Accelerated Gradient Methods for Nonconvex Optimization: Escape Trajectories From Strict Saddle Points and Convergence to Local Minima
Pith reviewed 2026-05-24 07:48 UTC · model grok-4.3
The pith
Nesterov's accelerated gradient method with variable momentum avoids strict saddle points almost surely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
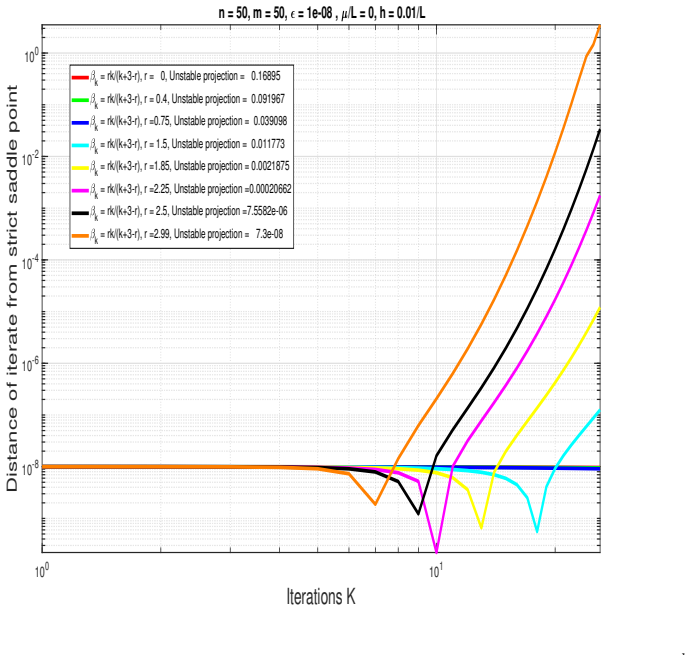
The paper claims that Nesterov's accelerated gradient method with a variable momentum parameter avoids strict saddle points almost surely, shown via asymptotic analysis of the associated discrete dynamical system. It further derives linear exit-time estimates for trajectories leaving strict saddle neighborhoods under necessary conditions on the parameters, develops two metrics for asymptotic rates of convergence and divergence near saddles, and identifies a sub-class of these methods that converges at a near-optimal rate to a local minimum inside convex neighborhoods while escaping saddles more effectively than standard NAG.
What carries the argument
The discrete dynamical system that encodes the accelerated gradient updates with momentum parameters, used to track trajectories near strict saddle points.
If this is right
- Trajectories exit strict saddle neighborhoods after a number of steps that scales linearly with the inverse of the smallest negative eigenvalue.
- A sub-class of the methods reaches a local minimum at a near-optimal rate once inside a convex neighborhood.
- Standard methods such as NAG and constant-momentum NCM exhibit quantifiable rates of divergence away from saddles under the developed metrics.
- Necessary conditions on momentum parameters must hold for escape trajectories to exist.
Where Pith is reading between the lines
- The same dynamical-system approach could be used to compare escape behavior across a wider family of momentum-based first-order methods.
- Parameter choices that improve saddle escape might be combined with adaptive schemes to maintain performance across mixed convex-nonconvex landscapes.
- The linear exit-time result suggests that practical implementations could monitor gradient norms or function values to detect and accelerate passage through saddle regions.
Load-bearing premise
The objective function is twice continuously differentiable with Lipschitz continuous gradients, and the chosen momentum parameters produce well-defined trajectories near saddle points.
What would settle it
A simulation in which a trajectory generated by NAG with variable momentum remains inside a strict saddle neighborhood for arbitrarily long time with positive probability would falsify the almost-sure escape result.
Figures





read the original abstract
This paper considers the problem of understanding the behavior of a general class of accelerated gradient methods on smooth nonconvex functions. Motivated by some recent works that have proposed effective algorithms, based on Polyak's heavy ball method and the Nesterov accelerated gradient method, to achieve convergence to a local minimum of nonconvex functions, this work proposes a broad class of Nesterov-type accelerated methods and puts forth a rigorous study of these methods encompassing the escape from saddle points and convergence to local minima through both an asymptotic and a non-asymptotic analysis. In the asymptotic regime, this paper answers an open question of whether Nesterov's accelerated gradient method (NAG) with variable momentum parameter avoids strict saddle points almost surely. This work also develops two metrics of asymptotic rates of convergence and divergence, and evaluates these two metrics for several popular standard accelerated methods such as the NAG and Nesterov's accelerated gradient with constant momentum (NCM) near strict saddle points. In the non-asymptotic regime, this work provides an analysis that leads to the "linear" exit time estimates from strict saddle neighborhoods for trajectories of these accelerated methods as well the necessary conditions for the existence of such trajectories. Finally, this work studies a sub-class of accelerated methods that can converge in convex neighborhoods of nonconvex functions with a near optimal rate to a local minimum and at the same time this sub-class offers superior saddle-escape behavior compared to that of NAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a broad class of Nesterov-type accelerated gradient methods for smooth nonconvex optimization. In the asymptotic regime it claims to resolve an open question by proving that NAG with variable momentum (e.g., the standard schedule) avoids strict saddle points almost surely; it introduces two metrics of asymptotic convergence/divergence rates and evaluates them for NAG and NCM near saddles. In the non-asymptotic regime it derives linear exit-time bounds from saddle neighborhoods together with necessary conditions for such trajectories to exist. Finally it identifies a subclass that converges at near-optimal rates inside convex neighborhoods while exhibiting improved saddle-escape behavior relative to standard NAG.
Significance. If the central claims hold, the work supplies the first rigorous almost-sure escape guarantee for variable-momentum NAG and supplies both asymptotic rate metrics and explicit linear exit-time estimates, which are load-bearing for any global-convergence theory of accelerated methods on nonconvex landscapes. The identification of a subclass that simultaneously enjoys near-optimal local convergence and superior escape properties is a concrete algorithmic contribution.
major comments (1)
- [Abstract (asymptotic regime)] The almost-sure escape claim for variable-momentum NAG rests on the local analysis of a non-autonomous linearization around a strict saddle. The provided abstract does not indicate whether the proof controls the infinite product of the time-dependent Jacobians or rules out the emergence of neutral/contracting modes that the skeptic note identifies; without such control the stable manifold may fail to have measure zero. This is load-bearing for the open-question resolution stated in the abstract.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a point where the abstract could better reflect the technical content of the proof. We address the comment below.
read point-by-point responses
-
Referee: [Abstract (asymptotic regime)] The almost-sure escape claim for variable-momentum NAG rests on the local analysis of a non-autonomous linearization around a strict saddle. The provided abstract does not indicate whether the proof controls the infinite product of the time-dependent Jacobians or rules out the emergence of neutral/contracting modes that the skeptic note identifies; without such control the stable manifold may fail to have measure zero. This is load-bearing for the open-question resolution stated in the abstract.
Authors: We agree that the abstract should more explicitly signal the key technical controls. The manuscript's asymptotic analysis (Section 3) does control the infinite product of the time-dependent Jacobians by deriving uniform bounds on the operator norms along the trajectory and showing that the product of the linearized maps contracts to zero on the stable subspace while expanding on the unstable directions. The variable-momentum schedule is used to ensure that the time-varying eigenvalues remain bounded away from the unit circle, thereby excluding persistent neutral modes; the strict-saddle assumption then implies that the stable manifold has Lebesgue measure zero in a neighborhood of the saddle. We will revise the abstract to state that the proof establishes these controls on the infinite product and rules out neutral/contracting modes. revision: yes
Circularity Check
No circularity; independent analysis of existing accelerated methods
full rationale
The paper performs a self-contained asymptotic and non-asymptotic analysis of a broad class of Nesterov-type accelerated methods on twice continuously differentiable functions with Lipschitz gradients. It resolves an open question on almost-sure escape from strict saddles for variable-momentum NAG by direct study of the non-autonomous recurrence and linearization, without reducing any claimed prediction or rate to a fitted parameter, self-definition, or load-bearing self-citation. Standard external assumptions (smoothness, well-defined trajectories) are stated explicitly and do not embed the target escape or convergence claims. No equations or steps are shown to be equivalent to their inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function is smooth (twice continuously differentiable with Lipschitz gradient).
Forward citations
Cited by 1 Pith paper
-
Convergence of difference inclusions via a diameter criterion
A diameter criterion tied to a potential function certifies convergence of difference inclusions, enabling discrete proofs for first-order optimization methods with diminishing steps.
Reference graph
Works this paper leans on
-
[1]
In: Advances in Neural Information Processing Systems, pp
Allen-Zhu, Z.: Natasha 2: Faster non-convex optimization than sgd. In: Advances in Neural Information Processing Systems, pp. 2675–2686 (2018)
work page 2018
-
[2]
In: Advances in Neural Information Processing Systems, pp
Allen-Zhu, Z., Li, Y.: Neon2: Finding local minima via first-order oracles. In: Advances in Neural Information Processing Systems, pp. 3716–3726 (2018)
work page 2018
-
[3]
Mathematical Programming 180(1-2), 137–156 (2020)
Apidopoulos, V., Aujol, J.F., Dossal, C.: Convergence rate of inertial forward–backward algorithm beyond nesterov’s rule. Mathematical Programming 180(1-2), 137–156 (2020)
work page 2020
-
[4]
Mathematical Programming 168, 123–175 (2018)
Attouch, H., Chbani, Z., Peypouquet, J., Redont, P.: Fast convergence of inertial dynamics and algo- rithms with asymptotic vanishing viscosity. Mathematical Programming 168, 123–175 (2018)
work page 2018
-
[5]
ESAIM: Control, Optimisation and Calculus of Variations 25, 2 (2019)
Attouch, H., Chbani, Z., Riahi, H.: Rate of convergence of the nesterov accelerated gradient method in the subcritical case α ≤ 3. ESAIM: Control, Optimisation and Calculus of Variations 25, 2 (2019)
work page 2019
-
[6]
Aujol, J., Dossal, C.: Optimal rate of convergence of an ode associated to the fast gradient descent schemes for b> 0 (2017)
work page 2017
-
[7]
arXiv preprint arXiv:1911.07596 (2019)
Barakat, A., Bianchi, P.: Convergence analysis of a momentum algorithm with adaptive step size for non convex optimization. arXiv preprint arXiv:1911.07596 (2019)
-
[8]
Braun, P., Gr¨ une, L., Kellett, C.M.: (In-) Stability of Differential Inclusions: Notions, Equivalences, and Lyapunov-like Characterizations. Springer Nature (2021) 59The matrix C will depend on the value of β, n and the eigenvalues in the EU S subspace of the matrix I − h∇2f(x∗) . 103
work page 2021
-
[9]
Brezis, H., Br´ ezis, H.: Functional analysis, Sobolev spaces and partial differential equations, vol. 2. Springer (2011)
work page 2011
-
[10]
arXiv preprint arXiv:2204.11292 (2022)
Can, B., Gurbuzbalaban, M.: Entropic risk-averse generalized momentum methods. arXiv preprint arXiv:2204.11292 (2022)
-
[11]
In: International Conference on Machine Learning, pp
Can, B., Gurbuzbalaban, M., Zhu, L.: Accelerated linear convergence of stochastic momentum methods in wasserstein distances. In: International Conference on Machine Learning, pp. 891–901. PMLR (2019)
work page 2019
-
[12]
IEEE Transactions on Information Theory 61(4), 1985–2007 (2015)
Candes, E.J., Li, X., Soltanolkotabi, M.: Phase retrieval via wirtinger flow: Theory and algorithms. IEEE Transactions on Information Theory 61(4), 1985–2007 (2015)
work page 1985
-
[13]
SIAM Journal on Optimization 28(2), 1751–1772 (2018)
Carmon, Y., Duchi, J.C., Hinder, O., Sidford, A.: Accelerated methods for nonconvex optimization. SIAM Journal on Optimization 28(2), 1751–1772 (2018)
work page 2018
-
[14]
On the Convergence of A Class of Adam-Type Algorithms for Non-Convex Optimization
Chen, X., Liu, S., Sun, R., Hong, M.: On the convergence of a class of adam-type algorithms for non-convex optimization. arXiv preprint arXiv:1808.02941 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Mathematical Programming 176(1), 5–37 (2019)
Chen, Y., Chi, Y., Fan, J., Ma, C.: Gradient descent with random initialization: Fast global convergence for nonconvex phase retrieval. Mathematical Programming 176(1), 5–37 (2019)
work page 2019
-
[16]
Chicone, C.C.: Ordinary Differential Equations With Applications. Springer (1999)
work page 1999
-
[17]
Bulletin of the Belgian Mathematical Society-Simon Stevin 22(1), 71–75 (2015)
Conejero, J.A., Mu˜ noz-Fern´ andez, G.A., Arcila, M.M., Seoane-Sep´ ulveda, J.B.: Smooth functions with uncountably many zeros. Bulletin of the Belgian Mathematical Society-Simon Stevin 22(1), 71–75 (2015)
work page 2015
-
[18]
Ad- vances in Computational mathematics 5(1), 329–359 (1996)
Corless, R.M., Gonnet, G.H., Hare, D.E., Jeffrey, D.J., Knuth, D.E.: On the lambertw function. Ad- vances in Computational mathematics 5(1), 329–359 (1996)
work page 1996
-
[19]
arXiv preprint arXiv:2012.04061 (2020)
Das, R., Acharya, A., Hashemi, A., Sanghavi, S., Dhillon, I.S., Topcu, U.: Faster non-convex federated learning via global and local momentum. arXiv preprint arXiv:2012.04061 (2020)
-
[20]
Davidson, J.: Stochastic limit theory: An introduction for econometricians. OUP Oxford (1994)
work page 1994
-
[21]
arXiv preprint arXiv:2108.11832 (2021)
Davis, D., Drusvyatskiy, D., Jiang, L.: Subgradient methods near active manifolds: saddle point avoid- ance, local convergence, and asymptotic normality. arXiv preprint arXiv:2108.11832 (2021)
-
[22]
De, S., Mukherjee, A., Ullah, E.: Convergence guarantees for rmsprop and adam in non-convex opti- mization and an empirical comparison to nesterov acceleration. arXiv preprint arXiv:1807.06766 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Convergence of stochastic gradient descent schemes for Loj asiewicz- landscapes
Dereich, S., Kassing, S.: Convergence of stochastic gradient descent schemes for lojasiewicz-landscapes. arXiv preprint arXiv:2102.09385 (2021)
-
[24]
IEEE Transactions on Information Theory pp
Dixit, R., G¨ urb¨ uzbalaban, M., Bajwa, W.U.: Boundary conditions for linear exit time gradient trajec- tories around saddle points: Analysis and algorithm. IEEE Transactions on Information Theory pp. 1–1 (2022). DOI 10.1109/TIT.2022.3213607
-
[25]
Information and Inference: A Journal of the IMA (2022)
Dixit, R., G¨ urb¨ uzbalaban, M., Bajwa, W.U.: Exit Time Analysis for Approximations of Gradient Descent Trajectories Around Saddle Points. Information and Inference: A Journal of the IMA (2022). DOI 10.1093/imaiai/iaac025. URL https://doi.org/10.1093/imaiai/iaac025. Iaac025
-
[26]
Dozat, T.: Incorporating nesterov momentum into adam (2016)
work page 2016
-
[27]
Dunford, N., Schwartz, J.T.: Linear operators, part 1: general theory, vol. 10. John Wiley & Sons (1988)
work page 1988
-
[28]
Sharp Analysis for Nonconvex SGD Escaping from Saddle Points
Fang, C., Lin, Z., Zhang, T.: Sharp analysis for nonconvex sgd escaping from saddle points. arXiv preprint arXiv:1902.00247 (2019) 104
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[29]
SIAM Journal on Optimization 28(3), 2654–2689 (2018)
Fazlyab, M., Ribeiro, A., Morari, M., Preciado, V.M.: Analysis of optimization algorithms via integral quadratic constraints: Nonstrongly convex problems. SIAM Journal on Optimization 28(3), 2654–2689 (2018)
work page 2018
-
[30]
Electronic Journal of Statistics 12(1), 461–529 (2018)
Gadat, S., Panloup, F., Saadane, S.: Stochastic heavy ball. Electronic Journal of Statistics 12(1), 461–529 (2018)
work page 2018
-
[31]
Advances in Neural Information Processing Systems 33, 17850–17862 (2020)
Gao, X., Gurbuzbalaban, M., Zhu, L.: Breaking reversibility accelerates langevin dynamics for non- convex optimization. Advances in Neural Information Processing Systems 33, 17850–17862 (2020)
work page 2020
-
[32]
Operations Research 70(5), 2931–2947 (2022)
Gao, X., G¨ urb¨ uzbalaban, M., Zhu, L.: Global convergence of stochastic gradient hamiltonian monte carlo for nonconvex stochastic optimization: Nonasymptotic performance bounds and momentum-based acceleration. Operations Research 70(5), 2931–2947 (2022)
work page 2022
-
[33]
In: 2015 European control conference (ECC), pp
Ghadimi, E., Feyzmahdavian, H.R., Johansson, M.: Global convergence of the heavy-ball method for convex optimization. In: 2015 European control conference (ECC), pp. 310–315. IEEE (2015)
work page 2015
-
[34]
Mathematical Programming 156(1), 59–99 (2016)
Ghadimi, S., Lan, G.: Accelerated gradient methods for nonconvex nonlinear and stochastic program- ming. Mathematical Programming 156(1), 59–99 (2016)
work page 2016
-
[35]
Advances in Neural Information Processing Systems 32 (2019)
Gitman, I., Lang, H., Zhang, P., Xiao, L.: Understanding the role of momentum in stochastic gradient methods. Advances in Neural Information Processing Systems 32 (2019)
work page 2019
-
[36]
Hahn, W., et al.: Stability of motion, vol. 138. Springer (1967)
work page 1967
-
[37]
Hirsch, M., Pugh, C., Shub, M.: Invariant manifolds (lecture notes in mathematics, 583) (1977)
work page 1977
-
[38]
http://math.huji.ac.il/~mhochman/courses/ fractals-2012/convergence-of-sets-and-measures.pdf
Hochman, M.: Convergence of sets and measures. http://math.huji.ac.il/~mhochman/courses/ fractals-2012/convergence-of-sets-and-measures.pdf . Accessed: 2022-12-22
work page 2012
-
[39]
http://math.huji.ac.il/~mhochman/courses/ fractals-2012/
Hochman, M.: Convergence of sets and measures. http://math.huji.ac.il/~mhochman/courses/ fractals-2012/. Accessed: 2022-12-22
work page 2012
-
[40]
IEEE Journal of selected topics in signal processing 10(4), 770–781 (2016)
Jaganathan, K., Eldar, Y.C., Hassibi, B.: Stft phase retrieval: Uniqueness guarantees and recovery algorithms. IEEE Journal of selected topics in signal processing 10(4), 770–781 (2016)
work page 2016
-
[41]
Accelerated Gradient Descent Escapes Saddle Points Faster than Gradient Descent
Jin, C., Netrapalli, P., Jordan, M.I.: Accelerated gradient descent escapes saddle points faster than gradient descent. arXiv preprint arXiv:1711.10456 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Courier Dover Publications (2017)
Kelley, J.L.: General topology. Courier Dover Publications (2017)
work page 2017
-
[43]
Kinderlehrer, D., Stampacchia, G.: An introduction to variational inequalities and their applications. SIAM (2000)
work page 2000
-
[44]
Springer Science & Business Media (2012)
Kirillov, A.A., Gvishiani, A.D.: Theorems and problems in functional analysis. Springer Science & Business Media (2012)
work page 2012
-
[45]
Fundamenta Mathe- maticae 22(1), 77–108 (1934)
Kirszbraun, M.: ¨Uber die zusammenziehende und lipschitzsche transformationen. Fundamenta Mathe- maticae 22(1), 77–108 (1934)
work page 1934
-
[46]
In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp
Koppel, A., Mokhtari, A., Ribeiro, A.: Parallel stochastic successive convex approximation method for large-scale dictionary learning. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2771–2775. IEEE (2018)
work page 2018
-
[47]
Computational Mathematics and Mathematical Physics 61(7), 1162–1168 (2021)
Kurochkin, S.V.: Neural network with smooth activation functions and without bottlenecks is almost surely a morse function. Computational Mathematics and Mathematical Physics 61(7), 1162–1168 (2021)
work page 2021
-
[48]
Mathematical programming 176(1), 311–337 (2019) 105
Lee, J.D., Panageas, I., Piliouras, G., Simchowitz, M., Jordan, M.I., Recht, B.: First-order methods almost always avoid strict saddle points. Mathematical programming 176(1), 311–337 (2019) 105
work page 2019
-
[49]
Gradient Descent Converges to Minimizers
Lee, J.D., Simchowitz, M., Jordan, M.I., Recht, B.: Gradient descent converges to minimizers. arXiv preprint arXiv:1602.04915 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[50]
In: Introduction to Smooth Manifolds, pp
Lee, J.M.: Smooth manifolds. In: Introduction to Smooth Manifolds, pp. 1–31. Springer (2013)
work page 2013
-
[51]
IEEE Control Systems Magazine 42(3), 58–72 (2022)
Lessard, L.: The analysis of optimization algorithms: A dissipativity approach. IEEE Control Systems Magazine 42(3), 58–72 (2022)
work page 2022
-
[52]
Letov, A.: Stability of nonlinear control systems
-
[53]
Advances in Neural Information Processing Systems 33, 18261–18271 (2020)
Liu, Y., Gao, Y., Yin, W.: An improved analysis of stochastic gradient descent with momentum. Advances in Neural Information Processing Systems 33, 18261–18271 (2020)
work page 2020
-
[54]
Aggregated Momentum: Stability Through Passive Damping
Lucas, J., Sun, S., Zemel, R., Grosse, R.: Aggregated momentum: Stability through passive damping. arXiv preprint arXiv:1804.00325 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[55]
Luenberger, D.G., Ye, Y., et al.: Linear and nonlinear programming, vol. 2. Springer (1984)
work page 1984
-
[56]
International journal of control 55(3), 531–534 (1992)
Lyapunov, A.M.: The general problem of the stability of motion. International journal of control 55(3), 531–534 (1992)
work page 1992
-
[57]
Foundations of Computational Mathematics 20(3) (2020)
Ma, C., Wang, K., Chi, Y., Chen, Y.: Implicit regularization in nonconvex statistical estimation: Gradient descent converges linearly for phase retrieval, matrix completion, and blind deconvolution. Foundations of Computational Mathematics 20(3) (2020)
work page 2020
-
[58]
In: International Confer- ence on Learning Representations (2018)
Ma, J., Yarats, D.: Quasi-hyperbolic momentum and adam for deep learning. In: International Confer- ence on Learning Representations (2018)
work page 2018
-
[59]
Matsumoto, Y.: An introduction to Morse theory, vol. 208. American Mathematical Soc. (2002)
work page 2002
-
[60]
Megginson, R.E.: An introduction to Banach space theory, vol. 183. Springer Science & Business Media (2012)
work page 2012
-
[61]
The Annals of Statistics 46(6A), 2747–2774 (2018)
Mei, S., Bai, Y., Montanari, A.: The landscape of empirical risk for nonconvex losses. The Annals of Statistics 46(6A), 2747–2774 (2018)
work page 2018
-
[62]
In: The 22nd International Conference on Artificial Intelligence and Statistics, pp
Mokhtari, A., Ozdaglar, A., Jadbabaie, A.: Efficient nonconvex empirical risk minimization via adaptive sample size methods. In: The 22nd International Conference on Artificial Intelligence and Statistics, pp. 2485–2494. PMLR (2019)
work page 2019
-
[63]
Nesterov, Y.: Introductory lectures on convex optimization: A basic course, vol. 87. Springer Science & Business Media (2003)
work page 2003
- [64]
-
[65]
Cambridge university press (2002)
Ott, E.: Chaos in dynamical systems. Cambridge university press (2002)
work page 2002
-
[66]
Mathematical Programming 176(1-2), 403–427 (2019)
O’Neill, M., Wright, S.J.: Behavior of accelerated gradient methods near critical points of nonconvex functions. Mathematical Programming 176(1-2), 403–427 (2019)
work page 2019
-
[67]
Gradient Descent Only Converges to Minimizers: Non-Isolated Critical Points and Invariant Regions
Panageas, I., Piliouras, G.: Gradient descent only converges to minimizers: Non-isolated critical points and invariant regions. arXiv preprint arXiv:1605.00405 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[68]
Journal of Inequalities and Appli- cations 2005, 1–14 (2005)
Papi, M.: On the domain of the implicit function and applications. Journal of Inequalities and Appli- cations 2005, 1–14 (2005)
work page 2005
-
[69]
IEEE Transactions on Signal Processing 66(4), 982–991 (2017)
Pauwels, E.J.R., Beck, A., Eldar, Y.C., Sabach, S.: On fienup methods for sparse phase retrieval. IEEE Transactions on Signal Processing 66(4), 982–991 (2017)
work page 2017
-
[70]
USSR Computational Mathematics and Mathematical Physics 4(5), 1–17 (1964) 106
Polyak, B.T.: Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics 4(5), 1–17 (1964) 106
work page 1964
-
[71]
In: Conference on Learning Theory, pp
Raginsky, M., Rakhlin, A., Telgarsky, M.: Non-convex learning via stochastic gradient langevin dynam- ics: a nonasymptotic analysis. In: Conference on Learning Theory, pp. 1674–1703. PMLR (2017)
work page 2017
-
[72]
On the Convergence of Adam and Beyond
Reddi, S.J., Kale, S., Kumar, S.: On the convergence of adam and beyond. arXiv preprint arXiv:1904.09237 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[73]
A Generic Approach for Escaping Saddle points
Reddi, S.J., Zaheer, M., Sra, S., Poczos, B., Bach, F., Salakhutdinov, R., Smola, A.J.: A generic approach for escaping saddle points. arXiv preprint arXiv:1709.01434 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[74]
Rudin, W., et al.: Principles of mathematical analysis, vol. 3. McGraw-hill New York (1976)
work page 1976
-
[75]
Schwartz, J.T.: Nonlinear functional analysis, vol. 4. CRC Press (1969)
work page 1969
-
[76]
Springer Science & Business Media (2013)
Shub, M.: Global stability of dynamical systems. Springer Science & Business Media (2013)
work page 2013
-
[77]
Bulletin of the American mathematical Society 73(6), 747–817 (1967)
Smale, S.: Differentiable dynamical systems. Bulletin of the American mathematical Society 73(6), 747–817 (1967)
work page 1967
-
[78]
Advances in neural information processing systems 27 (2014)
Su, W., Boyd, S., Candes, E.: A differential equation for modeling nesterov’s accelerated gradient method: theory and insights. Advances in neural information processing systems 27 (2014)
work page 2014
-
[79]
In: International conference on machine learning, pp
Sutskever, I., Martens, J., Dahl, G., Hinton, G.: On the importance of initialization and momentum in deep learning. In: International conference on machine learning, pp. 1139–1147. PMLR (2013)
work page 2013
-
[80]
Tabor, M.: Chaos and integrability in nonlinear dynamics: an introduction. Wiley-Interscience (1989)
work page 1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.