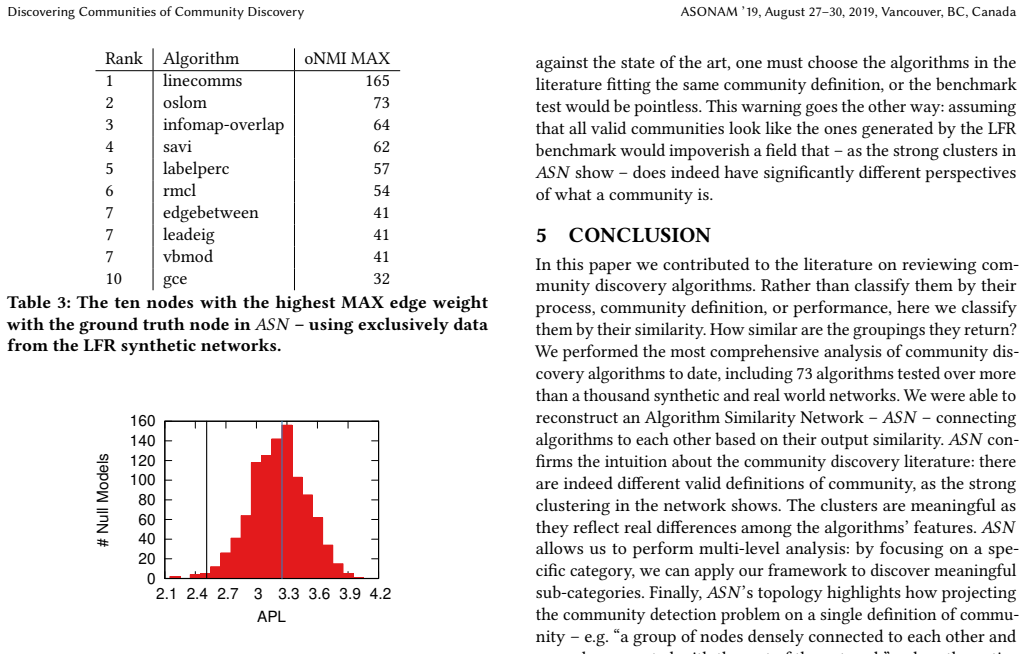
Discovering Communities of Community Discovery
Pith reviewed 2026-05-25 08:41 UTC · model grok-4.3
The pith
Community detection algorithms form distinct groups when linked by the similarity of the partitions they return across thousands of networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By building an Algorithm Similarity Network in which algorithms are connected when they produce comparable partitions on the same collection of networks, and by detecting communities within that network, the work shows that more than seventy community detection methods fall into well-separated groups according to the empirical similarity of their outputs.
What carries the argument
The Algorithm Similarity Network (ASN), whose edges are determined by the similarity of output partitions across a large collection of input networks.
If this is right
- Algorithms placed in the same group will tend to return comparable results on previously unseen networks.
- Different groups correspond to measurably distinct operational definitions of community structure.
- A practitioner can restrict testing to one representative from each group instead of evaluating every available method.
- The empirical grouping offers a data-driven complement to classifications based on algorithmic mechanics or theoretical definitions.
Where Pith is reading between the lines
- The same construction could be applied to other families of network algorithms to produce empirical taxonomies of their behavior.
- If the groups remain stable under modest changes in the similarity metric, they may indicate a small number of fundamentally distinct ways to partition networks in practice.
- The ASN could serve as a recommendation system that suggests alternative algorithms once a user has tried one member of a group.
Load-bearing premise
Similarity of the partitions returned by different algorithms on the chosen networks reflects stable differences between the algorithms themselves rather than depending on the particular networks or similarity measure used.
What would settle it
Repeating the entire procedure on a fresh collection of networks and obtaining entirely different clusters of algorithms would falsify the claim that the groups are intrinsic.
Figures




read the original abstract
Discovering communities in complex networks means grouping nodes similar to each other, to uncover latent information about them. There are hundreds of different algorithms to solve the community detection task, each with its own understanding and definition of what a "community" is. Dozens of review works attempt to order such a diverse landscape -- classifying community discovery algorithms by the process they employ to detect communities, by their explicitly stated definition of community, or by their performance on a standardized task. In this paper, we classify community discovery algorithms according to a fourth criterion: the similarity of their results. We create an Algorithm Similarity Network (ASN), whose nodes are the community detection approaches, connected if they return similar groupings. We then perform community detection on this network, grouping algorithms that consistently return the same partitions or overlapping coverage over a span of more than one thousand synthetic and real world networks. This paper is an attempt to create a similarity-based classification of community detection algorithms based on empirical data. It improves over the state of the art by comparing more than seventy approaches, discovering that the ASN contains well-separated groups, making it a sensible tool for practitioners, aiding their choice of algorithms fitting their analytic needs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes classifying community detection algorithms empirically by the similarity of their output partitions rather than by theoretical definitions or performance on benchmarks. It constructs an Algorithm Similarity Network (ASN) whose nodes are over 70 algorithms; edges connect algorithms that produce similar groupings. Community detection is then performed on the ASN using results from more than 1000 synthetic and real-world networks. The central claim is that the resulting ASN contains well-separated groups, making the ASN a practical tool for practitioners to choose algorithms matching their analytic needs.
Significance. If the separation is shown to be robust, the work supplies a large-scale, behavior-based taxonomy that complements existing reviews. The scale (70+ algorithms, >1000 networks) is a clear strength and provides concrete empirical data on algorithm similarity. The approach is falsifiable in principle and could guide practitioners, but the absence of methodological details prevents assessment of whether the groups reflect intrinsic algorithm differences.
major comments (2)
- [Abstract] Abstract: the claim that the ASN 'contains well-separated groups' supplies no information on the partition similarity measure, the criteria used to select the >1000-network corpus, any statistical validation of cluster separation, or sensitivity checks. Without these the central empirical claim cannot be evaluated.
- The manuscript does not test whether the recovered groups remain stable when the meta-community-detection method applied to the ASN or the underlying partition similarity function is varied. This directly affects the practitioner-utility argument that the groups capture intrinsic algorithm distinctions rather than artifacts of the chosen corpus and meta-method.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, agreeing where revisions are needed to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the ASN 'contains well-separated groups' supplies no information on the partition similarity measure, the criteria used to select the >1000-network corpus, any statistical validation of cluster separation, or sensitivity checks. Without these the central empirical claim cannot be evaluated.
Authors: We agree the abstract is insufficiently detailed. In the revised version we will expand it to specify the partition similarity measure (Normalized Mutual Information), the corpus selection criteria (balanced coverage of LFR synthetic networks with varied mixing parameters plus real networks spanning social, biological and technological domains), the statistical validation of separation (silhouette scores on the ASN plus significance testing against randomized baselines), and explicit references to the sensitivity analyses already present in the methods and appendix. revision: yes
-
Referee: The manuscript does not test whether the recovered groups remain stable when the meta-community-detection method applied to the ASN or the underlying partition similarity function is varied. This directly affects the practitioner-utility argument that the groups capture intrinsic algorithm distinctions rather than artifacts of the chosen corpus and meta-method.
Authors: This is a fair observation on robustness. We will add a dedicated subsection reporting new experiments that recompute the ASN under alternative similarity functions (Adjusted Rand Index and Variation of Information) and apply different meta-community detection algorithms (Louvain and spectral clustering). Agreement between the resulting partitions will be quantified via normalized mutual information; we will show that the primary clusters remain consistent, supporting that they reflect intrinsic algorithmic behavior rather than corpus or method artifacts. revision: yes
Circularity Check
No circularity: direct empirical comparison of algorithm outputs
full rationale
The paper constructs the ASN by running >70 algorithms on >1000 networks, computing partition similarities, and applying community detection to the resulting graph. No equations, fitted parameters, or self-citations reduce the reported clusters to quantities defined from the same data by construction. The separation claim is an observed empirical outcome, independently checkable by re-running the comparison pipeline, with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Similarity of community partitions produced by different algorithms across a broad set of networks is a meaningful basis for grouping the algorithms themselves.
invented entities (1)
-
Algorithm Similarity Network (ASN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
YY Ahn, JP Bagrow, and S Lehmann. 2010. Link communities reveal multiscale complexity in networks. nature 466 (2010), 761
work page 2010
-
[2]
Alessia Amelio and Clara Pizzuti. 2014. Overlapping community discovery methods: A survey. In Social Networks: Analysis and Case Studies . Springer, 105–125
work page 2014
-
[3]
B Ball, B Karrer, and MEJ Newman. 2011. Efficient and principled method for detecting communities in networks. PRE 84, 3 (2011)
work page 2011
-
[4]
Qing Cai, Lijia Ma, Maoguo Gong, and Dayong Tian. 2016. A survey on network community detection based on evolutionary computation. IJBIC 8, 2 (2016), 84–98
work page 2016
-
[5]
Gennaro Cordasco and Luisa Gargano. 2010. Community detection via semi- synchronous label propagation algorithms. In BASNA. IEEE, 1–8
work page 2010
-
[6]
Michele Coscia, Fosca Giannotti, and Dino Pedreschi. 2011. A classification for community discovery methods in complex networks. SADM 4, 5 (2011), 512–546
work page 2011
-
[7]
Michele Coscia and Frank MH Neffke. 2017. Network backboning with noisy data. In ICDE. IEEE, 425–436. ASONAM ’19, August 27–30, 2019, Vancouver, BC, Canada Michele Coscia
work page 2017
-
[8]
Michele Coscia, Giulio Rossetti, Fosca Giannotti, and Dino Pedreschi. 2012. De- mon: a local-first discovery method for overlapping communities. In SIGKDD. ACM, 615–623
work page 2012
-
[9]
Leon Danon, Albert Diaz-Guilera, Jordi Duch, and Alex Arenas. 2005. Comparing community structure identification. Statistical Mechanics: Theory and Experiment 09 (2005), P09008
work page 2005
- [10]
-
[11]
Vinh-Loc Dao, Cécile Bothorel, and Philippe Lenca. 2018. Estimating the sim- ilarity of community detection methods based on cluster size distribution. In International Workshop on Complex Networks and their Applications . Springer, 183–194
work page 2018
-
[12]
TS Evans and R Lambiotte. 2009. Line graphs, link partitions, and overlapping communities. PRE 80, 1 (2009), 016105
work page 2009
- [13]
-
[14]
Santo Fortunato. 2010. Community detection in graphs. Physics reports 486, 3-5 (2010), 75–174
work page 2010
-
[15]
Santo Fortunato and Darko Hric. 2016. Community detection in networks: A user guide. Physics Reports 659 (2016), 1–44
work page 2016
- [16]
-
[17]
Steve Harenberg, Gonzalo Bello, L Gjeltema, Stephen Ranshous, Jitendra Harlalka, Ramona Seay, Kanchana Padmanabhan, and Nagiza Samatova. 2014. Community detection in large-scale networks: a survey and empirical evaluation. Wiley Interdisciplinary Reviews: Computational Statistics 6, 6 (2014), 426–439
work page 2014
-
[18]
Darko Hric, Richard K Darst, and Santo Fortunato. 2014. Community detection in networks: Structural communities versus ground truth. Physical Review E 90, 6 (2014), 062805
work page 2014
-
[19]
J Kim and J-G Lee. 2015. Community detection in multi-layer graphs: A survey. SIGMOD Record 44, 3 (2015), 37–48
work page 2015
-
[20]
A Lancichinetti and S Fortunato. 2009. Community detection algorithms: a comparative analysis. PRE 80, 5 (2009), 056117
work page 2009
-
[21]
Andrea Lancichinetti, Santo Fortunato, and János Kertész. 2009. Detecting the overlapping and hierarchical community structure in complex networks. New Journal of Physics 11, 3 (2009), 033015
work page 2009
-
[22]
Andrea Lancichinetti, Santo Fortunato, and Filippo Radicchi. 2008. Benchmark graphs for testing community detection algorithms. Physical review E 78, 4 (2008), 046110
work page 2008
-
[23]
A Lázár, D Ábel, and T Vicsek. 2010. Modularity measure of networks with overlapping communities. EPL 90, 1 (2010), 18001
work page 2010
-
[24]
Jure Leskovec, Kevin J Lang, and Michael Mahoney. 2010. Empirical comparison of algorithms for network community detection. In WWW. ACM, 631–640
work page 2010
-
[25]
Fragkiskos D Malliaros and Michalis Vazirgiannis. 2013. Clustering and com- munity detection in directed networks: A survey. Physics Reports 533, 4 (2013), 95–142
work page 2013
-
[26]
Aaron F McDaid, Derek Greene, and Neil Hurley. 2011. Normalized mutual in- formation to evaluate overlapping community finding algorithms. arXiv preprint arXiv:1110.2515 (2011)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[27]
MEJ Newman and M Girvan. 2004. Finding and evaluating community structure in networks. PRE 69, 2 (2004), 026113
work page 2004
-
[28]
Mark EJ Newman. 2004. Detecting community structure in networks. The European Physical Journal B 38, 2 (2004), 321–330
work page 2004
-
[29]
Mark EJ Newman. 2006. Modularity and community structure in networks.PNAS 103, 23 (2006), 8577–8582
work page 2006
-
[30]
Günce Keziban Orman and Vincent Labatut. 2009. A comparison of community detection algorithms on artificial networks. In DS. Springer, 242–256
work page 2009
-
[31]
Gergely Palla, Imre Derényi, Illés Farkas, and Tamás Vicsek. 2005. Uncovering the overlapping community structure of complex networks in nature and society. Nature 435, 7043 (2005), 814
work page 2005
-
[32]
S Parthasarathy, Y Ruan, and V Satuluri. 2011. Community discovery in social networks: Applications, methods and emerging trends. In Social network data analytics. Springer, 79–113
work page 2011
-
[33]
Clara Pizzuti. 2009. Overlapped community detection in complex networks. In GECCO. ACM, 859–866
work page 2009
-
[34]
P Pons and M Latapy. 2005. Computing communities in large networks using random walks. In ISCIS. Springer, 284–293
work page 2005
-
[35]
MA Porter, J-P Onnela, and PJ Mucha. 2009. Communities in networks. Notices of the AMS 56, 9 (2009), 1082–1097
work page 2009
-
[36]
Usha Nandini Raghavan, Réka Albert, and Soundar Kumara. 2007. Near linear time algorithm to detect community structures in large-scale networks. Physical review E 76, 3 (2007), 036106
work page 2007
-
[37]
G Rossetti and R Cazabet. 2018. Community discovery in dynamic networks: a survey. Comput. Surveys 51, 2 (2018), 35
work page 2018
-
[38]
Martin Rosvall and Carl T Bergstrom. 2008. Maps of random walks on complex networks reveal community structure. PNAS 105, 4 (2008), 1118–1123
work page 2008
-
[39]
Satu Elisa Schaeffer. 2007. Graph clustering. Computer science review 1, 1 (2007), 27–64
work page 2007
-
[40]
Nguyen Xuan Vinh, Julien Epps, and James Bailey. 2010. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. Journal of Machine Learning Research 11, Oct (2010), 2837–2854
work page 2010
-
[41]
J Xie, S Kelley, and BK Szymanski. 2013. Overlapping community detection in networks: The state-of-the-art and comparative study. Acm computing surveys (csur) 45, 4 (2013), 43
work page 2013
-
[42]
Jierui Xie and Boleslaw K Szymanski. 2013. Labelrank: A stabilized label propa- gation algorithm for community detection in networks. In NSW. IEEE, 138–143
work page 2013
-
[43]
Jaewon Yang and Jure Leskovec. 2013. Overlapping community detection at scale: a nonnegative matrix factorization approach. In WSDM. ACM, 587–596
work page 2013
-
[44]
Zhao Yang, René Algesheimer, and Claudio J Tessone. 2016. A comparative analysis of community detection algorithms on artificial networks. Scientific Reports 6 (2016), 30750
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.