Quantifying Geospatial in the Common Crawl Corpus
Pith reviewed 2026-05-23 23:53 UTC · model grok-4.3
The pith
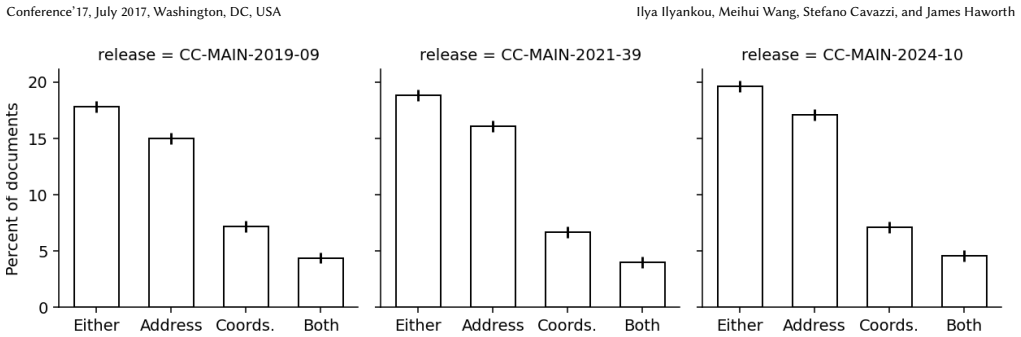
18.7% of documents in the Common Crawl corpus contain geospatial information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Analysis of a sample of Common Crawl documents, classified for geospatial content by Gemini 1.5 and then manually revised, leads to the conclusion that 18.7% of web documents contain geospatial information such as coordinates and addresses, with comparable prevalence in English and non-English documents.
What carries the argument
Gemini 1.5-based classification of sample documents for the presence of geospatial details, revised by hand to yield the overall prevalence figure.
If this is right
- Large language models encounter geospatial data in roughly one-fifth of their Common Crawl training documents.
- The share of geospatial content remains similar regardless of document language.
- The estimate supplies a foundation for investigating geospatial biases within trained language models.
Where Pith is reading between the lines
- Analyses of other content types in the Common Crawl could follow the same sampling and classification approach.
- Data preparation pipelines for language model training might reference this percentage when deciding on filters for spatial information.
- The finding suggests testing whether models' spatial performance scales with the measured prevalence in their training sets.
Load-bearing premise
The sample of documents is representative of the full Common Crawl corpus and the manual revisions confirm the accuracy of the model's classifications for geospatial content.
What would settle it
Classification of a much larger or exhaustive set of Common Crawl documents by human reviewers that produces a percentage far from 18.7%.
Figures



read the original abstract
Large language models (LLMs) exhibit emerging geospatial capabilities, stemming from their pre-training on vast unlabelled text datasets that are often derived from the Common Crawl (CC) corpus. However, the geospatial content within CC remains largely unexplored, impacting our understanding of LLMs' spatial reasoning. This paper investigates the prevalence of geospatial data in recent Common Crawl releases using Gemini 1.5, a powerful language model. By analyzing a sample of documents and manually revising the results, we estimate that 18.7% of web documents in CC contain geospatial information such as coordinates and addresses. We find little difference in prevalence between Enlgish- and non-English-language documents. Our findings provide quantitative insights into the nature and extent of geospatial data in CC, and lay the groundwork for future studies of geospatial biases of LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper uses Gemini 1.5 to classify a sample of documents from recent Common Crawl releases, followed by manual revision, to estimate that 18.7% of web documents contain geospatial information such as coordinates and addresses. It finds little difference in prevalence between English- and non-English-language documents.
Significance. If the sampling and classification methodology can be validated, this provides a quantitative measure of geospatial content in a major pretraining corpus, which is relevant for understanding the sources of LLMs' geospatial capabilities and potential biases in spatial reasoning.
major comments (2)
- [Abstract] Abstract: The central prevalence estimate of 18.7% is presented without any information on sample size, sampling frame or stratification (by language, domain, crawl date, or duplicates), or the manual revision protocol (fraction revised, reviewer count, or reliability metrics). This directly undermines assessment of the claim's reliability and generalizability.
- [Abstract] Abstract (and implied Methods): No error rates, validation against a gold standard, or inter-annotator agreement are reported for the Gemini 1.5 classifications even after manual revision, leaving the accuracy of the labels unquantified and the 18.7% figure without a clear uncertainty bound.
minor comments (1)
- [Abstract] Abstract: Typo in 'Enlgish-language' (should be 'English-language').
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of reporting transparency. We address each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central prevalence estimate of 18.7% is presented without any information on sample size, sampling frame or stratification (by language, domain, crawl date, or duplicates), or the manual revision protocol (fraction revised, reviewer count, or reliability metrics). This directly undermines assessment of the claim's reliability and generalizability.
Authors: We agree that the abstract should be self-contained with respect to these details. The full methods section describes the sampling from recent Common Crawl releases and the English/non-English stratification, but we will revise the abstract to explicitly state the sample size, sampling frame, stratification approach, and manual revision protocol (including fraction revised and reviewer count). Reliability metrics from the revision process will be included if they were recorded. revision: yes
-
Referee: [Abstract] Abstract (and implied Methods): No error rates, validation against a gold standard, or inter-annotator agreement are reported for the Gemini 1.5 classifications even after manual revision, leaving the accuracy of the labels unquantified and the 18.7% figure without a clear uncertainty bound.
Authors: This is a fair observation. The study relied on manual revision of Gemini outputs to improve label quality, but no formal error rates, gold-standard validation, or inter-annotator agreement statistics were computed. We will revise the abstract and methods to describe the revision protocol in more detail and to note the lack of quantitative accuracy metrics as a limitation, while clarifying that the 18.7% estimate is based on the revised labels. revision: partial
- Specific numerical error rates, gold-standard validation results, or inter-annotator agreement values cannot be supplied because these were not calculated during the original analysis.
Circularity Check
No circularity: empirical prevalence estimate from sampling and classification
full rationale
The paper's central claim is a direct empirical count (18.7% prevalence) obtained by sampling CC documents, applying Gemini 1.5 classification, and performing manual revision. No equations, fitted parameters, derivations, or self-citations appear in the load-bearing steps. The result is a straightforward proportion from observed data and does not reduce to its inputs by construction. This matches the default case of a self-contained empirical study with score 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gemini 1.5 can be prompted to detect geospatial information in web documents with sufficient accuracy after manual correction
- domain assumption The sampled documents are statistically representative of recent Common Crawl releases
Reference graph
Works this paper leans on
-
[1]
Stefan Baack. 2024. A Critical Analysis of the Largest Source for Generative AI Training Data: Common Crawl. In The 2024 ACM Conference on Fairness, Accountability, and Transparency. ACM, Rio de Janeiro Brazil, 2199–2208. https: //doi.org/10.1145/3630106.3659033
-
[2]
Stefan Baack. 2024. Training Data for the Price of a Sandwich: Common Crawl’s Impact on Generative AI. (Feb. 2024)
work page 2024
-
[3]
James E Bartlett, Joe W Kotrlik, and Chadwick C Higgins. 2001. Organizational Research: Determining Appropriate Sample Size in Survey Research. (2001)
work page 2001
-
[4]
Prabin Bhandari, Antonios Anastasopoulos, and Dieter Pfoser. 2023. Are Large Language Models Geospatially Knowledgeable?. In Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems (SIGSPA- TIAL ’23). Association for Computing Machinery, New York, NY, USA, 1–4. https://doi.org/10.1145/3589132.3625625
- [5]
-
[6]
John Bossler. 2010. Manual of Geospatial Science and Technology . CRC Press. Google-Books-ID: UdZ3uDekqwwC
work page 2010
-
[7]
Chia-Hui Chang and Shu-Ying Li. 2010. MapMarker: Extraction of Postal Addresses and Associated Information for General Web Pages. In 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology. IEEE, Toronto, AB, Canada, 105–111. https://doi.org/10.1109/WI- IAT.2010.64
work page doi:10.1109/wi- 2010
-
[8]
Common Crawl. 2024. Common Crawl - Open Repository of Web Crawl Data. https://commoncrawl.org/
work page 2024
-
[9]
Common Crawl. 2024. Statistics of Common Crawl Monthly Archives by com- moncrawl. https://commoncrawl.github.io/cc-crawl-statistics/plots/languages
work page 2024
- [10]
-
[11]
Julia Efremova, Ian Endres, Isaac Vidas, and Ofer Melnik. 2018. A Geo-Tagging Framework for Address Extraction from Web Pages. In Advances in Data Mining. Applications and Theoretical Aspects, Petra Perner (Ed.). Springer International Publishing, Cham, 288–295. https://doi.org/10.1007/978-3-319-95786-9_22
-
[12]
Nir Fulman, Abdulkadir Memduhoğlu, and Alexander Zipf. 2024. Evidence for Systematic Bias in the Spatial Memory of Large Language Models. (2024)
work page 2024
-
[13]
Wes Gurnee and Max Tegmark. 2024. Language Models Represent Space and Time. https://doi.org/10.48550/arXiv.2310.02207 arXiv:2310.02207 [cs]
-
[14]
Ilya Ilyankou, Meihui Wang, James Haworth, and Stefano Cavazzi. 2024. CC- GPX: Extracting High-Quality Annotated Geospatial Data from Common Crawl. https://doi.org/10.48550/arXiv.2405.11039 arXiv:2405.11039 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.11039 2024
-
[15]
ISO. 2012. geographic data — MLGT: The authoritative multi-lingual geographic information terminology database. https://isotc211.geolexica.org/concepts/202/
work page 2012
-
[16]
I Think i Discovered a Military Base in the Middle of the Ocean
Levente Juhasz and Peter Mooney. 2022. “I Think i Discovered a Military Base in the Middle of the Ocean”—Null Island, the Most Real of Fictional Places. IEEE Access 10 (2022), 84147–84165. https://doi.org/10.1109/ACCESS.2022.3197222 Conference’17, July 2017, Washington, DC, USA Ilya Ilyankou, Meihui Wang, Stefano Cavazzi, and James Haworth
-
[17]
Julia Kreutzer, Isaac Caswell, Lisa Wang, Ahsan Wahab, Daan van Esch, Nasan- bayar Ulzii-Orshikh, Allahsera Tapo, Nishant Subramani, Artem Sokolov, Clay- tone Sikasote, Monang Setyawan, Supheakmungkol Sarin, Sokhar Samb, Benoît Sagot, Clara Rivera, Annette Rios, Isabel Papadimitriou, Salomey Osei, Pedro Or- tiz Suarez, Iroro Orife, Kelechi Ogueji, Andre N...
-
[18]
Transactions of the Association for Computational Linguistics 10 (Jan
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets. Transactions of the Association for Computational Linguistics 10 (Jan. 2022), 50–72. https://doi.org/10.1162/tacl_a_00447 arXiv:2103.12028 [cs]
- [19]
-
[20]
Gengchen Mai, Weiming Huang, Jin Sun, Suhang Song, Deepak Mishra, Ninghao Liu, Song Gao, Tianming Liu, Gao Cong, Yingjie Hu, Chris Cundy, Ziyuan Li, Rui Zhu, and Ni Lao. 2023. On the Opportunities and Challenges of Foundation Models for Geospatial Artificial Intelligence. http://arxiv.org/abs/2304.06798 arXiv:2304.06798 [cs]
-
[21]
Rohin Manvi, Samar Khanna, Marshall Burke, David Lobell, and Stefano Ermon
-
[22]
Large Language Models are Geographically Biased. http://arxiv.org/abs/ 2402.02680 arXiv:2402.02680 [cs]
-
[23]
Mazda Moayeri and Soheil Feizi. 2024. WorldBench: Quantifying Geographic Disparities in LLM Factual Recall. https://openreview.net/forum?id=fubvUIBggI
work page 2024
-
[24]
Hannes Mühleisen and Christian Bizer. 2012. Web Data Commons – Extracting Structured Data from Two Large Web Corpora. (2012)
work page 2012
-
[25]
John Paolillo, Daniel Pimienta, and Daniel Prado. 2005. Measuring Linguistic Diversity on the Internet. (2005)
work page 2005
-
[26]
Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. 2023. The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only. http://arxiv.org/abs/2306. 01116 arXiv:2306.01116 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Im- proving Language Understanding by Generative Pre-Training. (2018)
work page 2018
-
[28]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. http: //arxiv.org/abs/1910.10683 arXiv:1910.10683 [cs, stat]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[29]
2013.Linked Data: Structured data on the Web
Luke Ruth, David Wood, Marsha Zaidman, and Michael Hausenblas. 2013.Linked Data: Structured data on the Web . Simon and Schuster. Google-Books-ID: hTozEAAAQBAJ
work page 2013
-
[30]
Sebastian Schmidt, Simon Manschitz, Christoph Rensing, and Ralf Steinmetz
-
[31]
Extraction of Address Data from Unstructured Text using Free Knowl- edge Resources. In Proceedings of the 13th International Conference on Knowl- edge Management and Knowledge Technologies . ACM, Graz Austria, 1–8. https: //doi.org/10.1145/2494188.2494193
-
[32]
Pedro Javier Ortiz Suárez, Benoît Sagot, and Laurent Romary. 2021. Asynchronous Pipeline for Processing Huge Corpora on Medium to Low Resource Infrastruc- tures. (2021)
work page 2021
-
[33]
Gemini Team. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Willem Robert Van Hage, Thomas Ploeger, and Jesper Hoeksema. 2014. Number frequency on the web. InProceedings of the 23rd International Conference on World Wide Web. ACM, Seoul Korea, 571–572. https://doi.org/10.1145/2567948.2576962
-
[35]
W3Techs. 2024. Usage Statistics and Market Share of Top Level Domains for Websites, August 2024. https://w3techs.com/technologies/overview/top_level_ domain
work page 2024
-
[36]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. 2022. Finetuned Language Models Are Zero-Shot Learners. http://arxiv.org/abs/2109.01652 arXiv:2109.01652 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Tingyu Xie, Qi Li, Jian Zhang, Yan Zhang, Zuozhu Liu, and Hongwei Wang. 2023. Empirical Study of Zero-Shot NER with ChatGPT. (2023)
work page 2023
- [38]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.