Supervise Thyself: Examining Self-Supervised Representations in Interactive Environments
Pith reviewed 2026-05-25 14:29 UTC · model grok-4.3
The pith
The usefulness of self-supervised representations in games depends heavily on the environment's visuals and dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our results show that the utility of the representations is highly dependent on the visuals and dynamics of the environment.
What carries the argument
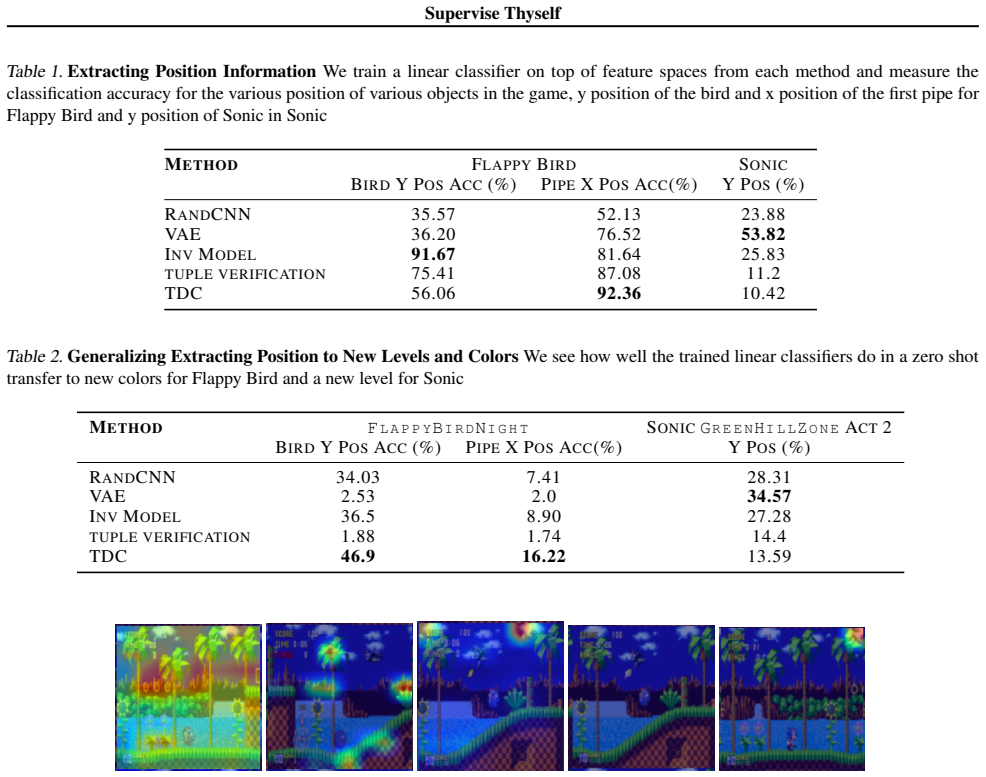
Two evaluation contexts: the extent to which the representations capture true state information of the agent, and how generalizable the representations are to novel situations such as new levels and textures.
If this is right
- Representations from one self-supervised method may suit environments with certain visuals while another method suits environments with different dynamics.
- State capture and generalizability can trade off, so a representation that scores high on one may score low on the other.
- Visualizing attention can reveal whether a representation focuses on task-relevant objects or on background elements.
Where Pith is reading between the lines
- Pretraining choices for control agents may need to be tuned per environment rather than applied uniformly across games.
- The same dependency could appear in robotics settings where camera images and physics vary across tasks.
- Combining multiple self-supervised objectives might reduce sensitivity to a single environment's visuals and dynamics.
Load-bearing premise
That the two evaluation contexts are sufficient proxies for determining which representations best capture meaningful features for downstream tasks such as control or exploration.
What would settle it
Running the learned representations as input features in an actual control or exploration task and finding that the method with highest state-capture and generalizability scores does not produce the best downstream performance.
Figures



read the original abstract
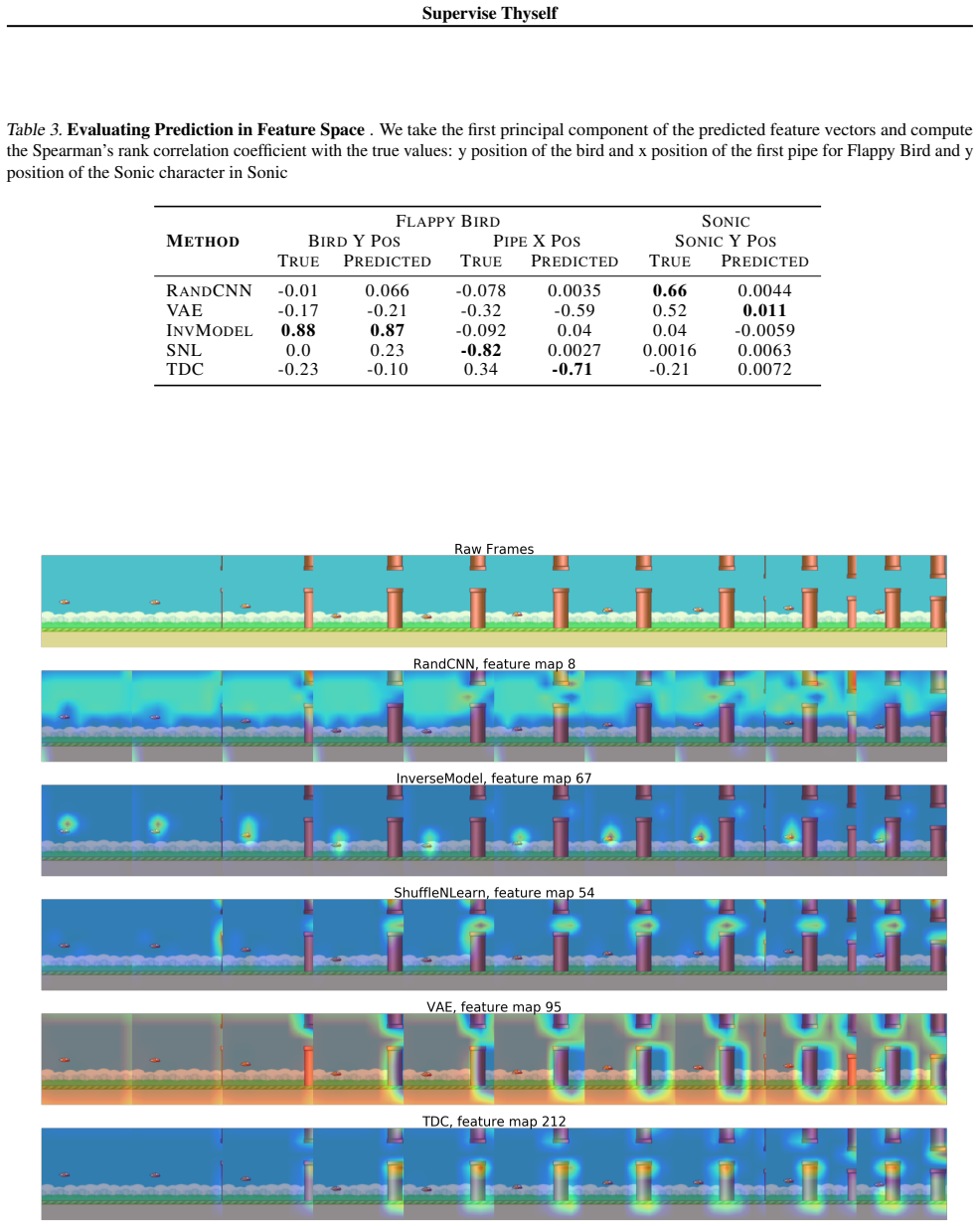
Self-supervised methods, wherein an agent learns representations solely by observing the results of its actions, become crucial in environments which do not provide a dense reward signal or have labels. In most cases, such methods are used for pretraining or auxiliary tasks for "downstream" tasks, such as control, exploration, or imitation learning. However, it is not clear which method's representations best capture meaningful features of the environment, and which are best suited for which types of environments. We present a small-scale study of self-supervised methods on two visual environments: Flappy Bird and Sonic The Hedgehog. In particular, we quantitatively evaluate the representations learned from these tasks in two contexts: a) the extent to which the representations capture true state information of the agent and b) how generalizable these representations are to novel situations, like new levels and textures. Lastly, we evaluate these self-supervised features by visualizing which parts of the environment they focus on. Our results show that the utility of the representations is highly dependent on the visuals and dynamics of the environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a small-scale empirical study comparing self-supervised representation learning methods in two visual interactive environments (Flappy Bird and Sonic the Hedgehog). Representations are evaluated quantitatively on (a) extent of true state capture and (b) generalizability to novel levels/textures, supplemented by saliency visualizations; the central claim is that representation utility is highly dependent on the visuals and dynamics of the environment.
Significance. If the proxy-based findings hold, the work usefully demonstrates environment-specific variation in self-supervised representations, providing a concrete basis for method selection in different visual/dynamics regimes. The comparative design across two distinct games and the inclusion of both quantitative proxies and visualizations are strengths for a small-scale study.
major comments (2)
- [Abstract] Abstract: the framing states that the study addresses 'which method's representations best capture meaningful features of the environment, and which are best suited for which types of environments' in the context of downstream tasks (control, exploration, imitation), yet the reported results contain no direct measurements on those tasks and rely solely on the two proxy contexts; this makes the dependence claim less directly supported for the stated practical utility.
- [Evaluation sections] Evaluation sections (state capture and generalizability): the two proxy metrics are presented as sufficient to determine representation utility, but the manuscript provides no correlation analysis, ablation, or discussion showing that performance on these proxies predicts downstream task performance; without this link the central claim that utility 'is highly dependent on the visuals and dynamics' rests on an unverified assumption.
minor comments (2)
- The manuscript would benefit from explicit listing of the exact self-supervised methods compared, the precise definitions of the state-capture and generalizability metrics, and any statistical tests used to support the dependence conclusion.
- Saliency visualizations are mentioned but their quantitative relation to the proxy metrics is not detailed; adding this would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the framing states that the study addresses 'which method's representations best capture meaningful features of the environment, and which are best suited for which types of environments' in the context of downstream tasks (control, exploration, imitation), yet the reported results contain no direct measurements on those tasks and rely solely on the two proxy contexts; this makes the dependence claim less directly supported for the stated practical utility.
Authors: The abstract motivates the work by referencing downstream tasks but then specifies that the evaluations use two proxy contexts (state capture and generalizability). To better align the framing with the actual results, we will revise the abstract to state explicitly that the study assesses representation utility via these proxies rather than through direct measurements on control, exploration, or imitation. This change will ensure the dependence claim is tied directly to the reported findings. revision: yes
-
Referee: [Evaluation sections] Evaluation sections (state capture and generalizability): the two proxy metrics are presented as sufficient to determine representation utility, but the manuscript provides no correlation analysis, ablation, or discussion showing that performance on these proxies predicts downstream task performance; without this link the central claim that utility 'is highly dependent on the visuals and dynamics' rests on an unverified assumption.
Authors: We agree that the manuscript contains no explicit correlation analysis or ablation linking proxy performance to downstream task results. As a small-scale empirical study, the work centers on the proxies themselves. We will add a short discussion paragraph in the evaluation sections that (a) motivates the proxies by their relevance to feature capture and generalization and (b) acknowledges that predictive validity for downstream tasks is not demonstrated here and would require additional experiments. The central claim will be qualified to refer specifically to the observed variation across the two proxy contexts. revision: partial
Circularity Check
Empirical comparison of self-supervised representations contains no circular derivation steps
full rationale
The paper is an empirical study that trains several self-supervised models on Flappy Bird and Sonic, then measures two proxy quantities (state capture via linear probes or similar, and generalization to novel levels/textures) plus saliency maps. No equations, first-principles derivations, or predictions are presented that could reduce to fitted inputs or self-citations by construction. The abstract and results sections frame the work as an experimental comparison whose conclusions follow directly from the reported measurements on the chosen environments; no load-bearing uniqueness theorems, ansatzes smuggled via citation, or renaming of known results appear. The evaluation is therefore self-contained against its own experimental benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We quantitatively evaluate the representations learned from these tasks in two contexts: a) the extent to which the representations capture true state information of the agent and b) how generalizable these representations are to novel situations, like new levels and textures.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results show that the utility of the representations is highly dependent on the visuals and dynamics of the environment.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Agrawal, P., Carreira, J., and Malik, J. Learning to see by moving. In Proceedings of the IEEE International Conference on Computer Vision, pp.\ 37--45, 2015
work page 2015
-
[3]
V., Abbeel, P., Malik, J., and Levine, S
Agrawal, P., Nair, A. V., Abbeel, P., Malik, J., and Levine, S. Learning to poke by poking: Experiential learning of intuitive physics. In Advances in Neural Information Processing Systems, pp.\ 5074--5082, 2016
work page 2016
-
[4]
Exploration by random distillation
Anonymous. Exploration by random distillation. 2018. URL https://openreview.net/pdf?id=H1lJJnR5Ym. Submitted to ICLR 2019
work page 2018
-
[5]
A Theoretical Analysis of Contrastive Unsupervised Representation Learning
Arora, S., Khandeparkar, H., Khodak, M., Plevrakis, O., and Saunshi, N. A theoretical analysis of contrastive unsupervised representation learning. arXiv preprint arXiv:1902.09229, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[6]
Playing hard exploration games by watching YouTube
Aytar, Y., Pfaff, T., Budden, D., Paine, T. L., Wang, Z., and de Freitas, N. Playing hard exploration games by watching youtube. arXiv preprint arXiv:1805.11592, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Burda, Y., Edwards, H., Pathak, D., Storkey, A., Darrell, T., and Efros, A. A. Large-scale study of curiosity-driven learning. arXiv preprint arXiv:1808.04355, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Contingency-Aware Exploration in Reinforcement Learning
Choi, J., Guo, Y., Moczulski, M., Oh, J., Wu, N., Norouzi, M., and Lee, H. Contingency-aware exploration in reinforcement learning. arXiv preprint arXiv:1811.01483, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
SentEval: An Evaluation Toolkit for Universal Sentence Representations
Conneau, A. and Kiela, D. Senteval: An evaluation toolkit for universal sentence representations. arXiv preprint arXiv:1803.05449, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
M., Ghodrati, A., and Tuytelaars, T
Fernando, B., Gavves, E., Oramas, J. M., Ghodrati, A., and Tuytelaars, T. Modeling video evolution for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 5378--5387, 2015
work page 2015
-
[11]
Self-supervised video representation learning with odd-one-out networks
Fernando, B., Bilen, H., Gavves, E., and Gould, S. Self-supervised video representation learning with odd-one-out networks. In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on, pp.\ 5729--5738. IEEE, 2017
work page 2017
-
[12]
Ha, D. and Schmidhuber, J. World models. arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Hyvarinen, A. and Morioka, H. Unsupervised feature extraction by time-contrastive learning and nonlinear ica. In Advances in Neural Information Processing Systems, pp.\ 3765--3773, 2016
work page 2016
-
[14]
Hyvarinen, A., Sasaki, H., and Turner, R. E. Nonlinear ica using auxiliary variables and generalized contrastive learning. arXiv preprint arXiv:1805.08651, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Reinforcement Learning with Unsupervised Auxiliary Tasks
Jaderberg, M., Mnih, V., Czarnecki, W. M., Schaul, T., Leibo, J. Z., Silver, D., and Kavukcuoglu, K. Reinforcement learning with unsupervised auxiliary tasks. arXiv preprint arXiv:1611.05397, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
Jayaraman, D. and Grauman, K. Learning image representations tied to ego-motion. In Proceedings of the IEEE International Conference on Computer Vision, pp.\ 1413--1421, 2015
work page 2015
-
[17]
Jonschkowski, R. and Brock, O. Learning state representations with robotic priors. Autonomous Robots, 39 0 (3): 0 407--428, 2015
work page 2015
-
[18]
PVEs: Position-Velocity Encoders for Unsupervised Learning of Structured State Representations
Jonschkowski, R., Hafner, R., Scholz, J., and Riedmiller, M. Pves: Position-velocity encoders for unsupervised learning of structured state representations. arXiv preprint arXiv:1705.09805, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Learning world models with self-supervised learning, 2018
LeCun, Y. Learning world models with self-supervised learning, 2018. Presented at ICML worlshop on Generative Modeling in RL
work page 2018
-
[21]
State representation learning for control: An overview
Lesort, T., D \' az-Rodr \' guez, N., Goudou, J.-F., and Filliat, D. State representation learning for control: An overview. Neural Networks, 2018
work page 2018
-
[22]
Efficient Estimation of Word Representations in Vector Space
Mikolov, T., Chen, K., Corrado, G., and Dean, J. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[23]
Learning to Navigate in Complex Environments
Mirowski, P., Pascanu, R., Viola, F., Soyer, H., Ballard, A. J., Banino, A., Denil, M., Goroshin, R., Sifre, L., Kavukcuoglu, K., et al. Learning to navigate in complex environments. arXiv preprint arXiv:1611.03673, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Misra, I., Zitnick, C. L., and Hebert, M. Shuffle and learn: unsupervised learning using temporal order verification. In European Conference on Computer Vision, pp.\ 527--544. Springer, 2016
work page 2016
-
[25]
P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., and Kavukcuoglu, K
Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., and Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In International conference on machine learning, pp.\ 1928--1937, 2016
work page 1928
-
[26]
Gotta Learn Fast: A New Benchmark for Generalization in RL
Nichol, A., Pfau, V., Hesse, C., Klimov, O., and Schulman, J. Gotta learn fast: A new benchmark for generalization in rl. arXiv preprint arXiv:1804.03720, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Pathak, D., Agrawal, P., Efros, A. A., and Darrell, T. Curiosity-driven exploration by self-supervised prediction. 2017 a
work page 2017
-
[28]
Learning features by watching objects move
Pathak, D., Girshick, R., Doll \'a r, P., Darrell, T., and Hariharan, B. Learning features by watching objects move. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 6024--6033. IEEE, 2017 b
work page 2017
-
[29]
Deep contextualized word representations
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., and Zettlemoyer, L. Deep contextualized word representations. arXiv preprint arXiv:1802.05365, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
S-RL Toolbox: Environments, Datasets and Evaluation Metrics for State Representation Learning
Raffin, A., Hill, A., Traor \'e , R., Lesort, T., D \' az-Rodr \' guez, N., and Filliat, D. S-rl toolbox: Environments, datasets and evaluation metrics for state representation learning. arXiv preprint arXiv:1809.09369, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Time-Contrastive Networks: Self-Supervised Learning from Video
Sermanet, P., Lynch, C., Chebotar, Y., Hsu, J., Jang, E., Schaal, S., and Levine, S. Time-contrastive networks: Self-supervised learning from video. arXiv preprint arXiv:1704.06888, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Loss is its own Reward: Self-Supervision for Reinforcement Learning
Shelhamer, E., Mahmoudieh, P., Argus, M., and Darrell, T. Loss is its own reward: Self-supervision for reinforcement learning. arXiv preprint arXiv:1612.07307, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[33]
Subramanian, S., Trischler, A., Bengio, Y., and Pal, C. J. Learning general purpose distributed sentence representations via large scale multi-task learning. arXiv preprint arXiv:1804.00079, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Tasfi, N. Pygame learning environment. https://github.com/ntasfi/PyGame-Learning-Environment, 2016
work page 2016
-
[35]
Tracking emerges by colorizing videos
Vondrick, C., Shrivastava, A., Fathi, A., Guadarrama, S., and Murphy, K. Tracking emerges by colorizing videos. In European Conference on Computer Vision, pp.\ 402--419. Springer, 2018
work page 2018
-
[36]
Wang, X. and Gupta, A. Unsupervised learning of visual representations using videos. In Proceedings of the IEEE International Conference on Computer Vision, pp.\ 2794--2802, 2015
work page 2015
-
[37]
J., Zisserman, A., and Freeman, W
Wei, D., Lim, J. J., Zisserman, A., and Freeman, W. T. Learning and using the arrow of time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 8052--8060, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.