RA-RRG: Multimodal Retrieval-Augmented Radiology Report Generation with Key Phrase Extraction
Pith reviewed 2026-05-22 21:05 UTC · model grok-4.3
The pith
Retrieval of key phrases from similar X-ray reports lets LLMs generate accurate radiology reports with fewer hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RA-RRG extracts key phrases from training reports with LLMs, retrieves image-relevant phrases via multimodal similarity, and conditions an LLM on these phrases to produce the radiology report. This suppresses hallucinations while achieving state-of-the-art CheXbert metrics and competitive RadGraph F1 scores on MIMIC-CXR and IU X-ray, and supports multi-view aggregation.
What carries the argument
Multimodal retrieval of LLM-extracted key phrases from a report database, used to condition the report-generating LLM.
If this is right
- Achieves state-of-the-art results on CheXbert metrics compared with multimodal LLMs.
- Maintains competitive RadGraph F1 scores on standard benchmarks.
- Naturally extends to multi-view report generation by aggregating phrases across images.
- Reduces hallucinations and computational cost relative to full multimodal training.
Where Pith is reading between the lines
- The phrase-retrieval step could let smaller or cheaper LLMs reach usable accuracy in other medical imaging tasks if similar phrase databases are constructed.
- Retrieved phrases might serve as explicit evidence that clinicians can inspect alongside the generated report.
- The method could be tested on longitudinal patient data to check whether repeated retrievals improve consistency across visits.
Load-bearing premise
The key phrases extracted by LLMs from training reports capture all clinically essential information and image-based retrieval finds phrases relevant enough to guide accurate report generation without omissions or new errors.
What would settle it
On a new test set, reports generated after conditioning on retrieved phrases show higher rates of clinical omissions or factual errors than reports produced by direct multimodal LLMs.
Figures



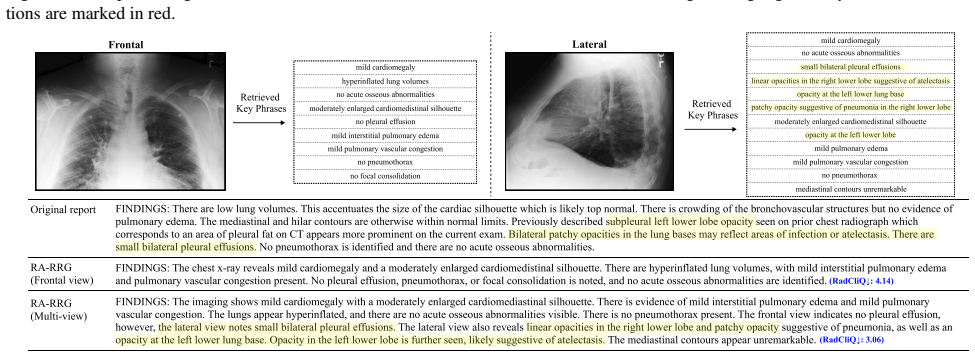
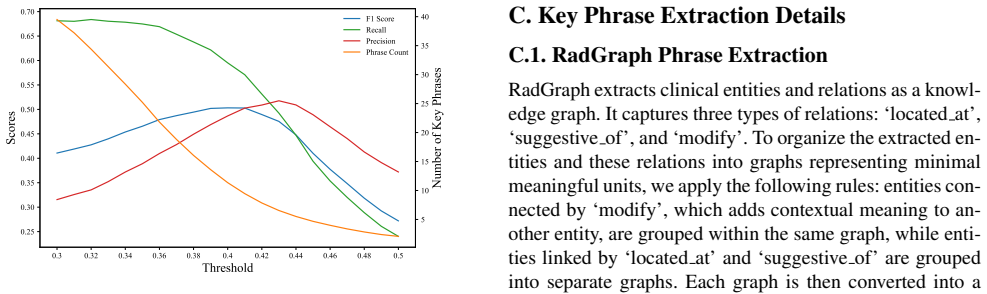








read the original abstract
Automated radiology report generation (RRG) holds potential to reduce the workload of radiologists, and recent advances in multimodal large language models (MLLMs) have enabled multimodal chest X-ray (CXR) report generation. However, existing MLLMs are computationally expensive, require large-scale training data, and may produce hallucinated content, limiting their practical deployment. To address these limitations, we propose RA-RRG, a retrieval-augmented RRG framework that combines multimodal retrieval with large language models (LLMs) to generate radiology reports while reducing hallucinations and computational demands. RA-RRG uses LLMs to extract clinically essential key phrases from radiology reports and retrieves relevant phrases given an input image. By conditioning LLMs on the retrieved phrases, RA-RRG effectively suppresses hallucinations while maintaining strong report generation performance. Experiments on the MIMIC-CXR and IU X-ray datasets show state-of-the-art results on CheXbert metrics and competitive RadGraph F1 scores compared to MLLMs. Furthermore, RA-RRG naturally generalizes to multi-view RRG by aggregating phrases retrieved from multiple images, highlighting its broad applicability to real-world clinical scenarios. Code is available at https://github.com/deepnoid-ai/RA-RRG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RA-RRG, a retrieval-augmented framework for radiology report generation. LLMs extract key phrases from training reports; given an input CXR image, relevant phrases are retrieved and used to condition an LLM for report generation. The approach is claimed to suppress hallucinations, lower computational cost relative to MLLMs, achieve SOTA CheXbert metrics and competitive RadGraph F1 on MIMIC-CXR and IU X-ray, and naturally extend to multi-view inputs. Code is released.
Significance. If the central claim is substantiated, RA-RRG would offer a lighter-weight, retrieval-based alternative to full multimodal LLMs for factual radiology report generation. The public code release is a positive contribution for reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that 'By conditioning LLMs on the retrieved phrases, RA-RRG effectively suppresses hallucinations' is not directly tested. Reported results are aggregate CheXbert and RadGraph scores; no ablation against a non-retrieval LLM baseline, no hallucination-specific metric (e.g., entity-level error analysis), and no quantification of omissions or new errors introduced by imperfect retrieval are provided.
- [Methods] Methods (retrieval and phrase extraction subsections): No description is given of the multimodal retrieval model architecture, the exact LLM prompt and selection criteria used to extract key phrases from training reports, or any controls for data leakage between retrieved training phrases and test images. These omissions are load-bearing for assessing whether the reported metrics reflect genuine hallucination reduction or retrieval artifacts.
minor comments (2)
- [Experiments] Experiments: Specify the exact train/validation/test splits, any additional preprocessing, and the precise CheXbert and RadGraph evaluation protocols to allow direct comparison with prior work.
- [Figure 1] Figure 1 or equivalent diagram: Clarify the flow from image to phrase retrieval to LLM conditioning with explicit notation for the retrieval similarity function.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation of our results and methods.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'By conditioning LLMs on the retrieved phrases, RA-RRG effectively suppresses hallucinations' is not directly tested. Reported results are aggregate CheXbert and RadGraph scores; no ablation against a non-retrieval LLM baseline, no hallucination-specific metric (e.g., entity-level error analysis), and no quantification of omissions or new errors introduced by imperfect retrieval are provided.
Authors: We agree that direct evidence for hallucination suppression would strengthen the central claim. The reported CheXbert and RadGraph improvements provide indirect support via standard factual metrics in the field, but we acknowledge the value of explicit testing. In the revised manuscript we have added an ablation comparing RA-RRG against a non-retrieval LLM baseline that uses the identical underlying model and prompt structure. We have also included a qualitative entity-level error analysis in the results section that illustrates reduced hallucinations, together with a brief discussion of retrieval-induced omissions in the limitations and supplementary material. revision: yes
-
Referee: [Methods] Methods (retrieval and phrase extraction subsections): No description is given of the multimodal retrieval model architecture, the exact LLM prompt and selection criteria used to extract key phrases from training reports, or any controls for data leakage between retrieved training phrases and test images. These omissions are load-bearing for assessing whether the reported metrics reflect genuine hallucination reduction or retrieval artifacts.
Authors: We thank the referee for highlighting these omissions. In the revised manuscript we have substantially expanded the retrieval subsection to describe the multimodal retrieval architecture, which uses a frozen vision-language encoder to compute cosine similarity between the input CXR embedding and phrase embeddings. The precise LLM prompt template and selection criteria (clinical relevance, frequency, and length constraints) for key-phrase extraction are now provided verbatim in a new appendix. We have also added an explicit statement that the retrieval index is constructed exclusively from the training split, with no test or validation images or reports used in index construction or retrieval, thereby eliminating data leakage. revision: yes
Circularity Check
No circularity: empirical framework evaluated on public benchmarks
full rationale
The paper describes an empirical retrieval-augmented pipeline that extracts key phrases via LLM, performs image-based retrieval, and conditions report generation on the retrieved phrases. No equations, fitted parameters, or derivations are presented that reduce reported metrics (CheXbert, RadGraph F1) to quantities defined by the authors' own inputs. Evaluation uses standard public datasets (MIMIC-CXR, IU X-ray) and released code; results are aggregate generation metrics with no self-definitional or self-citation load-bearing steps. The central claim rests on external benchmarks rather than internal construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can reliably extract clinically essential key phrases from radiology reports
- domain assumption Image-feature similarity retrieves phrases that are relevant for guiding accurate report generation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RA-RRG uses LLMs to extract clinically essential key phrases from radiology reports and retrieves relevant phrases given an input image. By conditioning LLMs on the retrieved phrases, RA-RRG effectively suppresses hallucinations
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce several training techniques... in-batch contrastive loss to align text and semantic embeddings
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maira-2: Grounded radiology report gener- ation.arXiv preprint arXiv:2406.04449, 2024
Shruthi Bannur, Kenza Bouzid, Daniel C Castro, Anton Schwaighofer, Sam Bond-Taylor, Maximilian Ilse, Fernando P´erez-Garc´ıa, Valentina Salvatelli, Harshita Sharma, Felix Meissen, et al. Maira-2: Grounded radiology report gener- ation.arXiv preprint arXiv:2406.04449, 2024. 2, 4, 5, 6, 7, 8
-
[2]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InEuropean confer- ence on computer vision, pages 213–229. Springer, 2020. 3
work page 2020
-
[3]
Pierre Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven QH Truong, Chu The Chuong, and Curtis P Langlotz. Chexpert plus: Hundreds of thousands of aligned radiology texts, im- ages and patients.arXiv preprint arXiv:2405.19538, 2024. 5
-
[4]
Lungren, Akshay Chaudhari, Ser- ena Yeung-Levy, Curtis P
Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Yanbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Yujia Xie, Mahmoud Khademi, Ziyi Yang, Hany Awadalla, Julia Gong, Houdong Hu, Jianwei Yang, Chunyuan Li, Jian- feng Gao, Yu Gu, Cliff Wong, Mu Wei, Tristan Naumann, Muhao Chen, Matthew P. Lungren, Akshay Chaudhari, Ser- ena Yeung-Levy, Curtis P. Langl...
- [5]
-
[6]
Generating radiology reports via memory-driven trans- former
Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan. Generating radiology reports via memory-driven trans- former. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1439–1449, Online, 2020. Association for Computational Linguistics. 2, 3
work page 2020
-
[7]
Tsai, Andrew Johnston, Cameron Olsen, Tanishq Mathew Abraham, Sergios Gatidis, Akshay S
Zhihong Chen, Maya Varma, Jean-Benoit Delbrouck, Mag- dalini Paschali, Louis Blankemeier, Dave Van Veen, Jeya Maria Jose Valanarasu, Alaa Youssef, Joseph Paul Cohen, Eduardo Pontes Reis, Emily B. Tsai, Andrew Johnston, Cameron Olsen, Tanishq Mathew Abraham, Sergios Gatidis, Akshay S. Chaudhari, and Curtis Langlotz. Chexagent: Towards a foundation model fo...
-
[8]
Dina Demner-Fushman, Marc D Kohli, Marc B Rosen- man, Steven E Shooshan, Louis Rodriguez, Sameer Antani, George R Thoma, and Clement J McDonald. Preparing a collection of radiology examinations for distribution and re- trieval.Journal of the American Medical Informatics Asso- ciation, 23(2):304–310, 2016. 5, 2
work page 2016
-
[9]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Retrieval-based chest x-ray report generation using a pre-trained contrastive language-image model
Mark Endo, Rayan Krishnan, Viswesh Krishna, Andrew Y Ng, and Pranav Rajpurkar. Retrieval-based chest x-ray report generation using a pre-trained contrastive language-image model. InMachine Learning for Health, pages 209–219. PMLR, 2021. 1, 2
work page 2021
-
[11]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
HippoRAG: Neurobiologically in- spired long-term memory for large language models
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. HippoRAG: Neurobiologically in- spired long-term memory for large language models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 2
work page 2024
-
[13]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A sur- vey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.arXiv preprint arXiv:2311.05232, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Hyland, Shruthi Bannur, Kenza Bouzid, Daniel C
Stephanie L. Hyland, Shruthi Bannur, Kenza Bouzid, Daniel C. Castro, Mercy Ranjit, Anton Schwaighofer, Fer- nando P ´erez-Garc´ıa, Valentina Salvatelli, Shaury Srivas- tav, Anja Thieme, Noel Codella, Matthew P. Lungren, Maria Teodora Wetscherek, Ozan Oktay, and Javier Alvarez- Valle. Maira-1: A specialised large multimodal model for ra- diology report gen...
-
[16]
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Sil- viana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, Jayne Seekins, David A. Mong, Safwan S. Halabi, Jesse K. Sandberg, Ricky Jones, David B. Larson, Curtis P. Langlotz, Bhavik N. Patel, Matthew P. Lungren, and Andrew Y . Ng. Chexpert: a large chest radio...
work page 2019
-
[17]
Neel Jain, Ping yeh Chiang, Yuxin Wen, John Kirchenbauer, Hong-Min Chu, Gowthami Somepalli, Brian R. Bartold- son, Bhavya Kailkhura, Avi Schwarzschild, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. NEF- Tune: Noisy embeddings improve instruction finetuning. In The Twelfth International Conference on Learning Represen- tations, 2024. 3
work page 2024
-
[18]
Radgraph: Extracting clinical entities and relations from ra- diology reports
Saahil Jain, Ashwin Agrawal, Adriel Saporta, Steven Truong, Du Nguyen Duong Nguyen Duong, Tan Bui, Pierre Chambon, Yuhao Zhang, Matthew Lungren, Andrew Ng, Curtis Langlotz, Pranav Rajpurkar, and Pranav Rajpurkar. Radgraph: Extracting clinical entities and relations from ra- diology reports. InProceedings of the Neural Informa- tion Processing Systems Trac...
-
[19]
From clip to dino: Visual encoders shout in multi-modal large language models,
Dongsheng Jiang, Yuchen Liu, Songlin Liu, Jin’e Zhao, Hao Zhang, Zhen Gao, Xiaopeng Zhang, Jin Li, and Hongkai Xiong. From clip to dino: Visual encoders shout in multi-modal large language models.arXiv preprint arXiv:2310.08825, 2023. 3
-
[20]
Promptmrg: Diagnosis-driven prompts for medical report generation
Haibo Jin, Haoxuan Che, Yi Lin, and Hao Chen. Promptmrg: Diagnosis-driven prompts for medical report generation. Proceedings of the AAAI Conference on Artificial Intelli- gence, 38(3):2607–2615, 2024. 5, 6, 2, 3
work page 2024
-
[21]
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019. 4
work page 2019
-
[22]
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs
Alistair EW Johnson, Tom J Pollard, Nathaniel R Green- baum, Matthew P Lungren, Chih-ying Deng, Yifan Peng, Zhiyong Lu, Roger G Mark, Seth J Berkowitz, and Steven Horng. Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs.arXiv preprint arXiv:1901.07042,
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[23]
Transq: Transformer-based semantic query for med- ical report generation
Ming Kong, Zhengxing Huang, Kun Kuang, Qiang Zhu, and Fei Wu. Transq: Transformer-based semantic query for med- ical report generation. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2022, pages 610– 620, Cham, 2022. Springer Nature Switzerland. 1, 2, 3, 5, 6
work page 2022
-
[24]
The hungarian method for the assignment problem.Naval research logistics quarterly, 2(1-2):83–97,
Harold W Kuhn. The hungarian method for the assignment problem.Naval research logistics quarterly, 2(1-2):83–97,
-
[25]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InPro- ceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 1
work page 2023
-
[26]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt ¨aschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020. 1, 2
work page 2020
-
[27]
Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. Align before fuse: Vision and language representation learn- ing with momentum distillation.Advances in neural infor- mation processing systems, 34:9694–9705, 2021. 2
work page 2021
-
[28]
Jiaxuan Li, Duc Minh V o, Akihiro Sugimoto, and Hideki Nakayama. Evcap: Retrieval-augmented image captioning with external visual-name memory for open-world compre- hension. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13733– 13742, 2024. 2
work page 2024
-
[29]
Dynamic graph enhanced contrastive learning for chest x-ray report generation
Mingjie Li, Bingqian Lin, Zicong Chen, Haokun Lin, Xi- aodan Liang, and Xiaojun Chang. Dynamic graph enhanced contrastive learning for chest x-ray report generation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3334–3343, 2023. 5, 6, 3
work page 2023
-
[30]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004. 5
work page 2004
-
[31]
Chang Liu, Yuanhe Tian, Weidong Chen, Yan Song, and Yongdong Zhang. Bootstrapping large language models for radiology report generation.Proceedings of the AAAI Conference on Artificial Intelligence, 38(17):18635–18643,
-
[32]
Aaron Nicolson, Jason Dowling, and Bevan Koopman. Im- proving chest X-ray report generation by leveraging warm starting.Artificial Intelligence in Medicine, 144:102633,
-
[33]
Aaron Nicolson, Jason Dowling, and Bevan Koopman. Im- proving chest x-ray report generation by leveraging warm starting.Artificial intelligence in medicine, 144:102633,
-
[34]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Je- gou, Julien Mairal, Patr...
work page 2024
-
[35]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318,
-
[36]
Jonggwon Park, Soobum Kim, Byungmu Yoon, Jihun Hyun, and Kyoyun Choi. M4cxr: Exploring multi-task potentials of multi-modal large language models for chest x-ray inter- pretation.arXiv preprint arXiv:2408.16213, 2024. 2, 5, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Fernando P ´erez-Garc´ıa, Harshita Sharma, Sam Bond-Taylor, Kenza Bouzid, Valentina Salvatelli, Maximilian Ilse, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Matthew P Lungren, et al. Rad-dino: Exploring scalable medical image encoders beyond text supervision.arXiv preprint arXiv:2401.10815, 2024. 5
-
[38]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 3, 4
work page 2021
-
[39]
Vignav Ramesh, Nathan A Chi, and Pranav Rajpurkar. Im- proving radiology report generation systems by removing hallucinated references to non-existent priors. InMachine Learning for Health, pages 456–473. PMLR, 2022. 1, 2
work page 2022
-
[40]
Smallcap: lightweight image captioning prompted with retrieval augmentation
Rita Ramos, Bruno Martins, Desmond Elliott, and Yova Ke- mentchedjhieva. Smallcap: lightweight image captioning prompted with retrieval augmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2840–2849, 2023. 2
work page 2023
-
[41]
Retrieval augmented chest x-ray report gen- eration using openai gpt models
Mercy Ranjit, Gopinath Ganapathy, Ranjit Manuel, and Tanuja Ganu. Retrieval augmented chest x-ray report gen- eration using openai gpt models. InMachine Learning for Healthcare Conference, pages 650–666. PMLR, 2023. 2
work page 2023
-
[42]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N Reimers. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084,
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[43]
Retrieval-augmented transformer for image caption- ing
Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cuc- chiara. Retrieval-augmented transformer for image caption- ing. InProceedings of the 19th international conference on content-based multimedia indexing, pages 1–7, 2022. 2
work page 2022
-
[44]
M. Moein Shariatnia. Simple CLIP, 2021.https:// github.com/moein-shariatnia/OpenAI-CLIP. 4
work page 2021
-
[45]
Eagle: Exploring the design space for multimodal LLMs with mixture of encoders
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, Yilin Zhao, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, Bryan Catan- zaro, Andrew Tao, Jan Kautz, Zhiding Yu, and Guilin Liu. Eagle: Exploring the design space for multimodal LLMs with mixture of encoders. InThe Thirteenth International Conference on Learning Re...
work page 2025
-
[46]
Akshay Smit, Saahil Jain, Pranav Rajpurkar, Anuj Pareek, Andrew Y Ng, and Matthew P Lungren. Chexbert: Combin- ing automatic labelers and expert annotations for accurate radiology report labeling using bert. InEMNLP 2020-2020 Conference on Empirical Methods in Natural Language Pro- cessing, Proceedings of the Conference, pages 1500–1519,
work page 2020
-
[47]
Liwen Sun, James Zhao, Megan Han, and Chenyan Xiong. Fact-aware multimodal retrieval augmentation for accu- rate medical radiology report generation.arXiv preprint arXiv:2407.15268, 2024. 2, 5, 6
-
[48]
Interactive and explainable region-guided radi- ology report generation
Tim Tanida, Philip M ¨uller, Georgios Kaissis, and Daniel Rueckert. Interactive and explainable region-guided radi- ology report generation. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 7433–7442. IEEE, 2023. 3
work page 2023
-
[49]
Towards gen- eralist biomedical ai.NEJM AI, 1(3):AIoa2300138, 2024
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaeker- mann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al. Towards gen- eralist biomedical ai.NEJM AI, 1(3):AIoa2300138, 2024. 1, 2, 5, 6, 7
work page 2024
-
[50]
Metransformer: Radiology report generation by transformer with multiple learnable expert tokens
Zhanyu Wang, Lingqiao Liu, Lei Wang, and Luping Zhou. Metransformer: Radiology report generation by transformer with multiple learnable expert tokens. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11558–11567, 2023. 5, 6
work page 2023
-
[51]
Distribution-balanced loss for multi-label classification in long-tailed datasets
Tong Wu, Qingqiu Huang, Ziwei Liu, Yu Wang, and Dahua Lin. Distribution-balanced loss for multi-label classification in long-tailed datasets. InComputer Vision – ECCV 2020, pages 162–178, Cham, 2020. Springer International Publish- ing. 4
work page 2020
-
[52]
Retrieval-augmented egocentric video captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, and Weidi Xie. Retrieval-augmented egocentric video captioning. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13525–13536, 2024. 2
work page 2024
-
[53]
Style- aware radiology report generation with radgraph and few- shot prompting
Benjamin Yan, Ruochen Liu, David Kuo, Subathra Adithan, Eduardo Reis, Stephen Kwak, Vasantha Venugopal, Chloe O’Connell, Agustina Saenz, Pranav Rajpurkar, et al. Style- aware radiology report generation with radgraph and few- shot prompting. InFindings of the Association for Computa- tional Linguistics: EMNLP 2023, pages 14676–14688, 2023. 2, 5, 6
work page 2023
-
[54]
Advancing multi- modal medical capabilities of gemini.arXiv preprint arXiv:2405.03162, 2024
Lin Yang, Shawn Xu, Andrew Sellergren, Timo Kohlberger, Yuchen Zhou, Ira Ktena, Atilla Kiraly, Faruk Ahmed, Farhad Hormozdiari, Tiam Jaroensri, et al. Advancing multi- modal medical capabilities of gemini.arXiv preprint arXiv:2405.03162, 2024. 1, 2, 5, 6, 8
-
[55]
Shuxin Yang, Xian Wu, Shen Ge, Zhuozhao Zheng, S. Kevin Zhou, and Li Xiao. Radiology report generation with a learned knowledge base and multi-modal alignment.Med- ical Image Analysis, 86:102798, 2023. 3
work page 2023
-
[56]
Retrieval-augmented multimodal language modeling
Michihiro Yasunaga, Armen Aghajanyan, Weijia Shi, Richard James, Jure Leskovec, Percy Liang, Mike Lewis, Luke Zettlemoyer, and Wen-Tau Yih. Retrieval-augmented multimodal language modeling. InInternational Conference on Machine Learning, pages 39755–39769. PMLR, 2023. 2
work page 2023
-
[57]
Evaluating progress in automatic chest x-ray radiology report generation.Patterns, 4(9), 2023
Feiyang Yu, Mark Endo, Rayan Krishnan, Ian Pan, Andy Tsai, Eduardo Pontes Reis, Eduardo Kaiser Ururahy Nunes Fonseca, Henrique Min Ho Lee, Zahra Shakeri Hossein Abad, Andrew Y Ng, et al. Evaluating progress in automatic chest x-ray radiology report generation.Patterns, 4(9), 2023. 5
work page 2023
-
[58]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915,
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Junting Zhao, Yang Zhou, Zhihao Chen, Huazhu Fu, and Liang Wan. Topicwise separable sentence retrieval for med- ical report generation.IEEE Transactions on Medical Imag- ing, 2024. 1, 2 Leveraging LLMs for Multimodal Retrieval-Augmented Radiology Report Generation via Key Phrase Extraction Supplementary Material A. Implementation Details A.1. External Sou...
work page 2024
-
[60]
used the entire IU X-Ray dataset as the test set, treating each frontal and lateral image as an independent sample and excluding a portion of normal images to maintain a 10% normal image ratio. This subset of 4,168 images is publicly available8 and is also used in our evaluation to assess the performance of single-view RRG. B.2. Results Table 5 shows our ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.