An empirical exploration of the diversified R ecosystem
Pith reviewed 2026-05-24 12:06 UTC · model grok-4.3
The pith
R started in statistics but draws its main development from computer science and its academic users from agriculture, biology, environment, and medicine.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
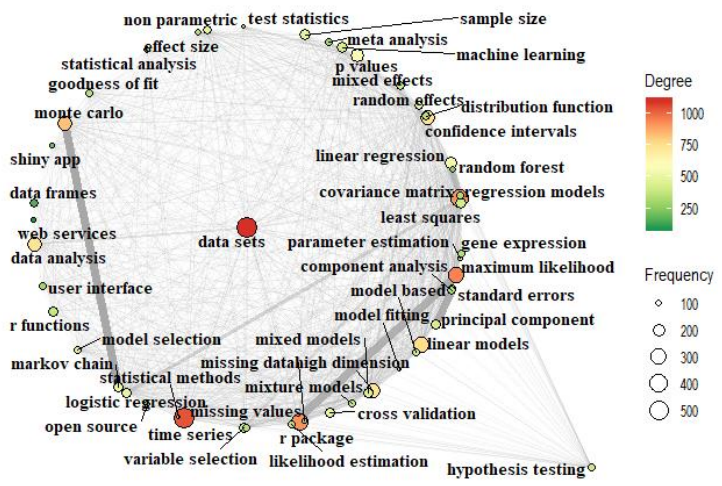
Based on the meta information of the Comprehensive R Archive Network (CRAN) and the bibliometric data of literature citing R, while R is initiated by statistics, its development is benefited greatly from computer science and the main user group in academics come from various disciplines such as agricultural science, biological science, environmental science and medical science. In addition, we displayed the collaboration patterns among R developers and analyze the possible effects of collaboration in the R community.
What carries the argument
Empirical mapping of CRAN package metadata together with bibliometric records of papers that cite R, used to identify disciplinary origins, user fields, and developer collaboration networks.
If this is right
- R functions as an interdisciplinary platform whose growth depends on contributions outside its founding field.
- Computer science supplies a larger share of ongoing package development than statistics itself.
- The heaviest academic uptake occurs in agricultural, biological, environmental, and medical research.
- Developer collaboration networks exist and can be examined for measurable effects on the R community.
- The same data sources allow tracking of how these patterns change over time.
Where Pith is reading between the lines
- The same combination of repository metadata and citation analysis could be applied to other open statistical environments to test whether they show similar cross-field spread.
- If collaboration effects prove positive, targeted support for cross-institutional R projects might accelerate package growth.
- Longitudinal versions of the CRAN-plus-citation dataset could reveal whether the user base continues to shift away from core statistics.
- Package dependency graphs inside CRAN might be combined with the author networks to identify which collaborations produce the most widely reused code.
Load-bearing premise
The CRAN package records and academic citation counts accurately represent the full scope of R's development, user base, and collaboration patterns without major selection or measurement biases.
What would settle it
A broad survey of active R users that finds the largest share come from statistics departments rather than the four listed applied-science fields, or a breakdown of CRAN package authors showing most contributions originate inside statistics rather than computer science.
Figures
read the original abstract
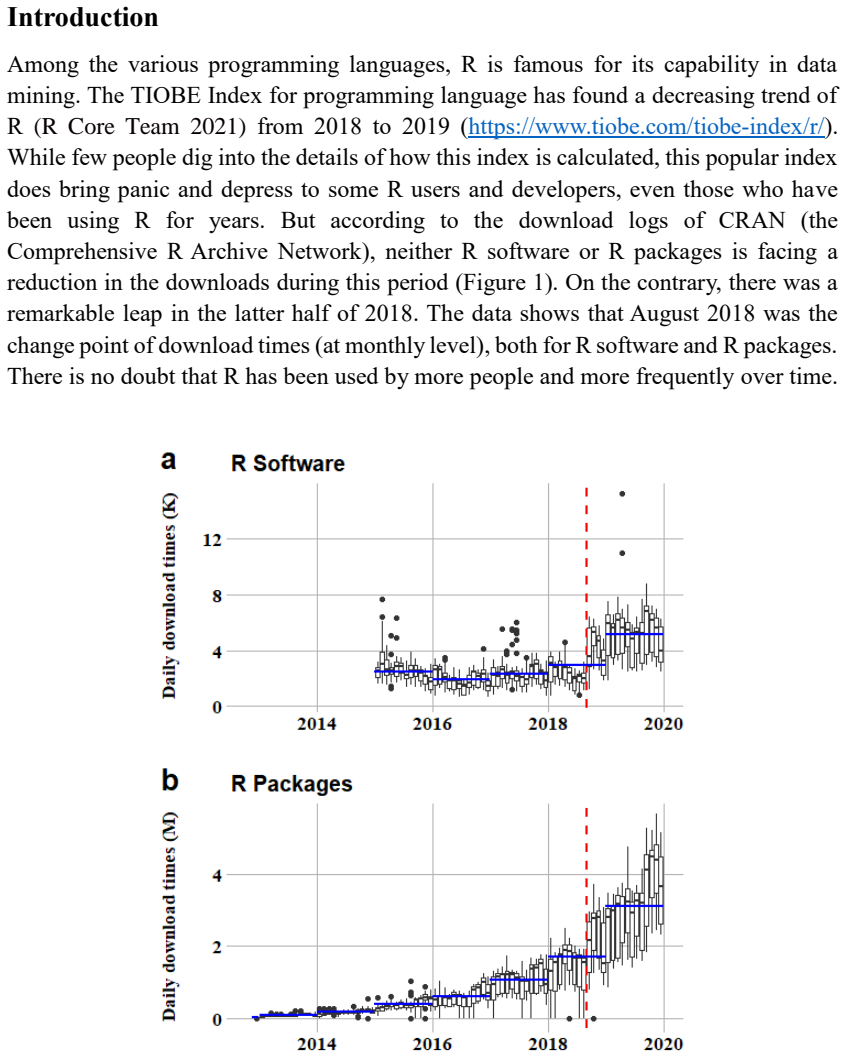
Born in the late 20s, R is one of the most popular software for statistical computing and graphics. With the development of information technology and the advent of the big data era, great changes have taken place in the R ecosystem. Based on the meta information of the Comprehensive R Archive Network (CRAN) and the bibliometric data of literature citing R, we discovered that while R is initiated by statistics, its development is benefited greatly from computer science and the main user group in academics come from various disciplines such as agricultural science, biological science, environmental science and medical science. In addition, we displayed the collaboration patterns among R developers and analyze the possible effects of collaboration in the R community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes CRAN package metadata and bibliometric records of literature citing R to explore the R ecosystem. It claims that R originated in statistics but has benefited substantially from computer science contributions, that the primary academic user groups are in agricultural, biological, environmental, and medical sciences, and that collaboration patterns among developers can be characterized with implications for the community.
Significance. If supported by transparent and bias-controlled methods, the work would provide a useful empirical map of the interdisciplinary spread and collaboration structure of the R ecosystem, complementing existing surveys with large-scale metadata. The use of public CRAN and citation data is a strength for reproducibility, but the current absence of processing details prevents assessment of whether the headline claims about user composition hold.
major comments (3)
- [Abstract / user-discipline results] Abstract and the section presenting user-discipline results: the claim that the main academic user groups come from agricultural, biological, environmental, and medical sciences rests on disciplinary classification of papers citing R, yet no description is given of how disciplines were assigned, how citation records were filtered or deduplicated, or how selection biases (field-specific citation norms, non-publishing users) were addressed. This directly undermines the central user-base claim.
- [Data sources and methods] The section on data sources and methods: the manuscript states conclusions from CRAN metadata and citation data but supplies no details on data acquisition dates, cleaning steps, statistical procedures, error handling, or controls for citation inflation and incomplete coverage. Without these, the support for all empirical claims cannot be evaluated.
- [Collaboration patterns] The collaboration-patterns analysis: the same citation-derived data source is used to examine developer collaborations and their effects, amplifying the risk that any unaddressed measurement biases in the bibliometric layer propagate to the collaboration conclusions.
minor comments (1)
- [Abstract] Abstract: 'Born in the late 20s' is unclear; the intended period (late 1990s or late twentieth century) should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which identify key areas where the manuscript requires greater methodological transparency. We agree that the current version does not supply sufficient detail on data processing and classification procedures, and we will revise the paper to address these points directly.
read point-by-point responses
-
Referee: [Abstract / user-discipline results] Abstract and the section presenting user-discipline results: the claim that the main academic user groups come from agricultural, biological, environmental, and medical sciences rests on disciplinary classification of papers citing R, yet no description is given of how disciplines were assigned, how citation records were filtered or deduplicated, or how selection biases (field-specific citation norms, non-publishing users) were addressed. This directly undermines the central user-base claim.
Authors: We acknowledge that the manuscript provides no description of the disciplinary classification method, citation filtering, deduplication, or bias mitigation steps. In the revised manuscript we will insert a new subsection under Methods that specifies the classification scheme (journal subject categories from the source database), the exact filtering and deduplication rules applied to the citation records, the date range of the data pull, and an explicit discussion of limitations arising from field-specific citation practices and the exclusion of non-publishing users. revision: yes
-
Referee: [Data sources and methods] The section on data sources and methods: the manuscript states conclusions from CRAN metadata and citation data but supplies no details on data acquisition dates, cleaning steps, statistical procedures, error handling, or controls for citation inflation and incomplete coverage. Without these, the support for all empirical claims cannot be evaluated.
Authors: We agree that the absence of these details prevents proper evaluation. The revised Methods section will report the precise acquisition dates for both CRAN metadata and the bibliometric records, all cleaning and preprocessing steps performed, any statistical procedures used, error-handling rules, and a dedicated paragraph addressing potential citation inflation and coverage gaps in the source databases. revision: yes
-
Referee: [Collaboration patterns] The collaboration-patterns analysis: the same citation-derived data source is used to examine developer collaborations and their effects, amplifying the risk that any unaddressed measurement biases in the bibliometric layer propagate to the collaboration conclusions.
Authors: We note that the collaboration analysis primarily draws on CRAN package maintainer and contributor metadata rather than citation records; however, the referee is correct that any bibliometric component could introduce bias. In revision we will (i) clearly separate the data sources used for each analysis, (ii) add explicit caveats about possible propagation of measurement error, and (iii) include a brief sensitivity check where feasible. We therefore mark this revision as partial because full elimination of all bibliometric bias may not be possible with the available data. revision: partial
Circularity Check
No circularity: empirical analysis relies on external public datasets
full rationale
The paper performs an empirical exploration using CRAN package metadata and bibliometric citation records as inputs. These are independent external data sources, not fitted parameters or self-referential models. No equations, predictions, or derivations reduce to the paper's own outputs by construction. No self-citation chains or ansatzes are invoked for load-bearing claims. The central findings on user disciplines and collaboration are direct summaries of the external data, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CRAN metadata and bibliometric citation data accurately reflect real-world R usage, development contributions, and academic user groups without significant biases
Reference graph
Works this paper leans on
-
[1]
Csá rdi, G. (2019). cranlogs: Download Logs from the RStudio 'CRAN' Mirror. https://CRAN.R - project.org/package=cranlogs. Decan, A., Mens, T., Claes, M., & Grosjean, P. (2015, September). On the development and distribution of R packages: An empirical analysis of the R ecosystem. In Proceedings of the 2015 european conference on software architecture wor...
work page 2019
-
[2]
Huang, T. (2020). akc: Automatic Knowledge Classification. https://github.com/hope-data-science/akc. Huber, W., V. J. Carey, R. Gentleman, S. Anders, M. Carlson, B. S. Carvalho, H. C. Bravo, S. Davis, L. Gatto, T. Girke, R. Gottardo, F. Hahne, K. D. Hansen, R. A. Irizarry, M. Lawrence, M. I. Love, J. MacDonald, V. Obenchain, A. K. Oleś, H. Pagès, A. Reyes...
work page 2020
-
[3]
Muschelli, J. (2019). rscopus: Scopus Database API Interface. https://CRAN.R - project.org/package=rscopus. Pebesma, E., D. Nü st & R. Bivand (2012) The R software environment in reproducible geoscientific research. Eos, Transactions American Geophysical Union, 93, 163-163. Pedersen, T. L. (2020). patchwork: The Composer of Plots. https://CRAN.R - project...
work page 2019
-
[4]
R Core Team. (2021). R: A Language and Environment for Statistical Computing. https://www.R - project.org/. Schoch, D. (2019). graphlayouts: Additional Lay out Algorithms for Network Visualizations. https://CRAN.R-project.org/package=graphlayouts. Spinu, V., G. Grolemund & H. Wickham. (2021). lubridate: Make Dealing with Dates a Little Easier. https://CRA...
work page 2021
-
[5]
Wuchty, S., Jones, B. F., & Uzzi, B. (2007). The Increasing Dominance of Teams in Production of Knowledge. SCIENCE, 316(5827), 1036-1039. http://doi.org/10.1126/science.1136099
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.