpusID: 246411621
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
In: Eu- ropean Conference on Computer Vision
Wong, B., Chen, J., Wu, Y., Lei, S.W., Mao, D., Gao, D., Shou, M.Z.: Assistq: Affordance-centric question-driven task completion for egocentric assistant. In: Eu- ropean Conference on Computer Vision. pp. 485–501. Springer (2022)
2022
-
[57]
In: AAAI
Wu, J., Li, G., Liu, S., Lin, L.: Tree-structured policy based progressive reinforce- ment learning for temporally language grounding in video. In: AAAI. vol. 34, pp. 12386–12393 (2020)
2020
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xiao, A., Cheng, S., Xu, Y., Ren, Y., Chen, H., Yokoya, N.: Geommbench and geommagent:Towardexpert-levelmultimodalintelligenceingeoscienceandremote sensing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 34843–34853 (June 2026)
2026
-
[59]
ArXivabs/2403.02076(2024),https://api
Xu, Y., Sun, Y., Xie, Z., Zhai, B., Du, S.: Vtg-gpt: Tuning-free zero-shot video temporal grounding with gpt. ArXivabs/2403.02076(2024),https://api. semanticscholar.org/CorpusID:268035181
-
[60]
Xu, Y., Sun, Y., Zhai, B., Li, M., Liang, W., Du, S.: Zero-shot video moment retrieval via off-the-shelf multimodal large language models. AAAI pp. 8978–8986 (2025)
2025
-
[61]
In: CVPR
Yang, L., Kong, Q., Yang, H.K., Kehl, W., Sato, Y., Kobori, N.: Deco: Decompo- sition and reconstruction for compositional temporal grounding via coarse-to-fine contrastive ranking. In: CVPR. pp. 23130–23140 (2023)
2023
-
[62]
In: SIGIR
Yang, X., Feng, F., Ji, W., Wang, M., Chua, T.S.: Deconfounded video moment retrieval with causal intervention. In: SIGIR. pp. 1–10 (2021)
2021
-
[63]
In: ACM Workshop on Human-Centric Multimedia Analysis
Yuan, Y., Lan, X., Wang, X., Chen, L., Wang, Z., Zhu, W.: A closer look at temporal sentence grounding in videos: Dataset and metric. In: ACM Workshop on Human-Centric Multimedia Analysis. pp. 13–21 (2021)
2021
-
[64]
NeurIPS32(2019)
Yuan, Y., Ma, L., Wang, J., Liu, W., Zhu, W.: Semantic conditioned dynamic modulation for temporal sentence grounding in videos. NeurIPS32(2019)
2019
-
[65]
In: Conference on Empirical Methods in Nat- ural Language Processing (2023),https://api.semanticscholar.org/CorpusID: 259075356
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual lan- guage model for video understanding. In: Conference on Empirical Methods in Nat- ural Language Processing (2023),https://api.semanticscholar.org/CorpusID: 259075356
2023
-
[66]
Zhang, H., Sun, A., Jing, W., Zhou, J.T.: Span-based localizing network for natural language video localization. In: ACL. pp. 6543–6554 (2020)
2020
-
[67]
In: ICCV
Zhang, J., Guo, Y., Potamias, R.A., Deng, J., Xu, H., Ma, C.: VTimeCoT: Think- ing by drawing for video temporal grounding and reasoning. In: ICCV. pp. 24203– 24213 (2025)
2025
-
[68]
In: AAAI
Zhang, S., Peng, H., Fu, J., Luo, J.: Learning 2d temporal adjacent networks for moment localization with natural language. In: AAAI. vol. 34, pp. 12870–12877 (2020)
2020
-
[69]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2026)
Zhang, Z., Tu, Z., Yuan, J., Soh, D.W., Du, B.: Leveraging text-to-image diffusion models for unsupervised visual object tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence (2026)
2026
-
[70]
In: European Conference on Computer Vision
Zhang, Z., Xu, L., Peng, D., Rahmani, H., Liu, J.: Diff-tracker: text-to-image dif- fusion models are unsupervised trackers. In: European Conference on Computer Vision. pp. 319–337. Springer (2024) DART: Difficulty-Adaptive Routing for Zero-Shot VTG 19
2024
-
[71]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, Z., Zhou, Y., Peng, D., Lim, J.H., Tu, Z., Soh, D.W., Foo, L.G.: Visual prompting for one-shot controllable video editing without inversion. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7784–7794 (2025)
2025
-
[72]
In: European Conference on Com- puter Vision (2024),https://api.semanticscholar.org/CorpusID:272146312
Zheng, M., Cai, X., Chen, Q., Peng, Y., Liu, Y.: Training-free video temporal grounding using large-scale pre-trained models. In: European Conference on Com- puter Vision (2024),https://api.semanticscholar.org/CorpusID:272146312
2024
-
[73]
Zheng,M.,Gong,S.,Jin,H.,Peng,Y.,Liu,Y.:Generatingstructuredpseudolabels for noise-resistant zero-shot video sentence localization. In: ACL. pp. 14197–14209 (2023)
2023
-
[74]
In: AAAI (2022)
Zheng, M., Huang, Y., Chen, Q., Liu, Y.: Weakly supervised video moment local- ization with contrastive negative sample mining. In: AAAI (2022)
2022
-
[75]
In: CVPR (2022)
Zheng, M., Huang, Y., Chen, Q., Peng, Y., Liu, Y.: Weakly supervised temporal sentence grounding with gaussian-based contrastive proposal learning. In: CVPR (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.