Defending against Backdoor Attacks via Module Switching
Pith reviewed 2026-05-22 20:23 UTC · model grok-4.3
The pith
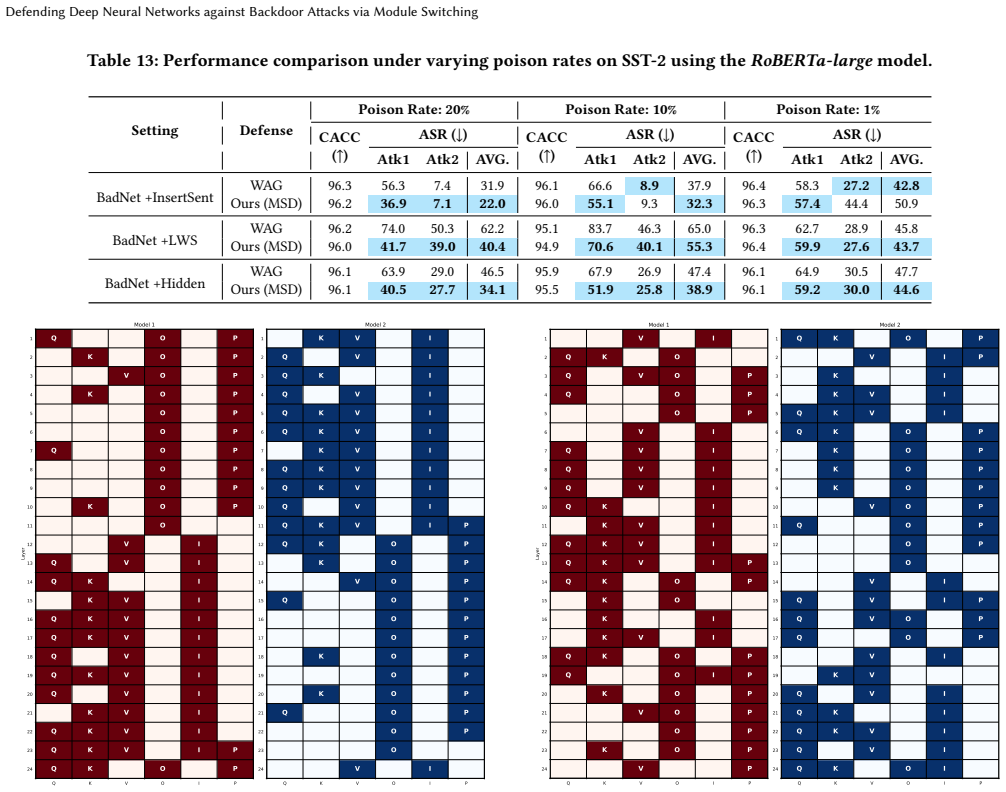
Module switching defense disrupts backdoor triggers more effectively than weight averaging, especially with fewer models and collusive attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By selectively switching modules across multiple models, MSD increases divergence between backdoor behaviors while preserving utility on clean inputs, delivering stronger defense than weight averaging with fewer models and superior robustness against collusive attacks where models share triggers.
What carries the argument
Module-switching defense (MSD), which selectively activates modules from different models according to optimized fusion strategies to disrupt backdoor shortcuts.
If this is right
- MSD produces higher backdoor divergence than weight averaging on two-layer networks while maintaining utility.
- An evolutionary algorithm can identify effective selective fusion strategies for deep Transformer and CNN models.
- Switching strategies remain robust even when multiple models share the same backdoors in collusive attack settings.
- Fewer models suffice for practical defense compared with averaging methods.
Where Pith is reading between the lines
- Defenders with small sets of models could achieve reliable protection by running the evolutionary search once at deployment time.
- The same selective-switching idea might target shared malicious features in other poisoning or trojan scenarios beyond backdoors.
- Evaluating MSD on additional architectures or attack variants would test whether the divergence effect generalizes.
Load-bearing premise
The evolutionary algorithm will reliably discover module combinations that break backdoors without degrading accuracy on clean data.
What would settle it
A test showing that the best MSD strategy found by the evolutionary search reduces backdoor attack success rate no more than weight averaging while also lowering clean accuracy would falsify the claim.
Figures






read the original abstract
Backdoor attacks pose a serious threat to deep neural networks (DNNs), allowing adversaries to implant triggers for hidden behaviors in inference. Defending against such vulnerabilities is especially difficult in the post-training setting, since end-users lack training data or prior knowledge of the attacks. Model merging offers a cost-effective defense; however, latest methods like weight averaging (WAG) provide reasonable protection when multiple homologous models are available, but are less effective with fewer models and place heavy demands on defenders. We propose a module-switching defense (MSD) for disrupting backdoor shortcuts. We first validate its theoretical rationale and empirical effectiveness on two-layer networks, showing its capability of achieving higher backdoor divergence than WAG, and preserving utility. For deep models, we evaluate MSD on Transformer and CNN architectures and design an evolutionary algorithm to optimize fusion strategies with selective mechanisms to identify the most effective combinations. Experiments show that MSD achieves stronger defense with fewer models in practical settings, and even under an underexplored case of collusive attacks among multiple models--where some models share the same backdoors--switching strategies by MSD deliver superior robustness against diverse attacks. Code is available at https://github.com/weijun-l/module-switching-defense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Module Switching Defense (MSD) as a post-training defense against backdoor attacks on DNNs. It validates the approach on two-layer networks with a theoretical argument for higher backdoor divergence than weight averaging (WAG) while preserving clean utility, then extends to deep Transformer and CNN models via an evolutionary algorithm that searches over fusion strategies incorporating selective mechanisms. Experiments claim MSD delivers stronger robustness than baselines with fewer models and remains effective even under collusive attacks where multiple models share backdoors.
Significance. If the central claims hold, MSD would be a practical, low-cost defense that reduces the number of models required compared to prior merging methods and handles an underexplored collusive-attack setting. The public code release supports reproducibility.
major comments (2)
- [Evolutionary algorithm for deep models] Evolutionary algorithm description (deep-model section): the fitness function used to guide the search over fusion strategies is not specified. Under the stated threat model (no training data, no attack knowledge), a fitness based solely on clean accuracy cannot distinguish backdoor-disrupting switches from neutral ones; without an explicit backdoor-sensitive term or other mechanism, the reported robustness gains on Transformers and CNNs rest on an unverified assumption.
- [Theoretical analysis] Theoretical analysis (two-layer networks): the proof of higher backdoor divergence is not connected by any concrete mechanism or reduction to the evolutionary search procedure employed for deep models, so the two-layer result does not directly support the headline claims on complex architectures.
minor comments (2)
- Abstract and experimental sections lack quantitative numbers, error bars, or explicit description of how backdoor success rate was measured, hindering assessment of the empirical claims.
- Notation for selective mechanisms and fusion strategies should be defined more clearly before the evolutionary-algorithm description.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We provide point-by-point responses to the major comments below and will make revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Evolutionary algorithm for deep models] Evolutionary algorithm description (deep-model section): the fitness function used to guide the search over fusion strategies is not specified. Under the stated threat model (no training data, no attack knowledge), a fitness based solely on clean accuracy cannot distinguish backdoor-disrupting switches from neutral ones; without an explicit backdoor-sensitive term or other mechanism, the reported robustness gains on Transformers and CNNs rest on an unverified assumption.
Authors: We acknowledge that the description of the evolutionary algorithm requires additional detail on the fitness function. In the revised manuscript we will explicitly state that the fitness is clean accuracy on a small held-out validation set (consistent with the post-training threat model). The selective mechanisms incorporated in the fusion strategies guide the search toward module combinations that preserve utility while producing the observed backdoor disruption; we will add pseudocode, a description of the selection operators, and further empirical diagnostics showing that the discovered strategies systematically increase backdoor divergence relative to random or weight-averaged baselines. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis (two-layer networks): the proof of higher backdoor divergence is not connected by any concrete mechanism or reduction to the evolutionary search procedure employed for deep models, so the two-layer result does not directly support the headline claims on complex architectures.
Authors: The two-layer analysis establishes that module switching can provably achieve higher backdoor divergence than weight averaging while preserving clean accuracy; this supplies the core intuition motivating the design of selective fusion strategies. We agree there is no formal reduction linking the proof to the evolutionary procedure on deep models. In revision we will clarify this distinction, present the theory as foundational motivation rather than direct support, and emphasize that the headline claims for Transformers and CNNs rest on the empirical results. revision: partial
Circularity Check
No significant circularity; empirical evaluation on held-out attacks is independent of fitted parameters or self-citations
full rationale
The paper's core claims rest on (1) a two-layer theoretical comparison of backdoor divergence between MSD and WAG, presented as direct validation rather than a fitted result, and (2) an evolutionary search over fusion strategies whose effectiveness is measured empirically on held-out attack scenarios and clean data. No equation reduces a claimed prediction to a parameter fit by construction, no load-bearing premise is justified solely by self-citation, and the EA is described as an optimizer rather than a definitional renaming of its own objective. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- evolutionary optimizer hyperparameters
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel module-switching strategy to break such spurious correlations within the model’s propagation path... evolutionary algorithm to optimize fusion strategies with selective mechanisms
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Intra-layer adjacency penalty... Consecutive-layer adjacency penalty... Residual-path adjacency penalty... Balance penalty... Diversity reward
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Abien Fred Agarap. 2018. Deep learning using rectified linear units (relu). arXiv preprint arXiv:1803.08375 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Ansh Arora, Xuanli He, Maximilian Mozes, Srinibas Swain, Mark Dras, and Qiongkai Xu. 2024. Here’s a Free Lunch: Sanitizing Backdoored Models with Model Merge. In Findings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 15059–1507...
-
[3]
Léon Bottou. 2010. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010: 19th International Conference on Computational StatisticsParis France, August 22-27, 2010 Keynote, Invited and Contributed Papers . Springer, 177–186
work page 2010
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gr...
work page 2020
- [5]
-
[6]
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. 2017. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning. CoRR abs/1712.05526 (2017). arXiv:1712.05526 http://arxiv.org/abs/1712.05526
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Jiazhu Dai, Chuanshuai Chen, and Yufeng Li. 2019. A Backdoor Attack Against LSTM-Based Text Classification Systems. IEEE Access 7 (2019), 138872–138878. https://api.semanticscholar.org/CorpusID:168170110
work page 2019
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy...
work page 2019
-
[9]
Jacob Dumford and Walter Scheirer. 2020. Backdooring Convolutional Neural Networks via Targeted Weight Perturbations. In 2020 IEEE International Joint Conference on Biometrics (IJCB) . 1–9. doi:10.1109/IJCB48548.2020.9304875
-
[10]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova Das- Sarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah....
work page 2021
-
[11]
Chong Fu, Xuhong Zhang, Shouling Ji, Ting Wang, Peng Lin, Yanghe Feng, and Jianwei Yin. 2023. FreeEagle: Detecting Complex Neural Trojans in Data- Free Cases. In 32nd USENIX Security Symposium (USENIX Security 23) . USENIX Association, Anaheim, CA, 6399–6416. https://www.usenix.org/conference/ usenixsecurity23/presentation/fu-chong
work page 2023
-
[12]
Matt Gardner, William Merrill, Jesse Dodge, Matthew Peters, Alexis Ross, Sameer Singh, and Noah A. Smith. 2021. Competency Problems: On Finding and Re- moving Artifacts in Language Data. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , Marie-Francine Moens, Xuan- jing Huang, Lucia Specia, and Scott Wen-tau Yih (E...
-
[13]
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. 2017. BadNets: Iden- tifying Vulnerabilities in the Machine Learning Model Supply Chain. CoRR abs/1708.06733 (2017). arXiv:1708.06733 http://arxiv.org/abs/1708.06733
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Resid- ual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2016
-
[15]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2021. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing. arXiv preprint arXiv:2111.09543 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Xuanli He, Qiongkai Xu, Jun Wang, Benjamin Rubinstein, and Trevor Cohn. 2023. Mitigating Backdoor Poisoning Attacks through the Lens of Spurious Correlation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 953–...
-
[17]
Xuanli He, Qiongkai Xu, Jun Wang, Benjamin IP Rubinstein, and Trevor Cohn
-
[18]
Transactions of the Association for Computational Linguistics 12 (2024), 996–1010
SEEP: Training Dynamics Grounds Latent Representation Search for Mitigating Backdoor Poisoning Attacks. Transactions of the Association for Computational Linguistics 12 (2024), 996–1010
work page 2024
-
[19]
Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and An- drew Gordon Wilson. 2018. Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Opti- mization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings , Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[21]
Alex Krizhevsky et al. 2009. Learning multiple layers of features from tiny images. (2009)
work page 2009
-
[22]
Keita Kurita, Paul Michel, and Graham Neubig. 2020. Weight Poisoning Attacks on Pretrained Models. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 2793–2806. doi:10.18653/v1/2020.acl-main.249
-
[23]
Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, Joe Davison, Mario Šaško, Gunjan Chhablani, Bhavitvya Malik, Simon Brandeis, Teven Le Scao, Victor Sanh, Canwen Xu, Nicolas Patry, Angelina McMillan-Major, Philipp Schmid, Sylvain Gugger,...
-
[24]
Yige Li, Xixiang Lyu, Nodens Koren, Lingjuan Lyu, Bo Li, and Xingjun Ma
-
[25]
In Advances in Neural Information Processing Systems , M
Anti-Backdoor Learning: Training Clean Models on Poisoned Data. In Advances in Neural Information Processing Systems , M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (Eds.), Vol. 34. Curran Associates, Inc., 14900–14912. https://proceedings.neurips.cc/paper_files/paper/2021/file/ 7d38b1e9bd793d3f45e0e212a729a93c-Paper.pdf
work page 2021
- [26]
-
[27]
Yiming Li, Mengxi Ya, Yang Bai, Yong Jiang, and Shu-Tao Xia. 2023. BackdoorBox: A Python Toolbox for Backdoor Learning. In ICLR Workshop
work page 2023
- [28]
-
[29]
Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. 2018. Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks. CoRR abs/1805.12185 (2018). arXiv:1805.12185 http://arxiv.org/abs/1805.12185
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Yingqi Liu, Wen-Chuan Lee, Guanhong Tao, Shiqing Ma, Yousra Aafer, and Xiangyu Zhang. 2019. Abs: Scanning neural networks for back-doors by artificial brain stimulation. InProceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security. 1265–1282
work page 2019
-
[31]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. CoRR abs/1907.11692 (2019). arXiv:1907.11692 http://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
Michael S Matena and Colin A Raffel. 2022. Merging Models with Fisher-Weighted Averaging. In Advances in Neural Information Pro- cessing Systems , S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 17703– 17716. https://proceedings.neurips.cc/paper_files/paper/2022/file/ 70c26937fbf3d4600b69a129031b...
work page 2022
-
[33]
Geoffrey F Miller, Peter M Todd, and Shailesh U Hegde. 1989. Designing Neural Networks Using Genetic Algorithms.. In ICGA, Vol. 89. 379–384
work page 1989
- [34]
-
[35]
Fanchao Qi, Yangyi Chen, Mukai Li, Yuan Yao, Zhiyuan Liu, and Maosong Sun
-
[36]
ONION: A Simple and Effective Defense Against Textual Backdoor Attacks. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.). Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 9558–9566. doi:10.18653/v1...
-
[37]
Fanchao Qi, Mukai Li, Yangyi Chen, Zhengyan Zhang, Zhiyuan Liu, Yasheng Wang, and Maosong Sun. 2021. Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long P...
-
[38]
Fanchao Qi, Mukai Li, Yangyi Chen, Zhengyan Zhang, Zhiyuan Liu, Yasheng Wang, and Maosong Sun. 2021. Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger. In Annual Meeting of the Association for Computational Linguistics. https://api.semanticscholar.org/CorpusID:235196099
work page 2021
-
[39]
Fanchao Qi, Yuan Yao, Sophia Xu, Zhiyuan Liu, and Maosong Sun. 2021. Turn the Combination Lock: Learnable Textual Backdoor Attacks via Word Substitution. In Annual Meeting of the Association for Computational Linguistics . https://api. semanticscholar.org/CorpusID:235417102
work page 2021
-
[40]
Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V. Le. 2019. Regularized Evolution for Image Classifier Architecture Search. Proceedings of the AAAI Conference on Artificial Intelligence 33, 01 (Jul. 2019), 4780–4789. doi:10.1609/aaai. v33i01.33014780
-
[41]
David So, Quoc Le, and Chen Liang. 2019. The Evolved Transformer. In Pro- ceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdi- nov (Eds.). PMLR, 5877–5886. https://proceedings.mlr.press/v97/so19a.html
work page 2019
-
[42]
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Con- ference on Empirical Methods in Natural Language Processing , David Yarowsky, Timothy Baldwin, Anna Korhonen, Karen Livescu, a...
work page 2013
-
[43]
Yanghao Su, Jie Zhang, Ting Xu, Tianwei Zhang, Weiming Zhang, and Nenghai Yu. 2024. Model X-ray: Detecting Backdoored Models via Decision Boundary. In Proceedings of the 32nd ACM International Conference on Multimedia . 10296– 10305
work page 2024
- [44]
-
[45]
TorchVision maintainers and contributors. 2016. TorchVision: PyTorch’s Com- puter Vision library. https://github.com/pytorch/vision. GitHub repository
work page 2016
-
[46]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems , I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc. https://pr...
work page 2017
-
[47]
Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y. Zhao. 2019. Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks. In 2019 IEEE Symposium on Security and Privacy (SP). 707–723. doi:10.1109/SP.2019.00031
-
[48]
Hang Wang, Zhen Xiang, David J Miller, and George Kesidis. 2024. Mm-bd: Post-training detection of backdoor attacks with arbitrary backdoor pattern types using a maximum margin statistic. In 2024 IEEE Symposium on Security and Privacy (SP). IEEE, 1994–2012
work page 2024
-
[49]
Ren Wang, Gaoyuan Zhang, Sijia Liu, Pin-Yu Chen, Jinjun Xiong, and Meng Wang. 2020. Practical detection of trojan neural networks: Data-limited and data- free cases. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIII 16 . Springer, 222–238
work page 2020
- [50]
-
[51]
Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies, Volume 1 (Long Papers) (New Orleans, Louisiana). Association for Computa...
work page 2018
- [52]
-
[53]
Dongxian Wu and Yisen Wang. 2021. Adversarial Neuron Pruning Purifies Backdoored Deep Models. In Advances in Neural Information Processing Systems , M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (Eds.), Vol. 34. Curran Associates, Inc., 16913–16925. https://proceedings.neurips. cc/paper_files/paper/2021/file/8cbe9ce23f42628c98...
work page 2021
-
[54]
Tong Xu, Yiming Li, Yong Jiang, and Shu-Tao Xia. 2023. Batt: Backdoor at- tack with transformation-based triggers. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 1–5
work page 2023
-
[55]
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal
-
[56]
In Ad- vances in Neural Information Processing Systems , A
TIES-Merging: Resolving Interference When Merging Models. In Ad- vances in Neural Information Processing Systems , A. Oh, T. Naumann, A. Glober- son, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 7093–7115. https://proceedings.neurips.cc/paper_files/paper/2023/file/ 1644c9af28ab7916874f6fd6228a9bcf-Paper-Conference.pdf
work page 2023
- [57]
-
[58]
Wenqian Ye, Guangtao Zheng, Xu Cao, Yunsheng Ma, and Aidong Zhang
-
[59]
Will You Find These Shortcuts?
Spurious correlations in machine learning: A survey. arXiv preprint arXiv:2402.12715 (2024)
-
[60]
Biao Yi, Sishuo Chen, Yiming Li, Tong Li, Baolei Zhang, and Zheli Liu. 2024. BadActs: A Universal Backdoor Defense in the Activation Space. In Findings of the Association for Computational Linguistics: ACL 2024 , Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 5339–5352. doi:10.18653/v1/2...
-
[61]
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. 2024. Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch. In Forty-first International Conference on Machine Learning . https: //openreview.net/forum?id=fq0NaiU8Ex
work page 2024
-
[62]
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. 2019. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF international conference on computer vision. 6023–6032
work page 2019
-
[63]
Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level Convolutional Networks for Text Classification. In Advances in Neural Information Processing Systems, C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett (Eds.), Vol. 28. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/ 2015/file/250cf8b51c773f3f8dc8b4be867a9a0...
work page 2015
-
[64]
Zhiyuan Zhang, Lingjuan Lyu, Xingjun Ma, Chenguang Wang, and Xu Sun. 2022. Fine-mixing: Mitigating Backdoors in Fine-tuned Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2022 , Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Computational Linguis- tics, Abu Dhabi, United Arab Emirates, 355–372....
-
[65]
Xingyi Zhao, Depeng Xu, and Shuhan Yuan. 2024. Defense against Backdoor Attack on Pre-trained Language Models via Head Pruning and Attention Normal- ization. In Proceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235) , Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuri...
work page 2024
-
[66]
Xun Zhou, A. K. Qin, Maoguo Gong, and Kay Chen Tan. 2021. A Survey on Evolutionary Construction of Deep Neural Networks. IEEE Transactions on Evolutionary Computation 25, 5 (2021), 894–912. doi:10.1109/TEVC.2021.3079985 10 Defending Deep Neural Networks against Backdoor Attacks via Module Switching A Results of a Two-Layer Network with Varying Activations...
-
[67]
Intra-layer Adjacency ( 𝐹intra). 𝐹intra (𝑆) = − |𝑆 |∑︁ 𝑙=1 IntraViolation(𝑆 [𝑙]) (6) Here, IntraViolation quantifies the number of adjacent module pairs from the same source model within layer 𝑆 [𝑙]
-
[68]
Consecutive-layer Adjacency ( 𝐹consec). 𝐹consec (𝑆) = − |𝑆 | −1∑︁ 𝑙=1 ConsecViolation(𝑆 [𝑙], 𝑆[𝑙 + 1]) (7) The function ConsecViolation counts module pairs from the same source model that are directly connected between consecutive layers
-
[69]
Residual Connections ( 𝐹residual). 𝐹residual(𝑆) = − |𝑆 |∑︁ 𝑙=1 |𝑆 |∑︁ 𝑘=𝑙+1 ResidualViolation(𝑆 [𝑙], 𝑆[𝑘]) × ( 0.5)𝑘 −𝑙 (8) This term evaluates residual connections between layers 𝑆 [𝑙] and 𝑆 [𝑘], with ResidualViolation weighted by (0.5)𝑘 −𝑙 to reduce the impact of long-range connections
-
[70]
Module Balance ( 𝐹balance). 𝐹balance (𝑆) = − 𝑛models∑︁ 𝑖=1 ∑︁ 𝑚∈ M |count𝑖,𝑚 − countideal| (9) where count𝑖,𝑚 is the count of module type 𝑚 from model 𝑖, M = {𝑄, 𝐾, 𝑉 , 𝑂, 𝐼, 𝑃} is the set of module types, and countideal = |𝑆 |/𝑛models represents the ideal count per module type per model
-
[71]
Layer Diversity ( 𝐹diversity). 𝐹diversity(𝑆) = |unique(𝑆)| (10) where unique(𝑆) is the set of unique layer compositions in strategy 𝑆. 12 Defending Deep Neural Networks against Backdoor Attacks via Module Switching C Additional Experiment Setup C.1 Dataset Statistics We evaluate our method on four datasets. The statistical information of each dataset and ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.