PSR: Scaling Multi-Subject Personalized Image Generation with Pairwise Subject-Consistency Rewards
Pith reviewed 2026-05-17 03:46 UTC · model grok-4.3
The pith
A synthetic data pipeline plus pairwise rewards lets single-subject image models handle multiple subjects with better consistency and prompt following.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A scalable pipeline first generates diverse multi-subject training data by prompting strong single-subject models, allowing those models to learn multi-image and multi-subject synthesis. A subsequent reinforcement learning stage then applies Pairwise Subject-Consistency Rewards together with general-purpose rewards to jointly improve subject identity preservation and text controllability, producing models that maintain consistency across multiple subjects while following complex prompts.
What carries the argument
The Pairwise Subject-Consistency Rewards, which measure and reward identity agreement between every pair of subjects within generated images during the reinforcement learning stage.
If this is right
- Single-subject models can be upgraded to multi-subject use without collecting new paired training data.
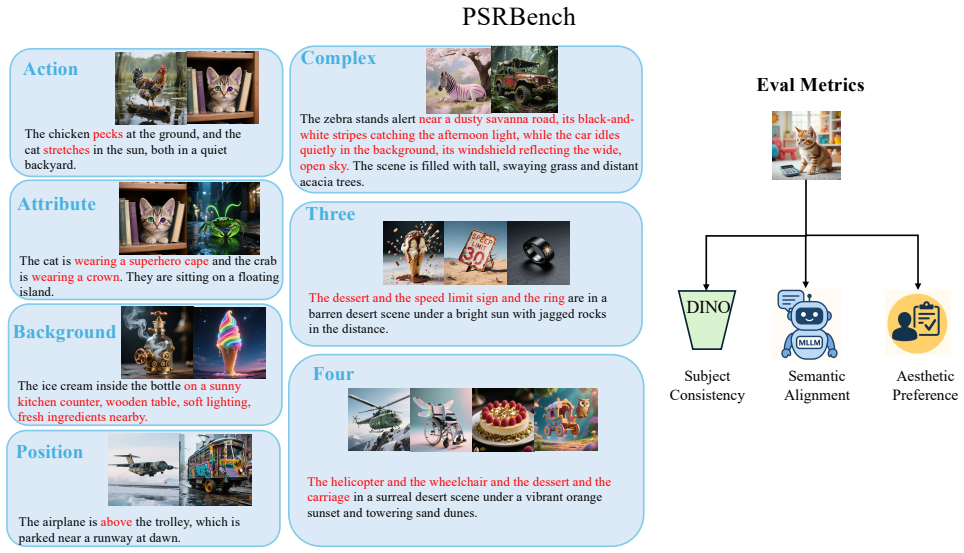
- The introduced benchmark supplies a standardized test covering seven subsets and three evaluation dimensions for future multi-subject methods.
- Adding general-purpose rewards alongside consistency rewards improves both identity fidelity and prompt adherence at the same time.
- The data-generation pipeline can be repeated at larger scale to keep improving performance as base single-subject models advance.
Where Pith is reading between the lines
- The same pairwise-reward idea could be tested on video or 3D generation where multiple subjects must stay consistent across frames or views.
- If the synthetic data proves robust, the method lowers the barrier to personalized generation for users who lack access to multi-person reference photos.
- Future extensions might combine these rewards with other objectives such as aesthetic or safety constraints without changing the core pipeline.
Load-bearing premise
Synthetic images produced by single-subject models contain enough variety and lack systematic biases that would prevent the rewards from teaching reliable multi-subject behavior.
What would settle it
Run the trained model on a held-out set of real photographs showing multiple distinct people and measure whether the generated subjects retain their identities across varied prompts and spatial arrangements.
Figures









read the original abstract
Personalized generation models for a single subject have demonstrated remarkable effectiveness, highlighting their significant potential. However, when extended to multiple subjects, existing models often exhibit degraded performance, particularly in maintaining subject consistency and adhering to textual prompts. We attribute these limitations to the absence of high-quality multi-subject datasets and refined post-training strategies. To address these challenges, we propose a scalable multi-subject data generation pipeline that leverages powerful single-subject generation models to construct diverse and high-quality multi-subject training data. Through this dataset, we first enable single-subject personalization models to acquire knowledge of synthesizing multi-image and multi-subject scenarios. Furthermore, to enhance both subject consistency and text controllability, we design a set of Pairwise Subject-Consistency Rewards and general-purpose rewards, which are incorporated into a refined reinforcement learning stage. To comprehensively evaluate multi-subject personalization, we introduce a new benchmark that assesses model performance using seven subsets across three dimensions. Extensive experiments demonstrate the effectiveness of our approach in advancing multi-subject personalized image generation. Github Link: https://github.com/wang-shulei/PSR
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to advance multi-subject personalized image generation by proposing a scalable data generation pipeline that uses existing single-subject models to synthesize diverse multi-subject training pairs, followed by a reinforcement learning stage incorporating Pairwise Subject-Consistency Rewards (plus general-purpose rewards) to improve subject consistency and text controllability. It also introduces a new benchmark consisting of seven subsets across three evaluation dimensions and reports that extensive experiments demonstrate the effectiveness of the overall approach.
Significance. If the central claims hold after addressing data-quality concerns, the work would be significant for the field: it offers a practical route to scale personalization beyond single subjects without requiring large-scale real multi-subject datasets, and the new benchmark could become a useful standard for future comparisons. The combination of synthetic data construction with reward-driven RL is a reasonable engineering contribution, though its impact depends on whether the synthetic pairs truly capture inter-subject relations without systematic artifacts.
major comments (3)
- [§3] §3 (Multi-Subject Data Generation Pipeline): The pipeline constructs training pairs by prompting single-subject models; the manuscript must include a quantitative audit (e.g., human preference scores or automated metrics on interaction fidelity, occlusion handling, and prompt adherence) comparing the synthetic pairs against real multi-subject photographs or artist-created references. Without this, the claim that the data is “diverse and high-quality” remains unverified and directly affects the reliability of the subsequent RL stage.
- [§5] §5 (Experiments and Benchmark): The abstract states that “extensive experiments demonstrate the effectiveness,” yet the provided description supplies no numerical results, baseline comparisons, or ablation tables. The manuscript should report concrete metrics (e.g., subject consistency scores, CLIP text alignment, FID) on the new benchmark’s seven subsets, together with statistical significance tests against at least two strong baselines (e.g., DreamBooth extended to multi-subject and a recent multi-subject method).
- [§4.2] §4.2 (Pairwise Subject-Consistency Rewards): The rewards are defined on generated images that themselves depend on the synthetic training distribution; if reward weights or filtering thresholds were tuned using the same evaluation sets used for final reporting, the reported gains risk circularity. The authors should state explicitly whether any hyper-parameters were selected on held-out data or via cross-validation and provide the exact reward formulation (including any learned components).
minor comments (2)
- The abstract mentions “seven subsets across three dimensions” but does not name the dimensions or list the subsets; this information should appear in the abstract or in a dedicated table in §5.
- Figure captions and axis labels in the experimental section should explicitly indicate which metric corresponds to which benchmark subset to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and have revised the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Multi-Subject Data Generation Pipeline): The pipeline constructs training pairs by prompting single-subject models; the manuscript must include a quantitative audit (e.g., human preference scores or automated metrics on interaction fidelity, occlusion handling, and prompt adherence) comparing the synthetic pairs against real multi-subject photographs or artist-created references. Without this, the claim that the data is “diverse and high-quality” remains unverified and directly affects the reliability of the subsequent RL stage.
Authors: We agree that an explicit quantitative audit of the synthetic data would strengthen the paper. In the revised version we add a dedicated subsection with both human preference scores (n=200 raters) and automated metrics (CLIP-based interaction fidelity, occlusion detection via segmentation, and prompt adherence) comparing our generated pairs against a held-out set of real multi-subject photographs and artist references. These results confirm that the synthetic pairs achieve comparable or superior fidelity on the targeted dimensions. revision: yes
-
Referee: [§5] §5 (Experiments and Benchmark): The abstract states that “extensive experiments demonstrate the effectiveness,” yet the provided description supplies no numerical results, baseline comparisons, or ablation tables. The manuscript should report concrete metrics (e.g., subject consistency scores, CLIP text alignment, FID) on the new benchmark’s seven subsets, together with statistical significance tests against at least two strong baselines (e.g., DreamBooth extended to multi-subject and a recent multi-subject method).
Authors: The full manuscript already contains numerical results, ablation tables, and comparisons on the seven benchmark subsets. To make these findings more prominent and directly responsive to the comment, we have added a consolidated results table reporting subject consistency, CLIP text alignment, and FID scores, together with paired t-test significance values against DreamBooth (multi-subject extension) and a recent multi-subject baseline. We also include the full per-subset breakdown. revision: yes
-
Referee: [§4.2] §4.2 (Pairwise Subject-Consistency Rewards): The rewards are defined on generated images that themselves depend on the synthetic training distribution; if reward weights or filtering thresholds were tuned using the same evaluation sets used for final reporting, the reported gains risk circularity. The authors should state explicitly whether any hyper-parameters were selected on held-out data or via cross-validation and provide the exact reward formulation (including any learned components).
Authors: We confirm that all reward weights and filtering thresholds were selected exclusively on a held-out validation split that is disjoint from both the training data and the final test benchmark. The exact mathematical formulation of the Pairwise Subject-Consistency Rewards (including the learned component) is already given in Section 4.2; we have added an explicit paragraph in the revised manuscript stating the data-separation protocol and cross-validation procedure to eliminate any ambiguity regarding circularity. revision: yes
Circularity Check
No circularity: derivation builds on external single-subject models with independent rewards and benchmark
full rationale
The paper describes generating multi-subject training data via existing single-subject models, then applying newly designed Pairwise Subject-Consistency Rewards within an RL stage, followed by evaluation on a new benchmark with seven subsets. No equations, definitions, or steps in the provided text reduce the claimed performance gains to fitted parameters on the same data, self-citations that bear the central load, or ansatzes smuggled from prior author work. The pipeline and rewards are presented as additive refinements rather than tautological redefinitions of the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward weights
axioms (1)
- domain assumption Single-subject personalization models can generate sufficiently diverse and unbiased multi-subject training images.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a scalable multi-subject data generation pipeline that leverages powerful single-subject generation models to construct diverse and high-quality multi-subject training data... Pairwise Subject-Consistency Rewards... GRPO training pipeline
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pairwise Subject-Consistency Reward (PSR)... R_PSR = 1/N sum f(I_i_dec, I_i_gt)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
UniCustom: Unified Visual Conditioning for Multi-Reference Image Generation
UniCustom fuses ViT and VAE features before VLM encoding and uses two-stage training plus slot-wise regularization to improve subject consistency in multi-reference diffusion-based image generation.
-
UniCustom: Unified Visual Conditioning for Multi-Reference Image Generation
A unified visual conditioning approach fuses semantic and appearance features before VLM processing, with two-stage training and slot-wise regularization, to improve consistency in multi-reference image generation.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 4, 6, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bowen Chen, Mengyi Zhao, Haomiao Sun, Li Chen, Xu Wang, Kang Du, and Xinglong Wu. Xverse: Consistent multi-subject control of identity and semantic attributes via dit modulation.arXiv preprint arXiv:2506.21416, 2025. 2, 3, 4, 6, 7, 1
-
[3]
Directly Fine-Tuning Diffusion Models on Differentiable Rewards
Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable re- wards.arXiv preprint arXiv:2309.17400, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
GoT-R1: Unleashing Reasoning Capability of MLLM for Visual Generation with Reinforcement Learning
Chengqi Duan, Rongyao Fang, Yuqing Wang, Kun Wang, Linjiang Huang, Xingyu Zeng, Hongsheng Li, and Xihui Liu. Got-r1: Unleashing reasoning capability of mllm for vi- sual generation with reinforcement learning.arXiv preprint arXiv:2505.17022, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Optimizing ddpm sampling with shortcut fine-tuning.arXiv preprint arXiv:2301.13362, 2023
Ying Fan and Kangwook Lee. Optimizing ddpm sampling with shortcut fine-tuning.arXiv preprint arXiv:2301.13362, 2023
-
[6]
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Moham- mad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffu- sion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023. 3
work page 2023
-
[7]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Zinan Guo, Yanze Wu, Chen Zhuowei, Peng Zhang, Qian He, et al. Pulid: Pure and lightning id customization via contrastive alignment.Advances in neural information pro- cessing systems, 37:36777–36804, 2024. 2
work page 2024
-
[10]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 6, 1
work page 2022
-
[11]
Realcustom: Narrowing real text word for real-time open-domain text-to-image customiza- tion
Mengqi Huang, Zhendong Mao, Mingcong Liu, Qian He, and Yongdong Zhang. Realcustom: Narrowing real text word for real-time open-domain text-to-image customiza- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 7476–7485,
-
[12]
Resolving multi-condition confusion for finetuning-free personalized image generation
Qihan Huang, Siming Fu, Jinlong Liu, Hao Jiang, Yipeng Yu, and Jie Song. Resolving multi-condition confusion for finetuning-free personalized image generation. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 3707–3714, 2025. 2
work page 2025
-
[13]
T2i-r1: Reinforcing image generation with collaborative semantic-level and token-level cot
Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, and Hong- sheng Li. T2i-r1: Reinforcing image generation with col- laborative semantic-level and token-level cot.arXiv preprint arXiv:2505.00703, 2025. 3
-
[14]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2023. 2
work page 1931
-
[15]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Photomaker: Customizing re- alistic human photos via stacked id embedding
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming- Ming Cheng, and Ying Shan. Photomaker: Customizing re- alistic human photos via stacked id embedding. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8640–8650, 2024. 2
work page 2024
-
[17]
Rich human feedback for text-to-image generation
Youwei Liang, Junfeng He, Gang Li, Peizhao Li, Arseniy Klimovskiy, Nicholas Carolan, Jiao Sun, Jordi Pont-Tuset, Sarah Young, Feng Yang, et al. Rich human feedback for text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19401–19411, 2024. 3
work page 2024
-
[18]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via on- line rl.arXiv preprint arXiv:2505.05470, 2025. 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[20]
Hpsv3: Towards wide-spectrum human preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum human preference score. arXiv preprint arXiv:2508.03789, 2025. 4, 6, 2
-
[21]
Zhendong Mao, Mengqi Huang, Fei Ding, Mingcong Liu, Qian He, and Yongdong Zhang. Realcustom++: Represent- ing images as real-word for real-time customization.arXiv preprint arXiv:2408.09744, 2024. 2
-
[22]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2, 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022. 3
work page 2022
-
[24]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Ground- ing multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, and Katerina Fragkiadaki. Aligning text-to-image diffusion models with reward backpropagation.arXiv preprint arXiv:2310.03739, 2023. 3
-
[26]
Video diffusion align- ment via reward gradients.arXiv preprint arXiv:2407.08737,
Mihir Prabhudesai, Russell Mendonca, Zheyang Qin, Kate- rina Fragkiadaki, and Deepak Pathak. Video diffusion align- ment via reward gradients.arXiv preprint arXiv:2407.08737,
-
[27]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 4
work page 2021
-
[28]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500– 22510, 2023. 2, 4, 1
work page 2023
-
[29]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 8430–8439, 2019. 4
work page 2019
-
[31]
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and uni- versal control for diffusion transformer.arXiv preprint arXiv:2411.15098, 2024. 2, 3, 5
-
[32]
Jiale Tao, Yanbing Zhang, Qixun Wang, Yiji Cheng, Hao- fan Wang, Xu Bai, Zhengguang Zhou, Ruihuang Li, Linqing Wang, Chunyu Wang, et al. Instantcharacter: Personalize any characters with a scalable diffusion transformer frame- work.arXiv preprint arXiv:2504.12395, 2025. 2
- [33]
-
[34]
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu. Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[35]
Xierui Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang. Ms-diffusion: Multi-subject zero-shot im- age personalization with layout guidance.arXiv preprint arXiv:2406.07209, 2024. 3, 6
-
[36]
Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
Yibin Wang, Zhimin Li, Yuhang Zang, Yujie Zhou, Jiazi Bu, Chunyu Wang, Qinglin Lu, Cheng Jin, and Jiaqi Wang. Pref-grpo: Pairwise preference reward-based grpo for sta- ble text-to-image reinforcement learning.arXiv preprint arXiv:2508.20751, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Elite: Encoding visual con- cepts into textual embeddings for customized text-to-image generation
Yuxiang Wei, Yabo Zhang, Zhilong Ji, Jinfeng Bai, Lei Zhang, and Wangmeng Zuo. Elite: Encoding visual con- cepts into textual embeddings for customized text-to-image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15943–15953, 2023. 2
work page 2023
-
[38]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 1, 3, 4, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025. 1, 3, 4, 6, 7, 8, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Shaojin Wu, Mengqi Huang, Wenxu Wu, Yufeng Cheng, Fei Ding, and Qian He. Less-to-more generalization: Unlocking more controllability by in-context generation.arXiv preprint arXiv:2504.02160, 2025. 1, 2, 3, 4, 5, 6, 7
-
[41]
Omnigen: Unified image genera- tion
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xin- grun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image genera- tion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13294–13304, 2025. 1
work page 2025
-
[42]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagere- ward: Learning and evaluating human preferences for text- to-image generation.Advances in Neural Information Pro- cessing Systems, 36:15903–15935, 2023. 3
work page 2023
-
[43]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shu- run Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation. arXiv preprint arXiv:2412.21059, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 4, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.