Statistical Inference for Privatized Data with Unknown Sample Size
Pith reviewed 2026-05-24 00:03 UTC · model grok-4.3
The pith
Under calibrated noise on sample size, unbounded DP sampling distributions converge to bounded DP as n grows large.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
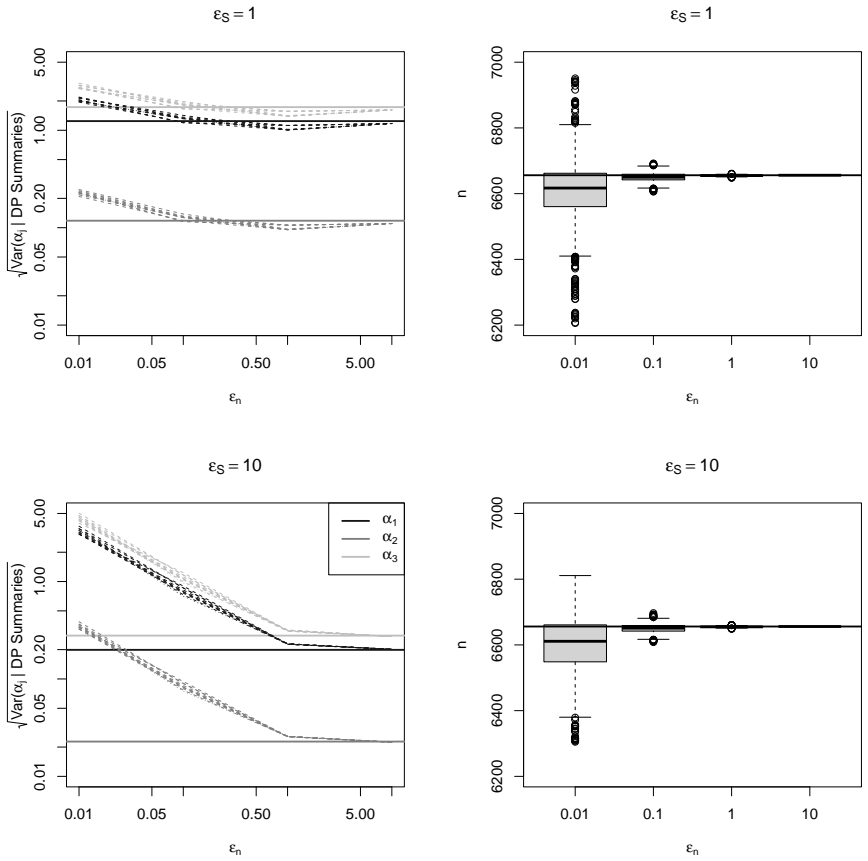
We show that the distance between the sampling distributions under unbounded DP and bounded DP goes to zero as the sample size n goes to infinity, provided that the noise used to privatize n is at an appropriate rate; we also establish that Approximate Bayesian Computation (ABC)-type posterior distributions converge under similar assumptions. We further give asymptotic results in the regime where the privacy budget for n goes to infinity, establishing similarity of sampling distributions as well as showing that the MLE in the unbounded setting converges to the bounded-DP MLE.
What carries the argument
Asymptotic equivalence of sampling distributions and ABC posteriors between unbounded and bounded DP when noise on the privatized sample size meets a rate condition relative to n and the privacy budget.
If this is right
- Inference procedures already validated for bounded DP can be applied directly to unbounded-DP data when n is large and the noise rate condition holds.
- The MLE computed from unbounded-DP data converges to the bounded-DP MLE once the privacy budget allocated to n diverges.
- The reversible-jump MCMC algorithm produces valid finite-sample posterior samples for models such as linear regression under unbounded DP.
- The Monte Carlo EM algorithm yields consistent MLEs for both bounded and unbounded DP privatized data.
Where Pith is reading between the lines
- For very large datasets the extra privacy cost of protecting the sample size becomes asymptotically negligible under proper calibration.
- The rate condition on noise for n could be relaxed or replaced by data-dependent tuning in practice.
- Similar convergence arguments might apply to other privacy mechanisms that release a random sample size, such as certain forms of local DP.
Load-bearing premise
The noise added to the sample size must be scaled at a rate that depends on both the privacy budget and n for the convergence results to hold.
What would settle it
A sequence of simulations or explicit counterexamples in which the noise variance on the sample size is held fixed or scaled too slowly, showing that the total variation or Wasserstein distance between unbounded-DP and bounded-DP sampling distributions fails to approach zero as n increases.
Figures



read the original abstract
We develop both theory and algorithms to analyze privatized data in unbounded differential privacy (DP), where even the sample size is considered a sensitive quantity that requires privacy protection. We show that the distance between the sampling distributions under unbounded DP and bounded DP goes to zero as the sample size $n$ goes to infinity, provided that the noise used to privatize $n$ is at an appropriate rate; we also establish that Approximate Bayesian Computation (ABC)-type posterior distributions converge under similar assumptions. We further give asymptotic results in the regime where the privacy budget for $n$ goes to infinity, establishing similarity of sampling distributions as well as showing that the MLE in the unbounded setting converges to the bounded-DP MLE. To facilitate valid, finite-sample Bayesian inference on privatized data under unbounded DP, we propose a reversible jump MCMC algorithm which extends the data augmentation MCMC of Ju et al, (2022). We also propose a Monte Carlo EM algorithm to compute the MLE from privatized data in both bounded and unbounded DP. We apply our methodology to analyze a linear regression model as well as a 2019 American Time Use Survey Microdata File which we model using a Dirichlet distribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops theory and algorithms for statistical inference from data privatized under unbounded differential privacy, where the sample size n itself is treated as sensitive and must be noised. It claims that the total variation (or similar) distance between the sampling distributions under unbounded DP and bounded DP tends to zero as n→∞ provided the noise added to n satisfies an appropriate rate condition relative to the privacy budget; similar convergence holds for ABC-type posterior distributions. Additional asymptotic results are given in the regime where the privacy budget allocated to n tends to infinity, including convergence of the unbounded-DP MLE to the bounded-DP MLE. The authors propose a reversible-jump MCMC algorithm extending the data-augmentation scheme of Ju et al. (2022) and a Monte Carlo EM algorithm for MLE computation, and illustrate the methods on linear regression and a Dirichlet model fitted to 2019 American Time Use Survey microdata.
Significance. If the rate conditions can be met in practice, the work provides a principled way to perform valid inference when sample size must be protected, thereby extending the applicability of differential privacy beyond the usual fixed-n setting. The explicit construction of RJMCMC and MCEM procedures supplies concrete, implementable tools for finite-sample Bayesian and frequentist analysis under unbounded DP.
major comments (3)
- [Abstract] Abstract and the statement of the main convergence theorems: the central claims that sampling distributions and ABC posteriors converge to their bounded-DP counterparts are conditioned on the noise added to n satisfying an 'appropriate rate' relative to the privacy budget and n, yet this rate is never stated quantitatively (e.g., as a specific order in ε or n). Because the rate condition is load-bearing for all asymptotic results, its explicit characterization must appear in the theorem statements.
- [Mechanism for privatizing n] Section describing the unbounded-DP mechanism for n: without an explicit functional form or variance bound on the noise added to n, it is impossible to verify whether the claimed convergence holds for any concrete privacy mechanism (e.g., discrete Laplace or Gaussian). The paper should supply the precise noise distribution and the resulting rate restriction before the convergence statements.
- [ABC posterior convergence] ABC convergence argument: the tolerance parameter in the ABC acceptance step must interact with the noise rate on n; the manuscript does not indicate whether the tolerance must shrink at a particular rate relative to the noise on n for the posterior convergence to remain valid.
minor comments (2)
- [Abstract] The abstract states that 'the MLE in the unbounded setting converges to the bounded-DP MLE' when the privacy budget for n tends to infinity; the precise regime (e.g., ε_n = ω(log n) or similar) should be stated explicitly.
- Notation for the privacy budget allocated to n versus the budget allocated to the data vector should be introduced consistently in the first theoretical section.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the manuscript. We agree that the points raised will improve clarity and address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and the statement of the main convergence theorems: the central claims that sampling distributions and ABC posteriors converge to their bounded-DP counterparts are conditioned on the noise added to n satisfying an 'appropriate rate' relative to the privacy budget and n, yet this rate is never stated quantitatively (e.g., as a specific order in ε or n). Because the rate condition is load-bearing for all asymptotic results, its explicit characterization must appear in the theorem statements.
Authors: We agree that the quantitative rate condition is central to the results and should be stated explicitly in the theorem statements rather than described only qualitatively. In the revision we will insert a precise condition (e.g., a bound on the variance or tail probability of the noise added to n that is o(1) or of a specific order in n and ε) directly into the statements of the main convergence theorems. revision: yes
-
Referee: [Mechanism for privatizing n] Section describing the unbounded-DP mechanism for n: without an explicit functional form or variance bound on the noise added to n, it is impossible to verify whether the claimed convergence holds for any concrete privacy mechanism (e.g., discrete Laplace or Gaussian). The paper should supply the precise noise distribution and the resulting rate restriction before the convergence statements.
Authors: We will revise the section on the mechanism for privatizing n to state the exact noise distribution employed (the discrete Laplace mechanism with scale parameter determined by the privacy budget allocated to n) together with the explicit variance bound and the resulting rate restriction that guarantees the convergence statements hold. revision: yes
-
Referee: [ABC posterior convergence] ABC convergence argument: the tolerance parameter in the ABC acceptance step must interact with the noise rate on n; the manuscript does not indicate whether the tolerance must shrink at a particular rate relative to the noise on n for the posterior convergence to remain valid.
Authors: We acknowledge that the dependence between the ABC tolerance and the noise level on n needs to be made explicit. In the revised manuscript we will add a short lemma or remark specifying the rate at which the tolerance must vanish relative to the noise on n in order for the ABC posterior convergence to hold. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central results establish asymptotic convergence of sampling distributions and ABC posteriors between unbounded and bounded DP as n → ∞, under an explicitly stated rate condition on noise for privatizing n. These follow from standard limit arguments in probability and DP definitions, without reduction to self-inputs. The reversible-jump MCMC extends Ju et al. (2022) as an algorithmic contribution rather than a load-bearing premise for the asymptotics; the MLE convergence and Monte Carlo EM are likewise derived independently. No self-definitional, fitted-prediction, or uniqueness-via-self-citation steps appear. The work remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard definitions and properties of bounded and unbounded differential privacy
- standard math Standard asymptotic analysis assumptions in statistics (e.g., regularity conditions for convergence in distribution)
Forward citations
Cited by 1 Pith paper
-
Large-Sample Bayesian Approximations for Privatized Data
A two-step approximate Bayesian sampler for privatized data is shown to be asymptotically valid under mild assumptions, with conservative frequentist properties in simulations and an application to 2022 American Commu...
Reference graph
Works this paper leans on
-
[1]
Statistic with an absolutely continuous component: s =Pn0 i=1 t(xi) + N, where t(xi) ∈ Rd has an absolutely continuous component: t(xi) d = χv +(1 − χ)w, where χ ∼ Bern(p) for p > 0, v is absolutely continuous, and w is any random variable; furthermore, N is absolutely continuous. For example, if t(xi) = [et(xi)]u l whereet(xi) is absolutely continuous, t...
-
[2]
Locally private additive mechanism with continuous noise: s =Pn0 i=1(t(xi)+ Ni), where Ni is absolutely continuous. 24
-
[3]
Integer-valued statistic with uniform noise: s =Pn0 i=1 t(xi) + U + N, where t(xi) ∈ Z and U ∼ Unif(−1/2, 1/2). For example, when N is a discrete Laplace random variable (Inusah and Kozubowski, 2006), then U + N has the truncated-uniform Laplace (tulap) distribution (Awan and Slavkovi´ c, 2018) which satisfies ϵ-DP. Proof. 1. This result follows from Lemm...
work page 2006
-
[4]
The convolution of an absolutely continuous random variable with another is absolutely continuous (Millier et al., 2016); the result follows from Lemma A.2
work page 2016
-
[5]
A.2 Main technical results Lemma A.5
This result follows from Lemmas A.3 and A.1. A.2 Main technical results Lemma A.5. [Multivariate Polya’s Theorem] If Xn d → X, and X ∈ Rd is a continuous random vector, then the convergence of the multivariate cdfs is uniform. It follows that KS(p(xn), p(x)) → 0. Proof. Let Φ be the cdf of N(0, 1), and let Y = Φ(X), and Yn = Φ(Xn), where Φ is applied elem...
-
[6]
If M satisfies f-DP, then it satisfies (0, 1 − 2c)-DP, where c is the unique fixed point of f: f(c) = c
-
[7]
If M satisfies ϵ-DP, then it satisfies 0, exp(ϵ)−1 exp(ϵ)+1 -DP
-
[8]
If M satisfies (ϵ, δ)-DP, then it satisfies 0, 2δ+exp(ϵ)−1 exp(ϵ)+1 -DP
-
[9]
If M satisfies µ-GDP, then it satisfies (0, 2Φ(µ/2) − 1)-DP
-
[10]
If M satisfies ρ-zCDP, then it satisfies 0, min np ρ/2, p 1 − exp(−ρ) o -DP
-
[11]
If M satisfies (α, ϵ)-RDP, then it satisfies 0, min np ρ/2, p 1 − exp(−ρ) o -DP. Proof. The first four properties are proved using f-DP. It is easy to see that if f has fixed point c, then f0,1−2c ≤ f. For properties 2-4, we will simply calculate c for the tradeoff functions fϵ,0, fϵ,δ and Gµ, and then apply property 1
-
[12]
It is easy to see that if f has fixed point c, then f0,1−2c ≤ f, since this is the tangent line of the convex function f at the point ( c, c)
-
[13]
The fixed point of fϵ,0 is the solution to the following equation: 1−exp(ϵ)c = exp(−ϵ)(1− c), which yields c = 1/(1 + exp(ϵ))
-
[14]
The fixed point of fϵ,δ is the solution to the following equation: 1 − δ − exp(ϵ)c = exp(−ϵ)(1 − δ − c), which yields c = (1 − δ)/(1 + exp(ϵ))
-
[15]
We calculate d dα Gµ(α) = (−1)ϕ(Φ−1(1 − α) − µ) ϕ(Φ−1(1 − α))
The fixed point c of Gµ(α) = Φ(Φ −1(1 − α) − µ) satisfies d dα Gµ(α) α=c = −1. We calculate d dα Gµ(α) = (−1)ϕ(Φ−1(1 − α) − µ) ϕ(Φ−1(1 − α)) . We can easily verify that 1 − Φ(µ/2) is the solution to d dα Gµ(α) = −1
-
[16]
Recall that ρ-zCDP is equivalent to bounding the order α R´ enyi Divergence byρα for all α > 1. Since R´ enyi divergences are monotonic: Dα1 ≤ Dα2 when 1 ≤ α1 ≤ α2, and D1 is the KL-divergence, we have that the KL-divergence is bounded above by ρ. Pinsker’s inequality implies that TV ≤ p ρ/2, and Bretagnole & Huber’s inequality implies that TV ≤ p 1 − exp(−ρ)
-
[17]
Recall that ( α, ϵ)-RDP means that Dα ≤ ϵ. Again, by the monotonicity of R´ enyi divergences, we have KL ≤ ϵ and apply the same inequalities as in part 5. 29 Lemma A.9. Let p(s|x) be the distribution of a (0, δ)-DP privacy mechanism, and let p(x|θ, n) be a distribution for x, where we assume that x consists of n copies of i.i.d. data. Then TV(p(s|θ, n), p...
work page 2022
-
[18]
Next, we suppose that p(n|ndp = n0) ∝ exp(−(ϵ2/2)(n − n0)2). First we will call A = ∞X k=0 exp(−ϵ2k2/2), and note that ∞X k=1 exp(−(ϵ2/2)(k − n0)2) ≥ A, and ∞X k=−∞ exp(−(ϵ2/2)(k − n0)2)) = 2A − 1 ≤ 2A. 31 Then, En|ndp=n0|n − n0| = P∞ k=1 |k − n0| exp(−(ϵ2/2)(k − n0)2)P∞ k=1 exp(−(ϵ2/2)(k − n0)2) (12) ≤ P∞ k=−∞ |k − n0| exp(−(ϵ2/2)(k − n0)2)(2A) AP∞ k=−∞ ...
work page 2020
-
[19]
The bound on the ratio of the privacy mechanisms follows from the differential privacy guarantees
We see that when p(n) is a flat prior, these terms cancel out, and when n ≥ 2, the transition probabilities for n and n∗ also cancel. The bound on the ratio of the privacy mechanisms follows from the differential privacy guarantees. In the case that n = 1 and n∗ = 2, we have an additional factor of 1 /2, from the ratio q(1|2)/q(2|1) = 1/2. Proof of Propos...
work page 2004
-
[20]
for any k ∈ K , if X(t) = ( k, Z) for some Z ∈ Zk, then the chain stays at k with probability ≥ ck > 0 and makes within model moves according to Pk, which satisfies ΦkPk = Φk,
-
[21]
geometrically ergodic and reversibly with respect to Φk,
the chain associated with Pk is Φk-irreducible and Φk-a.e. geometrically ergodic and reversibly with respect to Φk,
-
[22]
there exists s ∈ Z+ such that for all k, k′ ∈ K , Z Zk Φk(dz)P s ((k, z); ({k′} × Zk′)) > 0, i.e., if Z ∼ Ψk, then the chain starting from (k, z) can reach {k′}× Zk′ after s iterations with positive probability, then X(t) is π-a.e. geometrically ergodic. Proof. The result follows from Theorem 1, Lemma 2 and Lemma 3 of Qin (2023) along with some simplifyin...
work page 2023
-
[23]
, k, set x′ i = xi ± 1, with probability p(x′ i|xi) (could be w.p
For i = 1, . . . , k, set x′ i = xi ± 1, with probability p(x′ i|xi) (could be w.p. 1/2 unless xi = 0), and accept with probability p(s|x′)p(x′ i |eλi)p(x′ i|xi) p(s|x)p(xi|eλi)p(x′ i|xi) i1 , and notice that the first ratio is bounded between e−ϵ and eϵ (since changing xi to x′ i 36 can be achieved by adding/deleting a person), the second is a ratio of P...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.