Gesture Recognition in RGB Videos UsingHuman Body Keypoints and Dynamic Time Warping
Pith reviewed 2026-05-25 16:35 UTC · model grok-4.3
The pith
Gesture recognition from RGB video works by tracking body keypoints with OpenPose then aligning sequences via Dynamic Time Warping and nearest-neighbor lookup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that combining OpenPose keypoint trajectories with Dynamic Time Warping and 1NN produces reliable gesture classification on RGB video, while remaining independent of any particular capture hardware and allowing new gestures to be added by supplying only a few examples.
What carries the argument
OpenPose keypoint extraction followed by DTW+1NN alignment and comparison of the resulting 2D pose time series.
If this is right
- Recognition runs on any RGB camera without depth sensors or custom rigs.
- A new gesture enters the system by adding a handful of example videos to the reference set.
- Classification operates on the temporal shape of pose trajectories rather than learned visual features.
- The method avoids the data and compute cost of training an end-to-end gesture network.
Where Pith is reading between the lines
- The same pipeline could be tested on other temporal tasks such as action segmentation where pose is the dominant cue.
- Replacing DTW with a learned distance metric might improve accuracy while keeping the few-example property.
- Deployment on a mobile robot would let gestures serve as an attention or command channel without retraining the vision stack.
Load-bearing premise
The 2D keypoints produced by OpenPose stay accurate and consistent enough across the target videos and conditions for DTW to yield reliable similarity scores.
What would settle it
Run the pipeline on a set of videos that vary in lighting, camera angle, or partial occlusion; if DTW distances no longer separate the gesture classes at rates comparable to the reported results, the method fails.
Figures



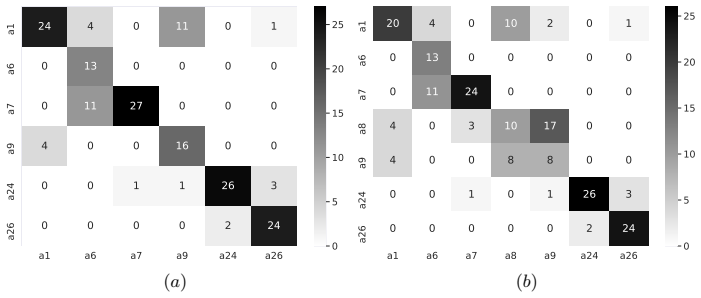
read the original abstract
Gesture recognition opens up new ways for humans to intuitively interact with machines. Especially for service robots, gestures can be a valuable addition to the means of communication to, for example, draw the robot's attention to someone or something. Extracting a gesture from video data and classifying it is a challenging task and a variety of approaches have been proposed throughout the years. This paper presents a method for gesture recognition in RGB videos using OpenPose to extract the pose of a person and Dynamic Time Warping (DTW) in conjunction with One-Nearest-Neighbor (1NN) for time-series classification. The main features of this approach are the independence of any specific hardware and high flexibility, because new gestures can be added to the classifier by adding only a few examples of it. We utilize the robustness of the Deep Learning-based OpenPose framework while avoiding the data-intensive task of training a neural network ourselves. We demonstrate the classification performance of our method using a public dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a gesture recognition method for RGB videos that extracts 2D human body keypoints via the pre-trained OpenPose framework and performs classification using Dynamic Time Warping (DTW) combined with 1-Nearest Neighbor (1NN). It highlights hardware independence (no custom sensors) and flexibility (new gestures added via a few example videos only), while avoiding training a neural network from scratch. Performance is demonstrated on a public dataset.
Significance. If the results hold under the stated conditions, the approach offers a lightweight, adaptable alternative to end-to-end learned models for gesture recognition in robotics and HCI. Credit is due for the explicit design choice to reuse off-the-shelf pose estimation and a parameter-light classifier, which directly supports the claimed ease of extending the gesture vocabulary without retraining.
major comments (2)
- [Method description and Experiments] The central claim that OpenPose-derived keypoints form sufficiently clean and consistent time series for reliable DTW+1NN separation (even with few-shot addition of new classes) is load-bearing, yet the manuscript supplies no quantitative characterization of keypoint jitter, dropout rates, or occlusion effects on the chosen public dataset. This directly affects both reported accuracy and the hardware-independence claim.
- [Experiments] No ablation is reported on the impact of missing or noisy joints (common in RGB video) on DTW distance computation or 1NN accuracy. Without this, it is impossible to assess whether the claimed flexibility survives realistic video conditions.
minor comments (2)
- [Method] Clarify the exact DTW variant (e.g., Sakoe-Chiba band width, distance metric on keypoints) and any preprocessing of the 2D keypoint trajectories.
- [Experiments] The public dataset should be named explicitly with citation and split details (train/test, number of gestures, subjects).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and agree that additional analyses will strengthen the paper. We will incorporate the suggested characterizations and ablations in the revised version.
read point-by-point responses
-
Referee: [Method description and Experiments] The central claim that OpenPose-derived keypoints form sufficiently clean and consistent time series for reliable DTW+1NN separation (even with few-shot addition of new classes) is load-bearing, yet the manuscript supplies no quantitative characterization of keypoint jitter, dropout rates, or occlusion effects on the chosen public dataset. This directly affects both reported accuracy and the hardware-independence claim.
Authors: We agree that explicit quantitative characterization of keypoint quality would better support the central claims. The current manuscript reports end-to-end classification results on the public dataset but does not include separate metrics for jitter, dropout, or occlusion. In the revision we will add a dedicated subsection with statistics on keypoint confidence scores, missing joint rates, and qualitative examples of occlusion handling from the dataset videos. This addition will directly address the hardware-independence claim. revision: yes
-
Referee: [Experiments] No ablation is reported on the impact of missing or noisy joints (common in RGB video) on DTW distance computation or 1NN accuracy. Without this, it is impossible to assess whether the claimed flexibility survives realistic video conditions.
Authors: We concur that an ablation on the effects of missing or noisy joints is necessary to evaluate robustness. The manuscript does not contain such an experiment. In the revised manuscript we will add an ablation study that systematically removes or perturbs joints in the keypoint sequences and reports the resulting change in DTW+1NN accuracy. This will clarify the limits of the few-shot flexibility under realistic RGB conditions. revision: yes
Circularity Check
No circularity: pipeline uses external OpenPose and standard DTW+1NN on public data without self-referential fits or definitions.
full rationale
The paper presents a straightforward pipeline: OpenPose (external) extracts 2D keypoints from RGB video, followed by DTW distance computation and 1NN classification. No equations, fitted parameters, or predictions are described that reduce reported accuracy to quantities defined by the authors' own prior choices. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results occurs. The central claim of hardware independence and few-shot addition of gestures follows directly from the off-the-shelf components and the public dataset evaluation, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption OpenPose produces sufficiently accurate and temporally consistent 2D keypoints on the input RGB videos
Reference graph
Works this paper leans on
-
[1]
C. Chen, R. Jafari, and N. Kehtarnavaz, “UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor,” in 2015 IEEE International Conference on Image Processing (ICIP) . IEEE, 2015, pp. 168–172
work page 2015
-
[2]
Recognition of multivariate temporal musical gestures using n-dimensional dynamic time warping
N. Gillian, B. Knapp, and S. O’Modhrain, “Recognition of multivariate temporal musical gestures using n-dimensional dynamic time warping.” in Nime, 2011, pp. 337–342
work page 2011
-
[3]
A. Rosa-Pujaz´ on, I. Barbancho, L. J. Tard´ on, and A. M. Barbancho, “Fast-gesture recognition and classification using Kinect: An application for a virtual reality drumkit,” Multimedia Tools and Applications, vol. 75, no. 14, pp. 8137–8164, 2016
work page 2016
-
[4]
Multi-layered gesture recognition with Kinect,
F. Jiang, S. Zhang, S. Wu, Y. Gao, and D. Zhao, “Multi-layered gesture recognition with Kinect,” The Journal of Machine Learning Research , vol. 16, no. 1, pp. 227– 254, 2015
work page 2015
-
[5]
A. Rib´ o, D. Warchol, and W. Oszust, “An approach to gesture recognition with skeletal data using dynamic time warping and nearest neighbour classifier,” In- ternational Journal of Intelligent Systems and Applications , vol. 8, no. 6, pp. 1–8, 2016
work page 2016
-
[6]
Probability-based dynamic time warping for gesture recognition on RGB-D data,
M. A. Bautista, A. Hern´ andez-Vela, V. Ponce, X. Perez-Sala, X. Bar´ o, O. Pujol, C. Angulo, and S. Escalera, “Probability-based dynamic time warping for gesture recognition on RGB-D data,” in International Workshop on Depth Image Analysis and Applications. Springer, 2012, pp. 126–135
work page 2012
-
[7]
Gesture recognition: A survey,
S. Mitra and T. Acharya, “Gesture recognition: A survey,” IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) , vol. 37, no. 3, pp. 311–324, 2007
work page 2007
-
[8]
Trajectory modeling in gesture recognition using cybergloves R⃝ and magnetic trackers,
N. Y. Y. Kevin, S. Ranganath, and D. Ghosh, “Trajectory modeling in gesture recognition using cybergloves R⃝ and magnetic trackers,” in 2004 IEEE Region 10 Conference TENCON 2004. IEEE, 2004, pp. 571–574
work page 2004
-
[9]
Feature weighting in dynamic time warping for gesture recognition in depth data,
M. Reyes, G. Dominguez, and S. Escalera, “Feature weighting in dynamic time warping for gesture recognition in depth data,” in Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on . IEEE, 2011, pp. 1182–1188
work page 2011
-
[10]
Multi-dimensional dynamic time warping for gesture recognition,
G. A. Ten Holt, M. J. Reinders, and E. Hendriks, “Multi-dimensional dynamic time warping for gesture recognition,” in Thirteenth Annual Conference of the Advanced School for Computing and Imaging , vol. 300, 2007, p. 1
work page 2007
-
[11]
Fast time series classification using numerosity reduction,
X. Xi, E. Keogh, C. Shelton, L. Wei, and C. A. Ratanamahatana, “Fast time series classification using numerosity reduction,” in Proceedings of the 23rd International Conference on Machine Learning . ACM, 2006, pp. 1033–1040
work page 2006
-
[12]
A. Bagnall, J. Lines, A. Bostrom, J. Large, and E. Keogh, “The great time series classification bake off: A review and experimental evaluation of recent algorithmic advances,” Data Mining and Knowledge Discovery , vol. 31, no. 3, pp. 606–660, 2017
work page 2017
-
[13]
Dynamic programming algorithm optimization for spoken word recognition,
H. Sakoe and S. Chiba, “Dynamic programming algorithm optimization for spoken word recognition,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 26, no. 1, pp. 43–49, 1978
work page 1978
-
[14]
Minimum prediction residual principle applied to speech recognition,
F. Itakura, “Minimum prediction residual principle applied to speech recognition,” IEEE Transactions on Acoustics, Speech, and Signal Processing , vol. 23, no. 1, pp. 67–72, 1975
work page 1975
-
[15]
Making time-series classification more accurate using learned constraints,
C. A. Ratanamahatana and E. Keogh, “Making time-series classification more accurate using learned constraints,” in Proceedings of the 2004 SIAM International Conference on Data Mining . SIAM, 2004, pp. 11–22
work page 2004
-
[16]
Toward accurate dynamic time warping in linear time and space,
S. Salvador and P. Chan, “Toward accurate dynamic time warping in linear time and space,” Intelligent Data Analysis , vol. 11, no. 5, pp. 561–580, 2007
work page 2007
-
[17]
M¨ uller,Information retrieval for music and motion
M. M¨ uller,Information retrieval for music and motion . Springer, 2007
work page 2007
-
[18]
Dynamic time warping algorithm review,
P. Senin, “Dynamic time warping algorithm review,” Information and Computer Science Department University of Hawaii at Manoa Honolulu, USA , vol. 855, pp. 1–23, 2008
work page 2008
-
[19]
Two streams recurrent neural net- works for large-scale continuous gesture recognition,
X. Chai, Z. Liu, F. Yin, Z. Liu, and X. Chen, “Two streams recurrent neural net- works for large-scale continuous gesture recognition,” in 23rd International Con- ference on Pattern Recognition (ICPR) . IEEE, 2016, pp. 31–36
work page 2016
-
[20]
P. Molchanov, X. Yang, S. Gupta, K. Kim, S. Tyree, and J. Kautz, “Online detec- tion and classification of dynamic hand gestures with recurrent 3d convolutional neural network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4207–4215
work page 2016
-
[21]
Gesture recognition for human-robot collaboration: A re- view,
H. Liu and L. Wang, “Gesture recognition for human-robot collaboration: A re- view,” International Journal of Industrial Ergonomics , vol. 68, pp. 355–367, 2018
work page 2018
-
[22]
Gesture recognition on human pose features of single images,
R. Memmesheimer, I. Mykhalchyshyna, and D. Paulus, “Gesture recognition on human pose features of single images,” in Intelligent Systems (IS), 2018 9th Inter- national Conference on . IEEE, 2018, pp. 1–7
work page 2018
-
[23]
Gesture recognition using skeleton data with weighted dynamic time warping
S. Celebi, A. S. Aydin, T. T. Temiz, and T. Arici, “Gesture recognition using skeleton data with weighted dynamic time warping.” in VISAPP (1) , 2013, pp. 620–625
work page 2013
-
[24]
J. Rwigema, H.-R. Choi, and T. Kim, “A differential evolution approach to opti- mize weights of dynamic time warping for multi-sensor based gesture recognition,” Sensors (Basel, Switzerland) , vol. 19, no. 5, p. 1007, 2019
work page 2019
-
[25]
Convolutional pose ma- chines,
S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh, “Convolutional pose ma- chines,” in CVPR, 2016
work page 2016
-
[26]
Hand keypoint detection in single images using multiview bootstrapping,
T. Simon, H. Joo, I. Matthews, and Y. Sheikh, “Hand keypoint detection in single images using multiview bootstrapping,” in CVPR, 2017
work page 2017
-
[27]
OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh, “OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields,” in arXiv preprint arXiv:1812.08008, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Derivative dynamic time warping,
E. J. Keogh and M. J. Pazzani, “Derivative dynamic time warping,” in Proceedings of the 2001 SIAM International Conference on Data Mining . SIAM, 2001, pp. 1–11
work page 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.