Environment Reconstruction with Hidden Confounders for Reinforcement Learning based Recommendation
Pith reviewed 2026-05-24 22:35 UTC · model grok-4.3
The pith
Treating the hidden confounder as a separate policy in multi-agent GAIL allows reconstruction of environments for RL recommendations despite unobserved variables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DEMER introduces a confounder-embedded policy and a compatible discriminator inside the multi-agent GAIL framework so that the hidden confounder can be learned alongside the main environment dynamics; experiments show this recovers the confounder effectively and yields recommendation policies with significantly higher performance in the real-application test phase.
What carries the argument
The confounder-embedded policy together with its compatible discriminator inside the multi-agent generative adversarial imitation learning framework, which separates observed transition dynamics from confounding effects.
If this is right
- Reconstructed environments can be used to train RL recommendation policies without incurring exploration costs in the live system.
- Isolating the hidden confounder produces environment models that more closely match the true data-generating process.
- The resulting policies achieve measurably higher performance when deployed back into the original recommendation application.
- The same multi-agent GAIL structure can be reused for other sequential decision tasks that suffer from unobserved confounders in logged data.
Where Pith is reading between the lines
- The same framing might be applied to non-recommendation RL domains that rely on offline data with hidden selection biases.
- If the confounder turns out to be time-varying rather than stationary, an extension with recurrent hidden policies could be tested.
- The approach suggests that other imitation-learning methods could also benefit from explicitly modeling an adversary as a hidden policy rather than as unstructured noise.
Load-bearing premise
The hidden confounder can be represented and recovered as a separate hidden policy that is compatible with the multi-agent generative adversarial imitation learning framework.
What would settle it
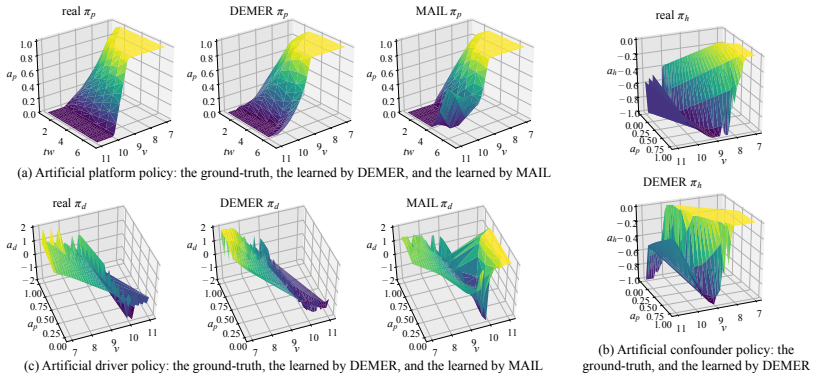
In the artificial driver-program environment where the true confounder is known, the method would be falsified if the recovered hidden policy fails to match the known confounder or if the final recommendation policy shows no performance gain over standard reconstruction baselines in the real Didi Chuxing test phase.
Figures









read the original abstract
Reinforcement learning aims at searching the best policy model for decision making, and has been shown powerful for sequential recommendations. The training of the policy by reinforcement learning, however, is placed in an environment. In many real-world applications, however, the policy training in the real environment can cause an unbearable cost, due to the exploration in the environment. Environment reconstruction from the past data is thus an appealing way to release the power of reinforcement learning in these applications. The reconstruction of the environment is, basically, to extract the casual effect model from the data. However, real-world applications are often too complex to offer fully observable environment information. Therefore, quite possibly there are unobserved confounding variables lying behind the data. The hidden confounder can obstruct an effective reconstruction of the environment. In this paper, by treating the hidden confounder as a hidden policy, we propose a deconfounded multi-agent environment reconstruction (DEMER) approach in order to learn the environment together with the hidden confounder. DEMER adopts a multi-agent generative adversarial imitation learning framework. It proposes to introduce the confounder embedded policy, and use the compatible discriminator for training the policies. We then apply DEMER in an application of driver program recommendation. We firstly use an artificial driver program recommendation environment, abstracted from the real application, to verify and analyze the effectiveness of DEMER. We then test DEMER in the real application of Didi Chuxing. Experiment results show that DEMER can effectively reconstruct the hidden confounder, and thus can build the environment better. DEMER also derives a recommendation policy with a significantly improved performance in the test phase of the real application.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DEMER, a deconfounded multi-agent environment reconstruction method for RL-based recommendation. It models the hidden confounder as an additional policy within a multi-agent GAIL framework, introducing a confounder-embedded policy and compatible discriminator to jointly learn environment dynamics and the confounder from observational data. Experiments on an artificial driver recommendation environment (abstracted from real applications) and real Didi Chuxing data are used to verify confounder reconstruction and derive an improved recommendation policy.
Significance. If the central claim holds, the work would offer a practical approach to offline environment reconstruction for sequential recommendation under unobserved confounding, a common issue in real-world RL recsys. The multi-agent GAIL framing for deconfounding could enable more robust policy learning without online interaction costs.
major comments (2)
- [§3] §3: Framing the hidden confounder explicitly as an additional policy in the multi-agent GAIL objective (with confounder-embedded policy and compatible discriminator) permits matching of observed trajectories but supplies no identifiability result. Multiple distinct confounder policies can induce identical marginal transition distributions on the observed state-action space, so the setup risks confirming improved observational fit rather than recovery of causal dynamics.
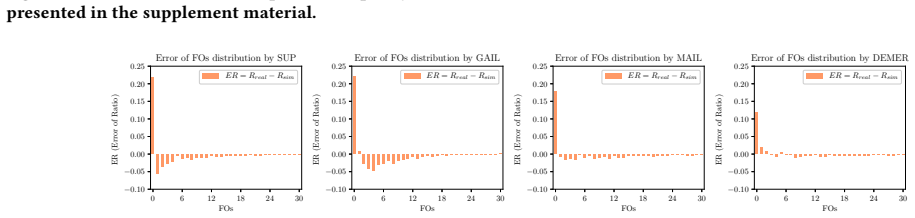
- [§4] §4: The artificial-environment verification and real-application results report improved performance but contain no sensitivity analysis to alternative confounder structures or tests that would distinguish successful deconfounding from mere predictive improvement on the observed data.
minor comments (1)
- The abstract supplies no quantitative metrics, baselines, ablation studies, or specific performance numbers, which obscures the strength of the experimental claims until the results sections are examined.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3] Framing the hidden confounder explicitly as an additional policy in the multi-agent GAIL objective (with confounder-embedded policy and compatible discriminator) permits matching of observed trajectories but supplies no identifiability result. Multiple distinct confounder policies can induce identical marginal transition distributions on the observed state-action space, so the setup risks confirming improved observational fit rather than recovery of causal dynamics.
Authors: We acknowledge that the manuscript does not contain a formal identifiability theorem guaranteeing unique recovery of the confounder policy. The multi-agent GAIL formulation with the confounder-embedded policy and compatible discriminator is intended to jointly optimize the observed dynamics and the hidden confounder so that the reconstructed environment supports improved downstream policies. While multiple confounder policies may be consistent with the same marginals, the adversarial objective and the explicit separation of agents encourage recovery of a confounder that explains sequential dependencies relevant to recommendation. We will add a dedicated limitations paragraph discussing the absence of identifiability guarantees and the distinction between observational fit and causal recovery. revision: partial
-
Referee: [§4] The artificial-environment verification and real-application results report improved performance but contain no sensitivity analysis to alternative confounder structures or tests that would distinguish successful deconfounding from mere predictive improvement on the observed data.
Authors: We agree that the current experiments would be strengthened by sensitivity analyses and explicit tests separating deconfounding from predictive gains. In the revised manuscript we will add (i) experiments on the artificial environment varying the number of hidden confounder states and alternative policy parameterizations, and (ii) comparisons against purely predictive baselines that improve observational likelihood without an explicit confounder agent. We will also report policy performance under simulated interventions to provide evidence that the gains arise from better causal reconstruction rather than marginal fit alone. revision: yes
Circularity Check
No circularity: derivation chain not reducible to inputs by construction
full rationale
The provided abstract and description introduce DEMER via a multi-agent GAIL framework treating the confounder as a hidden policy with a compatible discriminator, but contain no equations, fitted parameters, or derivations. No self-definitional steps (e.g., defining X in terms of Y then claiming X derives Y), no fitted inputs renamed as predictions, and no load-bearing self-citations or uniqueness theorems are present. The method description remains at the level of framework adoption without showing any reduction of outputs to inputs by construction. The skeptic concern addresses identifiability and lack of proof rather than circularity in the derivation itself. The paper is therefore self-contained against the circularity criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brenna Argall, Sonia Chernova, Manuela M. Veloso, and Brett Browning. 2009. A survey of robot learning from demonstration. Robotics and Autonomous Systems 57, 5 (2009), 469–483
work page 2009
-
[2]
Elias Bareinboim, Andrew Forney, and Judea Pearl. 2015. Bandits with Unob- served Confounders: A Causal Approach. In Advances in Neural Information Processing Systems 28. 1342–1350
work page 2015
-
[3]
Chelsea Finn, Paul F. Christiano, Pieter Abbeel, and Sergey Levine. 2016. A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models. arXiv abs/1611.03852 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Andrew Forney, Judea Pearl, and Elias Bareinboim. 2017. Counterfactual Data- Fusion for Online Reinforcement Learners. InProceedings of the 34th International Conference on Machine Learning . 1156–1164
work page 2017
-
[5]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. 2014. Generative Adver- sarial Nets. In Advances in Neural Information Processing Systems 27 . 2672–2680
work page 2014
-
[6]
Jonathan Ho and Stefano Ermon. 2016. Generative Adversarial Imitation Learning. In Advances in Neural Information Processing Systems 29 . 4565–4573
work page 2016
-
[7]
Mooij, David Sontag, Richard S
Christos Louizos, Uri Shalit, Joris M. Mooij, David Sontag, Richard S. Zemel, and Max Welling. 2017. Causal Effect Inference with Deep Latent-Variable Models. In Advances in Neural Information Processing Systems 30 . 6449–6459
work page 2017
-
[8]
Chaochao Lu, Bernhard Schölkopf, and José Miguel Hernández-Lobato. 2018. Deconfounding Reinforcement Learning in Observational Settings. arXiv abs/1812.10576 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Jacob Menick and Nal Kalchbrenner. 2018. Generating High Fidelity Images with Subscale Pixel Networks and Multidimensional Upscaling. arXiv abs/1812.01608 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin A. Riedmiller, Andreas Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. 2015. Human-level control through deep reinforce...
work page 2015
-
[11]
Judea Pearl. 2009. Causal inference in statistics: An overview. Statistics surveys 3 (2009), 96–146
work page 2009
-
[12]
Dean Pomerleau. 1991. Efficient Training of Artificial Neural Networks for Autonomous Navigation. Neural Computation 3, 1 (1991), 88–97
work page 1991
-
[13]
Stéphane Ross, Geoffrey J. Gordon, and Drew Bagnell. 2011. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. 627–635
work page 2011
-
[14]
Stuart J. Russell. 1998. Learning Agents for Uncertain Environments (Extended Abstract). In Proceedings of the Eleventh Annual Conference on Computational Learning Theory. 101–103
work page 1998
-
[15]
Stefan Schaal. 1999. Is imitation learning the route to humanoid robots? Trends in cognitive sciences 3, 6 (1999), 233–242
work page 1999
-
[16]
John Schulman, Sergey Levine, Pieter Abbeel, Michael I. Jordan, and Philipp Moritz. 2015. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July
work page 2015
-
[17]
Jing-Cheng Shi, Yang Yu, Qing Da, Shi-Yong Chen, and Anxiang Zeng. 2018. Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforce- ment Learning. arXiv abs/1805.10000 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Vedavyas Pan- neershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy P. Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. 2016. ...
work page 2016
-
[19]
Richard S. Sutton and Andrew G. Barto. 2018. Reinforcement Learning: An Intro- duction (2nd Edition). MIT Press
work page 2018
-
[20]
Zeyang Ye, Keli Xiao, Yong Ge, and Yuefan Deng. 2019. Applying Simulated Annealing and Parallel Computing to the Mobile Sequential Recommendation. IEEE Transactions on Knowledge and Data Engineering 31, 2 (2019), 243–256
work page 2019
-
[21]
Zeyang Ye, Lihao Zhang, Keli Xiao, Wenjun Zhou, Yong Ge, and Yuefan Deng
-
[22]
In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining
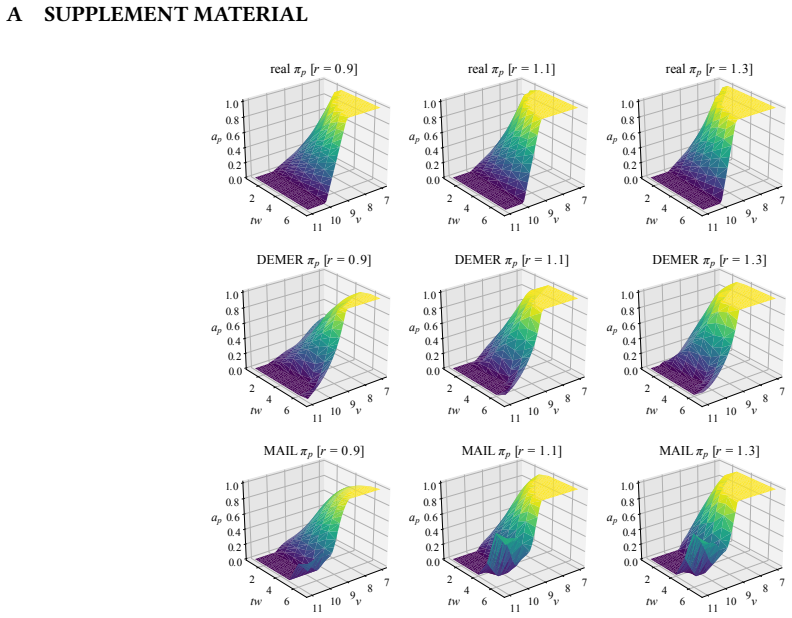
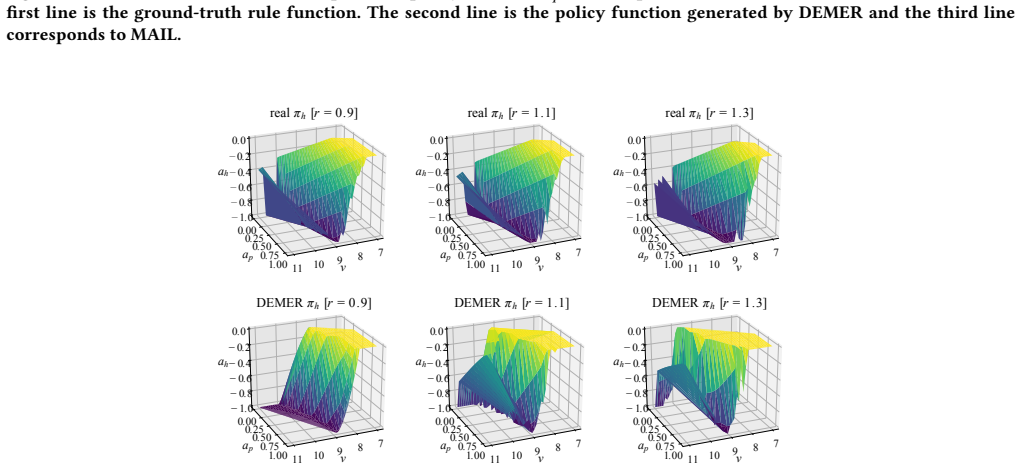
Multi-User Mobile Sequential Recommendation: An Efficient Parallel Computing Paradigm. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining . 2624–2633. A SUPPLEMENT MATERIAL v 7891011tw 2 4 6 ap 0.0 0.2 0.4 0.6 0.8 1.0 real πp [r = 0 .9] v 7891011tw 2 4 6 ap 0.0 0.2 0.4 0.6 0.8 1.0 real πp [r = 1 .1] v 78910...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.