Analyzing Multimodal Interaction Strategies for LLM-Assisted Manipulation of 3D Scenes
Pith reviewed 2026-05-23 18:39 UTC · model grok-4.3
The pith
Empirical study with 12 participants demonstrates that LLM-assisted systems support productive 3D scene manipulation in immersive environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through an empirical study with 12 participants, the authors show that LLM-assisted interactive systems can be used productively in immersive environments for 3D scene manipulation, while also mapping out common interaction patterns and key barriers that inform design recommendations for future systems.
What carries the argument
The empirical user study that combines quantitative usage data with post-experience questionnaire feedback to expose interaction patterns and barriers.
Load-bearing premise
The interaction patterns and barriers observed with a sample of 12 participants are representative of broader user behavior when manipulating 3D scenes with LLMs in immersive settings.
What would settle it
A larger follow-up study that records substantially different prompting styles, error rates, or productivity measures across a wider participant pool would undermine the generalizability of the observed patterns.
Figures




read the original abstract
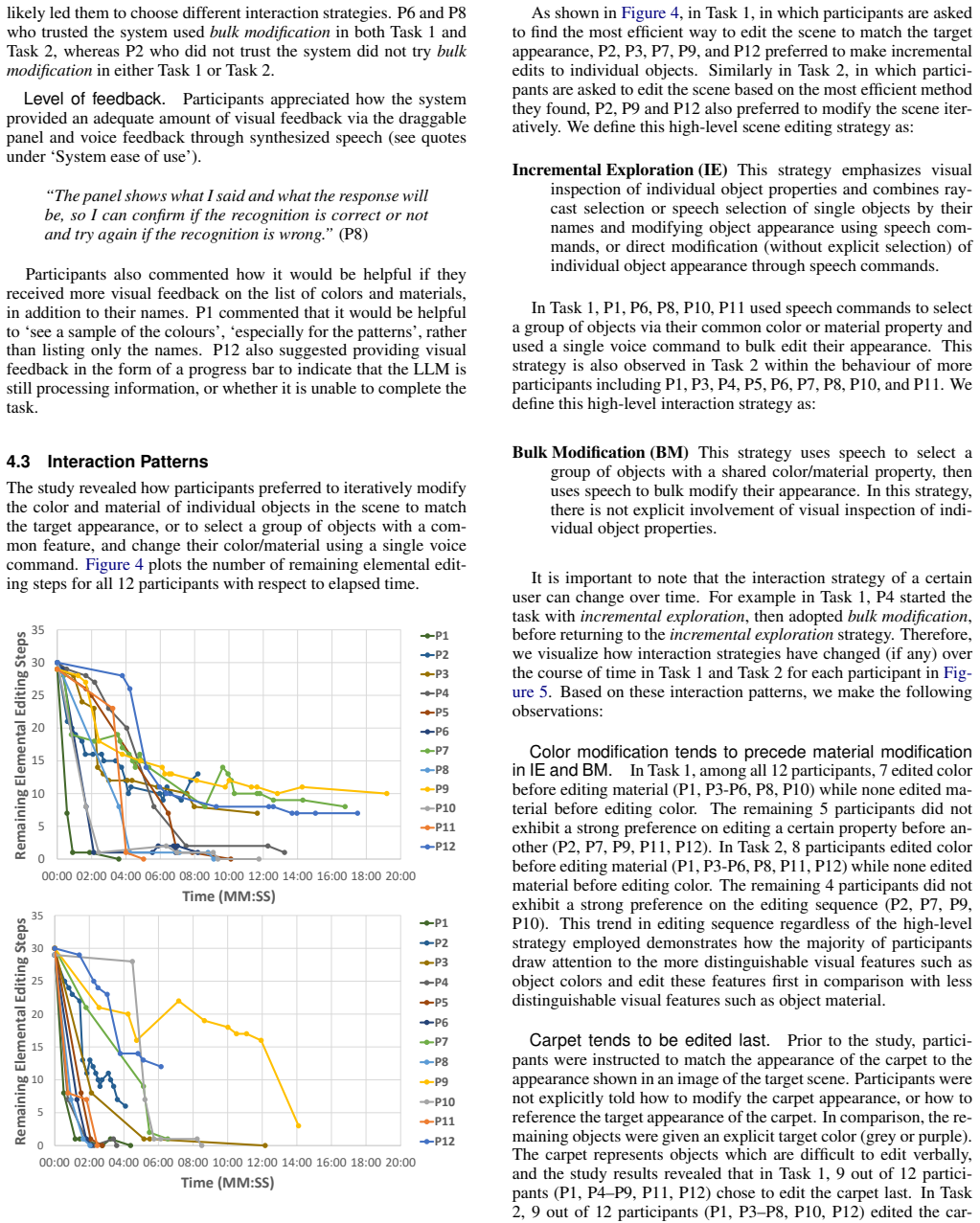
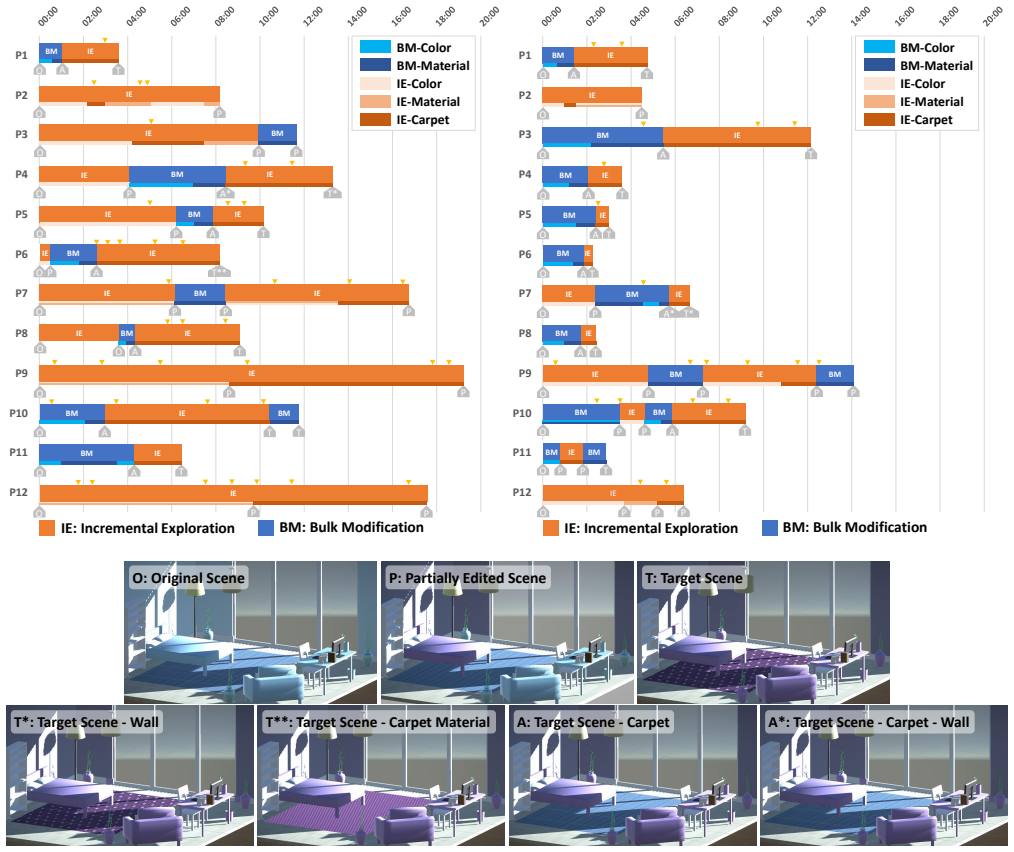
As more applications of large language models (LLMs) for 3D content for immersive environments emerge, it is crucial to study user behaviour to identify interaction patterns and potential barriers to guide the future design of immersive content creation and editing systems which involve LLMs. In an empirical user study with 12 participants, we combine quantitative usage data with post-experience questionnaire feedback to reveal common interaction patterns and key barriers in LLM-assisted 3D scene editing systems. We identify opportunities for improving natural language interfaces in 3D design tools and propose design recommendations for future LLM-integrated 3D content creation systems. Through an empirical study, we demonstrate that LLM-assisted interactive systems can be used productively in immersive environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a mixed-methods empirical user study with 12 participants that combines quantitative usage logs and post-experience questionnaires to analyze interaction patterns and barriers when using LLM-assisted systems for manipulating 3D scenes in immersive environments. It identifies common strategies, key challenges, and offers design recommendations for future LLM-integrated 3D content creation tools, with the central claim that such systems can be used productively in immersive settings.
Significance. If the observational findings hold, the work provides an early empirical foundation for understanding user behaviors in LLM-assisted immersive 3D editing, which is timely given the emergence of such applications. The mixed-methods approach (logs + questionnaires) is appropriate for an exploratory HCI study and directly supports the feasibility demonstration.
major comments (2)
- [User Study / Methodology] User Study / Methodology: The central productivity and pattern-identification claims rest on data from only 12 participants with no reported statistical tests, power analysis, exclusion criteria, or demographic details; this leaves the evidence for 'common' patterns and productive use descriptive rather than robust, directly weakening the generalizability asserted in the abstract and discussion.
- [Results / Analysis] Results / Analysis: The quantitative usage data and questionnaire feedback are presented without baseline comparisons, effect sizes, or inferential statistics, so the claim that LLM-assisted systems 'can be used productively' is supported only by existence (successful sessions occurred) rather than by evidence that the observed patterns exceed chance or prior non-LLM interfaces.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction could more explicitly distinguish the feasibility claim from the pattern-identification claims to clarify what the small sample can and cannot support.
- [Figures / Tables] Figure captions and table descriptions should include exact sample sizes and any filtering applied to the log data for reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We value the referee's assessment of the study's timeliness and methodological appropriateness for an exploratory HCI investigation. We address each major comment below, providing clarifications on the study's design and scope.
read point-by-point responses
-
Referee: [User Study / Methodology] User Study / Methodology: The central productivity and pattern-identification claims rest on data from only 12 participants with no reported statistical tests, power analysis, exclusion criteria, or demographic details; this leaves the evidence for 'common' patterns and productive use descriptive rather than robust, directly weakening the generalizability asserted in the abstract and discussion.
Authors: This study is explicitly positioned as an exploratory investigation into user behaviors with LLM-assisted 3D manipulation in immersive environments, following established practices in HCI for early-stage research on novel interfaces. Small participant numbers (N=12) are common in such studies to uncover qualitative patterns and barriers rather than to support broad statistical inferences. No statistical tests or power analyses were conducted because the research questions focused on identifying interaction strategies through observation and self-report, not on testing hypotheses or comparing conditions. We will include any omitted demographic details, exclusion criteria, and study procedure specifics in the revised manuscript to enhance transparency. The abstract and discussion emphasize the descriptive nature of the findings and do not assert statistical generalizability. revision: partial
-
Referee: [Results / Analysis] Results / Analysis: The quantitative usage data and questionnaire feedback are presented without baseline comparisons, effect sizes, or inferential statistics, so the claim that LLM-assisted systems 'can be used productively' is supported only by existence (successful sessions occurred) rather than by evidence that the observed patterns exceed chance or prior non-LLM interfaces.
Authors: The productivity claim is framed as a feasibility demonstration: all participants were able to complete the 3D scene manipulation tasks using the LLM-assisted system within the immersive environment. This is evidenced by the usage logs showing successful interactions and positive questionnaire feedback on usability. As the first study of its kind focusing on LLM integration in this context, we did not include baseline conditions or non-LLM comparisons, which would be valuable for future comparative work but beyond the scope of identifying LLM-specific patterns. The mixed-methods data provide rich descriptive insights into strategies and barriers, supporting the design recommendations. We can clarify the wording in the abstract and discussion to emphasize the observational basis of the findings. revision: no
Circularity Check
No significant circularity
full rationale
The paper is an empirical user study reporting observational findings from 12 participants on LLM-assisted 3D scene manipulation. It contains no equations, derivations, fitted parameters, predictions, or modeling steps. The central claim is a feasibility demonstration supported directly by the collected usage data and questionnaire results. No load-bearing steps reduce to self-definition, self-citation chains, or renamed inputs. This is a standard non-circular empirical report.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
S. Aghel Manesh, T. Zhang, Y . Onishi, K. Hara, S. Bateman, J. Li, and A. Tang. How people prompt generative ai to create interactive vr scenes. In Proceedings of the 2024 ACM Designing Interactive Systems Conference, pp. 2319–2340, 2024. 2
work page 2024
-
[3]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [4]
-
[5]
E. Bozkir, S. ¨Ozdel, K. H. C. Lau, M. Wang, H. Gao, and E. Kas- neci. Embedding large language models into extended reality: Op- portunities and challenges for inclusion, engagement, and privacy. In Proceedings of the 6th ACM Conference on Conversational User In- terfaces, pp. 1–7, 2024. 2
work page 2024
-
[6]
J. Brooke et al. Sus-a quick and dirty usability scale. Usability evalu- ation in industry, 189(194):4–7, 1996. 4
work page 1996
-
[7]
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhari- wal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amod...
work page 1901
-
[8]
F. De La Torre, C. M. Fang, H. Huang, A. Banburski-Fahey, J. Amores Fernandez, and J. Lanier. Llmr: Real-time prompting of interactive worlds using large language models. In Proceedings of the CHI Conference on Human Factors in Computing Systems, pp. 1–22,
- [9]
-
[10]
A. M. Feit, D. Weir, and A. Oulasvirta. How we type: Movement strategies and performance in everyday typing. In Proceedings of the 2016 chi conference on human factors in computing systems , pp. 4262–4273, 2016. 2
work page 2016
-
[11]
C. R. Foy, J. J. Dudley, A. Gupta, H. Benko, and P. O. Kristensson. Understanding, detecting and mitigating the effects of coactivations in ten-finger mid-air typing in virtual reality. In Proceedings of the 2021 CHI conference on human factors in computing systems , pp. 1–11,
work page 2021
-
[12]
D. Giunchi, N. Numan, E. Gatti, and A. Steed. Dreamcodevr: Towards democratizing behavior design in virtual reality with speech-driven programming. In 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR), pp. 579–589. IEEE, 2024. 1, 2, 9
work page 2024
-
[13]
J. Guo, V . Mohanty, J. H. Piazentin Ono, H. Hao, L. Gou, and L. Ren. Investigating interaction modes and user agency in human-llm collab- oration for domain-specific data analysis. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems , pp. 1–9,
-
[14]
S. G. Hart and L. E. Staveland. Development of nasa-tlx (task load index): Results of empirical and theoretical research. In Advances in psychology, vol. 52, pp. 139–183. Elsevier, 1988. 4
work page 1988
-
[15]
K. He, A. Lapham, and Z. Li. Enhancing narratives with saymotion’s text-to-3d animation and llms. In ACM SIGGRAPH 2024 Real-Time Live!, pp. 1–2. 2024. 2
work page 2024
- [16]
-
[17]
Inner Monologue: Embodied Reasoning through Planning with Language Models
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, et al. Inner monologue: Em- bodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
A. Jebeli, L. K. Chen, K. Guerrerio, S. Papparotto, L. Berlin, and B. J. Harden. Quantifying the quality of parent-child interaction through machine-learning based audio and video analysis: Towards a vision of ai-assisted coaching support for social workers. ACM Journal on Computing and Sustainable Societies, 2(1):1–21, 2024. 2
work page 2024
-
[19]
L. Jiang, M. Phutane, and S. Azenkot. Beyond audio description: Exploring 360 video accessibility with blind and low vision users through collaborative creation. In Proceedings of the 25th interna- tional ACM SIGACCESS conference on computers and accessibility , pp. 1–17, 2023. 2
work page 2023
-
[20]
M. Konenkov, A. Lykov, D. Trinitatova, and D. Tsetserukou. Vr- gpt: Visual language model for intelligent virtual reality applications. arXiv preprint arXiv:2405.11537, 2024. 2
- [21]
-
[22]
J. Lee, J. Wang, E. Brown, L. Chu, S. S. Rodriguez, and J. E. Froehlich. Gazepointar: A context-aware multimodal voice assis- tant for pronoun disambiguation in wearable augmented reality. In Proceedings of the CHI Conference on Human Factors in Computing Systems, pp. 1–20, 2024. 2
work page 2024
- [23]
- [24]
-
[25]
G. Manfredi, U. Erra, and G. Gilio. A mixed reality approach for in- novative pair programming education with a conversational ai virtual avatar. In Proceedings of the 27th International Conference on Eval- uation and Assessment in Software Engineering , pp. 450–454, 2023. 2
work page 2023
-
[26]
OpenAI. Hello GPT-4o, May 2024. Available at https://openai. com/index/hello-gpt-4o . 2
work page 2024
-
[27]
A. Plopski, T. Hirzle, N. Norouzi, L. Qian, G. Bruder, and T. Lan- glotz. The eye in extended reality: A survey on gaze interaction and eye tracking in head-worn extended reality. ACM Computing Surveys (CSUR), 55(3):1–39, 2022. 2
work page 2022
-
[28]
S. Rabsahl, T. Satzger, S. Kalamkar, J. Grubert, and F. Beck. Sym- bolic event visualization for analyzing user input and behavior of aug- mented reality sessions. 2023. 2
work page 2023
-
[29]
I. Rakkolainen, A. Farooq, J. Kangas, J. Hakulinen, J. Rantala, M. Tu- runen, and R. Raisamo. Technologies for multimodal interaction in extended reality—a scoping review. Multimodal Technologies and In- teraction, 5(12):81, 2021. 1
work page 2021
-
[30]
J. Roberts, A. Banburski-Fahey, and J. Lanier. Steps towards prompt- based creation of virtual worlds. arXiv preprint arXiv:2211.05875 ,
-
[31]
R. Rodriguez, B. T. Sullivan, M. D. Barrera Machuca, A. U. Batmaz, C. Tornatzky, and F. R. Ortega. An artists’ perspectives on natural interactions for virtual reality 3d sketching. In Proceedings of the CHI Conference on Human Factors in Computing Systems, pp. 1–20,
- [32]
-
[33]
M. Schrepp, A. Hinderks, and J. Thomaschewski. Design and evalu- ation of a short version of the user experience questionnaire (ueq-s). International Journal of Interactive Multimedia and Artificial Intelli- gence, 4 (6), 103-108., 2017. 4, 5
work page 2017
-
[34]
J. Song, B. Wang, Z. Wang, and D. K.-M. Yip. From expanded cinema to extended reality: How ai can expand and extend cinematic experi- ences. In Proceedings of the 16th International Symposium on Visual Information Communication and Interaction, pp. 1–5, 2023. 2
work page 2023
-
[35]
B. Spittle, M. Frutos-Pascual, C. Creed, and I. Williams. A review of interaction techniques for immersive environments. IEEE Trans- actions on Visualization and Computer Graphics , 29(9):3900–3921,
-
[36]
J. R. Trippas, S. F. D. Al Lawati, J. Mackenzie, and L. Gallagher. What do users really ask large language models? an initial log analysis of google bard interactions in the wild. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2703–2707, 2024. 2
work page 2024
-
[37]
M. Tsimpoukelli, J. L. Menick, S. Cabi, S. Eslami, O. Vinyals, and F. Hill. Multimodal few-shot learning with frozen language mod- els. Advances in Neural Information Processing Systems, 34:200–212,
-
[38]
A. S. Williams and F. R. Ortega. Understanding gesture and speech multimodal interactions for manipulation tasks in augmented reality using unconstrained elicitation. Proceedings of the ACM on Human- Computer Interaction, 4(ISS):1–21, 2020. 2
work page 2020
-
[39]
P. C. Wright, R. E. Fields, and M. D. Harrison. Analyzing human- computer interaction as distributed cognition: the resources model. Human-Computer Interaction, 15(1):1–41, 2000. 2
work page 2000
- [40]
-
[41]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Y . Zhang, Y . Li, L. Cui, D. Cai, L. Liu, T. Fu, X. Huang, E. Zhao, Y . Zhang, Y . Chen, et al. Siren’s song in the ai ocean: a sur- vey on hallucination in large language models. arXiv preprint arXiv:2309.01219, 2023. 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
X. Zhou, A. S. Williams, and F. R. Ortega. Eliciting multimodal ges- ture+ speech interactions in a multi-object augmented reality environ- ment. In Proceedings of the 28th ACM Symposium on Virtual Reality Software and Technology, pp. 1–10, 2022. 2
work page 2022
-
[43]
C. Zimmerer, E. Wolf, S. Wolf, M. Fischbach, J.-L. Lugrin, and M. E. Latoschik. Finally on par?! multimodal and unimodal interaction for open creative design tasks in virtual reality. In Proceedings of the 2020 international conference on multimodal interaction , pp. 222– 231, 2020. 2
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.