Group-Aware Coordination Graph for Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-24 02:15 UTC · model grok-4.3
The pith
A group-aware coordination graph captures pairwise relations from observations and group dependencies from trajectories to improve information exchange in multi-agent reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
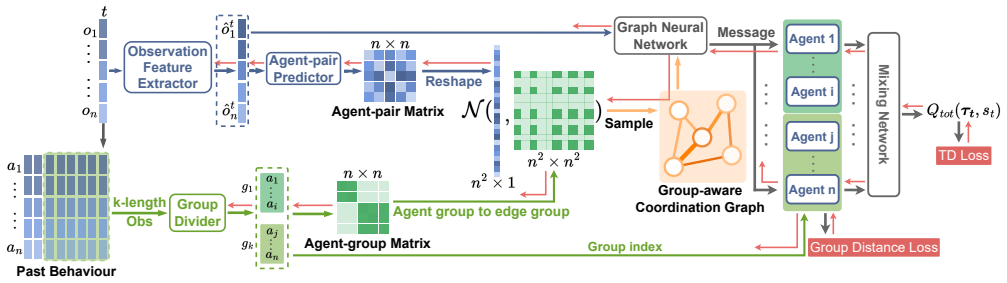
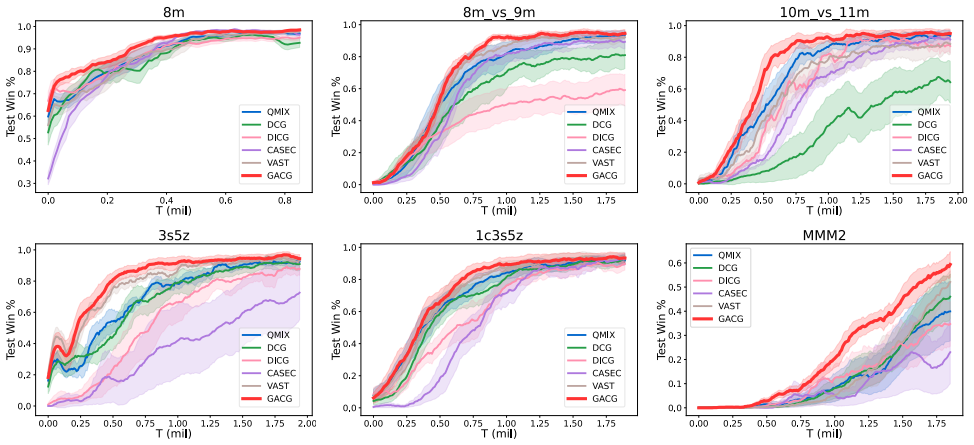
The Group-Aware Coordination Graph (GACG) is designed to capture both the cooperation between agent pairs based on current observations and group-level dependencies from behaviour patterns observed across trajectories. This graph is used in graph convolution for information exchange between agents during decision-making. To further ensure behavioural consistency among agents within the same group, a group distance loss is introduced which promotes group cohesion and encourages specialization between groups, yielding superior performance on StarCraft II micromanagement tasks.
What carries the argument
The Group-Aware Coordination Graph (GACG) that jointly models pairwise cooperation from instantaneous observations and group dependencies from trajectory-wide behavior patterns, processed by graph convolution for message passing and regularized by a group distance loss.
If this is right
- Pairwise relations from current observations combined with group relations from trajectories allow more relevant messages to pass between agents that cannot see one another.
- The group distance loss keeps agents inside each learned group behaving similarly while pushing different groups toward distinct roles.
- Graph convolution on the learned GACG produces the final joint policy used for cooperative decision making.
- Ablation results isolate the contribution of each added component to the reported performance gains.
Where Pith is reading between the lines
- The same concurrent graph-learning step could be applied in other partially observable domains where team structure is not known in advance.
- Specialization induced by the distance loss might produce emergent role division that fixed group definitions would miss.
- Because the graph is inferred from behavior rather than hand-specified, the approach may adapt when the optimal grouping changes during training.
Load-bearing premise
That concurrently learning the latent graph from behavior patterns observed across trajectories enables improved information exchange among partially observed agents compared with prior group-modeling methods.
What would settle it
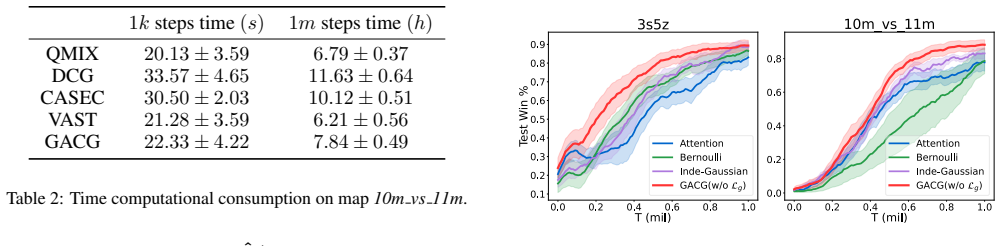
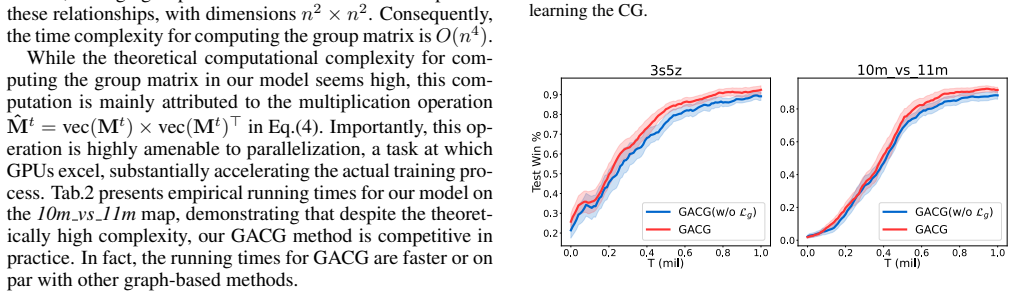
An experiment on the same StarCraft II micromanagement tasks in which ablating either the group-level dependency inference or the group distance loss produces no gain or a loss relative to the non-group baselines would falsify the central claim.
Figures

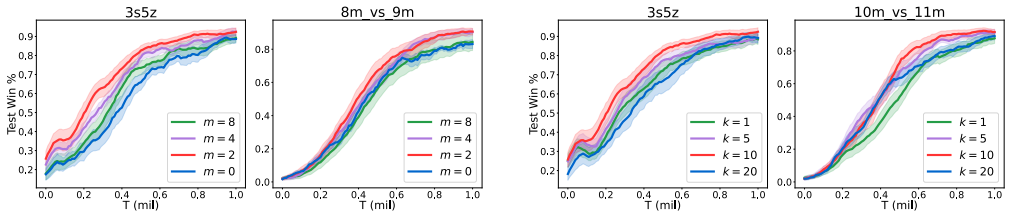
read the original abstract
Cooperative Multi-Agent Reinforcement Learning (MARL) necessitates seamless collaboration among agents, often represented by an underlying relation graph. Existing methods for learning this graph primarily focus on agent-pair relations, neglecting higher-order relationships. While several approaches attempt to extend cooperation modelling to encompass behaviour similarities within groups, they commonly fall short in concurrently learning the latent graph, thereby constraining the information exchange among partially observed agents. To overcome these limitations, we present a novel approach to infer the Group-Aware Coordination Graph (GACG), which is designed to capture both the cooperation between agent pairs based on current observations and group-level dependencies from behaviour patterns observed across trajectories. This graph is further used in graph convolution for information exchange between agents during decision-making. To further ensure behavioural consistency among agents within the same group, we introduce a group distance loss, which promotes group cohesion and encourages specialization between groups. Our evaluations, conducted on StarCraft II micromanagement tasks, demonstrate GACG's superior performance. An ablation study further provides experimental evidence of the effectiveness of each component of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Group-Aware Coordination Graph (GACG) for cooperative MARL. It infers a latent coordination graph that jointly captures pairwise cooperation from current observations and higher-order group dependencies from behavior patterns across trajectories. Graph convolution is applied on this graph for inter-agent information exchange during decision making, and a group distance loss is added to enforce behavioral consistency within groups while encouraging inter-group specialization. The central claims are that GACG achieves superior performance on StarCraft II micromanagement tasks and that an ablation study confirms the contribution of each component.
Significance. If the performance claims hold under rigorous evaluation, the concurrent learning of group-level structure alongside pairwise relations would represent a meaningful advance over prior coordination-graph methods that either ignore groups or learn them separately. The group distance loss provides a concrete mechanism for promoting cohesion and specialization, which could generalize to other partially observed cooperative settings.
major comments (1)
- [Abstract] Abstract: the statements that 'Our evaluations... demonstrate GACG's superior performance' and that 'An ablation study further provides experimental evidence of the effectiveness of each component' are unsupported by any reported metrics, baselines, error bars, statistical tests, or experimental protocol. Without these data the central empirical claim cannot be assessed.
minor comments (1)
- [Abstract] The abstract introduces 'group distance loss' and 'graph convolution' without indicating how the loss is formulated or how the convolution is parameterized (e.g., whether the graph is directed, how edge weights are normalized).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we address the major comment point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statements that 'Our evaluations... demonstrate GACG's superior performance' and that 'An ablation study further provides experimental evidence of the effectiveness of each component' are unsupported by any reported metrics, baselines, error bars, statistical tests, or experimental protocol. Without these data the central empirical claim cannot be assessed.
Authors: The abstract is a concise summary of results that are fully detailed in the manuscript. Section 4 describes the StarCraft II micromanagement benchmark, the baselines (including QMIX, VDN, and graph-based methods), the evaluation protocol (win rate, episode returns, 5 random seeds), and reports performance with error bars. Section 5.2 presents the ablation study with quantitative metrics showing the contribution of the group-aware graph inference and the group distance loss. We acknowledge that the abstract itself contains no numbers and will therefore revise it to include key quantitative highlights (e.g., average win-rate improvements) and a brief reference to the experimental setting, subject to the word limit. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes a data-driven MARL method that infers latent coordination graphs from agent observations and trajectory behavior patterns, applies graph convolution for information exchange, and adds a group distance loss for cohesion. No equations, derivations, or load-bearing steps are presented that reduce any prediction or result to a fitted input or self-citation by construction. The approach relies on standard learning from data with external benchmarks (SMAC tasks and ablations), so the derivation chain is self-contained and independent.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GACG ... capture both the cooperation between agent pairs based on current observations and group-level dependencies from behaviour patterns observed across trajectories ... E ∼ N(μt, M̂t) ... Lg ... group distance loss
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
entire experimental section on StarCraft micromanagement tasks and ablation of distributions/losses
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges
A survey that taxonomizes threats to agentic AI, reviews benchmarks and evaluation methods, discusses technical and governance defenses, and identifies open challenges.
Reference graph
Works this paper leans on
-
[1]
Wendelin Boehmer, Vitaly Kurin, and Shimon Whiteson. Deep coordination graphs. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020) , Virtual Event , volume 119 of Proceedings of Machine Learning Research , pages 980--991. PMLR , 2020
work page 2020
-
[2]
Multi-agent reinforcement learning-based resource allocation for UAV networks
Jingjing Cui, Yuanwei Liu, and Arumugam Nallanathan. Multi-agent reinforcement learning-based resource allocation for UAV networks. IEEE Trans. Wirel. Commun. , 19(2):729--743, 2020
work page 2020
-
[3]
Learning from the dark: Boosting graph convolutional neural networks with diverse negative samples
Wei Duan, Junyu Xuan, Maoying Qiao, and Jie Lu. Learning from the dark: Boosting graph convolutional neural networks with diverse negative samples. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI 2022) , Virtual Event , pages 6550--6558. AAAI Press, 2022
work page 2022
-
[4]
Wei Duan, Junyu Xuan, Maoying Qiao, and Jie Lu. Graph convolutional neural networks with diverse negative samples via decomposed determinant point processes. IEEE Trans. Neural Networks Learn. Syst. , 2023
work page 2023
-
[5]
Layer-diverse negative sampling for graph neural networks
Wei Duan, Jie Lu, Yu Guang Wang, and Junyu Xuan. Layer-diverse negative sampling for graph neural networks. Transactions on Machine Learning Research , 2024
work page 2024
-
[6]
Inferring Latent Temporal Sparse Coordination Graph for Multi-Agent Reinforcement Learning
Wei Duan, Jie Lu, and Junyu Xuan. Inferring latent temporal sparse coordination graph for multi-agent reinforcement learning. CoRR , abs/2403.19253, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Schr \" o der de Witt, Bei Peng, Wendelin Boehmer, Shimon Whiteson, and Fei Sha
Shariq Iqbal, Christian A. Schr \" o der de Witt, Bei Peng, Wendelin Boehmer, Shimon Whiteson, and Fei Sha. Randomized entity-wise factorization for multi-agent reinforcement learning. In Proceedings of the 38th International Conference on Machine Learning (ICML 2021) , 18-24 July, Virtual Event , volume 139 of Proceedings of Machine Learning Research , p...
work page 2021
-
[8]
Graph convolutional reinforcement learning
Jiechuan Jiang, Chen Dun, Tiejun Huang, and Zongqing Lu. Graph convolutional reinforcement learning. In 8th International Conference on Learning Representations (ICLR 2020) , Addis Ababa, Ethiopia , 2020
work page 2020
-
[9]
Sheng Li, Jayesh K. Gupta, Peter Morales, Ross E. Allen, and Mykel J. Kochenderfer. Deep implicit coordination graphs for multi-agent reinforcement learning. In AAMAS '21: 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021) , Virtual Event, United Kingdom , pages 764--772. ACM , 2021
work page 2021
-
[10]
Pic: permutation invariant critic for multi-agent deep reinforcement learning
Iou-Jen Liu, Raymond A Yeh, and Alexander G Schwing. Pic: permutation invariant critic for multi-agent deep reinforcement learning. In Proceedings of the 3rd Conference on Robot Learning (CoRL 2019) , Osaka, Japan , pages 590--602, 2020
work page 2019
-
[11]
Multi-agent game abstraction via graph attention neural network
Yong Liu, Weixun Wang, Yujing Hu, Jianye Hao, Xingguo Chen, and Yang Gao. Multi-agent game abstraction via graph attention neural network. In The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020) , New York, NY, USA, , pages 7211--7218. AAAI Press, 2020
work page 2020
-
[12]
Oliehoek and Christopher Amato
Frans A. Oliehoek and Christopher Amato. A Concise Introduction to Decentralized POMDPs . Springer Briefs in Intelligent Systems. Springer, 2016
work page 2016
-
[13]
Multi-agent deep reinforcement learning for multi-robot applications: A survey
James Orr and Ayan Dutta. Multi-agent deep reinforcement learning for multi-robot applications: A survey. Sensors , 23(7):3625, 2023
work page 2023
-
[14]
Learning to score behaviors for guided policy optimization
Aldo Pacchiano, Jack Parker-Holder, Yunhao Tang, Krzysztof Choromanski, Anna Choromanska, and Michael Jordan. Learning to score behaviors for guided policy optimization. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, (ICML 2020) , volume 119 of Proceedings of Machine Learning Research , pag...
work page 2020
-
[15]
VAST: value function factorization with variable agent sub-teams
Thomy Phan, Fabian Ritz, Lenz Belzner, Philipp Altmann, Thomas Gabor, and Claudia Linnhoff - Popien. VAST: value function factorization with variable agent sub-teams. In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems (NIPS 2021) , December 6-14, virtual , pages 24018--24032, 2021
work page 2021
-
[16]
Tabish Rashid, Mikayel Samvelyan, Christian Schr \" o der de Witt, Gregory Farquhar, Jakob N. Foerster, and Shimon Whiteson. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning. In Proceedings of the 35th International Conference on Machine Learning (ICML 2018) , Stockholmsm \" a ssan, Stockholm, Sweden , volume 80, pa...
work page 2018
-
[17]
Yara Rizk, Mariette Awad, and Edward W. Tunstel. Cooperative heterogeneous multi-robot systems: A survey. ACM Comput. Surv. , 52(2):29:1--29:31, 2019
work page 2019
-
[18]
Mikayel Samvelyan, Tabish Rashid, Christian Schr \" o der de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia - Man Hung, Philip H. S. Torr, Jakob N. Foerster, and Shimon Whiteson. The starcraft multi-agent challenge. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS 2019) , Montreal, QC,...
work page 2019
- [19]
-
[20]
Self-organized group for cooperative multi-agent reinforcement learning
Jianzhun Shao, Zhiqiang Lou, Hongchang Zhang, Yuhang Jiang, Shuncheng He, and Xiangyang Ji. Self-organized group for cooperative multi-agent reinforcement learning. In NeurIPS , 2022
work page 2022
-
[21]
Leibo, Karl Tuyls, and Thore Graepel
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vin \' cius Flores Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. Value-decomposition networks for cooperative multi-agent learning based on team reward. In Proceedings of the 17th International Conference on Autonomous Agents and...
work page 2018
-
[22]
Andrea Tacchetti, H. Francis Song, Pedro A. M. Mediano, Vin \' cius Flores Zambaldi, J \' a nos Kram \' a r, Neil C. Rabinowitz, Thore Graepel, Matthew M. Botvinick, and Peter W. Battaglia. Relational forward models for multi-agent learning. In 7th International Conference on Learning Representations (ICLR 2019) , New Orleans, LA, USA , 2019
work page 2019
-
[23]
Tonghan Wang, Heng Dong, Victor R. Lesser, and Chongjie Zhang. ROMA: multi-agent reinforcement learning with emergent roles. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020) , Virtual Event , volume 119 of Proceedings of Machine Learning Research , pages 9876--9886, 2020
work page 2020
-
[24]
Learning nearly decomposable value functions via communication minimization
Tonghan Wang, Jianhao Wang, Chongyi Zheng, and Chongjie Zhang. Learning nearly decomposable value functions via communication minimization. In 8th International Conference on Learning Representations (ICLR 2020) , Addis Ababa, Ethiopia , 2020
work page 2020
-
[25]
Traffic signal control with reinforcement learning based on region-aware cooperative strategy
Min Wang, Libing Wu, Jianxin Li, and Liu He. Traffic signal control with reinforcement learning based on region-aware cooperative strategy. IEEE Trans. Intell. Transp. Syst. , 23(7):6774--6785, 2022
work page 2022
-
[26]
Context-aware sparse deep coordination graphs
Tonghan Wang, Liang Zeng, Weijun Dong, Qianlan Yang, Yang Yu, and Chongjie Zhang. Context-aware sparse deep coordination graphs. In The Tenth International Conference on Learning Representations (ICLR 2022) , Virtual Event . OpenReview.net, 2022
work page 2022
-
[27]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S. Yu. A comprehensive survey on graph neural networks. IEEE Trans. Neural Networks Learn. Syst. , 32(1):4--24, 2021
work page 2021
-
[28]
Self-organized polynomial-time coordination graphs
Qianlan Yang, Weijun Dong, Zhizhou Ren, Jianhao Wang, Tonghan Wang, and Chongjie Zhang. Self-organized polynomial-time coordination graphs. In International Conference on Machine Learning (ICML 2022) , Baltimore, Maryland, USA , volume 162 of Proceedings of Machine Learning Research , pages 24963--24979. PMLR , 2022
work page 2022
-
[29]
Automatic grouping for efficient cooperative multi-agent reinforcement learning
Yifan Zang, Jinmin He, Kai Li, Haobo Fu, QIANG FU, Junliang Xing, and Jian Cheng. Automatic grouping for efficient cooperative multi-agent reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems, (NIPS 2023) , 2023
work page 2023
-
[30]
" write newline "" before.all 'output.state := FUNCTION fin.entry add.period write newline FUNCTION new.block output.state before.all = 'skip after.block 'output.state := if FUNCTION new.sentence output.state after.block = 'skip output.state before.all = 'skip after.sentence 'output.state := if if FUNCTION not #0 #1 if FUNCTION and 'skip pop #0 if FUNCTIO...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.