Network-accelerated Distributed Machine Learning Using MLFabric
Pith reviewed 2026-05-25 12:06 UTC · model grok-4.3
The pith
MLfabric accelerates distributed deep learning by up to 3X through in-network aggregation and ordered gradient transfers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MLfabric manages every network transfer in a DML system and holistically decides the communication pattern at any moment. This control lets the library order transfers to improve convergence, perform opportunistic in-network aggregation of updates, and proactively replicate some updates to enable new fault-tolerance properties, producing up to 3X faster training of large deep learning models under realistic dynamic cluster conditions.
What carries the argument
MLfabric, the communication library that determines the full communication pattern of a DML algorithm to enable ordering, in-network aggregation, and replication of gradient updates.
If this is right
- DML systems gain both faster convergence from ordered updates and lower communication volume from in-network aggregation.
- New fault-tolerance schemes become practical because replication can be done proactively without extra rounds.
- Training large models becomes feasible in clusters where network conditions change over time.
- Communication management can be separated from the core learning algorithm while still improving end-to-end performance.
Where Pith is reading between the lines
- Similar pattern-aware management could apply to other distributed workloads that exchange large intermediate results.
- Hardware vendors might add more flexible in-network compute primitives if libraries like this demonstrate consistent gains.
- Dynamic cluster environments may require such libraries as a standard layer rather than an optional optimization.
Load-bearing premise
The network hardware and fabric can carry out in-network aggregation and ordering at full line rate without adding latency or compatibility problems that erase the reported gains.
What would settle it
Run identical large-model training jobs in the same dynamic cluster once with MLfabric and once with a standard communication layer, then compare wall-clock time and measured network latency to check whether the 3X speedup and zero added latency both appear.
Figures



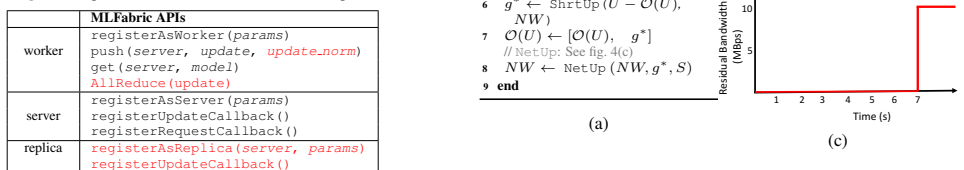




read the original abstract
Existing distributed machine learning (DML) systems focus on improving the computational efficiency of distributed learning, whereas communication aspects have received less attention. Many DML systems treat the network as a blackbox. Thus, DML algorithms' performance is impeded by network bottlenecks, and DML systems end up sacrificing important algorithmic and system-level benefits. We present MLfabric, a communication library that manages all network transfers in a DML system, and holistically determines the communication pattern of a DML algorithm at any point in time. This allows MLfabric to carefully order transfers (i.e., gradient updates) to improve convergence, opportunistically aggregate updates in-network to improve efficiency, and proactively replicate some of them to support new notions of fault tolerance. We empirically find that MLfabric achieves up to 3X speed-up in training large deep learning models in realistic dynamic cluster settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MLfabric, a communication library for distributed machine learning that manages all network transfers, holistically determines communication patterns, orders gradient updates to improve convergence, opportunistically aggregates them in-network for efficiency, and proactively replicates some for fault tolerance. The central claim is the empirical result that MLfabric achieves up to 3X speed-up when training large deep learning models in realistic dynamic cluster settings.
Significance. If the speedup claim is substantiated with proper controls, the work would be significant for distributed systems and ML by shifting from treating the network as a blackbox to actively leveraging it for ordering, aggregation, and resilience. This could reduce communication bottlenecks in DML without sacrificing algorithmic benefits.
major comments (2)
- [Abstract] Abstract: the central empirical claim of 'up to 3X speed-up' supplies no information on baselines, cluster size, model details, variance across runs, or whether gains persist after accounting for aggregation overhead; these details are load-bearing for assessing the result.
- [Abstract] Abstract: the assumption that the network fabric can execute in-network aggregation and ordering at line rate without introducing offsetting latency or compatibility problems is stated but receives no supporting evidence, implementation description, or hardware discussion in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional context would strengthen the presentation of our central empirical claim and will revise accordingly. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of 'up to 3X speed-up' supplies no information on baselines, cluster size, model details, variance across runs, or whether gains persist after accounting for aggregation overhead; these details are load-bearing for assessing the result.
Authors: We agree that the abstract is too terse on these points. The Evaluation section of the manuscript reports end-to-end speedups measured against standard parameter-server and all-reduce baselines, on clusters ranging from 8 to 64 nodes, using models such as ResNet-50 and VGG-16, with results averaged over multiple runs showing low variance. The reported gains already incorporate aggregation and ordering overheads, as confirmed by our microbenchmarks. In the revision we will expand the abstract to read: 'up to 3X end-to-end speedup versus standard baselines when training ResNet-50 on 16-32 GPU clusters, with overheads from in-network aggregation included.' revision: yes
-
Referee: [Abstract] Abstract: the assumption that the network fabric can execute in-network aggregation and ordering at line rate without introducing offsetting latency or compatibility problems is stated but receives no supporting evidence, implementation description, or hardware discussion in the provided text.
Authors: The design section describes how MLfabric issues commands to programmable switches for ordering and aggregation, but we acknowledge that the abstract and early sections do not explicitly discuss hardware assumptions or latency measurements. In the revision we will add a sentence to the abstract noting that MLfabric targets data-center networks with P4-programmable switches and will include a short paragraph in the System Design section summarizing our testbed measurements, which show sub-microsecond additional latency for in-network operations relative to standard forwarding. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents an empirical systems contribution: MLfabric is a communication library that orders, aggregates, and replicates gradient updates to achieve up to 3X training speedup in dynamic clusters. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claim is a measured performance result rather than a mathematical reduction; therefore no load-bearing step reduces to its own inputs by construction. The work is self-contained as an engineering artifact evaluated against external baselines.
Axiom & Free-Parameter Ledger
invented entities (1)
-
MLfabric
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first determine ordering for the batch of updates... We develop an in-network aggregation algorithm that determines whether to send each update directly to a server, or to an aggregator first.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
INTRODUCTION Machine learning (ML) is revolutionizing not only the computing industry, but also fields such as healthcare and education, where ML techniques are driving key applications. Thus, there is a race to build new ML systems [6, 1, 5, 33] that efficiently learn complex models from big datasets. To support large model sizes and training data most sys...
-
[2]
Using holistic control, MLfabric can determine in-network aggregation strategies
Flexible aggregation to overcome network bottlenecks. Using holistic control, MLfabric can determine in-network aggregation strategies. Workers can be dynamically organized into tree-like topologies over which updates are routed and aggregated before being committed at a server. This helps improve network efficiency in the presence of dynamically changing ...
-
[3]
Network-accelerated Distributed Machine Learning Using MLFabric
Leveraging the network for algorithmic advances In asyn- chronous SGD, updates from slow workers, e.g., compute stragglers, or those stuck behind a network bottleneck, have a high delay, i.e., their update is computed from an old model version. Applying stale updates to the model can affect convergence [7]. To address this, asynchronous algorithms set sma...
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[4]
Leveraging the network for framework improvements Exist- ing PS systems [23] use a hot-standby for server fault tolerance. Chain replication is employed to ensure every model update to the parameter server is also applied to the replica, enforcing strong consistency. However, chain replication introduces additional per- iteration latency, and exacerbates ...
-
[5]
DML PERFORMANCE ANALYSIS The de facto algorithm of choice for various ML applications like Deep learning, Generalized Linear Models, etc., is Stochas- tic Gradient Descent (SGD) [26]. SGD is inherently serial; in each iteration the model is updated using a gradient from a single sample or a mini-batch of training data [9]. In order to distribute SGD, ML p...
-
[6]
CENTRAL IDEAS Today’s DML systems’ network-agnosticity causes slowdowns in the face of compute or network contention (stragglers). In MLfabric, instead of treating the network as a blackbox, all transfers of a DML algorithm are handed off to a communication library, which determines the entire communication pattern at any point in time. For simplicity, we...
-
[7]
advocates on making learning rate a function of the delay observed for a worker; under the assumption that the delay follows an uniform distribution,τ∈ Uniform[0, 2¯τ], they show that delay adaptive SGD converges as: E[L(wt)]−L(w∗)≤O ( ¯τ √ t t ) (3) where,w∗ is the optimal model minimizing loss functionL(.), and ˆw(t) is the estimated model aftert iterat...
-
[8]
ARCHITECTURE AND APIS Architecture: The main component of MLfabric is a scheduler that interacts with MLfabric daemons on each worker/server; the sched- uler processes update and model transfer requests from the daemons and determines the (a) next hop, and (b) schedule for each transfer. The next hop can either be a final destination (worker or server) or ...
-
[9]
ALGORITHMS MLfabric scheduler determines the communication pattern for a batch of updates available from workers. It computes the transfer schedule (i.e., how bytes in an update are transferred at any given time) and forwarding (next hop – i.e., server or intermediate aggrega- tor hop) for each of these updates. This is done so as to (1) minimize the aver...
-
[10]
EXTENDING MLfabric We now describe how MLfabric applies to synchronous and stale synchronous SGD, and to MPI frameworks. Synchronous SGD/PS: Here, at each iteration, workers read the latest model and compute a local update using a portion of the mini- batch. The updates are then aggregated at the server and applied to the model (also incrementing model ve...
-
[11]
EV ALUA TION Implementation: MLfabric is implemented in C++ as a thin com- munication control layer between DML applications (e.g., PLDA [25], Keras [11], Tensorflow [6]) and MPI communication libraries (Open- MPI [18] and NCCL [2]). DML applications interact with MLfabric through APIs defined in Table 1 and MLfabric internally uses APIs provided by MPI fra...
-
[12]
RELA TED WORK Prior works propose various techniques to reduce the overall training time of ML algorithms that employ SGD for learning. Algorithmic approaches: Some other approaches for mitigating stragglers involve: aggregating gradients from only a subset of fast workers in each iteration of synchronous SGD [16], which is com- plementary with MLfabric’s...
-
[13]
CONCLUSION We designed MLfabric, a communication library for speeding up large-scale distributed machine learning (DML) systems in dynamic cluster settings. We showed that fine-grained in-network control helps MLfabric to (1) algorithmically speed up convergence, (2) improve network efficiency via dynamic update aggregation, and (3) offload model replication...
-
[14]
Let, A ={a1,..,a ℓ} be the aggre- gators that serve as intermediate hops
APPENDIX 10.1 ILP formulation for joint ordering and forwarding for aggregation LetW ={w1,..,w n} be the workers andS be the server storing a DML application’s model. Let, A ={a1,..,a ℓ} be the aggre- gators that serve as intermediate hops. Let G = (V,E ) denote a directed graph representing the underlying communication network. V is the set of all hosts ...
-
[15]
Caffe2: A new lightweight, modular, and scalable deep learning framework. https://caffe2.ai/
-
[16]
https://github.com/NVIDIA/nccl
NVIDIA Collective Communication Library. https://github.com/NVIDIA/nccl. Accessed: 2018-01-01
work page 2018
-
[17]
https://archive.ics.uci.edu/ml/ 12 machine-learning-databases/bag-of-words
NY Times Dataset. https://archive.ics.uci.edu/ml/ 12 machine-learning-databases/bag-of-words
-
[18]
http:// pytorch.org/docs/master/distributed.html
PyTorch -Distributed communication package. http:// pytorch.org/docs/master/distributed.html
-
[19]
Tensors and Dynamic neural network in Python with strong GPU accleration. http://pytorch.org/
-
[20]
G., S TEINER , B., T UCKER , P., VASUDEVAN , V., WARDEN , P., W ICKE , M., Y U, Y., AND ZHENG , X
A BADI , M., B ARHAM , P., C HEN , J., C HEN , Z., D AVIS, A., DEAN , J., D EVIN , M., G HEMAWAT, S., I RVING , G., I SARD , M., K UDLUR , M., L EVENBERG , J., M ONGA , R., M OORE , S., M URRAY, D. G., S TEINER , B., T UCKER , P., VASUDEVAN , V., WARDEN , P., W ICKE , M., Y U, Y., AND ZHENG , X. Tensorflow: A system for large-scale machine learning. In 12t...
work page 2016
-
[21]
A GARWAL , A., AND DUCHI , J. C. Distributed delayed stochastic optimization. In Advances in Neural Information Processing Systems 24, J. Shawe-Taylor, R. S. Zemel, P. L. Bartlett, F. Pereira, and K. Q. Weinberger, Eds. Curran Associates, Inc., 2011, pp. 873–881
work page 2011
-
[22]
B LEI , D. M., N G, A. Y., AND JORDAN , M. I. Latent dirichlet allocation. Journal of machine Learning research 3, Jan (2003), 993–1022
work page 2003
-
[23]
B OTTOU , L., C URTIS , F. E., AND NOCEDAL , J. Optimization Methods for Large-Scale Machine Learning. ArXiv e-prints (June 2016)
work page 2016
-
[24]
MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems
C HEN , T., L I, M., L I, Y., L IN, M., W ANG , N., W ANG , M., XIAO, T., X U, B., Z HANG , C., AND ZHANG , Z. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. CoRR abs/1512.01274 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
C HOLLET , F., ET AL . Keras. https://keras.io, 2015
work page 2015
-
[26]
Coflow: A networking abstraction for cluster applications
C HOWDHURY , M., AND STOICA , I. Coflow: A networking abstraction for cluster applications. In HotNets (2012)
work page 2012
-
[27]
Efficient coflow scheduling without prior knowledge
C HOWDHURY , M., AND STOICA , I. Efficient coflow scheduling without prior knowledge. In SIGCOMM (2015)
work page 2015
-
[28]
Efficient coflow scheduling with varys
C HOWDHURY , M., Z HONG , Y., AND STOICA , I. Efficient coflow scheduling with varys. In Proceedings of the 2014 ACM Conference on SIGCOMM (New York, NY , USA, 2014), SIGCOMM ’14, ACM, pp. 443–454
work page 2014
-
[29]
C UI, H., Z HANG , H., G ANGER , G. R., G IBBONS , P. B., AND XING , E. P. Geeps: Scalable deep learning on distributed gpus with a gpu-specialized parameter server. In Proceedings of the Eleventh European Conference on Computer Systems (New York, NY , USA, 2016), EuroSys ’16, ACM, pp. 4:1–4:16
work page 2016
-
[30]
S., M ONGA , R., C HEN , K., DEVIN , M., L E, Q
D EAN , J., C ORRADO , G. S., M ONGA , R., C HEN , K., DEVIN , M., L E, Q. V., M AO, M. Z., R ANZATO , M., SENIOR , A., T UCKER , P., YANG , K., AND NG, A. Y. Large scale distributed deep networks. In NIPS (2012)
work page 2012
-
[31]
Imagenet: A large-scale hierarchical image database
D ENG , J., D ONG , W., S OCHER , R., L I, L., L I, K., AND FEI-F EI, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition (June 2009), pp. 248–255
work page 2009
-
[32]
G RAHAM , R. L., W OODALL , T. S., AND SQUYRES , J. M. Open mpi: A flexible high performance mpi. In Parallel Processing and Applied Mathematics (Berlin, Heidelberg, 2006), R. Wyrzykowski, J. Dongarra, N. Meyer, and J. Wa´sniewski, Eds., Springer Berlin Heidelberg, pp. 228–239
work page 2006
-
[33]
G., Z HU, Y., YEONGJAE JEON , Q IAN , J., L IU, H., AND GUO, C
G U, J., C HOWDHURY , M., S HIN , K. G., Z HU, Y., YEONGJAE JEON , Q IAN , J., L IU, H., AND GUO, C. Tiresias: A gpu cluster manager for distributed deep learning. In Symposium on Networked Systems Design and Implementation (NSDI 19) (2019)
work page 2019
-
[34]
Deep residual learning for image recognition
H E, K., Z HANG , X., R EN, S., AND SUN, J. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(June 2016), pp. 770–778
work page 2016
-
[35]
HO, Q., C IPAR, J., C UI, H., K IM, J. K., L EE, S., G IBBONS , P. B., G IBSON , G. A., G ANGER , G. R., AND XING , E. P. More effective distributed ml via a stale synchronous parallel parameter server. In Proceedings of the 26th International Conference on Neural Information Processing Systems (USA, 2013), NIPS’13, Curran Associates Inc., pp. 1223–1231
work page 2013
-
[36]
K., H O, Q., L EE, S., Z HENG , X., D AI, W., GIBSON , G
K IM, J. K., H O, Q., L EE, S., Z HENG , X., D AI, W., GIBSON , G. A., AND XING , E. P. STRADS: a distributed framework for scheduled model parallel machine learning. In Proceedings of the Eleventh European Conference on Computer Systems, EuroSys 2016, London, United Kingdom, April 18-21, 2016 (2016), pp. 5:1–5:16
work page 2016
-
[37]
L I, M., A NDERSEN , D. G., P ARK , J. W., S MOLA , A. J., AHMED , A., J OSIFOVSKI , V., L ONG , J., S HEKITA , E. J., AND SU, B.-Y. Scaling distributed machine learning with the parameter server. In 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14) (Broomfield, CO, Oct. 2014), USENIX Association, pp. 583–598
work page 2014
-
[38]
Asynchronous decentralized parallel stochastic gradient descent
L IAN , X., Z HANG , W., Z HANG , C., AND LIU, J. Asynchronous decentralized parallel stochastic gradient descent. In International Conference on Machine Learning (2018)
work page 2018
-
[39]
L IU, Z., Z HANG , Y., C HANG , E. Y., AND SUN, M. Plda+: Parallel latent dirichlet allocation with data placement and pipeline processing. ACM Transactions on Intelligent Systems and Technology, special issue on Large Scale Machine Learning (2011). Software available at https://github.com/openbigdatagroup/plda
work page 2011
-
[40]
N OCEDAL , J., AND WRIGHT , S. J. Numerical optimization (2nd edition), 2006
work page 2006
-
[41]
Optimus: An efficient dynamic resource scheduler for deep learning clusters
P ENG , Y., BAO, Y., C HEN , Y., W U, C., AND GUO, C. Optimus: An efficient dynamic resource scheduler for deep learning clusters. In Proceedings of the Thirteenth EuroSys Conference (New York, NY , USA, 2018), EuroSys ’18, ACM, pp. 3:1–3:14
work page 2018
-
[42]
Minimizing the total weighted completion time of coflows in datacenter networks
Q IU, Z., S TEIN , C., AND ZHONG , Y. Minimizing the total weighted completion time of coflows in datacenter networks. In SPAA (2015)
work page 2015
-
[43]
Hogwild: A lock-free approach to parallelizing stochastic gradient descent
R ECHT , B., R E, C., W RIGHT , S., AND NIU, F. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Advances in Neural Information Processing Systems 24, J. Shawe-Taylor, R. S. Zemel, P. L. Bartlett, F. Pereira, and K. Q. Weinberger, Eds. Curran Associates, Inc., 2011, pp. 693–701
work page 2011
-
[44]
S EIDE , F., F U, H., D ROPPO , J., L I, G., AND YU, D. 1-bit stochastic gradient descent and application to data-parallel distributed training of speech dnns. In Interspeech 2014 (September 2014)
work page 2014
-
[45]
S RA, S., Y U, A. W., L I, M., AND SMOLA , A. J. Adadelay: Delay adaptive distributed stochastic optimization. In AISTATS (2016)
work page 2016
-
[46]
VAN RENESSE , R., AND SCHNEIDER , F. B. Chain replication for supporting high throughput and availability. In Proceedings of the 6th Conference on Symposium on Opearting Systems Design & Implementation - Volume 6 (Berkeley, CA, USA, 2004), OSDI’04, USENIX Association, pp. 7–7
work page 2004
-
[47]
W EI, J., D AI, W., Q IAO, A., H O, Q., C UI, H., G ANGER , G. R., G IBBONS , P. B., G IBSON , G. A., AND XING , E. P. Managed communication and consistency for fast data-parallel iterative analytics. In Proceedings of the Sixth ACM Symposium on Cloud Computing (New York, NY , USA, 2015), SoCC ’15, ACM, pp. 381–394
work page 2015
-
[48]
Gandiva: Introspective cluster scheduling for deep learning
X IAO, W., B HARDWAJ , R., R AMJEE , R., S IVATHANU , M., KWATRA, N., H AN, Z., P ATEL, P., P ENG , X., Z HAO, H., ZHANG , Q., Y ANG , F., AND ZHOU , L. Gandiva: Introspective cluster scheduling for deep learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (Berkeley, CA, USA, 2018), OSDI’18, USENIX Associat...
work page 2018
-
[49]
YellowFin and the Art of Momentum Tuning
Z HANG , J., AND MITLIAGKAS , I. YellowFin and the Art of Momentum Tuning. ArXiv e-prints (June 2017)
work page 2017
-
[50]
RAPIER: Integrating routing and scheduling for coflow-aware data center networks
Z HAO, Y., C HEN , K., B AI, W., T IAN , C., G ENG , Y., ZHANG , Y., L I, D., AND WANG , S. RAPIER: Integrating routing and scheduling for coflow-aware data center networks. In INFOCOM (2015). 13
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.