Learning Data Augmentation Strategies for Object Detection
Pith reviewed 2026-05-25 15:34 UTC · model grok-4.3
The pith
A learned data augmentation policy improves object detection accuracy by more than 2.3 mAP on COCO and transfers unchanged to other datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experiments on the COCO dataset indicate that an optimized data augmentation policy improves detection accuracy by more than +2.3 mAP, and allow a single inference model to achieve a state-of-the-art accuracy of 50.7 mAP. Importantly, the best policy found on COCO may be transferred unchanged to other detection datasets and models to improve predictive accuracy. For example, the best augmentation policy identified with COCO improves a strong baseline on PASCAL-VOC by +2.7 mAP. Our results also reveal that a learned augmentation policy is superior to state-of-the-art architecture regularization methods for object detection.
What carries the argument
A learned augmentation policy: a collection of image transformations and their parameters discovered by automated search to maximize detection performance on a given dataset.
If this is right
- A single inference model reaches 50.7 mAP on COCO.
- The identical policy raises accuracy by 2.7 mAP on PASCAL-VOC without retraining or retuning.
- Learned policies outperform architecture regularization methods on detection tasks.
- Policies discovered on one detection dataset improve performance on other detection datasets and models.
Where Pith is reading between the lines
- The transfer result suggests that the policy captures dataset-agnostic invariances that could apply to additional detection benchmarks.
- Because the policy changes only training data, it can be combined with any existing detection architecture without altering inference.
- The approach may lower the annotation cost for new detection tasks by extracting more signal from existing labeled images.
Load-bearing premise
The reported accuracy gains are produced by the learned augmentation policy itself rather than by differences in training schedule, optimizer, or random seed.
What would settle it
Reproduce the COCO experiments while holding training schedule, optimizer, and random seed fixed and differ only in the use of the learned policy versus the baseline augmentations; the mAP gap must disappear if the policy is not the cause.
Figures



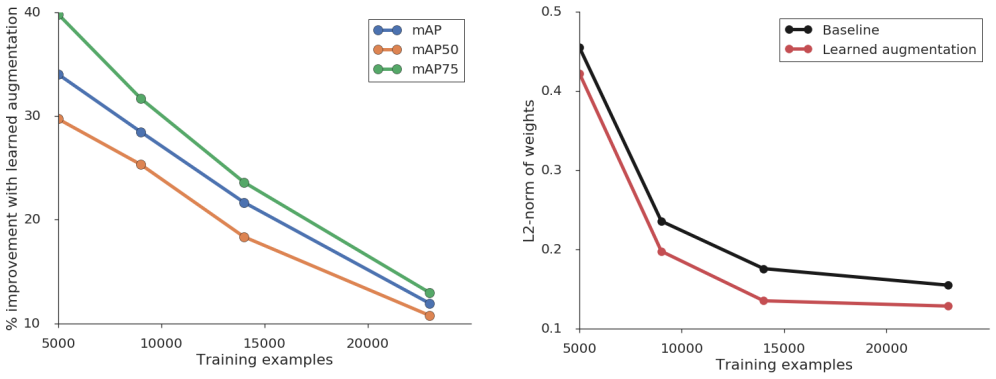
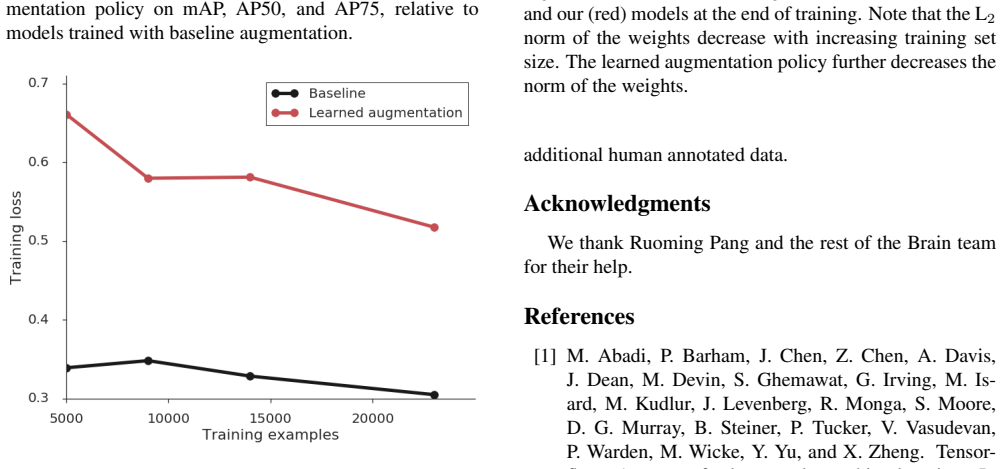
read the original abstract
Data augmentation is a critical component of training deep learning models. Although data augmentation has been shown to significantly improve image classification, its potential has not been thoroughly investigated for object detection. Given the additional cost for annotating images for object detection, data augmentation may be of even greater importance for this computer vision task. In this work, we study the impact of data augmentation on object detection. We first demonstrate that data augmentation operations borrowed from image classification may be helpful for training detection models, but the improvement is limited. Thus, we investigate how learned, specialized data augmentation policies improve generalization performance for detection models. Importantly, these augmentation policies only affect training and leave a trained model unchanged during evaluation. Experiments on the COCO dataset indicate that an optimized data augmentation policy improves detection accuracy by more than +2.3 mAP, and allow a single inference model to achieve a state-of-the-art accuracy of 50.7 mAP. Importantly, the best policy found on COCO may be transferred unchanged to other detection datasets and models to improve predictive accuracy. For example, the best augmentation policy identified with COCO improves a strong baseline on PASCAL-VOC by +2.7 mAP. Our results also reveal that a learned augmentation policy is superior to state-of-the-art architecture regularization methods for object detection, even when considering strong baselines. Code for training with the learned policy is available online at https://github.com/tensorflow/tpu/tree/master/models/official/detection
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies data augmentation for object detection, first showing that classification-derived operations give limited gains, then proposing to learn specialized augmentation policies via search. On COCO this yields >+2.3 mAP (reaching 50.7 mAP SOTA with one model); the best COCO policy transfers unchanged to improve a strong PASCAL-VOC baseline by +2.7 mAP and outperforms architecture regularization methods.
Significance. If the reported mAP gains are shown to be caused by the learned policy rather than differences in training schedule, optimizer, or seeds, the work would be significant: it supplies the first demonstration of transferable, detection-specific augmentation policies and supplies reproducible code, strengthening the case that learned augmentation is a high-leverage, low-cost lever for detection.
major comments (2)
- [Abstract / Experimental results] The abstract and experimental description supply no explicit statement that the reported baseline and policy-augmented runs share identical optimizer, learning-rate schedule, number of epochs, data-loader settings, and random seeds. Without this control the +2.3 mAP delta cannot be isolated to the augmentation policy.
- [Methods / Policy search] No information is given on the search procedure itself (search space size, number of trials, validation-set usage during policy search, or whether the final reported numbers use the same validation split). This information is load-bearing for assessing whether the headline gains are statistically reliable.
minor comments (1)
- [Abstract] The GitHub link is provided but the manuscript does not state the exact commit or configuration files used to reproduce the 50.7 mAP result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of experimental clarity and reproducibility. We respond to each major comment below and will revise the manuscript to incorporate clarifications.
read point-by-point responses
-
Referee: [Abstract / Experimental results] The abstract and experimental description supply no explicit statement that the reported baseline and policy-augmented runs share identical optimizer, learning-rate schedule, number of epochs, data-loader settings, and random seeds. Without this control the +2.3 mAP delta cannot be isolated to the augmentation policy.
Authors: We agree that an explicit statement would improve clarity. All experiments in the paper use identical training configurations (optimizer, learning-rate schedule, number of epochs, data-loader settings, and random seeds), with the only difference being the data augmentation policy. This is reflected in the released code at the provided GitHub link. We will add an explicit statement to the abstract and experimental results section confirming that all other factors are held constant across baseline and policy-augmented runs. revision: yes
-
Referee: [Methods / Policy search] No information is given on the search procedure itself (search space size, number of trials, validation-set usage during policy search, or whether the final reported numbers use the same validation split). This information is load-bearing for assessing whether the headline gains are statistically reliable.
Authors: We acknowledge that the methods section would benefit from expanded details on the search procedure. The policy search is conducted on a held-out validation split distinct from the test set used for final COCO and transfer results. We will revise the methods section to specify the search space size, number of trials performed, and confirmation that the validation split for search is separate from the evaluation test split. revision: yes
Circularity Check
No circularity: empirical gains validated on held-out COCO test set and transferred to independent VOC dataset
full rationale
The paper reports empirical improvements from searched augmentation policies, measured on held-out COCO test data (+2.3 mAP) and transferred unchanged to PASCAL-VOC (+2.7 mAP). No derivation chain, equations, or self-citations reduce any claimed result to a fitted parameter or input by construction. The central claims rest on standard train/test splits and cross-dataset transfer rather than self-definition or load-bearing self-citation.
Axiom & Free-Parameter Ledger
free parameters (1)
- augmentation policy
axioms (1)
- domain assumption Standard i.i.d. supervised learning assumptions hold for the COCO and PASCAL-VOC image distributions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We treat data augmentation search as a discrete optimization problem... RNN controller... PPO... 22 operations... K=5 sub-policies, N=2 operations...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on the COCO dataset indicate that an optimized data augmentation policy improves detection accuracy by more than +2.3 mAP
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Is- ard, M. Kudlur, J. Levenberg, R. Monga, S. Moore, D. G. Murray, B. Steiner, P. Tucker, V . Vasudevan, P. Warden, M. Wicke, Y . Yu, and X. Zheng. Tensor- flow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Conference on Oper- ati...
work page 2016
-
[2]
Data Augmentation Generative Adversarial Networks
A. Antoniou, A. Storkey, and H. Edwards. Data augmentation generative adversarial networks. arXiv preprint arXiv:1711.04340, 2017. 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
H. S. Baird. Document image defect models. In Structured Document Image Analysis, pages 546–556. Springer, 1992. 1
work page 1992
-
[4]
D. Ciregan, U. Meier, and J. Schmidhuber. Multi- column deep neural networks for image classifica- tion. In Proceedings of IEEE Conference on Com- puter Vision and Pattern Recognition , pages 3642–
-
[5]
E. D. Cubuk, B. Zoph, D. Mane, V . Vasudevan, and Q. V . Le. Autoaugment: Learning augmentation poli- cies from data. arXiv preprint arXiv:1805.09501 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
E. D. Cubuk, B. Zoph, S. S. Schoenholz, and Q. V . Le. Intriguing properties of adversarial examples. arXiv preprint arXiv:1711.02846, 2017. 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
J. Dai, K. He, and J. Sun. Instance-aware semantic segmentation via multi-task network cascades. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3150–3158, 2016. 8
work page 2016
-
[8]
Dataset Augmentation in Feature Space
T. DeVries and G. W. Taylor. Dataset augmentation in feature space. arXiv preprint arXiv:1702.05538, 2017. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Improved Regularization of Convolutional Neural Networks with Cutout
T. DeVries and G. W. Taylor. Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017. 2, 13
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
D. Dwibedi, I. Misra, and M. Hebert. Cut, paste and learn: Surprisingly easy synthesis for instance detec- tion. In Proceedings of the IEEE International Con- ference on Computer Vision, pages 1301–1310, 2017. 2
work page 2017
-
[11]
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vi- sion, 88(2):303–338, 2010. 6, 7
work page 2010
-
[12]
N. Ford, J. Gilmer, N. Carlini, and D. Cubuk. Adver- sarial examples are a natural consequence of test error in noise. arXiv preprint arXiv:1901.10513, 2019. 2
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[13]
G. Ghiasi, T.-Y . Lin, and Q. V . Le. DropBlock: A regularization method for convolutional networks. In Advances in Neural Information Processing Systems , pages 10750–10760, 2018. 2, 5, 7
work page 2018
-
[14]
G. Ghiasi, T.-Y . Lin, R. Pang, and Q. V . Le. NAS-FPN: Learning scalable feature pyramid architecture for ob- ject detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 5, 7
work page 2019
-
[15]
R. Girshick, I. Radosavovic, G. Gkioxari, P. Doll ´ar, and K. He. Detectron, 2018. 2
work page 2018
-
[16]
K. He, X. Zhang, S. Ren, and J. Sun. Deep resid- ual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. 1, 4
work page 2016
-
[17]
D. Ho, E. Liang, I. Stoica, P. Abbeel, and X. Chen. Population based augmentation: Efficient learning of augmentation policy schedules. arXiv preprint arXiv:1905.05393, 2019. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[18]
J. Hu, L. Shen, and G. Sun. Squeeze-and-excitation networks. arXiv preprint arXiv:1709.01507, 2017. 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
J. Huang, V . Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y . Song, S. Guadar- rama, et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7310–7311, 2017. 6
work page 2017
-
[20]
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, et al. In-datacenter performance analysis of a tensor processing unit. In 2017 ACM/IEEE 44th Annual International Symposium on Computer Archi- tecture (ISCA), pages 1–12. IEEE, 2017. 4, 5
work page 2017
-
[21]
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Im- agenet classification with deep convolutional neural networks. In Advances in Neural Information Process- ing Systems, 2012. 1, 2
work page 2012
- [22]
- [23]
-
[24]
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vi- sion, pages 2980–2988, 2017. 1, 4, 5
work page 2017
-
[25]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick. Microsoft coco: Common objects in context. In European con- ference on computer vision, pages 740–755. Springer,
-
[26]
C. Liu, B. Zoph, J. Shlens, W. Hua, L.-J. Li, L. Fei- Fei, A. Yuille, J. Huang, and K. Murphy. Pro- gressive neural architecture search. arXiv preprint arXiv:1712.00559, 2017. 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y . Fu, and A. C. Berg. Ssd: Single shot multibox detector. In European conference on computer vision, pages 21–37. Springer, 2016. 2
work page 2016
-
[28]
J. Long, E. Shelhamer, and T. Darrell. Fully convo- lutional networks for semantic segmentation. In Pro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015. 8
work page 2015
-
[29]
R. G. Lopes, D. Yin, B. Poole, J. Gilmer, and E. D. Cubuk. Improving robustness without sacrificing accuracy with patch gaussian augmentation. arXiv preprint arXiv:1906.02611, 2019. 2
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[30]
SGDR: Stochastic Gradient Descent with Warm Restarts
I. Loshchilov and F. Hutter. SGDR: Stochastic gra- dient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016. 4
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
S. Mun, S. Park, D. K. Han, and H. Ko. Generative adversarial network based acoustic scene training set augmentation and selection using svm hyper-plane. In Detection and Classification of Acoustic Scenes and Events Workshop, 2017. 1
work page 2017
-
[32]
C. Peng, T. Xiao, Z. Li, Y . Jiang, X. Zhang, K. Jia, G. Yu, and J. Sun. Megdet: A large mini-batch object detector. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018. 6, 7
work page 2018
-
[33]
The Effectiveness of Data Augmentation in Image Classification using Deep Learning
L. Perez and J. Wang. The effectiveness of data aug- mentation in image classification using deep learning. arXiv preprint arXiv:1712.04621, 2017. 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
P. O. Pinheiro, T.-Y . Lin, R. Collobert, and P. Doll ´ar. Learning to refine object segments. InEuropean Con- ference on Computer Vision , pages 75–91. Springer,
-
[35]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 652–660, 2017. 8
work page 2017
-
[36]
C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Pro- cessing Systems, pages 5099–5108, 2017. 8
work page 2017
-
[37]
A. J. Ratner, H. Ehrenberg, Z. Hussain, J. Dunnmon, and C. R ´e. Learning to compose domain-specific transformations for data augmentation. InAdvances in Neural Information Processing Systems, pages 3239– 3249, 2017. 1, 2
work page 2017
-
[38]
E. Real, A. Aggarwal, Y . Huang, and Q. V . Le. Reg- ularized evolution for image classifier architecture search. In Thirty-Third AAAI Conference on Artificial Intelligence, 2019. 4, 5, 7
work page 2019
-
[39]
S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region pro- posal networks. In Advances in neural information processing systems, pages 91–99, 2015. 6, 7
work page 2015
-
[40]
I. Sato, H. Nishimura, and K. Yokoi. Apac: Aug- mented pattern classification with neural networks. arXiv preprint arXiv:1505.03229, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017. 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
P. Y . Simard, D. Steinkraus, J. C. Platt, et al. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of Interna- tional Conference on Document Analysis and Recog- nition, 2003. 1, 2
work page 2003
-
[43]
L. Sixt, B. Wild, and T. Landgraf. Rendergan: Generating realistic labeled data. arXiv preprint arXiv:1611.01331, 2016. 1
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[44]
C. Szegedy, W. Liu, Y . Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V . Vanhoucke, A. Rabinovich, et al. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), 2015. 1
work page 2015
-
[45]
T. Tran, T. Pham, G. Carneiro, L. Palmer, and I. Reid. A bayesian data augmentation approach for learning deep models. In Advances in Neural Information Pro- cessing Systems, pages 2794–2803, 2017. 1, 2
work page 2017
-
[46]
Manifold Mixup: Better Representations by Interpolating Hidden States
V . Verma, A. Lamb, C. Beckham, A. Courville, I. Mitliagkis, and Y . Bengio. Manifold mixup: En- couraging meaningful on-manifold interpolation as a regularizer. arXiv preprint arXiv:1806.05236, 2018. 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
L. Wan, M. Zeiler, S. Zhang, Y . Le Cun, and R. Fer- gus. Regularization of neural networks using dropcon- nect. In International Conference on Machine Learn- ing, pages 1058–1066, 2013. 2
work page 2013
-
[48]
X. Wang, A. Shrivastava, and A. Gupta. A-fast- rcnn: Hard positive generation via adversary for ob- ject detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 2606–2615, 2017. 2
work page 2017
-
[49]
T. Yang, X. Zhang, Z. Li, W. Zhang, and J. Sun. Metaanchor: Learning to detect objects with cus- tomized anchors. In Advances in Neural Information Processing Systems, pages 318–328, 2018. 6
work page 2018
- [50]
-
[51]
S. Zagoruyko and N. Komodakis. Wide residual net- works. In British Machine Vision Conference, 2016. 2
work page 2016
-
[52]
mixup: Beyond Empirical Risk Minimization
H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017. 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
Random Erasing Data Augmentation
Z. Zhong, L. Zheng, G. Kang, S. Li, and Y . Yang. Random erasing data augmentation. arXiv preprint arXiv:1708.04896, 2017. 2, 13
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
X. Zhu, Y . Liu, Z. Qin, and J. Li. Data augmentation in emotion classification using generative adversarial networks. arXiv preprint arXiv:1711.00648, 2017. 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
B. Zoph and Q. V . Le. Neural architecture search with reinforcement learning. In International Conference on Learning Representations, 2017. 4
work page 2017
-
[56]
B. Zoph, V . Vasudevan, J. Shlens, and Q. V . Le. Learning transferable architectures for scalable image recognition. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2017. 1, 4 A. Appendix Operation Name Description Range of magnitudes ShearX(Y) Shear the image and the corners of the bounding boxes along the horizontal (verti...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.