OpenGLT: A Comprehensive Benchmark of Graph Neural Networks for Graph-Level Tasks
Pith reviewed 2026-05-23 06:08 UTC · model grok-4.3
The pith
No single Graph Neural Network architecture dominates both accuracy and efficiency on graph-level tasks across domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through a unified evaluation framework that groups GNNs into node-based, hierarchical pooling-based, subgraph-based, graph learning-based, and self-supervised learning-based categories, the study finds that no single architecture dominates both effectiveness and efficiency universally. Subgraph-based GNNs excel in expressiveness, graph learning-based and SSL-based methods excel in robustness, and node-based and pooling-based models excel in efficiency. Specific graph topological features such as density and centrality can partially guide the selection of suitable GNN architectures for different graph characteristics.
What carries the argument
The OpenGLT unified evaluation framework that applies a five-category taxonomy of GNNs to standardized tests on graph-level tasks across domains and scenarios.
If this is right
- Subgraph-based GNNs should be selected when expressiveness is the priority for a graph-level task.
- Graph learning-based and SSL-based methods should be chosen for datasets that are noisy, imbalanced, or few-shot.
- Node-based and pooling-based models should be used when computational efficiency matters most.
- Graph density and centrality metrics can be measured first to narrow architecture choices before training.
Where Pith is reading between the lines
- Future benchmarks could test whether hybrids that combine subgraph and pooling components reduce the observed trade-offs.
- Domain-specific follow-up studies might show stronger or weaker topology guidance in chemistry graphs versus social networks.
- Practitioners could add a quick topology check step to existing pipelines to improve initial model selection.
Load-bearing premise
The five-category taxonomy covers the main relevant GNN approaches and the 26 datasets plus scenarios are representative enough to support general conclusions about which types to choose.
What would settle it
A GNN that falls outside the five categories but consistently beats all tested models on both accuracy and efficiency metrics across the domains and scenarios, or reversal of the reported performance patterns when the same models are run on additional graphs with different density and centrality values.
Figures

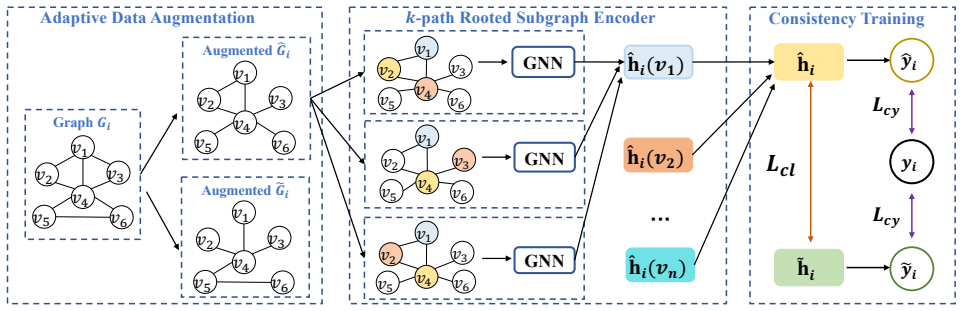


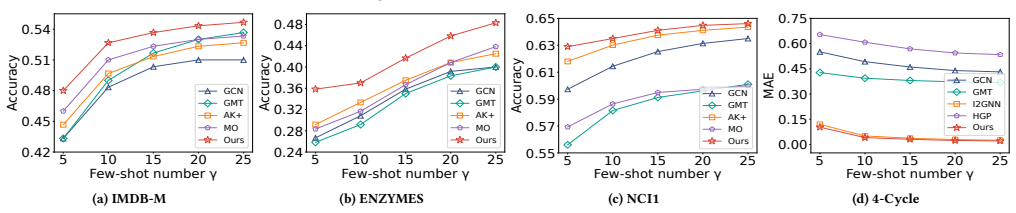
read the original abstract
Graphs are fundamental data structures for modeling complex interactions in domains such as social networks, molecular structures, and biological systems. Graph-level tasks, which involve predicting properties or labels for entire graphs, are crucial for applications like molecular property prediction and subgraph counting. While Graph Neural Networks (GNNs) have shown significant promise for these tasks, their evaluations are often limited by narrow datasets, insufficient architecture coverage, restricted task scope and scenarios, and inconsistent experimental setups, making it difficult to draw reliable conclusions across domains. In this paper, we present a comprehensive experimental study of GNNs on graph-level tasks, systematically categorizing them into five types: node-based, hierarchical pooling-based, subgraph-based, graph learning-based, and self-supervised learning-based GNNs. We propose a unified evaluation framework OpenGLT, which standardizes evaluation across four domains (social networks, biology, chemistry, and motif counting), two task types (classification and regression), and three real-world scenarios (clean, noisy, imbalanced, and few-shot graphs). Extensive experiments on 20 models across 26 classification and regression datasets reveal that: (i) no single architecture dominates both effectiveness and efficiency universally, i.e., subgraph-based GNNs excel in expressiveness, graph learning-based and SSL-based methods in robustness, and node-based and pooling-based models in efficiency; and (ii) specific graph topological features such as density and centrality can partially guide the selection of suitable GNN architectures for different graph characteristics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the OpenGLT benchmark for graph-level tasks, systematically categorizing GNNs into five types (node-based, hierarchical pooling-based, subgraph-based, graph learning-based, and self-supervised learning-based). It evaluates 20 models across 26 classification and regression datasets spanning four domains (social networks, biology, chemistry, motif counting) and three scenarios (clean, noisy, imbalanced, few-shot), claiming that no single architecture dominates effectiveness and efficiency, with subgraph-based models excelling in expressiveness, graph learning/SSL methods in robustness, node/pooling models in efficiency, and topological features (density, centrality) partially guiding architecture selection.
Significance. If the empirical patterns hold under broader coverage, the work provides actionable guidance for GNN selection in graph-level tasks by quantifying trade-offs across effectiveness, efficiency, and robustness, along with topology-based heuristics. The standardized framework and multi-scenario evaluation are strengths that could reduce inconsistent setups in future studies.
major comments (3)
- [Abstract and §3] Abstract and §3 (Taxonomy): The central claim that the five-category taxonomy supports general conclusions on architecture selection (no single model dominates, with category-specific strengths) is load-bearing on the assumption that the taxonomy exhaustively partitions relevant GNN families. However, the manuscript does not explicitly justify exclusion of recent equivariant or higher-order message-passing variants, which could alter the observed expressiveness and robustness rankings if included.
- [§5 and Tables 3/4] §5 (Experiments) and Table 3/4 (Results): The reported performance patterns (subgraph-based excelling in expressiveness, etc.) and the topology-guided selection heuristic rely on 26 datasets and 20 models, but the text provides insufficient detail on hyperparameter search ranges, number of random seeds, or statistical tests (e.g., paired t-tests or Wilcoxon) to establish that differences are significant rather than artifacts of the chosen subset.
- [§4] §4 (Evaluation Framework): The claim that the 26 datasets across four domains and three scenarios are representative enough for general model-selection advice is undermined without an analysis of topological coverage (e.g., distribution of density and centrality values) or explicit checks that the datasets do not under-sample certain regimes, risking that the observed correlations between topology and preferred architecture are dataset-specific.
minor comments (2)
- [§2] §2 (Related Work): Some citations to prior GNN benchmarks appear incomplete; ensure all relevant graph-level surveys (e.g., those covering motif counting) are referenced for context.
- [Figure 2] Figure 2 (Taxonomy diagram): The visual categorization would benefit from explicit arrows or labels indicating which models belong to which of the five types to improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Taxonomy): The central claim that the five-category taxonomy supports general conclusions on architecture selection (no single model dominates, with category-specific strengths) is load-bearing on the assumption that the taxonomy exhaustively partitions relevant GNN families. However, the manuscript does not explicitly justify exclusion of recent equivariant or higher-order message-passing variants, which could alter the observed expressiveness and robustness rankings if included.
Authors: We agree that an explicit justification for the taxonomy boundaries is warranted. The five categories were selected to reflect the dominant architectural paradigms appearing in graph-level literature up to the time of writing; equivariant and higher-order models remain relatively niche for whole-graph tasks and can often be viewed as extensions of node-based or subgraph-based families. In the revision we will add a dedicated paragraph in §3 that (a) states the selection criteria, (b) acknowledges the existence of these variants, and (c) lists their omission as a scope limitation with a forward-looking note. This clarification does not change the reported rankings but improves transparency. revision: yes
-
Referee: [§5 and Tables 3/4] §5 (Experiments) and Table 3/4 (Results): The reported performance patterns (subgraph-based excelling in expressiveness, etc.) and the topology-guided selection heuristic rely on 26 datasets and 20 models, but the text provides insufficient detail on hyperparameter search ranges, number of random seeds, or statistical tests (e.g., paired t-tests or Wilcoxon) to establish that differences are significant rather than artifacts of the chosen subset.
Authors: We accept that additional experimental detail is required. The original runs used a fixed grid search whose ranges are only summarized; we will expand §5 to list the exact hyper-parameter ranges, confirm that five random seeds were used throughout, and insert Wilcoxon signed-rank tests (with p-values) for all pairwise comparisons that underpin the category-level conclusions. These additions will be placed in the main text and supplementary material. revision: yes
-
Referee: [§4] §4 (Evaluation Framework): The claim that the 26 datasets across four domains and three scenarios are representative enough for general model-selection advice is undermined without an analysis of topological coverage (e.g., distribution of density and centrality values) or explicit checks that the datasets do not under-sample certain regimes, risking that the observed correlations between topology and preferred architecture are dataset-specific.
Authors: This observation is fair. While the 26 datasets were chosen for domain diversity, we did not quantify their coverage of topological regimes. In the revised §4 we will add (i) histograms and summary statistics of density, average degree, and betweenness centrality across all datasets, and (ii) a short discussion of potential under-represented regimes together with the corresponding limitation statement. These additions will allow readers to assess the scope of the topology-guided heuristics directly. revision: yes
Circularity Check
Empirical benchmark with no derivation chain or self-referential steps
full rationale
The paper's central claims rest entirely on direct empirical comparisons of 20 models across 26 datasets in four domains and multiple scenarios (clean, noisy, imbalanced, few-shot). No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation chains are invoked to support the taxonomy or performance patterns. The five-category taxonomy is presented as an organizational framework for the benchmark rather than a self-definitional or uniqueness-derived result. All conclusions are falsifiable via the reported experiments and do not reduce to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The five categories (node-based, hierarchical pooling-based, subgraph-based, graph learning-based, and self-supervised learning-based) comprehensively cover GNN approaches for graph-level tasks.
- domain assumption The 26 datasets across social networks, biology, chemistry, and motif counting plus the clean/noisy/imbalanced/few-shot scenarios are representative of real-world graph-level tasks.
Reference graph
Works this paper leans on
-
[1]
IMDb: Ratings, Reviews, and Where to Watch the Best Movies & TV Shows — imdb.com
2024. IMDb: Ratings, Reviews, and Where to Watch the Best Movies & TV Shows — imdb.com. https://www.imdb.com/
work page 2024
-
[2]
2024. Reddit. https://www.reddit.com/?rdt=55615
work page 2024
-
[3]
Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. 2019. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In international conference on machine learning. PMLR, 21–29
work page 2019
-
[4]
Jinheon Baek, Minki Kang, and Sung Ju Hwang. 2021. Accurate Learning of Graph Representations with Graph Multiset Pooling. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net
work page 2021
-
[5]
Beatrice Bevilacqua, Moshe Eliasof, Eli Meirom, Bruno Ribeiro, and Haggai Maron. 2024. Efficient Subgraph GNNs by Learning Effective Selection Policies. In The Twelfth International Conference on Learning Representations
work page 2024
-
[6]
Beatrice Bevilacqua, Fabrizio Frasca, Derek Lim, Balasubramaniam Srini- vasan, Chen Cai, Gopinath Balamurugan, Michael M. Bronstein, and Haggai Maron. 2022. Equivariant Subgraph Aggregation Networks. In International Conference on Learning Representations
work page 2022
-
[7]
Filippo Maria Bianchi, Daniele Grattarola, and Cesare Alippi. 2020. Spectral clustering with graph neural networks for graph pooling. In International conference on machine learning. PMLR, 874–883
work page 2020
-
[8]
Angela Bonifati, M Tamer Özsu, Yuanyuan Tian, Hannes Voigt, Wenyuan Yu, and Wenjie Zhang. 2024. The future of graph analytics. In Companion of the 2024 International Conference on Management of Data. 544–545
work page 2024
-
[9]
Cătălina Cangea, Petar Veličković, Nikola Jovanović, Thomas Kipf, and Pietro Liò. 2018. Towards sparse hierarchical graph classifiers. arXiv preprint arXiv:1811.01287 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Tingyang Chen, Dazhuo Qiu, Yinghui Wu, Arijit Khan, Xiangyu Ke, and Yunjun Gao. 2024. View-based explanations for graph neural networks. Proceedings of the ACM on Management of Data 2, 1 (2024), 1–27
work page 2024
-
[11]
Sara Cohen. 2016. Data management for social networking. In Proceedings of the 35th ACM SIGMOD-SIGACT-SIGAI symposium on principles of database systems. 165–177
work page 2016
-
[12]
Leonardo Cotta, Christopher Morris, and Bruno Ribeiro. 2021. Reconstruc- tion for powerful graph representations. Advances in Neural Information Processing Systems 34 (2021), 1713–1726
work page 2021
-
[13]
Yue Cui, Kai Zheng, Dingshan Cui, Jiandong Xie, Liwei Deng, Feiteng Huang, and Xiaofang Zhou. 2021. METRO: a generic graph neural network framework for multivariate time series forecasting. Proceedings of the VLDB Endowment 15, 2 (2021), 224–236
work page 2021
-
[14]
Gunduz Vehbi Demirci, Aparajita Haldar, and Hakan Ferhatosmanoglu. 2022. Scalable Graph Convolutional Network Training on Distributed-Memory Sys- tems. Proc. VLDB Endow. 16, 4 (2022), 711–724. https://www.vldb.org/pvldb/ vol16/p711-demirci.pdf
work page 2022
-
[15]
Inderjit S Dhillon, Yuqiang Guan, and Brian Kulis. 2007. Weighted graph cuts without eigenvectors a multilevel approach. IEEE transactions on pattern analysis and machine intelligence 29, 11 (2007), 1944–1957
work page 2007
-
[16]
Frederik Diehl. 2019. Edge contraction pooling for graph neural networks. arXiv preprint arXiv:1905.10990 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
Zhihao Ding, Jieming Shi, Shiqi Shen, Xuequn Shang, Jiannong Cao, Zhipeng Wang, and Zhi Gong. 2024. Sgood: Substructure-enhanced graph-level out-of-distribution detection. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. 467–476
work page 2024
-
[18]
Negin Entezari, Saba A Al-Sayouri, Amirali Darvishzadeh, and Evangelos E Papalexakis. 2020. All you need is low (rank) defending against adversarial attacks on graphs. In Proceedings of the 13th international conference on web search and data mining. 169–177
work page 2020
- [19]
-
[20]
Wenfei Fan. 2022. Big graphs: challenges and opportunities. Proceedings of the VLDB Endowment 15, 12 (2022), 3782–3797
work page 2022
-
[21]
Yixiang Fang, Xin Huang, Lu Qin, Ying Zhang, Wenjie Zhang, Reynold Cheng, and Xuemin Lin. 2020. A survey of community search over big graphs. The VLDB Journal 29 (2020), 353–392
work page 2020
-
[22]
Yixiang Fang, Wensheng Luo, and Chenhao Ma. 2022. Densest subgraph dis- covery on large graphs: Applications, challenges, and techniques. Proceedings of the VLDB Endowment 15, 12 (2022), 3766–3769
work page 2022
- [23]
-
[24]
Jiarui Feng, Yixin Chen, Fuhai Li, Anindya Sarkar, and Muhan Zhang. 2022. How powerful are k-hop message passing graph neural networks. Advances in Neural Information Processing Systems 35 (2022), 4776–4790
work page 2022
-
[25]
Hendrik Fichtenberger and Pan Peng. 2022. Approximately Counting Subgraphs in Data Streams. In Proceedings of the 41st ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems. 413–425
work page 2022
-
[26]
Luca Franceschi, Mathias Niepert, Massimiliano Pontil, and Xiao He. 2019. Learning discrete structures for graph neural networks. In International conference on machine learning. PMLR, 1972–1982
work page 2019
-
[27]
Fabrizio Frasca, Beatrice Bevilacqua, Michael Bronstein, and Haggai Maron
-
[28]
Advances in Neural Information Processing Systems 35 (2022), 31376– 31390
Understanding and extending subgraph gnns by rethinking their sym- metries. Advances in Neural Information Processing Systems 35 (2022), 31376– 31390
work page 2022
-
[29]
Hongyang Gao and Shuiwang Ji. 2019. Graph u-nets. In international conference on machine learning. PMLR, 2083–2092
work page 2019
-
[30]
Shihong Gao, Yiming Li, Xin Zhang, Yanyan Shen, Yingxia Shao, and Lei Chen
-
[31]
Proceedings of the ACM on Management of Data 2, 3 (2024), 1–25
SIMPLE: Efficient Temporal Graph Neural Network Training at Scale with Dynamic Data Placement. Proceedings of the ACM on Management of Data 2, 3 (2024), 1–25
work page 2024
-
[32]
Rustam Guliyev, Aparajita Haldar, and Hakan Ferhatosmanoglu. 2024. D3- GNN: Dynamic Distributed Dataflow for Streaming Graph Neural Networks. Proceedings of the VLDB Endowment 17, 11 (2024), 2764–2777
work page 2024
-
[33]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. Advances in neural information processing systems 30 (2017)
work page 2017
-
[34]
Kaveh Hassani and Amir Hosein Khasahmadi. 2020. Contrastive multi-view representation learning on graphs. In International Conference on Machine Learning. PMLR, 4116–4126
work page 2020
-
[35]
Taher Haveliwala. 1999. Efficient computation of PageRank. Technical Report. Stanford
work page 1999
-
[36]
Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. 2022. Graphmae: Self-supervised masked graph autoencoders. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 594–604
work page 2022
-
[37]
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems 33 (2020), 22118–22133
work page 2020
-
[38]
Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, and Yizhou Sun. 2020. GPT-GNN: Generative pre-training of graph neural networks. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 1857–1867
work page 2020
-
[39]
Kezhao Huang, Haitian Jiang, Minjie Wang, Guangxuan Xiao, David Wipf, Xiang Song, Quan Gan, Zengfeng Huang, Jidong Zhai, and Zheng Zhang. 2024. FreshGNN: Reducing Memory Access via Stable Historical Embeddings for Graph Neural Network Training. Proceedings of the VLDB Endowment 17, 6 (2024), 1473–1486
work page 2024
- [40]
- [41]
- [42]
-
[43]
Wei Jin, Tyler Derr, Yiqi Wang, Yao Ma, Zitao Liu, and Jiliang Tang. 2021. Node similarity preserving graph convolutional networks. InProceedings of the 14th ACM international conference on web search and data mining. 148–156
work page 2021
-
[44]
Wei Jin, Yao Ma, Xiaorui Liu, Xianfeng Tang, Suhang Wang, and Jiliang Tang
-
[45]
InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Graph structure learning for robust graph neural networks. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 66–74
-
[46]
Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
Junhyun Lee, Inyeop Lee, and Jaewoo Kang. 2019. Self-attention graph pooling. In International conference on machine learning. pmlr, 3734–3743
work page 2019
-
[48]
Namkyeong Lee, Junseok Lee, and Chanyoung Park. 2022. Augmentation-free self-supervised learning on graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 7372–7380
work page 2022
-
[49]
Haoyang Li and Lei Chen. 2021. Cache-based gnn system for dynamic graphs. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 937–946
work page 2021
-
[50]
Haoyang Li and Lei Chen. 2023. Early: Efficient and reliable graph neural network for dynamic graphs. Proceedings of the ACM on Management of Data 1, 2 (2023), 1–28
work page 2023
-
[51]
Haoyang Li, Shimin Di, Lei Chen, and Xiaofang Zhou. 2024. E2GCL: Efficient and Expressive Contrastive Learning on Graph Neural Networks. In 2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 859–873
work page 2024
-
[52]
Haoyang Li, Shimin Di, Calvin Hong Yi Li, Lei Chen, and Xiaofang Zhou
-
[53]
Fight Fire with Fire: Towards Robust Graph Neural Networks on Dynamic Graphs via Actively Defense.Proceedings of the VLDB Endowment 17, 8 (2024), 13 2050–2063
work page 2024
-
[54]
Haoyang Li, Shimin Di, Zijian Li, Lei Chen, and Jiannong Cao. 2022. Black-box adversarial attack and defense on graph neural networks. In 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 1017–1030
work page 2022
-
[55]
Qiyan Li and Jeffrey Xu Yu. 2024. Fast Local Subgraph Counting. Proceedings of the VLDB Endowment 17, 8 (2024), 1967–1980
work page 2024
-
[56]
Yuanzhi Li and Yang Yuan. 2017. Convergence analysis of two-layer neural networks with relu activation. Advances in neural information processing systems 30 (2017)
work page 2017
-
[57]
Yujia Li, Richard Zemel, Marc Brockschmidt, and Daniel Tarlow. 2016. Gated Graph Sequence Neural Networks. In Proceedings of ICLR’16
work page 2016
-
[58]
Zhiyuan Li, Xun Jian, Yue Wang, and Lei Chen. 2022. CC-GNN: A commu- nity and contraction-based graph neural network. In 2022 IEEE International Conference on Data Mining (ICDM). IEEE, 231–240
work page 2022
-
[59]
Zhiyuan Li, Xun Jian, Yue Wang, Yingxia Shao, and Lei Chen. 2024. DAHA: Accelerating GNN Training with Data and Hardware Aware Execution Planning. Proc. VLDB Endow. 17, 6 (2024), 1364–1376
work page 2024
-
[60]
Zhixun Li, Xin Sun, Yifan Luo, Yanqiao Zhu, Dingshuo Chen, Yingtao Luo, Xiangxin Zhou, Qiang Liu, Shu Wu, Liang Wang, et al. 2024. GSLB: the graph structure learning benchmark. Advances in Neural Information Processing Systems 36 (2024)
work page 2024
-
[61]
Ningyi Liao, Dingheng Mo, Siqiang Luo, Xiang Li, and Pengcheng Yin. 2022. SCARA: scalable graph neural networks with feature-oriented optimization. Proceedings of the VLDB Endowment 15, 11 (2022), 3240–3248
work page 2022
-
[62]
Qingyuan Linghu, Fan Zhang, Xuemin Lin, Wenjie Zhang, and Ying Zhang
-
[63]
In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data
Global reinforcement of social networks: The anchored coreness prob- lem. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2211–2226
work page 2020
-
[64]
Dongsheng Luo, Wei Cheng, Wenchao Yu, Bo Zong, Jingchao Ni, Haifeng Chen, and Xiang Zhang. 2021. Learning to drop: Robust graph neural network via topo- logical denoising. In Proceedings of the 14th ACM international conference on web search and data mining. 779–787
work page 2021
-
[65]
Diego Mesquita, Amauri Souza, and Samuel Kaski. 2020. Rethinking pooling in graph neural networks. Advances in Neural Information Processing Systems 33 (2020), 2220–2231
work page 2020
-
[66]
Christopher Morris, Nils M Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. 2020. Tudataset: A collection of benchmark datasets for learning with graphs. arXiv preprint arXiv:2007.08663 (2020)
work page internal anchor Pith review arXiv 2020
-
[67]
Giannis Nikolentzos, George Dasoulas, and Michalis Vazirgiannis. 2020. K-hop graph neural networks. Neural Networks 130 (2020), 195–205
work page 2020
- [68]
-
[69]
Pál András Papp, Karolis Martinkus, Lukas Faber, and Roger Wattenhofer
-
[70]
Advances in Neural Information Processing Systems 34 (2021), 21997–22009
DropGNN: Random dropouts increase the expressiveness of graph neu- ral networks. Advances in Neural Information Processing Systems 34 (2021), 21997–22009
work page 2021
-
[71]
Pál András Papp and Roger Wattenhofer. 2022. A theoretical comparison of graph neural network extensions. In International Conference on Machine Learning. PMLR, 17323–17345
work page 2022
-
[72]
S Patro. 2015. Normalization: A preprocessing stage. arXiv preprint arXiv:1503.06462 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[73]
Bryan Perozzi et al. 2014. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 701–710
work page 2014
-
[74]
Chendi Qian, Gaurav Rattan, Floris Geerts, Mathias Niepert, and Christopher Morris. 2022. Ordered subgraph aggregation networks. Advances in Neural Information Processing Systems 35 (2022), 21030–21045
work page 2022
-
[75]
Dylan Sandfelder, Priyesh Vijayan, and William L Hamilton. 2021. Ego-gnns: Exploiting ego structures in graph neural networks. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 8523–8527
work page 2021
-
[76]
Tim Schwabe and Maribel Aco. 2024. Cardinality Estimation over Knowledge Graphs with Embeddings and Graph Neural Networks. Proceedings of the ACM on Management of Data 2, 1 (2024), 1–26
work page 2024
-
[77]
Zezhi Shao, Zhao Zhang, Wei Wei, Fei Wang, Yongjun Xu, Xin Cao, and Chris- tian S Jensen. 2022. Decoupled dynamic spatial-temporal graph neural network for traffic forecasting. Proceedings of the VLDB Endowment 15, 11 (2022), 2733–2746
work page 2022
-
[78]
Xing Su, Shan Xue, Fanzhen Liu, Jia Wu, Jian Yang, Chuan Zhou, Wenbin Hu, Cecile Paris, Surya Nepal, Di Jin, et al . 2022. A comprehensive survey on community detection with deep learning. IEEE Transactions on Neural Networks and Learning Systems (2022)
work page 2022
-
[79]
Li Sun, Zhenhao Huang, Zixi Wang, Feiyang Wang, Hao Peng, and S Yu Philip. 2024. Motif-aware riemannian graph neural network with generative- contrastive learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 9044–9052
work page 2024
-
[80]
Qingyun Sun, Jianxin Li, Hao Peng, Jia Wu, Xingcheng Fu, Cheng Ji, and S Yu Philip. 2022. Graph structure learning with variational information bottleneck. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 4165– 4174
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.