Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Pith reviewed 2026-05-23 03:11 UTC · model grok-4.3
The pith
Humans detect AI-generated text at 87.6 percent accuracy across 16 datasets in nine languages, far above prior random-guessing estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
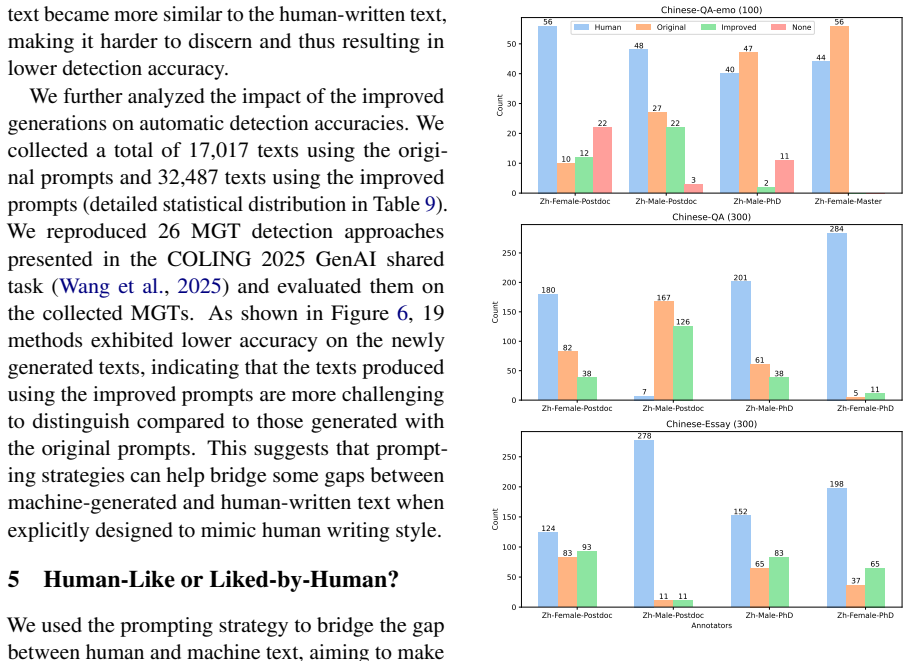
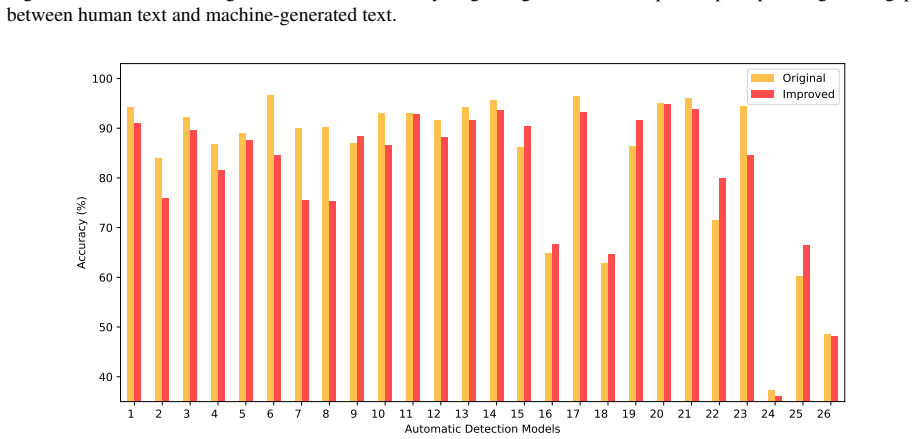
Across 16 datasets covering nine languages and nine domains, 19 annotators reached an average detection accuracy of 87.6 percent when separating machine-generated text from human-written text. This finding directly challenges earlier conclusions that such distinction is highly challenging and often equivalent to random guessing. The study locates the main gaps in concreteness, cultural nuances, and diversity. Prompting that explicitly explains these gaps narrows the performance difference in over 50 percent of cases. Humans show no consistent preference for human-written text when they cannot identify its origin.
What carries the argument
The multilingual, multidomain human annotation experiment that measures both detection accuracy and source preference.
If this is right
- Earlier claims that humans cannot detect AI text better than chance do not generalize across languages and domains.
- Explicit prompts that name concreteness, cultural nuance, and diversity gaps can raise human detection rates in more than half the tested cases.
- Human preference does not automatically favor human-written text when the source remains unidentified.
- The released dataset of human labels and annotator metadata can be used to test further distinctions between the two text types.
Where Pith is reading between the lines
- If the high detection accuracy holds for typical readers, automated detectors may be less critical in some everyday settings.
- The preference result suggests that AI text could gain acceptance in practice even when it remains distinguishable in principle.
- Future work could test whether brief training on the identified gaps raises accuracy further or whether accuracy drops for non-expert readers.
Load-bearing premise
The 19 annotators and the 16 chosen datasets are representative of typical human detection performance and text distributions across the covered languages and domains.
What would settle it
A new study that recruits a substantially larger and more varied group of annotators on comparable datasets and obtains average accuracy near 50 percent would falsify the central accuracy claim.
Figures


read the original abstract
Prior studies have shown that distinguishing text generated by Large Language Models (LLMs) from human-written one is highly challenging for humans, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source. We release our dataset, the human labels, and the annotator metadata at https://github.com/xnlp-lab/HumanEval-MGT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prior findings of humans performing near random guessing in distinguishing LLM-generated from human-written text do not generalize: across 16 datasets spanning 9 languages and 9 domains, 19 annotators achieved 87.6% average detection accuracy. It identifies gaps in concreteness, cultural nuances, and diversity as major discriminators, reports that explicit prompting bridges the gap in over 50% of cases, and finds that humans do not consistently prefer human text when the source cannot be identified. The authors release the dataset, human labels, and annotator metadata.
Significance. If the 87.6% figure and its generalizability hold, the result would materially revise the empirical baseline for human detection of machine-generated text in multilingual settings and would have downstream implications for detection tools and preference studies. The public release of the annotated data and metadata is a clear strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract: the headline 87.6% average detection accuracy is presented without inter-annotator agreement statistics, per-language or per-domain variance, or error analysis; these omissions make it impossible to evaluate whether the result reliably overturns the random-guessing literature.
- [Abstract] Abstract: the claim that the 19 annotators and 16 datasets verify generalizability across languages and domains rests on an unstated assumption of representativeness; no information is given on annotator recruitment criteria, language proficiency screening, or dataset curation procedures that would rule out selection toward high-expertise annotators or easily distinguishable texts.
minor comments (1)
- [Abstract] The abstract states that prompting 'can partially bridge the gaps in over 50% of the cases' but does not define the exact success metric or the baseline prompting condition used for this comparison.
Simulated Author's Rebuttal
We thank the referee for highlighting ways to strengthen the abstract's self-contained presentation of our results. We address each point below and will revise the abstract accordingly while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline 87.6% average detection accuracy is presented without inter-annotator agreement statistics, per-language or per-domain variance, or error analysis; these omissions make it impossible to evaluate whether the result reliably overturns the random-guessing literature.
Authors: The full manuscript reports inter-annotator agreement (Fleiss' kappa = 0.82 overall), per-language accuracies ranging from 78.4% to 94.1% and per-domain from 81.2% to 93.7% (Tables 2-3), plus error analysis attributing errors to concreteness, cultural nuance, and diversity gaps (Section 4.2). We agree the abstract should briefly reference these to allow immediate evaluation and will add one sentence summarizing agreement and variance ranges. revision: yes
-
Referee: [Abstract] Abstract: the claim that the 19 annotators and 16 datasets verify generalizability across languages and domains rests on an unstated assumption of representativeness; no information is given on annotator recruitment criteria, language proficiency screening, or dataset curation procedures that would rule out selection toward high-expertise annotators or easily distinguishable texts.
Authors: The manuscript details annotator recruitment (via Prolific with native-speaker screening and language-proficiency self-reports plus qualification tests) and dataset curation (standard public corpora balanced across languages/domains, with no post-hoc filtering for distinguishability). We acknowledge the abstract omits these and will add a concise clause on recruitment and curation criteria. We note that while our scale improves on prior work, full population-level generalizability remains a limitation discussed in Section 6. revision: yes
Circularity Check
No circularity: purely empirical annotation study
full rationale
The paper reports new human annotations by 19 annotators on 16 datasets, yielding an observed 87.6% average detection accuracy. No equations, fitted parameters, derivations, or self-citation chains are present in the abstract or described methodology. The central claim is a direct empirical measurement rather than any reduction of a prediction to its inputs by construction. This is the normal case of a self-contained data-collection study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The judgments of the 19 annotators accurately reflect human detection capabilities across languages and domains.
Forward citations
Cited by 1 Pith paper
-
LLM Output Detectability and Task Performance Can be Jointly Optimized
PUPPET jointly optimizes LLM outputs for high detectability and task performance via RL rewards from a detector and a task evaluator, outperforming watermarking on tasks while matching detectability.
Reference graph
Works this paper leans on
-
[1]
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Anthropic. 2024. https://api.semanticscholar.org/CorpusID:268232499 The claude 3 model family: Opus, sonnet, haiku
work page 2024
-
[4]
Giovanni Bonisoli, Maria Pia di Buono, Laura Po, and Federica Rollo. 2023. https://doi.org/10.1145/3539618.3591904 Dice: A dataset of italian crime event news . In SIGIR '23: The 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, July 23 - 27, 2023 . ACM
-
[5]
JM Chein, SA Martinez, and AR Barone. 2024. Human intelligence can safeguard against artificial intelligence: individual differences in the discernment of human from ai texts. Scientific Reports, 14(1):25989
work page 2024
-
[6]
Elizabeth Clark, Tal August, Sofia Serrano, Nikita Haduong, Suchin Gururangan, and Noah A. Smith. 2021. https://doi.org/10.18653/v1/2021.acl-long.565 All that`s human' is not gold: Evaluating human evaluation of generated text . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conf...
-
[7]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The Llama 3 Herd of Models . arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Liam Dugan, Daphne Ippolito, Arun Kirubarajan, Sherry Shi, and Chris Callison - Burch. 2023. https://doi.org/10.1609/AAAI.V37I11.26501 Real or fake text?: Investigating human ability to detect boundaries between human-written and machine-generated text . In Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on In...
-
[9]
Omar Einea, Ashraf Elnagar, and Ridhwan Al Debsi . 2019. https://doi.org/https://doi.org/10.1016/j.dib.2019.104076 Sanad: Single-label arabic news articles dataset for automatic text categorization . Data in Brief, 25:104076
-
[10]
Cristina Garbacea, Samuel Carton, Shiyan Yan, and Qiaozhu Mei. 2019. https://doi.org/10.18653/v1/D19-1409 Judge the judges: A large-scale evaluation study of neural language models for online review generation . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural L...
- [11]
-
[12]
Saiful Islam, Kazi Mubasshir, Yuan-Fang Li, Yong-Bin Kang, M
Tahmid Hasan, Abhik Bhattacharjee, Md. Saiful Islam, Kazi Mubasshir, Yuan-Fang Li, Yong-Bin Kang, M. Sohel Rahman, and Rifat Shahriyar. 2021. https://doi.org/10.18653/v1/2021.findings-acl.413 XL -sum: Large-scale multilingual abstractive summarization for 44 languages . In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4...
-
[13]
Jimpei Hitsuwari, Yoshiyuki Ueda, Woojin Yun, and Michio Nomura. 2023. https://doi.org/10.1016/J.CHB.2022.107502 Does human-ai collaboration lead to more creative art? aesthetic evaluation of human-made and ai-generated haiku poetry . Comput. Hum. Behav., 139:107502
-
[14]
Daphne Ippolito, Daniel Duckworth, Chris Callison-Burch, and Douglas Eck. 2020. https://doi.org/10.18653/v1/2020.acl-main.164 Automatic detection of generated text is easiest when humans are fooled . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1808--1822, Online. Association for Computational Linguistics
-
[15]
Miao Li, Eduard Hovy, and Jey Han Lau. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.472 Summarizing multiple documents with conversational structure for meta-review generation . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7089--7112, Singapore. Association for Computational Linguistics
-
[16]
Zaijing Li, Gongwei Chen, Rui Shao, Dongmei Jiang, and Liqiang Nie. 2024. https://doi.org/10.48550/ARXIV.2401.06836 Enhancing the emotional generation capability of large language models via emotional chain-of-thought . CoRR, abs/2401.06836
-
[17]
David M Markowitz, Jeffrey T Hancock, and Jeremy N Bailenson. 2024. Linguistic markers of inherently false ai communication and intentionally false human communication: Evidence from hotel reviews. Journal of Language and Social Psychology, 43(1):63--82
work page 2024
-
[18]
Hannah Mieczkowski, Jeffrey T Hancock, Mor Naaman, Malte Jung, and Jess Hohenstein. 2021. Ai-mediated communication: Language use and interpersonal effects in a referential communication task. Proceedings of the ACM on Human-Computer Interaction, 5(CSCW1):1--14
work page 2021
-
[19]
MOP-LIWU Community and MNBVC Team . 2023. Mnbvc: Massive never-ending bt vast chinese corpus. https://github.com/esbatmop/MNBVC
work page 2023
-
[20]
OpenAI. 2023. https://api.semanticscholar.org/CorpusID:257532815 Gpt-4 technical report . ArXiv, abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [21]
-
[22]
Tatiana Shamardina, Vladislav Mikhailov, Daniil Chernianskii, Alena Fenogenova, Marat Saidov, Anastasiya Valeeva, Tatiana Shavrina, Ivan Smurov, Elena Tutubalina, and Ekaterina Artemova. 2022. Findings of the ruatd shared task 2022 on artificial text detection in russian . arXiv preprint arXiv:2206.01583
-
[23]
Tatiana Shamardina, Marat Saidov, Alena Fenogenova, Aleksandr Tumanov, Alina Zemlyakova, Anna Lebedeva, Ekaterina Gryaznova, Tatiana Shavrina, Vladislav Mikhailov, and Ekaterina Artemova. 2025. Coat: Corpus of artificial texts. Natural Language Processing, 31(1):150--175
work page 2025
-
[24]
Wei Song, Kai Zhang, Ruiji Fu, Lizhen Liu, Ting Liu, and Miaomiao Cheng. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.546 Multi-stage pre-training for automated chinese essay scoring . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6723--6733, Online. Association for Computational Linguistics
-
[25]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Chris van der Lee, Albert Gatt, Emiel van Miltenburg, Sander Wubben, and Emiel Krahmer. 2019. https://doi.org/10.18653/v1/W19-8643 Best practices for the human evaluation of automatically generated text . In Proceedings of the 12th International Conference on Natural Language Generation, pages 355--368, Tokyo, Japan. Association for Computational Linguistics
-
[27]
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Osama Mohanned Afzal, Tarek Mahmoud, Giovanni Puccetti, Thomas Arnold, Alham Fikri Aji, Nizar Habash, Iryna Gurevych, and Preslav Nakov. 2024 a . https://doi.org/10.48550/ARXIV.2402.11175 M4gt-bench: Evaluation benchmark for black-box machine-generated text detection . C...
-
[28]
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Chenxi Whitehouse, Osama Mohammed Afzal, Tarek Mahmoud, Toru Sasaki, Thomas Arnold, Alham Aji, Nizar Habash, Iryna Gurevych, and Preslav Nakov. 2024 b . https://aclanthology.org/2024.eacl-long.83 M4: Multi-generator, multi-domain, and multi-lingual black-box machine-gene...
work page 2024
-
[29]
Yuxia Wang, Artem Shelmanov, Jonibek Mansurov, Akim Tsvigun, Vladislav Mikhailov, Rui Xing, Zhuohan Xie, Jiahui Geng, Giovanni Puccetti, Ekaterina Artemova, Jinyan Su, Minh Ngoc Ta, Mervat Abassy, Kareem Ashraf Elozeiri, Saad El Dine Ahmed El Etter, Maiya Goloburda, Tarek Mahmoud, Raj Vardhan Tomar, Nurkhan Laiyk, Osama Mohammed Afzal, Ryuto Koike, Masahi...
work page 2025
-
[30]
Rustem Yeshpanov, Pavel Efimov, Leonid Boytsov, Ardak Shalkarbayuli, and Pavel Braslavski. 2024. KazQAD : Kazakh open-domain question answering dataset. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 9645--9656
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.