Knowledge Over Parameters: Evolving Smart Contract Vulnerability Detection
Pith reviewed 2026-07-03 11:05 UTC · model grok-4.3
The pith
Vulnerability detection in smart contracts can be achieved by evolving procedural knowledge from a handful of examples rather than updating model parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
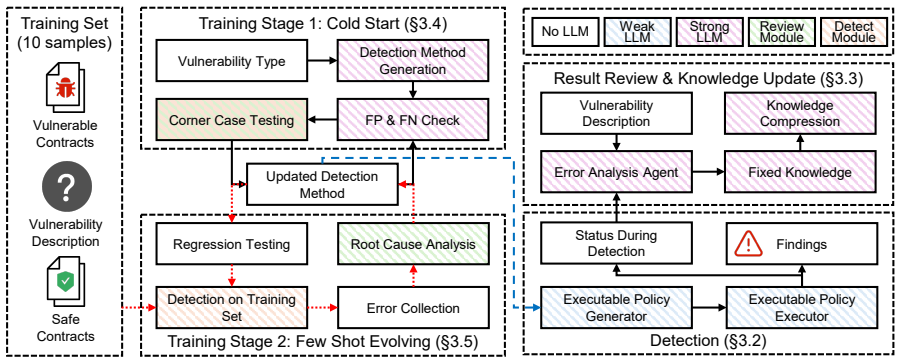
EvoVuln reformulates vulnerability detection as a procedural knowledge evolution problem, synthesizing and refining detection logic using only a minimal number of labeled samples through an Inversion of Control runtime for executable policies and a two-phase evolution pipeline.
What carries the argument
The Inversion of Control runtime that compiles detection rules into Executable Policies to decouple deterministic control flow from LLM semantic reasoning and produce dense diagnostic telemetry.
If this is right
- The evolved procedural knowledge enables a lightweight, low-cost model to surpass a much larger zero-shot model by 19 percentage points.
- The knowledge transfers to other LLMs without retraining.
- The one-time evolution cost is under $50.
- Detection achieves a 71% macro-average F1-score across five real-world vulnerability types, outperforming baselines.
Where Pith is reading between the lines
- This could be extended to other security tasks involving logic bugs in code where labeled data is scarce.
- The portability of the rules suggests they could be shared and improved collectively rather than recreated for each model.
- Testing on evolving smart contract languages or new bug types would show if the method stays effective over time.
Load-bearing premise
The LLM can refine the detection rules abductively from only five vulnerable and five safe examples per type without missing important edge cases or introducing biases.
What would settle it
Measuring performance on a new collection of contracts with the same vulnerabilities but different code structures and seeing if the F1-score falls below the baselines.
Figures


read the original abstract
Smart contract vulnerabilities are predominantly logic bugs whose detection requires structured, step-by-step procedural knowledge of attack patterns and contract semantics. Existing LLM-based methods struggle to generate this knowledge automatically: prompt-based methods rely on manually crafted detection rules, while fine-tuning requires massive labeled datasets that are inherently scarce in this domain. We present EvoVuln, an automated framework that reformulates vulnerability detection as a procedural knowledge evolution problem, synthesizing and refining detection logic using only a minimal number of labeled samples. To achieve this, EvoVuln introduces two key mechanisms. First, a Runtime with an Inversion of Control (IoC) architecture compiles detection rules into Executable Policies. This strictly decouples deterministic control flow from LLM semantic reasoning, ensuring faithful logical adherence and producing dense diagnostic telemetry for precise error localization. Second, a two-phase evolution pipeline refines the rule via abductive semantic debugging without any parameter updates: Cold Start bootstraps and stress-tests an initial rule using auto-synthesized corner cases; Few-Shot Evolving then grounds the policy in real-world semantics using only five vulnerable and five safe examples per vulnerability type. Evaluated across five real-world vulnerability types, EvoVuln achieves a 71% macro-average F1-score, outperforming all baselines. The evolved procedural knowledge is portable across models: it enables a lightweight, low-cost model to surpass a much larger zero-shot model by 19 percentage points, and transfers to other LLMs without retraining, at a one-time evolution cost under $50.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents EvoVuln, a framework that reformulates smart contract vulnerability detection as procedural knowledge evolution. It introduces an IoC runtime to compile rules into Executable Policies that decouple control flow from LLM reasoning, and a two-phase pipeline (Cold Start with auto-synthesized corner cases, followed by Few-Shot Evolving using exactly five vulnerable and five safe examples per type) that performs abductive refinement without parameter updates. The central empirical claim is a 71% macro-average F1 across five real-world vulnerability types, outperforming baselines, with the evolved policies being portable across LLMs (enabling a lightweight model to exceed a larger zero-shot model by 19 points) at a one-time cost under $50.
Significance. If the evaluation details and generalizability hold, the work offers a promising direction for data-scarce security domains by showing that portable, executable detection logic can be synthesized from minimal examples rather than large labeled sets or fine-tuning. The IoC architecture for producing dense diagnostics and ensuring logical fidelity is a concrete technical contribution that could be adopted more broadly. The low-cost portability result, if reproducible, would be practically relevant for blockchain auditing tools.
major comments (2)
- [§4 (Evaluation)] §4 (Evaluation) and abstract: the 71% macro F1, 19-point portability gain, and 'outperforming all baselines' claims are stated without naming the concrete baselines, describing dataset construction or train/test splits, reporting statistical significance, or detailing how the macro F1 was aggregated across the five vulnerability types; these omissions make the central performance claims unverifiable from the supplied information.
- [§3.2 (Few-Shot Evolving)] §3.2 (Few-Shot Evolving): the abductive refinement step grounds policies using only five vulnerable and five safe examples per type and relies on the IoC runtime for error localization, yet no coverage metrics, edge-case enumeration, or verification of test-set disjointness from the evolution examples are reported; if the LLM refinements systematically miss semantic interactions (e.g., reentrancy with particular storage layouts), the reported F1 and cross-model portability would not hold.
minor comments (2)
- [Abstract] Abstract: the phrase 'outperforming all baselines' should be accompanied by at least the names of the strongest baselines for immediate context.
- [§2] Notation: the term 'Executable Policies' is introduced without an explicit formal definition or pseudocode in the early sections; a short definition box would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on verifiability and robustness. We address each major point below and will revise the manuscript to improve clarity without altering the core claims or methodology.
read point-by-point responses
-
Referee: [§4 (Evaluation)] §4 (Evaluation) and abstract: the 71% macro F1, 19-point portability gain, and 'outperforming all baselines' claims are stated without naming the concrete baselines, describing dataset construction or train/test splits, reporting statistical significance, or detailing how the macro F1 was aggregated across the five vulnerability types; these omissions make the central performance claims unverifiable from the supplied information.
Authors: We agree that the abstract and §4 would benefit from greater explicitness to make the claims verifiable. In the revised version we will: (1) name the concrete baselines (zero-shot GPT-4, prior fine-tuned detectors, and static tools) in both the abstract and §4.2; (2) describe dataset construction, including sources, labeling process, and total contract counts; (3) specify the train/test splits and confirm they are disjoint; (4) report statistical significance via bootstrap resampling; and (5) state that macro F1 is the unweighted mean of the five per-type F1 scores. These additions will be placed in a new subsection of §4. revision: yes
-
Referee: [§3.2 (Few-Shot Evolving)] §3.2 (Few-Shot Evolving): the abductive refinement step grounds policies using only five vulnerable and five safe examples per type and relies on the IoC runtime for error localization, yet no coverage metrics, edge-case enumeration, or verification of test-set disjointness from the evolution examples are reported; if the LLM refinements systematically miss semantic interactions (e.g., reentrancy with particular storage layouts), the reported F1 and cross-model portability would not hold.
Authors: We acknowledge that explicit verification of disjointness and coverage would strengthen the section. In revision we will add: (a) confirmation that the five vulnerable and five safe examples per type are disjoint from the test set, (b) enumeration of the edge cases synthesized in the Cold Start phase together with coverage metrics, and (c) expanded discussion of how the IoC runtime's error localization addresses potential missed semantic interactions. We will also note this as a limitation in §5. The current empirical results and the runtime design provide supporting evidence, but we agree the additional reporting is warranted. revision: yes
Circularity Check
No circularity: empirical results rest on external test-set comparisons
full rationale
The paper describes an empirical two-phase evolution pipeline (Cold Start + Few-Shot Evolving) that produces Executable Policies from 5+5 labeled examples per vulnerability type, then reports macro F1 and cross-model portability on held-out real-world contracts. No equations, fitted parameters, or self-citations are invoked to derive the 71% F1 or 19-point gains; performance is measured by direct comparison against baselines on external data. The IoC runtime and abductive refinements are procedural mechanisms whose outputs are validated externally rather than defined by construction from the input examples. This is a standard self-contained empirical claim with no load-bearing reduction to internal fits or author prior work.
Axiom & Free-Parameter Ledger
free parameters (1)
- examples per vulnerability type =
5 + 5
axioms (1)
- domain assumption LLMs supplied with executable policies and diagnostic telemetry can perform abductive semantic debugging that improves rule quality
invented entities (1)
-
Executable Policies
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Defi hacks analysis - root cause analysis,
“Defi hacks analysis - root cause analysis,” https://web3sec.notion.site/ c582b99cd7a84be48d972ca2126a2a1f, 2026
2026
-
[2]
Gptscan: Detecting logic vulnerabilities in smart contracts by combining gpt with program analysis,
Y . Sun, D. Wu, Y . Xue, H. Liu, H. Wang, Z. Xu, X. Xie, and Y . Liu, “Gptscan: Detecting logic vulnerabilities in smart contracts by combining gpt with program analysis,” inProceedings of the IEEE/ACM 46th international conference on software engineering, 2024, pp. 1–13
2024
-
[3]
Propertygpt: Llm-driven formal verification of smart contracts through retrieval- augmented property generation,
Y . Liu, Y . Xue, D. Wu, Y . Sun, Y . Li, M. Shi, and Y . Liu, “Propertygpt: Llm-driven formal verification of smart contracts through retrieval- augmented property generation,” inProceedings of the Network and Distributed System Security Symposium (NDSS), 2025
2025
-
[4]
Smartguard: An llm- enhanced framework for smart contract vulnerability detection,
H. Ding, Y . Liu, X. Piao, H. Song, and Z. Ji, “Smartguard: An llm- enhanced framework for smart contract vulnerability detection,”Expert Systems with Applications, vol. 269, p. 126479, 2025
2025
-
[5]
Combining fine-tuning and llm-based agents for intuitive smart contract auditing with justifications,
W. Ma, D. Wu, Y . Sun, T. Wang, S. Liu, J. Zhang, Y . Xue, and Y . Liu, “Combining fine-tuning and llm-based agents for intuitive smart contract auditing with justifications,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 1742– 1754
2025
-
[6]
Agent4vul: multimodal llm agents for smart contract vulnerability detection,
W. Jie, W. Qiu, H. Yang, M. Guo, X. Huang, T. Lei, Q. Zhang, H. Zheng, and Z. Zheng, “Agent4vul: multimodal llm agents for smart contract vulnerability detection,”Science China Information Sciences, vol. 68, no. 6, p. 160101, 2025
2025
-
[7]
Smartinv: Multimodal learning for smart contract invariant inference,
S. J. Wang, K. Pei, and J. Yang, “Smartinv: Multimodal learning for smart contract invariant inference,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 2217–2235
2024
-
[8]
Re-task: Revisiting llm tasks from capability, skill, and knowledge perspectives,
Z. Wang, S. Zhao, Y . Wang, H. Huang, S. Xie, Y . Zhang, J. Shi, Z. Wang, H. Li, and J. Yan, “Re-task: Revisiting llm tasks from capability, skill, and knowledge perspectives,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 4925–4936
2025
-
[9]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Y . Jiang, D. Li, H. Deng, B. Ma, X. Wang, Q. Wang, and G. Yu, “Sok: Agentic skills–beyond tool use in llm agents,”arXiv preprint arXiv:2602.20867, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in neural informa- tion processing systems, vol. 36, pp. 68 539–68 551, 2023
2023
-
[11]
Slither: a static analysis framework for smart contracts,
J. Feist, G. Grieco, and A. Groce, “Slither: a static analysis framework for smart contracts,” inProceedings of the 2019 2nd IEEE/ACM in- ternational workshop on emerging trends in software engineering for blockchain (WETSEB). New York, NY , USA: IEEE, 2019, pp. 8–15
2019
-
[12]
Mando-guru: vulnerability detection for smart contract source code by heterogeneous graph embeddings,
H. H. Nguyen, N.-M. Nguyen, H.-P. Doan, Z. Ahmadi, T.-N. Doan, and L. Jiang, “Mando-guru: vulnerability detection for smart contract source code by heterogeneous graph embeddings,” inProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2022, pp. 1736–1740
2022
-
[13]
Sael: Leveraging large language models with adaptive mixture-of-experts for smart contract vulnerability detection,
L. Yu, S. Cheng, Z. Huang, J. Zhang, C. Shen, J. Lu, L. Yang, F. Zhang, and J. Ma, “Sael: Leveraging large language models with adaptive mixture-of-experts for smart contract vulnerability detection,” in2025 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2025, pp. 61–72
2025
-
[14]
Gpt-5.2,
“Gpt-5.2,” https://developers.openai.com/api/docs/models/gpt-5.2, 2026
2026
-
[15]
Gpt-5 nano,
“Gpt-5 nano,” https://developers.openai.com/api/docs/models/ gpt-5-nano, 2026
2026
-
[16]
Claude code,
Anthropic, “Claude code,” https://www.anthropic.com/claude-code, 2025
2025
-
[17]
OpenAI, “Codex,” https://openai.com/codex/, 2025
2025
-
[18]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[19]
Faithful logical reasoning via symbolic chain-of-thought,
J. Xu, H. Fei, L. Pan, Q. Liu, M.-L. Lee, and W. Hsu, “Faithful logical reasoning via symbolic chain-of-thought,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[20]
Reasoning Theater: Disentangling Model Beliefs from Chain-of-Thought
S. Boppana, A. Ma, M. Loeffler, R. Sarfati, E. Bigelow, A. Geiger, O. Lewis, and J. Merullo, “Reasoning theater: Disentangling model beliefs from chain-of-thought,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.05488
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks,
W. Chen, X. Ma, X. Wang, and W. W. Cohen, “Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks,”Transactions on Machine Learning Research, 2023
2023
-
[22]
Y . Nong, M. Aldeen, L. Cheng, H. Hu, F. Chen, and H. Cai, “Chain-of- thought prompting of large language models for discovering and fixing software vulnerabilities,”arXiv preprint arXiv:2402.17230, 2024
-
[23]
Preemptive answer “attacks
R. Xu, Z. Qi, and W. Xu, “Preemptive answer “attacks” on chain-of- thought reasoning,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 14 708–14 726
2024
-
[24]
Towards combining chain-of-thought and code static analysis for buffer overflow vulnerability detection,
Y . Huang, Y . Chen, J. Cai, J. Wu, X. Chen, P. Shen, and L. Yun, “Towards combining chain-of-thought and code static analysis for buffer overflow vulnerability detection,”Software Quality Journal, vol. 34, no. 1, p. 2, 2026
2026
-
[25]
Towards explainable vulnerability detection with large language models,
Q. Mao, Z. Li, X. Hu, K. Liu, X. Xia, and J. Sun, “Towards explainable vulnerability detection with large language models,”IEEE Transactions on Software Engineering, 2025
2025
-
[26]
Large language model for vulnerability detection: Emerging results and future directions,
X. Zhou, T. Zhang, and D. Lo, “Large language model for vulnerability detection: Emerging results and future directions,” inProceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineer- ing: New Ideas and Emerging Results, 2024, pp. 47–51
2024
-
[27]
5gpt: 5g vulnerability detection by combining zero-shot capabilities of gpt-4 with domain aware strategies through prompt engineering,
A. Shahriar, S. J. Hisham, K. A. Rahman, M. R. Islam, M. S. Hossain, R.-H. Hwang, and Y .-D. Lin, “5gpt: 5g vulnerability detection by combining zero-shot capabilities of gpt-4 with domain aware strategies through prompt engineering,”IEEE Transactions on Information Foren- sics and Security, 2025
2025
-
[28]
Examining zero-shot vulnerability repair with large language models,
H. Pearce, B. Tan, B. Ahmad, R. Karri, and B. Dolan-Gavitt, “Examining zero-shot vulnerability repair with large language models,” in2023 IEEE symposium on security and privacy (SP). IEEE, 2023, pp. 2339–2356
2023
-
[29]
Hybrid language processor fuzzing via llm-based constraint solving,
Y . Yang, S. Yao, J. Chen, and W. Lee, “Hybrid language processor fuzzing via llm-based constraint solving,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 6299–6318
2025
-
[30]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” February
-
[31]
Available: https://qwen.ai/blog?id=qwen3.5
[Online]. Available: https://qwen.ai/blog?id=qwen3.5
-
[32]
Minimax m2.5 sota in coding and agent, designed for agent universe,
M. AI, “Minimax m2.5 sota in coding and agent, designed for agent universe,” https://www.minimax.io/models/text, 2026
2026
-
[33]
The unified interface for llms,
“The unified interface for llms,” https://openrouter.ai/, 2026
2026
-
[34]
Mythril,
“Mythril,” https://github.com/Consensys/mythril, 2026
2026
-
[35]
Securify: Practical security analysis of smart contracts,
P. Tsankov, A. Dan, D. Drachsler-Cohen, A. Gervais, F. Buenzli, and M. Vechev, “Securify: Practical security analysis of smart contracts,” inProceedings of the 2018 ACM SIGSAC conference on computer and communications security (CCS). New York, NY , USA: ACM, 2018, pp. 67–82
2018
-
[36]
Osiris: Hunting for integer bugs in ethereum smart contracts,
C. F. Torres, J. Sch ¨utte, and R. State, “Osiris: Hunting for integer bugs in ethereum smart contracts,” inProceedings of the 2018 34th annual computer security applications conference (ACSAC). New York, NY , USA: ACM, 2018, pp. 664–676
2018
-
[37]
Manticore: A user-friendly symbolic execution framework for binaries and smart contracts,
M. Mossberg, F. Manzano, E. Hennenfent, A. Groce, G. Grieco, J. Feist, T. Brunson, and A. Dinaburg, “Manticore: A user-friendly symbolic execution framework for binaries and smart contracts,” inProceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). New York, NY , USA: IEEE, 2019, pp. 1186–1189
2019
-
[38]
Making smart contracts smarter,
L. Luu, D.-H. Chu, H. Olickel, P. Saxena, and A. Hobor, “Making smart contracts smarter,” inProceedings of the 2016 ACM SIGSAC conference on computer and communications security, 2016, pp. 254–269
2016
-
[39]
Efficiently detecting reentrancy vulnerabilities in complex smart contracts,
Z. Wang, J. Chen, Y . Wang, Y . Zhang, W. Zhang, and Z. Zheng, “Efficiently detecting reentrancy vulnerabilities in complex smart contracts,” vol. 1. [Online]. Available: https://doi.org/10.1145/3643734 11
-
[40]
Y . Xue, M. Ma, Y . Lin, Y . Sui, J. Ye, and T. Peng, “Cross-contract static analysis for detecting practical reentrancy vulnerabilities in smart contracts,” inProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering, ser. Ase ’20. Asso- ciation for Computing Machinery, pp. 1029–1040. [Online]. Available: https://doi-org...
-
[41]
Z. Zheng, N. Zhang, J. Su, Z. Zhong, M. Ye, and J. Chen, “Turn the rudder: A beacon of reentrancy detection for smart contracts on ethereum,” inProceedings of the 45th International Conference on Software Engineering, ser. Icse ’23. IEEE Press, pp. 295–306. [Online]. Available: https://doi.org/10.1109/ICSE48619.2023.00036
-
[42]
Clairvoyance: Cross- contract static analysis for detecting practical reentrancy vulnerabilities in smart contracts,
J. Ye, M. Ma, Y . Lin, Y . Sui, and Y . Xue, “Clairvoyance: Cross- contract static analysis for detecting practical reentrancy vulnerabilities in smart contracts,” inProceedings of the ACM/IEEE 42nd International Conference on Software Engineering: Companion Proceedings, 2020, pp. 274–275
2020
-
[43]
Reentrancy vulnerability detection and localization: A deep learning based two-phase approach,
Z. Zhang, Y . Lei, M. Yan, Y . Yu, J. Chen, S. Wang, and X. Mao, “Reentrancy vulnerability detection and localization: A deep learning based two-phase approach,” inProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, 2022, pp. 1–13
2022
-
[44]
Reguard: finding reentrancy bugs in smart contracts,
C. Liu, H. Liu, Z. Cao, Z. Chen, B. Chen, and B. Roscoe, “Reguard: finding reentrancy bugs in smart contracts,” inProceedings of the 40th International Conference on Software Engineering: Companion Proceeedings, ser. ICSE ’18. New York, NY , USA: Association for Computing Machinery, 2018, p. 65–68. [Online]. Available: https://doi.org/10.1145/3183440.3183495
-
[45]
Silence false alarms: Identifying anti-reentrancy patterns on ethereum to refine smart contract reentrancy detection,
Q. Song, H. Huang, X. Jia, Y . Xie, and J. Cao, “Silence false alarms: Identifying anti-reentrancy patterns on ethereum to refine smart contract reentrancy detection,” inNDSS, 2025
2025
-
[46]
SAIL- FISH: Vetting smart contract state-inconsistency bugs in seconds,
P. Bose, D. Das, Y . Chen, Y . Feng, C. Kruegel, and G. Vigna, “SAIL- FISH: Vetting smart contract state-inconsistency bugs in seconds,” in 2022 IEEE Symposium on Security and Privacy (SP), pp. 161–178
2022
-
[47]
Achecker: Statically de- tecting smart contract access control vulnerabilities,
A. Ghaleb, J. Rubin, and K. Pattabiraman, “Achecker: Statically de- tecting smart contract access control vulnerabilities,” inProceedings of the 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), Melbourne, Australia, May 2023, p. 945–956
2023
-
[48]
Beyond “protected
Y . Fang, D. Wu, X. Yi, S. Wang, Y . Chen, M. Chen, Y . Liu, and L. Jiang, “Beyond “protected” and “private”: An empirical security analysis of custom function modifiers in smart contracts,” inProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, New York, NY , USA, 2023, p. 1157–1168
2023
-
[49]
Finding permission bugs in smart contracts with role mining,
Y . Liu, Y . Li, S.-W. Lin, and C. Artho, “Finding permission bugs in smart contracts with role mining,” inProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA
-
[50]
New York, NY , USA: Association for Computing Machinery, 2022, p. 716–727
2022
-
[51]
Prettysmart: Detecting permission re-delegation vulnerability for token behaviors in smart contracts,
Z. Zhong, Z. Zheng, H.-N. Dai, Q. Xue, J. Chen, and Y . Nan, “Prettysmart: Detecting permission re-delegation vulnerability for token behaviors in smart contracts,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ser. ICSE ’24. New York, NY , USA: Association for Computing Machinery, 2024
2024
-
[52]
Actaint: Agent- based taint analysis for access control vulnerabilities in smart contracts,
H. Lin, Z. Gao, J. Chen, X. Chen, X. Yang, and L. Bao, “Actaint: Agent- based taint analysis for access control vulnerabilities in smart contracts,” inProceedings of the 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). New York, NY , USA: IEEE, 2025, pp. 2555–2567
2025
-
[53]
Have We Solved Access Control Vulnerability Detection in Smart Contracts? A Benchmark Study,
H. Liu, D. Wu, Y . Sun, S. Wang, Y . Liu, and Y . Chen, “Have We Solved Access Control Vulnerability Detection in Smart Contracts? A Benchmark Study,” inProceedings of the 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). New York, NY , USA: IEEE, 2025, pp. 1995–2007
2025
-
[54]
Defitainter: Detect- ing price manipulation vulnerabilities in defi protocols,
Q. Kong, J. Chen, Y . Wang, Z. Jiang, and Z. Zheng, “Defitainter: Detect- ing price manipulation vulnerabilities in defi protocols,” inProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2023, pp. 1144–1156
2023
-
[55]
De- firanger: Detecting defi price manipulation attacks,
S. Wu, Z. Yu, D. Wang, Y . Zhou, L. Wu, H. Wang, and X. Yuan, “De- firanger: Detecting defi price manipulation attacks,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 4, pp. 4147–4161, 2023
2023
-
[56]
Toward automated detecting unanticipated price feed in smart contract,
Y . Mo, J. Chen, Y . Wang, and Z. Zheng, “Toward automated detecting unanticipated price feed in smart contract,” inProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2023, pp. 1257–1268
2023
-
[57]
Cobra: interaction-aware bytecode- level vulnerability detector for smart contracts,
W. Li, X. Li, Z. Li, and Y . Zhang, “Cobra: interaction-aware bytecode- level vulnerability detector for smart contracts,” inProceedings of the 39th IEEE/ACM international conference on automated software engineering, 2024, pp. 1358–1369
2024
-
[58]
A novel method for vulnerability detection based on fusion and hyperbolic neural network graphs,
X. Li, A. Bhattacharjya, Q. Li, M. Zhou, R. Wisniewski, and G. Bazydło, “A novel method for vulnerability detection based on fusion and hyperbolic neural network graphs,”IEEE Transactions on Software Engineering, 2026
2026
-
[59]
When chatgpt meets smart contract vulnerability detec- tion: How far are we?
C. Chen, J. Su, J. Chen, Y . Wang, T. Bi, J. Yu, Y . Wang, X. Lin, T. Chen, and Z. Zheng, “When chatgpt meets smart contract vulnerability detec- tion: How far are we?”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 4, pp. 1–30, 2025
2025
-
[60]
Do you still need a manual smart contract audit?
I. David, L. Zhou, K. Qin, D. Song, L. Cavallaro, and A. Gervais, “Do you still need a manual smart contract audit?”arXiv preprint arXiv:2306.12338, 2023
-
[61]
Smart-llama-dpo: Reinforced large language model for explainable smart contract vulnerability detection,
L. Yu, Z. Huang, H. Yuan, S. Cheng, L. Yang, F. Zhang, C. Shen, J. Ma, J. Zhang, J. Luet al., “Smart-llama-dpo: Reinforced large language model for explainable smart contract vulnerability detection,” Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 182–205, 2025
2025
-
[62]
Numscout: Unveiling numerical defects in smart contracts using llm-pruning symbolic execution,
J. Chen, Z. Shao, S. Yang, Y . Shen, Y . Wang, T. Chen, Z. Shan, and Z. Zheng, “Numscout: Unveiling numerical defects in smart contracts using llm-pruning symbolic execution,”IEEE Transactions on Software Engineering, 2025
2025
-
[63]
Self-refine: Iter- ative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yanget al., “Self-refine: Iter- ative refinement with self-feedback,”Advances in neural information processing systems, vol. 36, pp. 46 534–46 594, 2023
2023
-
[64]
Re- flexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Re- flexion: Language agents with verbal reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 8634–8652, 2023. 12
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.