How Humans Help LLMs: Assessing and Incentivizing Human Preference Annotators
Pith reviewed 2026-05-23 03:51 UTC · model grok-4.3
The pith
Linear contracts achieve a shortfall of Θ(1/(I n)) to the perfect-observation benchmark and are rate-optimal when annotator effort is continuous.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
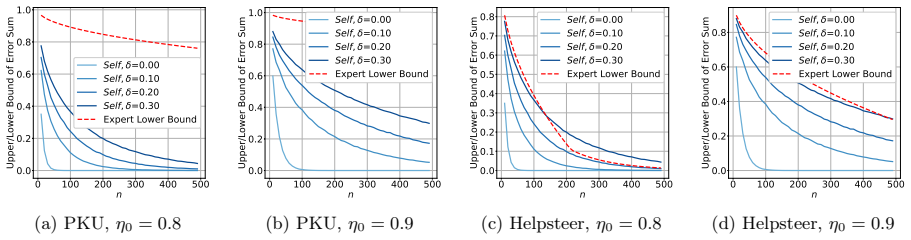
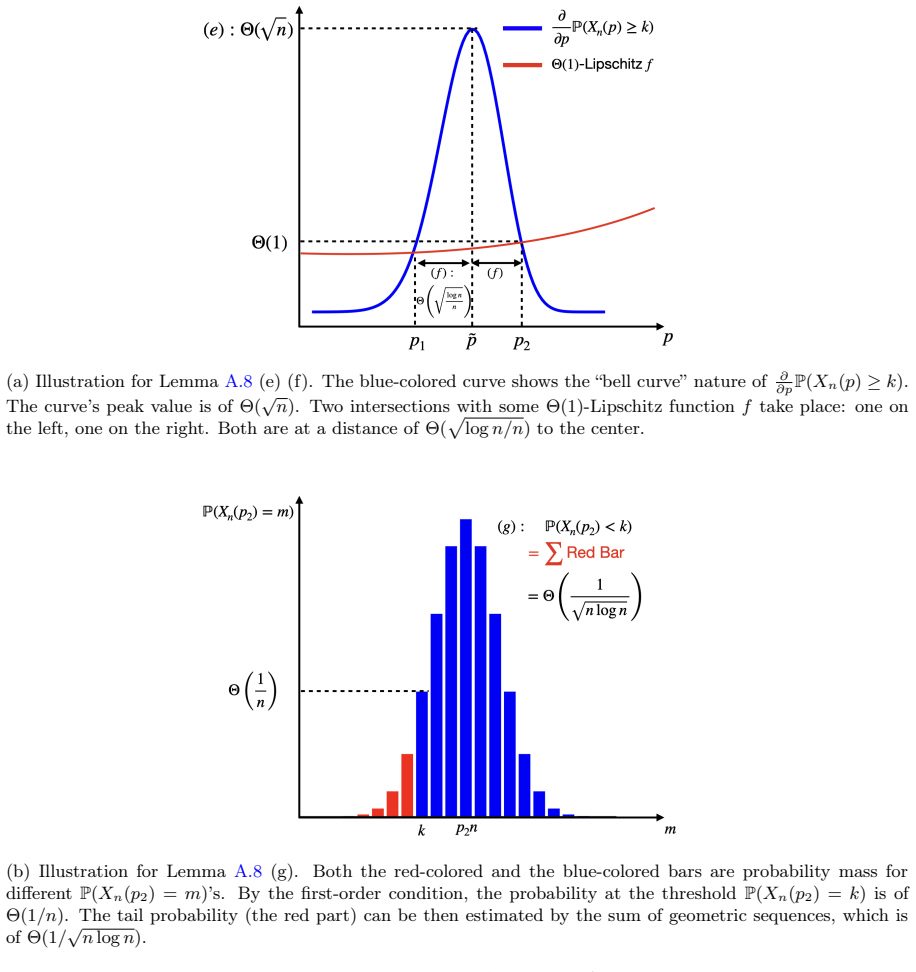
Under continuous action space, the shortfall to the ideal benchmark scales as Θ(1/√(I n log n)) for binary contracts and Θ(1/(I n)) for linear contracts, where I is the Fisher information of the monitoring signal and n is the number of samples; linear contracts are rate-optimal among general contracts. This contrasts with the discrete-action result that binary contracts are optimal and achieve exponential convergence.
What carries the argument
Principal-agent contract model in which the monitoring signal (self-consistency or expert review) supplies Fisher information I independent of contract form, used to bound the performance gap when annotator effort is chosen from a continuous interval.
If this is right
- Self-consistency monitoring requires fewer inspected samples than expert review when annotators are heterogeneous and downstream model performance is noisy.
- Linear contracts reach near-ideal performance with far fewer monitored samples than binary contracts once effort is continuous.
- The optimal contract form depends on whether the underlying effort space is modeled as discrete or continuous.
- A finite but explicit number of monitored samples suffices to make the contract performance arbitrarily close to the first-best benchmark.
Where Pith is reading between the lines
- Contract designers facing continuous effort should default to linear rather than threshold-based payments.
- Self-consistency checks could replace expert review in large-scale preference datasets if the derived sample thresholds are met.
- The same monitoring-plus-contract framework could be applied to other human feedback tasks such as instruction following or safety labeling.
Load-bearing premise
The annotator's effort choice lives in a continuous action space and the monitoring signal supplies Fisher information I that does not depend on the chosen contract.
What would settle it
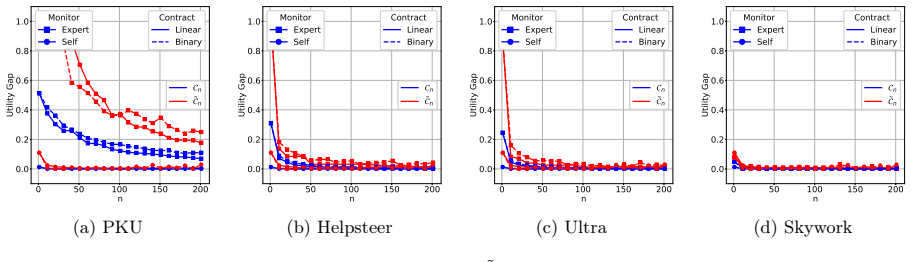
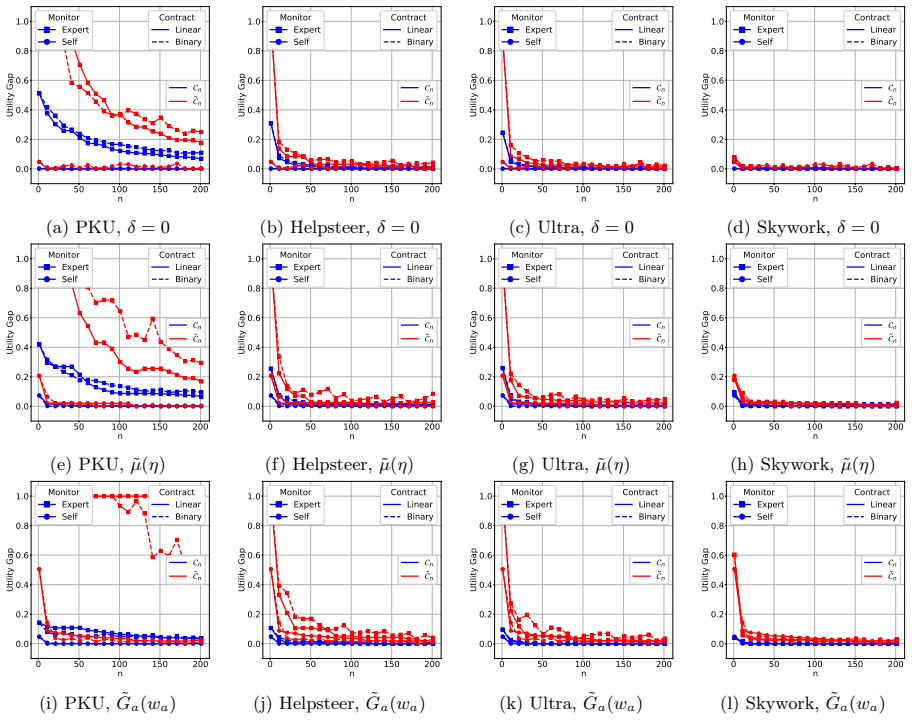
An empirical test that varies the number of monitored samples n while holding the monitoring signal's Fisher information fixed and measures whether the realized performance gap under linear versus binary contracts follows the predicted 1/(I n) versus 1/√(I n log n) scalings.
Figures





read the original abstract
Human-annotated preference data play an important role in aligning large language models (LLMs). In this paper, we study two connected questions: how to monitor the quality of human preference annotators and how to incentivize them to provide high-quality annotations. In current practice, expert-based monitoring is a natural workhorse for quality control, but it performs poorly in preference annotation because annotators are heterogeneous and downstream model performance is an indirect and noisy proxy for annotation quality. We therefore propose a self-consistency monitoring scheme tailored to preference annotation, and analyze the statistical sample complexity of both methods. This practitioner-facing analysis identifies how many inspected samples are needed to reliably assess an annotator and shows when self-consistency monitoring can outperform expert-based monitoring. We then use the resulting monitoring signal as the performance measure in a principal-agent model, which lets us study a second sample-complexity question: how many monitored samples are needed before simple contracts perform close to the ideal benchmark in which annotation quality is perfectly observable. Under this continuous action space, we show that this shortfall scales as $\Theta(1/\sqrt{\mathcal{I} n \log n})$ for binary contracts and $\Theta(1/(\mathcal{I}n))$ for linear contracts, where $\mathcal{I}$ is the Fisher information and $n$ is the number of samples; we further show that the linear contracts are rate-optimal among general contracts. This contrasts with the known result that binary contracts are optimal and of $\exp(-\Theta(n))$ when the action space is discrete \citep{frick2023monitoring}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies quality monitoring for human preference annotators in LLM alignment, proposing a self-consistency scheme and deriving its sample complexity relative to expert review. It then embeds the resulting signal into a principal-agent model with continuous action space to analyze incentive contracts, establishing that the performance shortfall to the first-best benchmark scales as Θ(1/√(ℐ n log n)) for binary contracts and Θ(1/(ℐ n)) for linear contracts, with linear contracts rate-optimal among general contracts. This is contrasted with the exp(-Θ(n)) result known for discrete actions.
Significance. If the derivations hold, the work supplies explicit, quantitative guidance on the number of monitored samples needed for reliable annotator assessment and for contracts to approach ideal performance. The use of Fisher information to parameterize monitoring quality and the clean separation of rates by contract type provide a bridge between statistical learning theory and contract theory that is directly relevant to data pipelines for alignment. The continuous-action analysis and its contrast to the discrete case constitute a clear theoretical contribution.
major comments (1)
- [Abstract and principal-agent model] Abstract and principal-agent model section: the stated rates Θ(1/√(ℐ n log n)) and Θ(1/(ℐ n)) and the rate-optimality of linear contracts are derived under the assumption that the Fisher information ℐ of the monitoring signal (self-consistency or expert review) is fixed and independent of the contract parameters. Because the contract directly shapes the annotator’s effort choice, and effort can alter the distribution of the monitoring signal, ℐ is plausibly endogenous to the contract. This dependence would couple the monitoring and contracting analyses and change both the sample-complexity bounds and the optimality conclusion. The manuscript should either prove independence under its modeling assumptions or extend the analysis to the contract-dependent case.
minor comments (1)
- [Abstract] Notation: ensure that the symbol ℐ is introduced with its precise definition (Fisher information of which random variable) at first use and used consistently thereafter.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the insightful comment on the principal-agent model. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract and principal-agent model] Abstract and principal-agent model section: the stated rates Θ(1/√(ℐ n log n)) and Θ(1/(ℐ n)) and the rate-optimality of linear contracts are derived under the assumption that the Fisher information ℐ of the monitoring signal (self-consistency or expert review) is fixed and independent of the contract parameters. Because the contract directly shapes the annotator’s effort choice, and effort can alter the distribution of the monitoring signal, ℐ is plausibly endogenous to the contract. This dependence would couple the monitoring and contracting analyses and change both the sample-complexity bounds and the optimality conclusion. The manuscript should either prove independence under its modeling assumptions or extend the analysis to the contract-dependent case.
Authors: In the principal-agent model, the Fisher information ℐ is a fixed parameter of the monitoring technology (self-consistency or expert review) and is independent of the contract by construction. The contract influences the agent's effort choice, but the conditional distribution of the monitoring signal given effort is modeled with a noise structure whose Fisher information with respect to the action remains constant and does not depend on the chosen effort level or contract parameters. This is a standard modeling choice that separates the statistical monitoring analysis from the incentive design. We will add an explicit statement of this assumption and its implications in the principal-agent model section. revision: partial
Circularity Check
No circularity: scalings derived from standard Fisher-information concentration under stated assumptions
full rationale
The paper derives the Θ(1/√(I n log n)) and Θ(1/(I n)) shortfall bounds, plus rate-optimality of linear contracts, from the continuous-action principal-agent model using Fisher information I of the monitoring signal and standard concentration arguments. These steps do not reduce to any fitted parameter defined by the paper itself, nor to a self-citation chain; the discrete-action contrast is imported via external citation to frick2023monitoring. The independence of I from contract design is an explicit modeling assumption, not a definitional tautology. No self-definitional, fitted-input, or ansatz-smuggling patterns appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Annotator responses admit a parametric model whose Fisher information I governs the monitoring signal quality.
- standard math Standard large-deviation and information-theoretic bounds apply to the estimation of annotator quality.
Forward citations
Cited by 2 Pith papers
-
Incentivizing High-Quality Human Annotations with Golden Questions
The paper derives a Θ(1/√(n log n)) hypothesis testing rate under strategic annotator behavior and shows that high-certainty, format-similar golden questions better reveal annotation quality than standard checks.
-
Users as Annotators: LLM Preference Learning from Comparison Mode
Introduces a latent user quality model and EM algorithm to infer and filter noisy user-provided pairwise preferences for improved LLM alignment.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter doi edition editor eid howpublished institution journal key month note number organization pages publisher school series title type url volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sent...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in "" FUNCTION format.date year ...
-
[3]
Acemoglu, Daron, Ali Makhdoumi, Azarakhsh Malekian, Asu Ozdaglar. 2022. Too much data: Prices and inefficiencies in data markets. American Economic Journal: Microeconomics\/ 14 (4) 218--256
work page 2022
-
[4]
Adida, Elodie, Fernanda Bravo. 2019. Contracts for healthcare referral services: Coordination via outcome-based penalty contracts. Management Science\/ 65 (3) 1322--1341
work page 2019
-
[5]
Agarwal, Anish, Munther Dahleh, Tuhin Sarkar. 2019. A marketplace for data: An algorithmic solution. Proceedings of the 2019 ACM Conference on Economics and Computation\/ . 701--726
work page 2019
- [6]
-
[7]
Ananthakrishnan, Nivasini, Stephen Bates, Michael Jordan, Nika Haghtalab. 2024 a . Delegating data collection in decentralized machine learning. International Conference on Artificial Intelligence and Statistics\/ . PMLR, 478--486
work page 2024
-
[8]
Ananthakrishnan, Nivasini, Nika Haghtalab, Chara Podimata, Kunhe Yang. 2024 b . Is knowledge power? on the (im) possibility of learning from strategic interactions. The Thirty-eighth Annual Conference on Neural Information Processing Systems\/
work page 2024
-
[9]
Artstein, Ron, Massimo Poesio. 2008. Inter-coder agreement for computational linguistics. Computational linguistics\/ 34 (4) 555--596
work page 2008
-
[10]
Askell, Amanda, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. 2021. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861\/
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Bacon, David F, Yiling Chen, Ian Kash, David C Parkes, Malvika Rao, Manu Sridharan. 2012. Predicting your own effort. Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems-Volume 2 (AAMAS)\/ . 695--702
work page 2012
-
[12]
Bai, Yuntao, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862\/
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Bareket, Dan, Reut Tsarfaty. 2021. Neural modeling for named entities and morphology (nemoˆ2). Transactions of the Association for Computational Linguistics\/ 9 909--928
work page 2021
-
[14]
Barron, Daniel, George Georgiadis, Jeroen Swinkels. 2020. Optimal contracts with a risk-taking agent. Theoretical Economics\/ 15 (2) 715--761
work page 2020
- [15]
-
[16]
Bergemann, Dirk, Alessandro Bonatti. 2019. Markets for information: An introduction. Annual Review of Economics\/ 11 (1) 85--107
work page 2019
-
[17]
Boyd, Stephen. 2004. Convex optimization. Cambridge UP\/
work page 2004
-
[18]
Bradley, Ralph Allan, Milton E Terry. 1952. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika\/ 39 (3/4) 324--345
work page 1952
-
[19]
Bretagnolle, Jean, Catherine Huber. 1978. Estimation des densit \'e s: risque minimax. S \'e minaire de probabilit \'e s de Strasbourg\/ 12 342--363
work page 1978
-
[20]
Cai, Yang, Constantinos Daskalakis, Christos Papadimitriou. 2015. Optimum statistical estimation with strategic data sources. Conference on Learning Theory\/ . PMLR, 280--296
work page 2015
-
[21]
Callison-Burch, Chris, Mark Dredze. 2010. Creating speech and language data with amazon’s mechanical turk. Proceedings of the NAACL HLT 2010 workshop on creating speech and language data with Amazon’s Mechanical Turk\/ . 1--12
work page 2010
-
[22]
Carroll, Gabriel. 2015. Robustness and linear contracts. American Economic Review\/ 105 (2) 536--563
work page 2015
-
[23]
Chen, Junjie, Minming Li, Haifeng Xu. 2022. Selling data to a machine learner: Pricing via costly signaling. International Conference on Machine Learning\/ . PMLR, 3336--3359
work page 2022
- [24]
-
[25]
Collina, Natalie, Varun Gupta, Aaron Roth. 2024. Repeated contracting with multiple non-myopic agents: Policy regret and limited liability. Proceedings of the 25th ACM Conference on Economics and Computation\/ . EC '24, Association for Computing Machinery, New York, NY, USA, 640–668. doi:10.1145/3670865.3673607. ://doi.org/10.1145/3670865.3673607
-
[26]
Corbett, Charles J, Gregory A DeCroix, Albert Y Ha. 2005. Optimal shared-savings contracts in supply chains: Linear contracts and double moral hazard. European journal of operational research\/ 163 (3) 653--667
work page 2005
-
[27]
Corbett, Charles J, Christopher S Tang. 1999. Designing supply contracts: Contract type and information asymmetry. Quantitative models for supply chain management\/ 269--297
work page 1999
-
[28]
Cui, Ganqu, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, Maosong Sun. 2023. Ultrafeedback: Boosting language models with high-quality feedback. arXiv preprint arXiv:2310.01377\/
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Dai, Josef, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang. 2024. Safe RLHF : Safe reinforcement learning from human feedback. The Twelfth International Conference on Learning Representations\/ . ://openreview.net/forum?id=TyFrPOKYXw
work page 2024
-
[30]
Dasgupta, Anirban, Arpita Ghosh. 2013. Crowdsourced judgement elicitation with endogenous proficiency. Proceedings of the 22nd international conference on World Wide Web\/ . 319--330
work page 2013
-
[31]
de Zegher, Joann F, Dan A Iancu, Hau L Lee. 2019. Designing contracts and sourcing channels to create shared value. Manufacturing & Service Operations Management\/ 21 (2) 271--289
work page 2019
-
[32]
Duetting, Paul, Vahab Mirrokni, Renato Paes Leme, Haifeng Xu, Song Zuo. 2024. Mechanism design for large language models. Proceedings of the ACM on Web Conference 2024\/ . 144--155
work page 2024
-
[33]
D \"u tting, Paul, Michal Feldman, Inbal Talgam-Cohen, et al. 2024. Algorithmic contract theory: A survey. Foundations and Trends in Theoretical Computer Science\/ 16 (3-4) 211--412
work page 2024
-
[34]
D \"u tting, Paul, Tim Roughgarden, Inbal Talgam-Cohen. 2019. Simple versus optimal contracts. Proceedings of the 2019 ACM Conference on Economics and Computation\/ . 369--387
work page 2019
-
[35]
Dutting, Paul, Tim Roughgarden, Inbal Talgam-Cohen. 2021. The complexity of contracts. SIAM Journal on Computing\/ 50 (1) 211--254
work page 2021
- [36]
- [37]
-
[38]
Georgiadis, George, Balazs Szentes. 2020. Optimal monitoring design. Econometrica\/ 88 (5) 2075--2107
work page 2020
- [39]
-
[40]
Goldwasser, Shafi, Guy N Rothblum, Jonathan Shafer, Amir Yehudayoff. 2021. Interactive proofs for verifying machine learning. 12th Innovations in Theoretical Computer Science Conference (ITCS 2021)\/ . Schloss-Dagstuhl-Leibniz Zentrum f \"u r Informatik
work page 2021
-
[41]
Grossman, Sanford J, Oliver D Hart. 1992. An analysis of the principal-agent problem. Foundations of Insurance Economics: Readings in Economics and Finance\/ . Springer, 302--340
work page 1992
-
[42]
Guo, Chuan, Geoff Pleiss, Yu Sun, Kilian Q Weinberger. 2017. On calibration of modern neural networks. International conference on machine learning\/ . PMLR, 1321--1330
work page 2017
- [43]
- [44]
-
[45]
Harris, Milton, Artur Raviv. 1979. Optimal incentive contracts with imperfect information. Journal of economic theory\/ 20 (2) 231--259
work page 1979
-
[46]
Herweg, Fabian, Daniel M \"u ller, Philipp Weinschenk. 2010. Binary payment schemes: Moral hazard and loss aversion. American Economic Review\/ 100 (5) 2451--2477
work page 2010
-
[47]
Ho, Chien-Ju, Aleksandrs Slivkins, Jennifer Wortman Vaughan. 2014. Adaptive contract design for crowdsourcing markets: Bandit algorithms for repeated principal-agent problems. Proceedings of the fifteenth ACM conference on Economics and computation\/ . 359--376
work page 2014
-
[48]
Holmstr \"o m, Bengt. 1979. Moral hazard and observability. The Bell journal of economics\/ 74--91
work page 1979
-
[49]
Holmstrom, Bengt, Paul Milgrom. 1987. Aggregation and linearity in the provision of intertemporal incentives. Econometrica: Journal of the Econometric Society\/ 303--328
work page 1987
- [50]
-
[51]
Jain, Nitish, Sameer Hasija, Dana G Popescu. 2013. Optimal contracts for outsourcing of repair and restoration services. Operations Research\/ 61 (6) 1295--1311
work page 2013
-
[52]
Jewitt, Ian. 2006. Information order in decision and agency problems
work page 2006
- [53]
-
[54]
Karlin, Samuel, Herman Rubin. 1956. The theory of decision procedures for distributions with monotone likelihood ratio. The Annals of Mathematical Statistics\/ 272--299
work page 1956
- [55]
-
[56]
Kim, Son Ku. 1995. Efficiency of an information system in an agency model. Econometrica: Journal of the Econometric Society\/ 89--102
work page 1995
-
[57]
Klie, Jan-Christoph, Richard Eckart de Castilho, Iryna Gurevych. 2024 a . Analyzing dataset annotation quality management in the wild. Computational Linguistics\/ 50 (3) 817--866
work page 2024
- [58]
-
[59]
Krippendorff, Klaus. 2004. Reliability in content analysis: Some common misconceptions and recommendations. Human communication research\/ 30 (3) 411--433
work page 2004
-
[60]
Krippendorff, Klaus, et al. 1989. Content analysis. International encyclopedia of communication\/ 1 (1) 403--407
work page 1989
-
[61]
Laffont, Jean-Jacques, David Martimort. 2009. The theory of incentives: the principal-agent model. The theory of incentives\/ . Princeton university press
work page 2009
-
[62]
Lazear, Edward P, Paul Oyer. 2007. Personnel economics. Working Paper 13480, National Bureau of Economic Research. doi:10.3386/w13480. ://www.nber.org/papers/w13480
-
[63]
Le Cam, Lucien. 2012. Asymptotic methods in statistical decision theory\/ . Springer Science & Business Media
work page 2012
- [64]
-
[65]
Liao, JG, Arthur Berg. 2019. Sharpening jensen's inequality. The American Statistician\/
work page 2019
-
[66]
Liu, Chris Yuhao, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, Yahui Zhou. 2024 a . Skywork-reward: Bag of tricks for reward modeling in llms. arXiv preprint arXiv:2410.18451\/
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [67]
-
[68]
Lopomo, Giuseppe, Luca Rigotti, Chris Shannon. 2011. Knightian uncertainty and moral hazard. Journal of Economic Theory\/ 146 (3) 1148--1172
work page 2011
-
[69]
Miller, Nolan, Paul Resnick, Richard Zeckhauser. 2005. Eliciting informative feedback: The peer-prediction method. Management Science\/ 51 (9) 1359--1373
work page 2005
-
[70]
Monarch, Robert Munro. 2021. Human-in-the-Loop Machine Learning: Active learning and annotation for human-centered AI\/ . Simon and Schuster
work page 2021
-
[71]
Moscarini, Giuseppe, Lones Smith. 2002. The law of large demand for information. Econometrica\/ 70 (6) 2351--2366
work page 2002
- [72]
-
[73]
Northcutt, Curtis, Lu Jiang, Isaac Chuang. 2021. Confident learning: Estimating uncertainty in dataset labels. Journal of Artificial Intelligence Research\/ 70 1373--1411
work page 2021
-
[74]
Ouyang, Long, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems\/ 35 27730--27744
work page 2022
-
[75]
Polyanskiy, Yury, Yihong Wu. 2025. Information Theory: From Coding to Learning\/ . Cambridge University Press
work page 2025
-
[76]
Pustejovsky, James, Amber Stubbs. 2012. Natural Language Annotation for Machine Learning: A guide to corpus-building for applications\/ . " O'Reilly Media, Inc."
work page 2012
- [77]
-
[78]
Rafailov, Rafael, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, Chelsea Finn. 2024. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems\/ 36
work page 2024
-
[79]
Saig, Eden, Ohad Einav, Inbal Talgam-Cohen. 2024 a . Incentivizing quality text generation via statistical contracts. The Thirty-eighth Annual Conference on Neural Information Processing Systems\/ . ://openreview.net/forum?id=wZgw4CrxwK
work page 2024
-
[80]
Saig, Eden, Inbal Talgam-Cohen, Nir Rosenfeld. 2024 b . Delegated classification. Advances in Neural Information Processing Systems\/ 36
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.