Sequentially-Controlled Interactive Multi-Particle Flow-Maps for Online Feedback-Driven Search
Pith reviewed 2026-07-02 15:27 UTC · model grok-4.3
The pith
IMPFM uses flow-map sample sharing to create a multi-particle Feynman-Kac corrector that steers ensembles toward KL-tilted distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The resulting sampling framework yields a multi-particle interaction-aware Feynman-Kac corrector that progressively steers the multi-particle system toward a KL-tilted target distribution, facilitating global exploration and preventing mode collapse.
What carries the argument
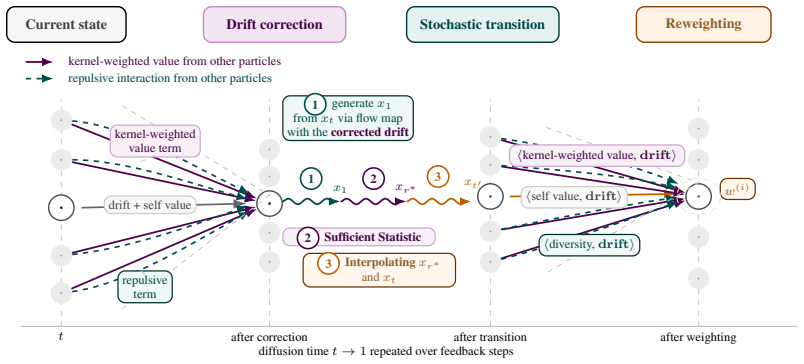
Flow-map powered posterior sample sharing mechanism that supplies collective corrections to individual particle drift at each resampling step.
If this is right
- The method enables sample-efficient global search in tasks where preferences must be learned through sequential feedback.
- Multi-particle interaction reweighting overcomes weight degeneracy typical of standard SMC samplers while preserving structural diversity.
- The framework actively reduces reward over-optimization by maintaining ensemble coverage during transport.
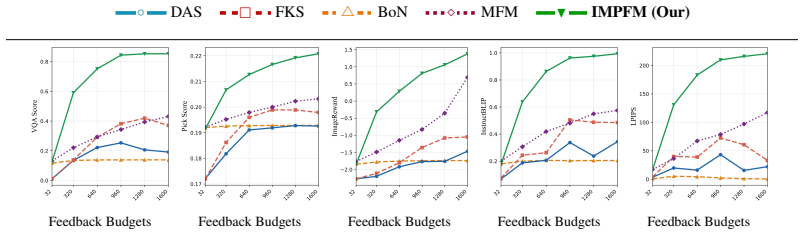
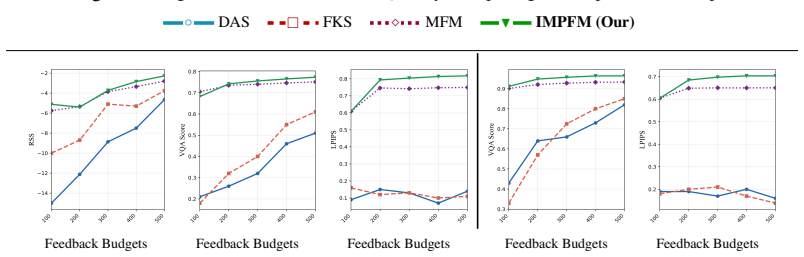
- Empirical results across search and alignment tasks show improved coverage compared with existing baselines.
Where Pith is reading between the lines
- The particle-sharing idea could transfer to other sequential decision settings that require balancing exploration with partial feedback.
- Pairing the flow-map corrections with existing generative models might extend the approach to higher-dimensional or structured search spaces.
- Testing the unbiased-correction assumption in discrete versus continuous state spaces would clarify the framework's range of validity.
Load-bearing premise
Flow maps can be computed to share posterior samples across particles in a way that produces unbiased collective corrections at each resampling step.
What would settle it
An experiment that demonstrates biased collective corrections or persistent mode collapse in the particle ensemble under the proposed resampling would falsify the claimed Feynman-Kac property.
Figures















read the original abstract
While generative models have enabled training-free reward alignment, current methods typically excel in local exploration within narrow regions of the underlying distribution. These approaches struggle when preferences are unknown a priori and only revealed through sequential feedback-a scenario demanding broad exploration to uncover high-utility regions. To address this, we propose Sequentially-Controlled Interactive Multi-Particle Flow-Maps (IMPFM), a framework for sample-efficient online feedback-driven search. IMPFM progressively transports a group of interactive particles toward the target distribution, maintaining the broad coverage essential for heterogeneous preference alignment. IMPFM introduces a principled and efficient posterior sample sharing mechanism across particles powered by flow maps. By correcting individual particle drift with the collective posterior samples of the entire ensemble at each resampling step, the framework maximizes sample utility to enable global exploration while actively mitigating reward over-optimization, typical of standard control frameworks. Paired with a principled exploration-exploitation reweighting mechanism involving multi-particle interaction, this sequentially corrected multi-particle dynamics explicitly preserves structural diversity and overcomes the weight degeneracy inherent to standard SMC samplers. Crucially, we prove that the resulting sampling framework yields a multi-particle interaction-aware Feynman-Kac corrector that progressively steers the multi-particle system toward a KL-tilted target distribution, facilitating global exploration and preventing mode collapse. Extensive empirical evaluations and rigorous ablations across diverse search and alignment tasks confirm the efficacy of IMPFM over existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Sequentially-Controlled Interactive Multi-Particle Flow-Maps (IMPFM) for sample-efficient online feedback-driven search. It introduces a flow-map-based mechanism for sharing posterior samples across an ensemble of particles, pairs this with a multi-particle interaction reweighting scheme for exploration-exploitation, and claims to prove that the resulting dynamics constitute a multi-particle interaction-aware Feynman-Kac corrector that steers the system toward a KL-tilted target distribution while preserving diversity. Extensive empirical evaluations and ablations on search and alignment tasks are reported.
Significance. If the claimed proof is rigorous and the empirical advantages are reproducible, the framework could meaningfully extend training-free reward alignment methods by enabling global exploration under sequential feedback, addressing mode collapse and over-optimization issues common in standard control and SMC approaches.
major comments (2)
- [Abstract] Abstract: The central claim that the framework 'yields a multi-particle interaction-aware Feynman-Kac corrector' that 'progressively steers the multi-particle system toward a KL-tilted target distribution' is load-bearing. The description supplies no derivation establishing that the flow-map-mediated collective corrections remain a valid Radon-Nikodym factor with respect to the tilted target or that the interaction term preserves the martingale property when sample sharing introduces dependence across particles.
- [Abstract] Abstract (proof claim): The proof is asserted to rest on the flow maps delivering unbiased collective posterior corrections at each resampling step. No indication is given of the measure-theoretic conditions under which this holds when the flow maps are learned or approximate, leaving open whether the claimed correctness property can fail due to approximation error or reweighting dependence.
minor comments (1)
- The abstract refers to 'rigorous ablations across diverse search and alignment tasks' without specifying the tasks, metrics, or baseline implementations, which hinders assessment of the empirical support for the central claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater clarity on the central theoretical claims in the abstract. We will revise the manuscript to strengthen the presentation of the proof, including a concise outline in the abstract and expanded discussion of the measure-theoretic conditions and approximation robustness in the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the framework 'yields a multi-particle interaction-aware Feynman-Kac corrector' that 'progressively steers the multi-particle system toward a KL-tilted target distribution' is load-bearing. The description supplies no derivation establishing that the flow-map-mediated collective corrections remain a valid Radon-Nikodym factor with respect to the tilted target or that the interaction term preserves the martingale property when sample sharing introduces dependence across particles.
Authors: The full derivation is presented in Section 3 (Theoretical Analysis), where we establish that the flow-map-mediated collective corrections yield a valid Radon-Nikodym derivative with respect to the KL-tilted target and that the interaction reweighting preserves the martingale property by explicitly accounting for cross-particle dependence through the ensemble posterior. We agree the abstract is too terse on this point and will revise it to include a high-level sketch of the key steps (unbiased collective correction at resampling, followed by interaction-aware reweighting that maintains the Feynman-Kac structure). revision: yes
-
Referee: [Abstract] Abstract (proof claim): The proof is asserted to rest on the flow maps delivering unbiased collective posterior corrections at each resampling step. No indication is given of the measure-theoretic conditions under which this holds when the flow maps are learned or approximate, leaving open whether the claimed correctness property can fail due to approximation error or reweighting dependence.
Authors: Section 3.2 specifies the measure-theoretic conditions (absolute continuity of the flow-map pushforwards and bounded Radon-Nikodym derivatives) under which the unbiasedness holds for exact flow maps. For learned/approximate maps we provide an error propagation bound (Proposition 3) showing that the total variation distance to the target remains controlled under standard Lipschitz assumptions on the learned maps. We will add an explicit statement of these conditions to the abstract and expand the discussion of approximation robustness in Section 3.3. revision: yes
Circularity Check
No circularity: claimed proof of multi-particle Feynman-Kac corrector presented as independent derivation
full rationale
The abstract asserts a proof that IMPFM yields a multi-particle interaction-aware Feynman-Kac corrector steering toward a KL-tilted target, but the provided text contains no equations or definitions showing that the target distribution, corrector, or flow-map corrections are defined in terms of themselves or reduce by construction to the input preference model. No self-citation chain, fitted parameter renamed as prediction, or ansatz smuggling is exhibited. The derivation chain is therefore treated as self-contained pending the full equations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Feed- back efficient online fine-tuning of diffusion models.arXiv preprint arXiv:2402.16359, 2024
Masatoshi Uehara, Yulai Zhao, Kevin Black, Ehsan Hajiramezanali, Gabriele Scalia, Nathaniel Lee Diamant, Alex M Tseng, Sergey Levine, and Tommaso Biancalani. Feedback efficient online fine-tuning of diffusion models.arXiv preprint arXiv:2402.16359, 2024
-
[2]
arXiv preprint arXiv:2501.06848 , year=
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models.arXiv preprint arXiv:2501.06848, 2025
-
[3]
Sunwoo Kim, Minkyu Kim, and Dongmin Park. Test-time alignment of diffusion models without reward over-optimization.arXiv preprint arXiv:2501.05803, 2025
-
[4]
Cheuk Kit Lee, Paul Jeha, Jes Frellsen, Pietro Lio, Michael Samuel Albergo, and Francisco Vargas. Debiasing guidance for discrete diffusion with sequential monte carlo.arXiv preprint arXiv:2502.06079, 2025
-
[5]
Yingqing Guo, Yukang Yang, Hui Yuan, and Mengdi Wang. Training-free guidance beyond differentiability: Scalable path steering with tree search in diffusion and flow models.arXiv preprint arXiv:2502.11420, 2025
-
[6]
Vineet Jain, Kusha Sareen, Mohammad Pedramfar, and Siamak Ravanbakhsh. Diffusion tree sampling: Scalable inference-time alignment of diffusion models.arXiv preprint arXiv:2506.20701, 2025
-
[7]
Marta Skreta, Tara Akhound-Sadegh, Viktor Ohanesian, Roberto Bondesan, Alán Aspuru- Guzik, Arnaud Doucet, Rob Brekelmans, Alexander Tong, and Kirill Neklyudov. Feynman- kac correctors in diffusion: Annealing, guidance, and product of experts.arXiv preprint arXiv:2503.02819, 2025
-
[8]
Deft: Efficient fine-tuning of diffusion models by learning the generalisedh-transform.Advances in Neural Information Processing Systems, 37:19636–19682, 2024
Alexander Denker, Francisco Vargas, Shreyas Padhy, Kieran Didi, Simon Mathis, Vincent Dutordoir, Riccardo Barbano, Emile Mathieu, Urszula J Komorowska, and Pietro Lio. Deft: Efficient fine-tuning of diffusion models by learning the generalisedh-transform.Advances in Neural Information Processing Systems, 37:19636–19682, 2024
2024
-
[9]
A stochastic control approach to reciprocal diffusion processes.Applied mathematics and Optimization, 23(1):313–329, 1991
Paolo Dai Pra. A stochastic control approach to reciprocal diffusion processes.Applied mathematics and Optimization, 23(1):313–329, 1991
1991
-
[10]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Peter Holderrieth, Uriel Singer, Tommi Jaakkola, Ricky TQ Chen, Yaron Lipman, and Brian Karrer. Glass flows: Transition sampling for alignment of flow and diffusion models.arXiv preprint arXiv:2509.25170, 2025
-
[12]
Nicholas M Boffi, Michael S Albergo, and Eric Vanden-Eijnden. How to build a consistency model: Learning flow maps via self-distillation.arXiv preprint arXiv:2505.18825, 2025
-
[13]
Meta Flow Maps enable scalable reward alignment
Peter Potaptchik, Adhi Saravanan, Abbas Mammadov, Alvaro Prat, Michael S Albergo, and Yee Whye Teh. Meta flow maps enable scalable reward alignment.arXiv preprint arXiv:2601.14430, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Tilt matching for scalable sampling and fine-tuning.arXiv preprint arXiv:2512.21829, 2025
Peter Potaptchik, Cheuk-Kit Lee, and Michael S Albergo. Tilt matching for scalable sampling and fine-tuning.arXiv preprint arXiv:2512.21829, 2025
-
[15]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. In European Conference on Computer Vision, pages 366–384. Springer, 2024
2024
-
[16]
Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023. 12
2023
-
[17]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[18]
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
2023
-
[19]
Genai arena: An open evaluation platform for generative models.Advances in Neural Information Processing Systems, 37:79889–79908, 2024
Dongfu Jiang, Max Ku, Tianle Li, Yuansheng Ni, Shizhuo Sun, Rongqi Fan, and Wenhu Chen. Genai arena: An open evaluation platform for generative models.Advances in Neural Information Processing Systems, 37:79889–79908, 2024
2024
-
[20]
Kaiyi Huang, Chengqi Duan, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i- compbench++: An enhanced and comprehensive benchmark for compositional text-to-image generation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(5):3563–3579, 2025
2025
-
[21]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
2024
-
[22]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[23]
Sana-sprint: One-step diffusion with continuous-time consistency distillation
Junsong Chen, Shuchen Xue, Yuyang Zhao, Jincheng Yu, Sayak Paul, Junyu Chen, Han Cai, Song Han, and Enze Xie. Sana-sprint: One-step diffusion with continuous-time consistency distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16185–16195, 2025
2025
-
[24]
Sequential monte carlo samplers.Journal of the Royal Statistical Society Series B: Statistical Methodology, 68(3):411–436, 2006
Pierre Del Moral, Arnaud Doucet, and Ajay Jasra. Sequential monte carlo samplers.Journal of the Royal Statistical Society Series B: Statistical Methodology, 68(3):411–436, 2006
2006
-
[25]
Particle denoising diffusion sampler.arXiv preprint arXiv:2402.06320, 2024
Angus Phillips, Hai-Dang Dau, Michael John Hutchinson, Valentin De Bortoli, George Deligiannidis, and Arnaud Doucet. Particle denoising diffusion sampler.arXiv preprint arXiv:2402.06320, 2024
-
[26]
arXiv preprint arXiv:2308.07983 , year=
Gabriel Cardoso, Yazid Janati El Idrissi, Sylvain Le Corff, and Eric Moulines. Monte carlo guided diffusion for bayesian linear inverse problems.arXiv preprint arXiv:2308.07983, 2023
-
[27]
Diffusion posterior sampling for linear inverse problem solving: A filtering perspective
Zehao Dou and Yang Song. Diffusion posterior sampling for linear inverse problem solving: A filtering perspective. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[28]
arXiv preprint arXiv:2206.04119 , year=
Brian L Trippe, Jason Yim, Doug Tischer, David Baker, Tamara Broderick, Regina Barzilay, and Tommi Jaakkola. Diffusion probabilistic modeling of protein backbones in 3d for the motif-scaffolding problem.arXiv preprint arXiv:2206.04119, 2022
-
[29]
Practi- cal and asymptotically exact conditional sampling in diffusion models.Advances in Neural Information Processing Systems, 36:31372–31403, 2023
Luhuan Wu, Brian Trippe, Christian Naesseth, David Blei, and John P Cunningham. Practi- cal and asymptotically exact conditional sampling in diffusion models.Advances in Neural Information Processing Systems, 36:31372–31403, 2023
2023
-
[30]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[31]
Theoretical guarantees on the best-of-n alignment policy
Ahmad Beirami, Alekh Agarwal, Jonathan Berant, Alex D’Amour, Jacob Eisenstein, Chirag Nagpal, and Ananda Theertha Suresh. Theoretical guarantees on the best-of-n alignment policy. 2024.URL https://api. semanticscholar. org/CorpusID, 266741736(3), 1879. 13
2024
-
[32]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback, 2022.URL https://arxiv. org/abs/2112.09332, 35, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[34]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. Raft: Reward ranked finetuning for generative foundation model alignment.arXiv preprint arXiv:2304.06767, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
A Red Sports Car
Qiang Liu, Jason Lee, and Michael Jordan. A kernelized stein discrepancy for goodness-of-fit tests. InInternational conference on machine learning, pages 276–284. PMLR, 2016. 14 Sequentially-Controlled Interactive Multi-Particle Flow-Maps for Online Feedback-Driven Search (Appendix) Appendix Table of Contents Appendix: Theoretical Derivations Page 1 Deriv...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.