MIBE: Multi-subject Interaction Benchmark and Evaluator for Personalized Image Generation
Pith reviewed 2026-07-03 21:03 UTC · model grok-4.3
The pith
A reference-conditioned evaluator trained only on VLM-labeled pairs matches human preferences for multi-subject personalized image generation even on unseen generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a lightweight reference-conditioned evaluator with dual heads for ranking and diagnosis, trained exclusively on a VLM-labeled collection of multi-subject interaction pairs, produces pairwise decisions that align closely with human preferences on a held-out human-evaluated collection that spans diverse state-of-the-art generators, including those never seen during training, and outperforms standard metrics such as CLIP and DINO variants in both ranking separability and human agreement.
What carries the argument
The Multi-subject Interaction Evaluator (MIE), a reference-conditioned model with dual ranking and diagnosis heads trained on VLM preference labels from the decoupled Silver Set.
If this is right
- Generators can be ranked automatically for multi-subject fidelity and interaction accuracy at scale without new human labeling for each model.
- Specific errors such as subject omission, appearance drift, or interaction misattribution can be diagnosed automatically during evaluation.
- Evaluation remains reliable when applied to entirely new generators because the method demonstrates cross-generator generalization.
- Development cycles for personalized image models can incorporate diagnostic feedback to target particular failure modes rather than relying on aggregate scores alone.
Where Pith is reading between the lines
- The silver-gold set construction could be reused to create evaluators for related tasks such as multi-character video generation or scene layout assessment.
- MIE scores could serve as a reward signal in reinforcement learning loops to directly optimize generators for multi-subject correctness.
- Similar VLM-supervised training might improve automatic evaluation in other domains where human labeling is expensive, such as 3D asset or animation quality.
Load-bearing premise
Vision-language model labels for image-pair preferences are accurate and unbiased enough to produce an evaluator whose decisions match human judgments on images from generators never used in training.
What would settle it
A new test collection of multi-subject generated images from additional unseen generators where fresh human pairwise preferences show low agreement with the rankings produced by MIE.
Figures




read the original abstract
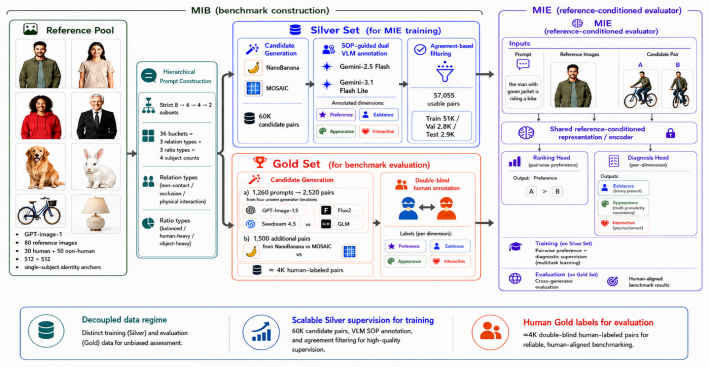
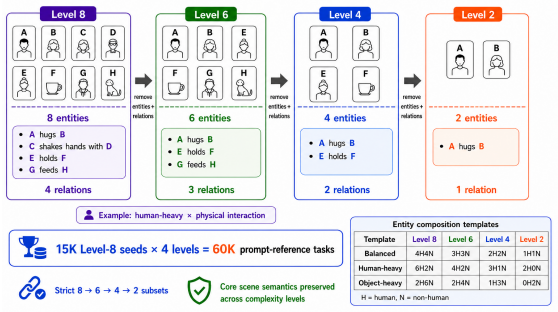
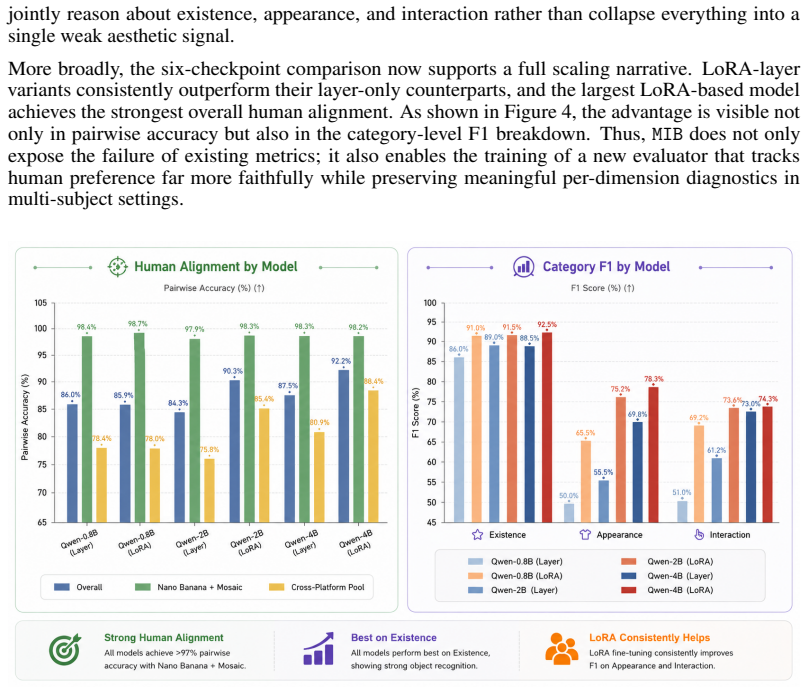
Multi-subject personalized image generation requires the precise rendering of all requested reference identities and their specified interactions based on a guiding prompt. However, state-of-the-art models still struggle with this process, frequently omitting subjects, failing to preserve reference appearances, or misattributing interactions. Furthermore, existing metrics designed primarily for single-subject fidelity cannot reliably capture these errors, suffering severe degradation in ranking separability and failing to align with human preference as the subject count increases. To address this gap, we introduce Multi-subject Interaction Benchmark and Evaluator (MIBE), a unified framework comprising a Multi-subject Interaction Benchmark (MIB) and a Multi-subject Interaction Evaluator (MIE). MIB systematically covers diverse relation types and scene complexities through a decoupled data regime. This consists of a 60K-pair VLM-labeled Silver Set for scalable metric training and a 4K-pair double-blind Human Evaluation Gold Set covering a diverse range of state-of-the-art generators, with the Silver Set reaching 95.1% cross-VLM preference agreement. To demonstrate the utility of this benchmark, we present MIE, a lightweight, reference-conditioned evaluator trained exclusively on the Silver Set with a dual-head ranking and diagnosis objective. MIE exhibits strong cross-generator generalization on the Gold Set, achieving 0.922 overall pairwise accuracy against human preference, including 0.982 on seen generators and 0.884 on unseen generators. By outperforming a broad spectrum of baseline metrics, including CLIP and DINO variants, MIE demonstrates that diagnostic supervision can preserve ranking separability and human alignment where traditional evaluators collapse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Multi-subject Interaction Benchmark and Evaluator (MIBE) for personalized image generation involving multiple subjects. It consists of the Multi-subject Interaction Benchmark (MIB) with a 60K-pair VLM-labeled Silver Set used for training and a 4K-pair double-blind human-evaluated Gold Set for testing, plus the Multi-subject Interaction Evaluator (MIE), a lightweight reference-conditioned model trained exclusively on the Silver Set using a dual-head ranking and diagnosis objective. MIE reports 0.922 overall pairwise accuracy against human preferences on the Gold Set (0.982 on seen generators, 0.884 on unseen), outperforming CLIP and DINO variants while maintaining ranking separability as subject count increases.
Significance. If the VLM-derived labels prove to be an unbiased proxy for human judgments, the work would provide a scalable training regime and diagnostic evaluator that addresses the documented failure of single-subject metrics on multi-subject interaction tasks. The explicit separation into Silver and Gold sets, cross-generator splits, and concrete accuracy numbers on human data are strengths that could support more reliable model ranking in this domain.
major comments (3)
- [Silver Set description (§3)] Silver Set description (abstract and §3): The 95.1% cross-VLM preference agreement is reported, yet no human preference correlation or agreement rate is provided for any subset of the 60K-pair Silver Set. Because MIE is trained exclusively on these VLM labels and the central claim is 0.922 pairwise accuracy against human judgments on the Gold Set, this missing validation is load-bearing; without it the generalization numbers could reflect VLM-specific biases rather than human alignment.
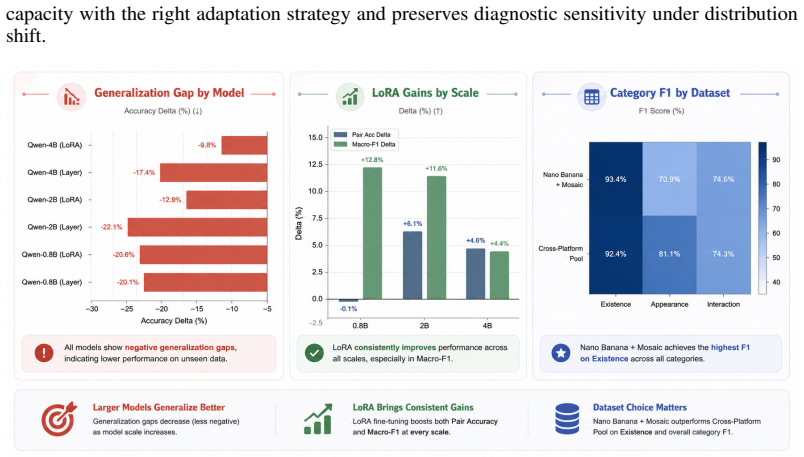
- [MIE evaluation protocol (§4)] MIE evaluation protocol (§4 and Gold Set results): The reported 0.884 accuracy on unseen generators is presented as evidence of cross-generator generalization, but the manuscript does not detail the exact generator overlap between Silver and Gold sets or provide an error analysis breaking down failure modes by interaction type or subject count. This information is required to confirm that the performance difference from baselines is not driven by distribution shift artifacts in the particular Gold Set generators.
- [Baseline comparisons (results table)] Baseline comparisons (Table reporting CLIP/DINO results): The claim that MIE outperforms CLIP and DINO variants is central, yet the manuscript does not report whether the baseline models were fine-tuned on the same Silver Set or used zero-shot; if the latter, the comparison does not isolate the contribution of the dual-head diagnostic supervision.
minor comments (2)
- [Abstract] The abstract states the Silver Set reaches 95.1% cross-VLM agreement but does not specify which VLMs were used or how ties were handled; adding this detail would improve reproducibility.
- [Method section] Notation for the dual-head loss could be clarified with an explicit equation showing how the ranking and diagnosis heads are combined during training.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Silver Set description (§3)] Silver Set description (abstract and §3): The 95.1% cross-VLM preference agreement is reported, yet no human preference correlation or agreement rate is provided for any subset of the 60K-pair Silver Set. Because MIE is trained exclusively on these VLM labels and the central claim is 0.922 pairwise accuracy against human judgments on the Gold Set, this missing validation is load-bearing; without it the generalization numbers could reflect VLM-specific biases rather than human alignment.
Authors: We agree that direct human validation on the Silver Set would strengthen the work. The Silver Set was constructed for scalability using VLM labels with high cross-VLM consistency (95.1%). To address the concern, we will add a human preference study on a random subset of 500 Silver Set pairs and report the agreement rate with VLM labels in the revised §3. This will provide evidence that the labels serve as a reasonable proxy for human judgments. revision: yes
-
Referee: [MIE evaluation protocol (§4)] MIE evaluation protocol (§4 and Gold Set results): The reported 0.884 accuracy on unseen generators is presented as evidence of cross-generator generalization, but the manuscript does not detail the exact generator overlap between Silver and Gold sets or provide an error analysis breaking down failure modes by interaction type or subject count. This information is required to confirm that the performance difference from baselines is not driven by distribution shift artifacts in the particular Gold Set generators.
Authors: We will revise §4 to explicitly document the generator overlap between the Silver and Gold sets, including the precise list of seen and unseen generators. We will also add a detailed error analysis that breaks down accuracy by interaction type (e.g., spatial relations, actions) and subject count, along with representative failure cases. This will allow readers to assess whether the reported gains are robust to distribution shifts. revision: yes
-
Referee: [Baseline comparisons (results table)] Baseline comparisons (Table reporting CLIP/DINO results): The claim that MIE outperforms CLIP and DINO variants is central, yet the manuscript does not report whether the baseline models were fine-tuned on the same Silver Set or used zero-shot; if the latter, the comparison does not isolate the contribution of the dual-head diagnostic supervision.
Authors: The baselines were evaluated zero-shot, as is standard for general-purpose metrics like CLIP and DINO in the literature. This choice highlights MIE's advantage as a specialized model. To better isolate the benefit of the dual-head ranking and diagnosis objective, we will additionally fine-tune the CLIP and DINO variants on the Silver Set using a standard ranking loss and report the updated results in the revised table. revision: yes
Circularity Check
No significant circularity: training labels and test labels are from independent sources
full rationale
The paper trains MIE exclusively on the VLM-labeled Silver Set (60K pairs) and measures pairwise accuracy directly against human preferences on the separate Gold Set (4K pairs). No equations, derivations, or first-principles claims are presented that reduce the reported 0.922 accuracy (or the 0.884 unseen-generator figure) to the training inputs by construction. The 95.1% cross-VLM agreement is used only to characterize the Silver Set itself and does not enter the Gold Set evaluation. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The central empirical claim therefore remains externally falsifiable on the human Gold Set and does not collapse into a renaming or self-definition of its own training signal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLM-generated preference labels are sufficiently reliable proxies for human preference to train a generalizable evaluator
Reference graph
Works this paper leans on
-
[1]
Multihuman-testbench: Benchmarking image generation for multiple humans
Shubhankar Borse, Sungrae Choi, Sanghyun Park, Jihoon Kim, Sayak Kadambi, Risheek Gar- repalli, Suyeon Yun, Munawar Hayat, and Fatih Porikli. Multihuman-testbench: Benchmarking image generation for multiple humans. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[2]
Hao Chen et al. Xverse: Consistent multi-subject control of identity and semantic attributes via dit modulation.arXiv preprint arXiv:2506.21416, 2025
-
[3]
Zhihan Chen, Yuhuan Zhao, Yijie Zhu, and Xinyu Yao. When identities collapse: A stress-test benchmark for multi-subject personalization.arXiv preprint arXiv:2603.26078, 2026
-
[4]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. InInternational Conference on Learning Representations, 2023
2023
-
[5]
Image quality metrics: Psnr vs
Alain Hore and Djemel Ziou. Image quality metrics: Psnr vs. ssim. In2010 20th international conference on pattern recognition, pages 2366–2369. IEEE, 2010
2010
-
[6]
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation
Kaiyi Huang, Kaiqiang Sun, Jian Enzweiler, et al. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[7]
Pick-a-pic: An open dataset of user preferences for text-to-image generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[8]
VLM Judges Can Rank but Cannot Score: Task-Dependent Uncertainty in Multimodal Evaluation
Divake Kumar, Sina Tayebati, Devashri Naik, Ranganath Krishnan, and Amit Ranjan Trivedi. Vlm judges can rank but cannot score: Task-dependent uncertainty in multimodal evaluation. arXiv preprint arXiv:2604.25235, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Multi- concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi- concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2023
1931
-
[10]
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming-Ming Cheng, and Ying Shan. Photomaker: Customizing realistic human photos via stacked id embedding.arXiv preprint arXiv:2312.04461, 2024
-
[11]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Sypetkowski, Vincent Lempereur, Armand Guzmao, Armand Joulin, and Piotr Bojanowski. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Multibanana: A challenging benchmark for multi-reference text- to-image generation
Yuta Oshima, Daiki Miyake, Kohsei Matsutani, Yusuke Iwasawa, Masahiro Suzuki, Yutaka Matsuo, and Hiroki Furuta. Multibanana: A challenging benchmark for multi-reference text- to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. arXiv preprint arXiv:2511.22989
-
[13]
Yuang Peng, Yuxin Cui, Haomiao Su, Mingzhen Ma, Wenqi Fang, Ting Cheng, Guanzhong Feng, Yu Hu, and Zhen Zhao. Dreambench++: A human-aligned benchmark for personalized image generation.arXiv preprint arXiv:2406.16855, 2024
-
[14]
Learning transferable visual models from natural language supervision.International conference on machine learning, pages 8748–8763, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision.International conference on machine learning, pages 8748–8763, 2021
2021
-
[15]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
2023
-
[16]
Wenqing Tian, Hanyi Mao, Zhaocheng Liu, Lihua Zhang, Qiang Liu, Jian Wu, and Liang Wang. Multibind: A benchmark for attribute misbinding in multi-subject generation.arXiv preprint arXiv:2603.21937, 2026
-
[17]
PSR: Scaling Multi-Subject Personalized Image Generation with Pairwise Subject-Consistency Rewards
Shulei Wang, Longhui Wei, Xin He, Jianbo Ouyang, Hui Lu, Zhou Zhao, and Qi Tian. Psr: Scaling multi-subject personalized image generation with pairwise subject-consistency rewards. arXiv preprint arXiv:2512.01236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
X Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang. Ms-diffusion: Multi-subject zero-shot image personalization with layout guidance.arXiv preprint arXiv:2406.07209, 2024
-
[19]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600– 612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600– 612, 2004
2004
-
[20]
Multiscale structural similarity for image quality assessment
Zhou Wang, Eero P Simoncelli, and Alan C Bovik. Multiscale structural similarity for image quality assessment. InThe thrity-seventh asilomar conference on signals, systems & computers, 2003, volume 2, pages 1398–1402. Ieee, 2003
2003
-
[21]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Fastcom- poser: Tuning-free multi-subject image generation with localized attention
Guangxuan Xiao, Tianwei Yin, William T Freeman, Fredo Durand, and Song Han. Fastcom- poser: Tuning-free multi-subject image generation with localized attention. InInternational Journal of Computer Vision, 2024
2024
-
[24]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yien Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[25]
Customized human object interaction image generation.arXiv preprint arXiv:2508.19575, 2025
Tang Xu, Wenbin Wang, Alin Zhong, et al. Customized human object interaction image generation.arXiv preprint arXiv:2508.19575, 2025
-
[26]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 11 A Appendix: Human Annotation Observations and Failure Mode Analysis During the human annotation process for the gold test set, annotators sy...
2023
-
[28]
The original generation prompt
-
[29]
Reference images for each subject mentioned in the prompt
-
[30]
A" or "B
Candidate image B. Your job consists of two parts: Part 1: Independent Evaluation Evaluate candidate A and candidate B independently. For each image, strictly evaluate: - Existence: Are ALL the required subjects in the references physically present? (Generic versions count as 1; completely missing counts as 0). - Appearance: Are the subjects rendered WITH...
-
[31]
Guidelines: 24 • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.