DGSNA: Dynamic Generative Scene-based Noise Addition method
Pith reviewed 2026-05-23 17:41 UTC · model grok-4.3
The pith
DGSNA generates dynamic scene-based noise via prompts and diffusion models to augment speech data without fixed libraries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
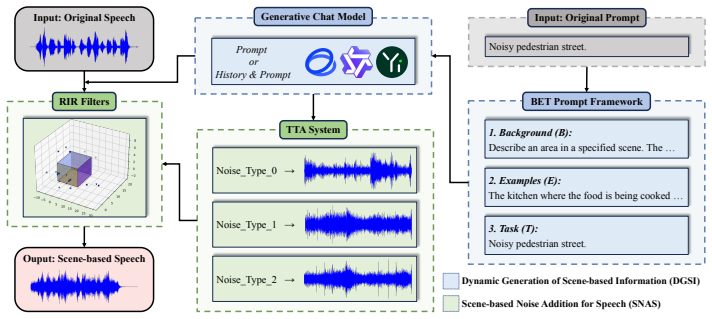
DGSNA combines the DGSI module, which uses a BET prompt framework to produce logic-compliant scene dimensions, sound sources, and microphone positions, with the SNAS module, which applies a Time-Frequency Diffusion text-to-audio model to synthesize scene-specific noise; the resulting audio is mixed with clean speech via RIR filters, removing dependence on pre-existing noise libraries and static metadata.
What carries the argument
BET (Background, Examples, Task) prompt framework for dynamic scene generation paired with Time-Frequency Diffusion text-to-audio synthesis for scene-matched noise.
If this is right
- Speech recognition and keyword spotting models trained with DGSNA-augmented data show relative error reductions of up to 11.32 percent.
- The pipeline works alongside conventional noise-addition methods rather than replacing them.
- Scene enumeration and detailed manual description are no longer required for covering diverse acoustic conditions.
- The labor of collecting or licensing large noise libraries is reduced by on-demand synthesis.
Where Pith is reading between the lines
- If the generated scenes prove transferable, the approach could scale training data to arbitrary numbers of environments without additional field recordings.
- The same prompt-plus-diffusion structure might be adapted for other audio domains that require context-specific interference, such as music or environmental sound classification.
- Further advances in text-to-audio fidelity would directly raise the ceiling on how closely the synthesized noise can match measured room acoustics.
Load-bearing premise
Outputs from the generative language model and the diffusion audio model are realistic and representative enough of real acoustic environments to transfer when models are tested on actual recordings.
What would settle it
Evaluation on a held-out corpus of real recorded noisy speech collected from physical rooms and devices shows no accuracy gain, or a loss, for models trained with DGSNA-augmented data.
Figures









read the original abstract
To ensure the reliable operation of speech systems across diverse environments, noise addition methods have emerged as the standard solution.However, existing methods offer limited coverage of real-world scenes and depend on pre-existing noise libraries and scene metadata.This paper presents prompt-based Dynamic Generative Scene-based Noise Addition (DGSNA), a novel approach driven by generative language models that integrates Dynamic Generation of Scene-based Information (DGSI) with Scene-based Noise Addition for Speech (SNAS).The DGSI module, with a BET (Background, Examples, Task) prompt framework, dynamically generates logic-compliant scene-based information, including scene dimensions, sound sources, and microphone positions, thereby addressing the challenges of scene enumeration and detailed description.Complementing this, the SNAS module employs a Time-Frequency Diffusion-based (TFD) Text-to-Audio model to synthesize scene-specific noise. By integrating this noise with clean speech via Room Impulse Response (RIR) filters, the module streamlines the traditionally labor-intensive process of replicating diverse acoustic environments.Experimental results show that DGSNA significantly enhances the robustness of speech recognition and keyword spotting models, achieving relative improvements of up to 11.32\%. Furthermore, DGSNA is highly compatible with existing noise addition techniques. Our implementation and demonstrations are available at https://dgsna.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DGSNA, a dynamic generative method for scene-based noise addition in speech augmentation. It combines DGSI, which employs a BET prompt framework with generative language models to produce scene dimensions, sound sources, and microphone positions, with SNAS, which uses a time-frequency diffusion (TFD) text-to-audio model to synthesize scene-specific noise that is then convolved with room impulse responses (RIRs). The central claim is that this pipeline enhances robustness of automatic speech recognition (ASR) and keyword spotting (KWS) models, delivering relative improvements of up to 11.32%, while remaining compatible with existing noise-addition techniques; code and demos are provided.
Significance. If the reported gains are reproducible and the generated data distribution matches real acoustic conditions, the approach could reduce reliance on static noise libraries and manual scene enumeration, offering a scalable augmentation strategy for improving generalization in diverse environments. The open-source implementation supports reproducibility and is a clear strength.
major comments (2)
- [DGSI and SNAS modules] DGSI and SNAS module descriptions: the central robustness claim (up to 11.32% relative gain) rests on the assumption that BET-prompt-generated scene parameters plus TFD-synthesized audio convolved with RIRs produce training distributions sufficiently close to real test conditions, yet no quantitative validation (comparison of generated vs. measured RIRs, acoustic metrics, or perceptual similarity to real recordings) is reported.
- [Experimental results] Experimental results: the headline performance claim lacks any reported details on datasets, model architectures, baseline methods, number of runs, statistical tests, or error bars, preventing assessment of whether the 11.32% figure is robust or influenced by post-hoc choices.
minor comments (1)
- [Abstract] Abstract states compatibility with existing techniques but provides no concrete examples or ablation results demonstrating additive gains when combined with standard methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript's clarity and support for its claims.
read point-by-point responses
-
Referee: [DGSI and SNAS modules] DGSI and SNAS module descriptions: the central robustness claim (up to 11.32% relative gain) rests on the assumption that BET-prompt-generated scene parameters plus TFD-synthesized audio convolved with RIRs produce training distributions sufficiently close to real test conditions, yet no quantitative validation (comparison of generated vs. measured RIRs, acoustic metrics, or perceptual similarity to real recordings) is reported.
Authors: We acknowledge that the manuscript does not include direct quantitative validation (e.g., acoustic metrics or perceptual comparisons) of the generated distributions against real recordings. Our primary evidence is the observed gains in downstream ASR and KWS tasks. To address this, we will add a dedicated validation subsection reporting acoustic feature similarities, spectrogram comparisons, and perceptual listening test results in the revised version. revision: yes
-
Referee: [Experimental results] Experimental results: the headline performance claim lacks any reported details on datasets, model architectures, baseline methods, number of runs, statistical tests, or error bars, preventing assessment of whether the 11.32% figure is robust or influenced by post-hoc choices.
Authors: We agree that the experimental section requires more complete reporting. The revised manuscript will expand this section with explicit details on all datasets, model architectures, baseline methods, number of runs, statistical tests, and error bars to enable full reproducibility and assessment of result robustness. revision: yes
Circularity Check
No circularity; engineering pipeline with no self-referential derivations or fitted predictions
full rationale
The paper presents DGSNA as a prompt-driven pipeline (BET prompts in DGSI for scene parameters, TFD diffusion in SNAS for audio, RIR convolution) whose outputs are used to augment training data. No equations, uniqueness theorems, ansatzes, or predictions appear in the provided text that reduce the claimed robustness gains to a fitted input or self-citation chain. The 11.32% improvement is reported from experiments rather than derived by construction from the method itself. This is a standard non-circular engineering description whose validity hinges on external validation of the generative outputs, not on internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can generate logic-compliant scene descriptions (dimensions, sources, microphone positions) when given a BET prompt template.
- domain assumption A Time-Frequency Diffusion text-to-audio model can synthesize noise that, when convolved with RIR, produces realistic acoustic mixtures.
Reference graph
Works this paper leans on
-
[1]
Peters, N., Sen, D., Kim, M. Y., Wuebbolt, O., & Weiss, S. M. (2015, October). Scene-based audio implemented with higher order ambisonics (HOA). In SMPTE 2015 Annual Technical Conference and Exhibition (pp. 1-13). SMPTE
work page 2015
-
[2]
Haykin, S., & Chen, Z. (2005). The cocktail party problem. Neural com- putation, 17(9), 1875-1902
work page 2005
-
[3]
Dokmani´ c, I., Scheibler, R., & Vetterli, M. (2015). Raking the cocktail party. IEEE journal of selected topics in signal processing , 9(5), 825-836
work page 2015
-
[4]
Pulkki, V. (2007). Spatial sound reproduction with directional audio cod- ing. Journal of the Audio Engineering Society , 55(6), 503-516
work page 2007
-
[5]
Arend, J. M., Gar´ ı, S. V. A., Schissler, C., Klein, F., & Robinson, P. W. (2021). Six-degrees-of-freedom parametric spatial audio based on one monaural room impulse response. Journal of the Audio Engineering So- ciety, 69(7/8), 557-575
work page 2021
-
[6]
Koyama, Y., Shigemi, K., Takahashi, M., Shimada, K., Takahashi, N., Tsunoo, E., ... & Mitsufuji, Y. (2022, May). Spatial data augmenta- tion with simulated room impulse responses for sound event localiza- tion and detection. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 8872-8876). IEEE
work page 2022
-
[7]
Wang, Y., Yao, Q., Kwok, J. T., & Ni, L. M. (2020). Generalizing from a few examples: A survey on few-shot learning. ACM computing surveys (csur), 53(3), 1-34
work page 2020
-
[8]
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhari- wal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems , 33, 1877-1901
work page 2020
-
[9]
Yang, D., Yu, J., Wang, H., Wang, W., Weng, C., Zou, Y., & Yu, D. (2023). Diffsound: Discrete diffusion model for text-to-sound generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing , 31, 1720-1733. 25
work page 2023
-
[10]
Rainal, A. J. (1961). Sampling technique for generating Gaussian noise. Review of Scientific Instruments , 32(3), 327-331
work page 1961
-
[11]
Peji´ c, D., Gazivoda, N., Liˇ cina, B., Urekar, M., Sovilj, P., & Vujiˇ ci´ c, B. (2018). A proposal of a novel method for generating discrete analog uniform noise. Advances in Electrical and Computer Engineering , 18(3), 61-66
work page 2018
-
[12]
Alspector, J., Gannett, J. W., Haber, S., Parker, M. B., & Chu, R. (1990, May). Generating multiple analog noise sources from a single linear feedback shift register with neural network applications. In 1990 IEEE International Symposium on Circuits and Systems (ISCAS) (pp. 1058- 1061). IEEE
work page 1990
- [13]
-
[14]
Toki´ c, D., & Juriˇ si´ c, D. (2022, May). High-precision fractional-order integrator for generating pink noise from white noise. In 2022 45th Ju- bilee International Convention on Information, Communication and Elec- tronic Technology (MIPRO) (pp. 191-194). IEEE
work page 2022
-
[15]
Xu, C. (2019). An easy algorithm to generate colored noise sequences. The Astronomical Journal, 157(3), 127
work page 2019
-
[16]
Reddy, V. U. (1998). On fast fourier transform: a popular tool for spec- trum analysis. Resonance, 3(10), 79-88
work page 1998
-
[17]
Tu, Z., Deadman, J., Ma, N., & Barker, J. (2022, May). Auditory- based data augmentation for end-to-end automatic speech recognition. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 7447-7451). IEEE
work page 2022
-
[18]
Specaugment: A simple data augmentation method for automatic speech recognition,
Park, D. S., Chan, W., Zhang, Y., Chiu, C. C., Zoph, B., Cubuk, E. D., & Le, Q. V. (2019). Specaugment: A simple data augmentation method for automatic speech recognition. arXiv preprint arXiv:1904.08779
-
[19]
Allen, J. B., & Berkley, D. A. (1979). Image method for efficiently sim- ulating small-room acoustics. The Journal of the Acoustical Society of America, 65(4), 943-950. 26
work page 1979
-
[20]
Funkhouser, T., Tsingos, N., Carlbom, I., Elko, G., Sondhi, M., West, J. E., ... & Ngan, A. (2004). A beam tracing method for interactive architectural acoustics. The Journal of the acoustical society of America , 115(2), 739-756
work page 2004
-
[21]
Scheibler, R., Bezzam, E., & Dokmani´ c, I. (2018, April). Pyroomacous- tics: A python package for audio room simulation and array processing algorithms. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 351-355). IEEE
work page 2018
-
[22]
Lehmann, E. A., & Johansson, A. M. (2009). Diffuse reverberation model for efficient image-source simulation of room impulse responses. IEEE Transactions on Audio, Speech, and Language Processing , 18(6), 1429-1439
work page 2009
-
[23]
Tang, Z., Chen, L., Wu, B., Yu, D., & Manocha, D. (2020, May). Im- proving reverberant speech training using diffuse acoustic simulation. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6969-6973). IEEE
work page 2020
-
[24]
Ackley, D. H., Hinton, G. E., & Sejnowski, T. J. (1985). A learning algorithm for Boltzmann machines. Cognitive science, 9(1), 147-169
work page 1985
-
[25]
J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S.,
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. Ad- vances in neural information processing systems , 27
work page 2014
-
[26]
X., Yu, M., Tang, Z., Manocha, D., & Yu, D
Ratnarajah, A., Zhang, S. X., Yu, M., Tang, Z., Manocha, D., & Yu, D. (2022, May). FAST-RIR: Fast neural diffuse room impulse response gener- ator. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 571-575). IEEE
work page 2022
-
[27]
Shalyminov, I., Sordoni, A., Atkinson, A., & Schulz, H. (2021). GRTr: Generative-retrieval transformers for data-efficient dialogue domain adap- tation. IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, 29, 2484-2492
work page 2021
-
[28]
Huang, R., Li, M., Yang, D., Shi, J., Chang, X., Ye, Z., ... & Watanabe, S. (2024, March). Audiogpt: Understanding and generating speech, mu- sic, sound, and talking head. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 38, No. 21, pp. 23802-23804). 27
work page 2024
-
[29]
Chen, J., Guo, H., Yi, K., Li, B., & Elhoseiny, M. (2022). Visualgpt: Data-efficient adaptation of pretrained language models for image cap- tioning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 18030-18040)
work page 2022
-
[30]
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training
work page 2018
-
[31]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., ... & McGrew, B. (2023). Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., ... & Zhu, T. (2023). Qwen technical report. arXiv preprint arXiv:2309.16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [33]
-
[34]
F., Leike, J., Brown, T., Martic, M., Legg, S., & Amodei, D
Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., & Amodei, D. (2017). Deep reinforcement learning from human preferences.Advances in neural information processing systems , 30
work page 2017
-
[35]
An important next step on our AI journey
Google. An important next step on our AI journey. https: //blog.google/intl/en-africa/products/explore-get-answers/ an-important-next-step-on-our-ai-journey/
-
[36]
Anthropic. Introducing Claude. https://www.anthropic.com/news/ introducing-claude
-
[37]
Kong, Q., Xu, Y., Iqbal, T., Cao, Y., Wang, W., & Plumbley, M. D. (2019, May). Acoustic scene generation with conditional SampleRNN. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 925-929). IEEE
work page 2019
-
[38]
Liu, X., Iqbal, T., Zhao, J., Huang, Q., Plumbley, M. D., & Wang, W. (2021, October). Conditional sound generation using neural discrete time-frequency representation learning. In 2021 IEEE 31st International Workshop on Machine Learning for Signal Processing (MLSP) (pp. 1-6). IEEE. 28
work page 2021
-
[39]
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems , 33, 6840- 6851
work page 2020
-
[40]
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015, June). Deep unsupervised learning using nonequilibrium thermo- dynamics. In International conference on machine learning (pp. 2256- 2265). pmlr
work page 2015
- [41]
-
[42]
Audioldm: Text-to-audio generation with latent diffusion models,
Liu, H., Chen, Z., Yuan, Y., Mei, X., Liu, X., Mandic, D., ... & Plumbley, M. D. (2023). Audioldm: Text-to-audio generation with latent diffusion models. arXiv preprint arXiv:2301.12503
-
[43]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10684-10695)
work page 2022
-
[44]
Ghosal, D., Majumder, N., Mehrish, A., & Poria, S. (2023, October). Text-to-audio generation using instruction guided latent diffusion model. In Proceedings of the 31st ACM International Conference on Multimedia (pp. 3590-3598)
work page 2023
- [45]
-
[46]
Wu, Y., Chen, K., Zhang, T., Hui, Y., Berg-Kirkpatrick, T., & Dub- nov, S. (2023, June). Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP) (pp. 1-5). IEEE
work page 2023
-
[47]
Kingma, D. P., & Welling, M. (2013, December). Auto-encoding varia- tional bayes. 29
work page 2013
-
[48]
Kong, J., Kim, J., & Bae, J. (2020). Hifi-gan: Generative adversar- ial networks for efficient and high fidelity speech synthesis. Advances in neural information processing systems, 33, 17022-17033
work page 2020
-
[49]
Bu, H., Du, J., Na, X., Wu, B., & Zheng, H. (2017, November). Aishell-1: An open-source mandarin speech corpus and a speech recognition base- line. In 2017 20th conference of the oriental chapter of the international coordinating committee on speech databases and speech I/O systems and assessment (O-COCOSDA) (pp. 1-5). IEEE
work page 2017
-
[50]
Zhang, B., Lv, H., Guo, P., Shao, Q., Yang, C., Xie, L., ... & Peng, Z. (2022, May). Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6182-6186). IEEE
work page 2022
-
[51]
Leroy, D., Coucke, A., Lavril, T., Gisselbrecht, T., & Dureau, J. (2019, May). Federated learning for keyword spotting. In ICASSP 2019-2019 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 6341-6345). IEEE
work page 2019
-
[52]
C., Parmar, N., Zhang, Y., Yu, J.,
Gulati, A., Qin, J., Chiu, C. C., Parmar, N., Zhang, Y., Yu, J., ... & Pang, R. (2020). Conformer: Convolution-augmented transformer for speech recognition. arXiv preprint arXiv:2005.08100
- [53]
-
[54]
Hou, J., Xie, L., & Zhang, S. (2022). Two-stage streaming keyword de- tection and localization with multi-scale depthwise temporal convolution. Neural Networks, 150, 28-42
work page 2022
-
[55]
Wang, J., Xu, M., Hou, J., Zhang, B., Zhang, X. L., Xie, L., & Pan, F. (2023, June). Wekws: A production first small-footprint end-to-end key- word spotting toolkit. In ICASSP 2023-2023 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1-5). IEEE. 30
work page 2023
-
[56]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30
work page 2017
-
[57]
Huang, Y., Bai, Y., Zhu, Z., Zhang, J., Zhang, J., Su, T., ... & He, J. (2023). C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. Advances in Neural Information Processing Systems , 36, 62991-63010
work page 2023
-
[58]
Vivo AI Lab. BlueLM Technical Report. https://github.com/ vivo-ai-lab/BlueLM/blob/main/BlueLM_technical_report.pdf
-
[59]
Yi: Open Foundation Models by 01.AI
Young, A., Chen, B., Li, C., Huang, C., Zhang, G., Zhang, G., ... & Dai, Z. (2024). Yi: Open foundation models by 01. ai. arXiv preprint arXiv:2403.04652
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
GLM-130B: An Open Bilingual Pre-trained Model
Zeng, A., Liu, X., Du, Z., Wang, Z., Lai, H., Ding, M., ... & Tang, J. (2022). Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[61]
Song, J., Meng, C., & Ermon, S. (2020). Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[62]
Hwang, J., Hira, M., Chen, C., Zhang, X., Ni, Z., Sun, G., ... & Tao, Y. (2023, December). TorchAudio 2.1: Advancing speech recognition, self- supervised learning, and audio processing components for PyTorch. In 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (pp. 1-9). IEEE. 31
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.