DaiMoN: A Decentralized Artificial Intelligence Model Network
Pith reviewed 2026-05-24 19:17 UTC · model grok-4.3
The pith
DaiMoN lets peers verify machine learning model accuracy improvements without access to the test labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
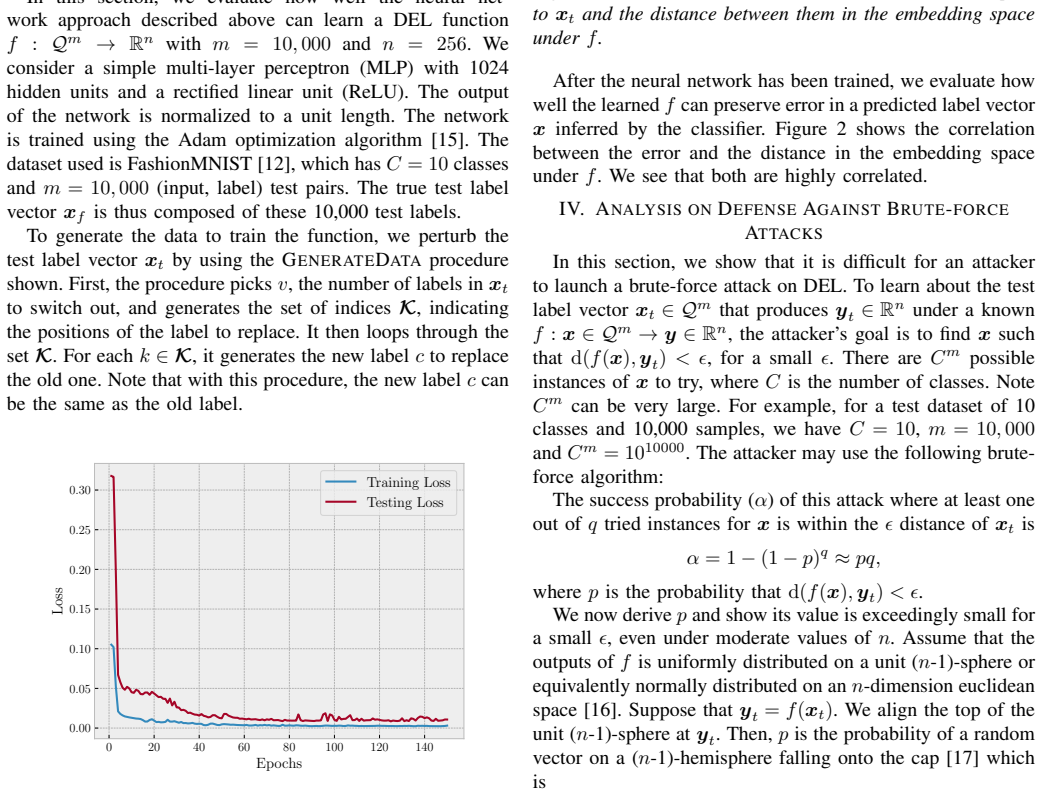
DaiMoN maintains a decentralized ledger of model improvements and uses a learnable Distance Embedding for Labels (DEL) to enable proof-of-improvement without access to true test labels. DEL embeds the test label vector in a low-dimensional space while approximately preserving distances to a classifier's inferred label vector, allowing peers to evaluate accuracy gains. The paper supplies both analysis and empirical results showing that accuracy assessment stays accurate under DEL and that the embedding resists inversion attacks aimed at label recovery.
What carries the argument
The learnable Distance Embedding for Labels (DEL) function, which embeds a dataset's test label vector into low-dimensional space while approximately preserving distances to any classifier's output vector.
If this is right
- Peers can accurately assess model accuracy using only the DEL embedding.
- The append-only ledger permanently records who improved a model, when, by how much, and where the new model is stored.
- Cryptographic tokens reward contributors for verified accuracy gains.
- The system reduces the incentive for intentional overfitting because submitters cannot see the test labels.
Where Pith is reading between the lines
- The same embedding approach could be adapted to regression or ranking tasks if analogous distance-preserving maps can be learned.
- The ledger-plus-DEL pattern might support marketplaces in which any participant can propose and monetize incremental model updates.
- The requirement that DEL be dataset-specific suggests that each new test collection would need its own trained embedding before the network can operate on it.
Load-bearing premise
DEL approximately preserves distances between the true test label vector and a model's inferred label vector while remaining hard to invert.
What would settle it
An experiment in which accuracy scores computed from DEL embeddings systematically disagree with accuracy measured on the true hidden test labels, or in which the original test labels can be recovered from the DEL output with high fidelity.
Figures




read the original abstract
We introduce DaiMoN, a decentralized artificial intelligence model network, which incentivizes peer collaboration in improving the accuracy of machine learning models for a given classification problem. It is an autonomous network where peers may submit models with improved accuracy and other peers may verify the accuracy improvement. The system maintains an append-only decentralized ledger to keep the log of critical information, including who has trained the model and improved its accuracy, when it has been improved, by how much it has improved, and where to find the newly updated model. DaiMoN rewards these contributing peers with cryptographic tokens. A main feature of DaiMoN is that it allows peers to verify the accuracy improvement of submitted models without knowing the test labels. This is an essential component in order to mitigate intentional model overfitting by model-improving peers. To enable this model accuracy evaluation with hidden test labels, DaiMoN uses a novel learnable Distance Embedding for Labels (DEL) function proposed in this paper. Specific to each test dataset, DEL scrambles the test label vector by embedding it in a low-dimension space while approximately preserving the distance between the dataset's test label vector and a label vector inferred by the classifier. It therefore allows proof-of-improvement (PoI) by peers without providing them access to true test labels. We provide analysis and empirical evidence that under DEL, peers can accurately assess model accuracy. We also argue that it is hard to invert the embedding function and thus, DEL is resilient against attacks aiming to recover test labels in order to cheat. Our prototype implementation of DaiMoN is available at https://github.com/steerapi/daimon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DaiMoN, a decentralized network for collaborative improvement of ML classification models. Peers submit improved models and verify accuracy gains via a novel learnable Distance Embedding for Labels (DEL) that embeds test label vectors in low dimension while approximately preserving distances to a classifier's inferred labels, enabling proof-of-improvement without exposing true labels. An append-only decentralized ledger records contributions, improvements, and model locations; contributors are rewarded with cryptographic tokens. The abstract asserts that analysis and empirical evidence confirm DEL permits accurate accuracy assessment by peers and resists label-recovery attacks.
Significance. If the distance-preservation and inversion-resistance properties of DEL can be placed on firmer footing, DaiMoN would supply a concrete mechanism for decentralized, label-private model verification that could support blockchain-based collaborative ML. The public prototype implementation at the cited GitHub repository is a concrete asset that would allow independent reproduction.
major comments (3)
- [Abstract] Abstract: the central claim that 'analysis and empirical evidence' establish that peers can accurately assess model accuracy under DEL supplies neither equations defining the embedding, quantitative distortion bounds, datasets, nor error metrics; this absence directly undermines evaluation of the load-bearing distance-preservation property required for reliable proof-of-improvement.
- [Abstract] Abstract: the assertion that DEL 'is hard to invert' and therefore 'resilient against attacks aiming to recover test labels' is offered without a security reduction, formal hardness argument, or even the embedding dimension and training procedure; because the embedding is learned per test set, the lack of any concrete guarantee is load-bearing for the anti-cheating guarantee.
- [Abstract] Abstract: DEL is described as 'learnable' and 'specific to each test dataset,' yet no information is given on the training objective, the source of supervision for learning the embedding, or how the embedding is distributed to peers without leaking label information; these omissions affect both reproducibility and the claimed security properties.
minor comments (1)
- [Abstract] The abstract states that the ledger records 'who has trained the model' but does not clarify how authorship is authenticated or how the system prevents Sybil submissions of the same model under multiple identities.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the abstract to improve accessibility to the technical details while preserving its high-level nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'analysis and empirical evidence' establish that peers can accurately assess model accuracy under DEL supplies neither equations defining the embedding, quantitative distortion bounds, datasets, nor error metrics; this absence directly undermines evaluation of the load-bearing distance-preservation property required for reliable proof-of-improvement.
Authors: The abstract is a high-level summary. The DEL embedding equations, distortion bounds, datasets, and error metrics appear in Sections 3 and 4. We will revise the abstract to reference these sections and briefly note the demonstrated properties. revision: yes
-
Referee: [Abstract] Abstract: the assertion that DEL 'is hard to invert' and therefore 'resilient against attacks aiming to recover test labels' is offered without a security reduction, formal hardness argument, or even the embedding dimension and training procedure; because the embedding is learned per test set, the lack of any concrete guarantee is load-bearing for the anti-cheating guarantee.
Authors: The abstract omits these specifics. Section 3 defines the embedding dimension, training procedure, and provides an argument plus empirical evidence for inversion resistance. No formal security reduction is present; we will update the abstract to state the parameters and note that resilience rests on analysis and experiments rather than a formal reduction. revision: partial
-
Referee: [Abstract] Abstract: DEL is described as 'learnable' and 'specific to each test dataset,' yet no information is given on the training objective, the source of supervision for learning the embedding, or how the embedding is distributed to peers without leaking label information; these omissions affect both reproducibility and the claimed security properties.
Authors: Section 3 details the distance-preserving training objective, the form of supervision, and the ledger-based distribution of embedding parameters that avoids exposing original labels. We will revise the abstract to include concise statements on these points. revision: yes
Circularity Check
No significant circularity detected; DEL properties rest on internal analysis and experiments
full rationale
The paper introduces a novel DEL embedding as a new component and supports its distance-preservation and inversion-resistance claims via analysis and empirical evidence presented in the work itself. No equations reduce a claimed prediction to a fitted parameter by construction, no load-bearing self-citations are invoked for uniqueness or ansatz, and the verification mechanism does not rename or self-define prior results. The central claims therefore remain independent of the inputs they evaluate.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Distance Embedding for Labels (DEL) function
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DEL scrambles the test label vector by embedding it in a low-dimension space while approximately preserving the distance between the dataset's test label vector and a label vector inferred by the classifier... We provide analysis and empirical evidence that under DEL, peers can accurately assess model accuracy.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Finding such a distance-preserving embedding function f is generally a challenging mathematical problem. Fortunately, we have observed empirically that we can learn this xt-specific embedding function using a neural network.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bitcoin: A peer-to-peer electronic cash system,
S. Nakamoto, “Bitcoin: A peer-to-peer electronic cash system,” 2008
work page 2008
-
[2]
Ethereum: A secure decentralised generalised trans- action ledger,
G. Wood, “Ethereum: A secure decentralised generalised trans- action ledger,” Ethereum project yellow paper , vol. 151, pp. 1–32, 2014
work page 2014
-
[3]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[4]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
work page 2016
-
[5]
Going deeper with convolutions,
C. Szegedy, W. Liu, Y . Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V . Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2015, pp. 1–9
work page 2015
-
[6]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [7]
-
[8]
“PyTorch Model Zoo,” https://pytorch.org/docs/stable/ torchvision/models.html
-
[9]
Models and examples built with TensorFlow,
“Models and examples built with TensorFlow,” https://github. com/tensorflow/models
- [10]
-
[11]
“Kaggle,” https://www.kaggle.com
-
[12]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Extensions of lipschitz mappings into a hilbert space,
W. B. Johnson and J. Lindenstrauss, “Extensions of lipschitz mappings into a hilbert space,” Contemporary mathematics , vol. 26, no. 189-206, p. 1, 1984
work page 1984
-
[14]
Optimality of the johnson- lindenstrauss lemma,
K. G. Larsen and J. Nelson, “Optimality of the johnson- lindenstrauss lemma,” in 2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS) . IEEE, 2017, pp. 633–638
work page 2017
-
[15]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Limit theorems for uniform distributions on spheres in high-dimensional euclidean spaces,
A. Stam, “Limit theorems for uniform distributions on spheres in high-dimensional euclidean spaces,” Journal of Applied prob- ability, vol. 19, no. 1, pp. 221–228, 1982
work page 1982
-
[17]
Concise formulas for the area and volume of a hyper- spherical cap,
S. Li, “Concise formulas for the area and volume of a hyper- spherical cap,” Asian Journal of Mathematics and Statistics , vol. 4, no. 1, pp. 66–70, 2011
work page 2011
-
[18]
IPFS - Content Addressed, Versioned, P2P File System
J. Benet, “IPFS-content addressed, versioned, P2P file system,” arXiv preprint arXiv:1407.3561 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
The MD5 message-digest algorithm,
R. Rivest, “The MD5 message-digest algorithm,” Tech. Rep., 1992
work page 1992
- [20]
-
[21]
Cyclic codes for error detection,
W. W. Peterson and D. T. Brown, “Cyclic codes for error detection,” Proceedings of the IRE, vol. 49, no. 1, pp. 228–235, 1961
work page 1961
-
[22]
F. V ogelsteller and V . Buterin, “ERC-20 token standard, 2015,” URL https://github.com/ethereum/EIPs/blob/master/EIPS/eip- 20-token-standard.md, 2018
work page 2015
-
[23]
Learning internal representations by error propagation,
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning internal representations by error propagation,” California Univ San Diego La Jolla Inst for Cognitive Science, Tech. Rep., 1985
work page 1985
-
[24]
Filecoin: A decentralized storage network,
“Filecoin: A decentralized storage network,” URL https:// filecoin.io/filecoin.pdf , 2017
work page 2017
-
[25]
Storj a peer-to-peer cloud storage network,
S. Wilkinson, T. Boshevski, J. Brandoff, and V . Buterin, “Storj a peer-to-peer cloud storage network,” 2014
work page 2014
-
[26]
Approximate nearest neighbors: towards removing the curse of dimensionality,
P. Indyk and R. Motwani, “Approximate nearest neighbors: towards removing the curse of dimensionality,” in Proceedings of the thirtieth annual ACM symposium on Theory of computing. ACM, 1998, pp. 604–613
work page 1998
-
[27]
Locality- preserving hashing in multidimensional spaces,
P. Indyk, R. Motwani, P. Raghavan, and S. Vempala, “Locality- preserving hashing in multidimensional spaces,” in STOC, vol. 97. Citeseer, 1997, pp. 618–625
work page 1997
-
[28]
K. Zhao, H. Lu, and J. Mei, “Locality preserving hashing.” in AAAI, 2014, pp. 2874–2881
work page 2014
-
[29]
Similarity estimation techniques from rounding algorithms,
M. S. Charikar, “Similarity estimation techniques from rounding algorithms,” in Proceedings of the thiry-fourth annual ACM symposium on Theory of computing . ACM, 2002, pp. 380– 388
work page 2002
-
[30]
SingularityNET: A decentralized, open market and inter-network for AIs,
B. Goertzel, S. Giacomelli, D. Hanson, C. Pennachin, and M. Argentieri, “SingularityNET: A decentralized, open market and inter-network for AIs,” 2017
work page 2017
-
[31]
Effect network: Decen- tralized network for artificial intelligence,
J. Eisses, L. Verspeek, and C. Dawe, “Effect network: Decen- tralized network for artificial intelligence,” URL http://effect.ai/ download/effect whitepaper.pdf, 2018
work page 2018
-
[32]
Numeraire: A cryptographic token for coordinating machine intelligence and preventing overfitting,
R. Craib, G. Bradway, X. Dunn, and J. Krug, “Numeraire: A cryptographic token for coordinating machine intelligence and preventing overfitting,” Retrieved, vol. 23, p. 2018, 2017
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.