StereoMamba: Real-time and Robust Intraoperative Stereo Disparity Estimation via Long-range Spatial Dependencies
Pith reviewed 2026-05-22 18:41 UTC · model grok-4.3
The pith
StereoMamba uses a Mamba-based module to capture long-range spatial dependencies for accurate real-time stereo disparity estimation in surgery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Incorporating the Feature Extraction Mamba module to strengthen long-range spatial dependencies within and across stereo images, together with the Multidimensional Feature Fusion module for multi-scale integration, enables StereoMamba to reach an EPE of 2.64 px, depth MAE of 2.55 mm, second-best Bad2 and Bad3 scores, 21.28 FPS inference on high-resolution pairs, and the highest SSIM of 0.8970 plus PSNR of 16.0761 under zero-shot evaluation on in-vivo data.
What carries the argument
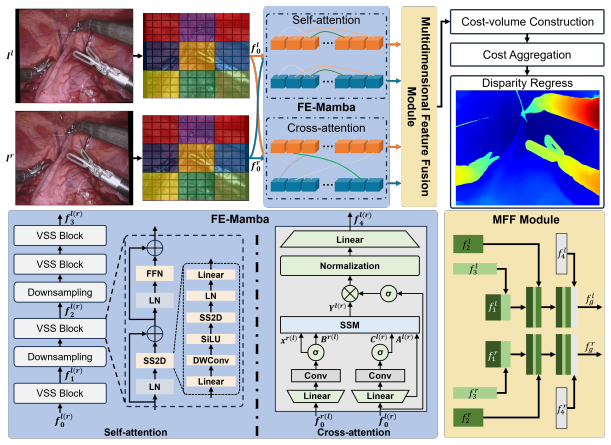
The Feature Extraction Mamba (FE-Mamba) module, which extracts and relates features over long spatial ranges both inside each stereo image and between the pair.
If this is right
- StereoMamba records the lowest EPE and depth MAE among compared methods while still delivering real-time throughput on high-resolution inputs.
- Disparity maps produced by the model yield the highest structural similarity and peak signal-to-noise ratio when used to warp one image onto the other.
- The same weights generalize without retraining to two independent in-vivo collections, indicating robustness to domain shift.
- The architecture therefore supplies a practical operating point that trades off accuracy, robustness, and speed for intraoperative stereo vision.
Where Pith is reading between the lines
- State-space models may serve as efficient substitutes for attention mechanisms in other real-time medical imaging tasks that require wide receptive fields.
- Accurate, fast disparity estimation of this kind could be chained directly into live 3D surface reconstruction and instrument tracking inside the operating room.
- Further experiments on sequences that contain rapid tissue motion, specular reflections, or changing illumination would test whether the reported robustness holds under more varied surgical conditions.
Load-bearing premise
That performance gains are mainly due to the long-range modeling inside FE-Mamba and that the chosen ex-vivo and limited in-vivo test sets represent the range of conditions encountered during actual operations.
What would settle it
An ablation study that removes the FE-Mamba module, retrains the remaining network on the same SCARED data, and directly compares the resulting EPE, depth MAE, and frame rate against the full model.
Figures



read the original abstract
Stereo disparity estimation is crucial for obtaining depth information in robot-assisted minimally invasive surgery (RAMIS). While current deep learning methods have made significant advancements, challenges remain in achieving an optimal balance between accuracy, robustness, and inference speed. To address these challenges, we propose the StereoMamba architecture, which is specifically designed for stereo disparity estimation in RAMIS. Our approach is based on a novel Feature Extraction Mamba (FE-Mamba) module, which enhances long-range spatial dependencies both within and across stereo images. To effectively integrate multi-scale features from FE-Mamba, we then introduce a novel Multidimensional Feature Fusion (MFF) module. Experiments against the state-of-the-art on the ex-vivo SCARED benchmark demonstrate that StereoMamba achieves superior performance on EPE of 2.64 px and depth MAE of 2.55 mm, the second-best performance on Bad2 of 41.49% and Bad3 of 26.99%, while maintaining an inference speed of 21.28 FPS for a pair of high-resolution images (1280*1024), striking the optimum balance between accuracy, robustness, and efficiency. Furthermore, by comparing synthesized right images, generated from warping left images using the generated disparity maps, with the actual right image, StereoMamba achieves the best average SSIM (0.8970) and PSNR (16.0761), exhibiting strong zero-shot generalization on the in-vivo RIS2017 and StereoMIS datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StereoMamba for stereo disparity estimation in robot-assisted minimally invasive surgery. It proposes a Feature Extraction Mamba (FE-Mamba) module to capture long-range spatial dependencies within and across stereo images, along with a Multidimensional Feature Fusion (MFF) module to integrate multi-scale features. On the ex-vivo SCARED benchmark, it reports an EPE of 2.64 px, depth MAE of 2.55 mm, Bad2 of 41.49%, Bad3 of 26.99%, and 21.28 FPS inference on 1280x1024 images. Zero-shot tests on in-vivo RIS2017 and StereoMIS datasets show best average SSIM of 0.8970 and PSNR of 16.0761 via comparison of synthesized and actual right images.
Significance. If the results hold and the gains are attributable to the novel modules, the work could advance real-time intraoperative depth estimation by improving the accuracy-efficiency trade-off over prior methods. The paper earns credit for reporting concrete benchmark numbers on public datasets and conducting cross-dataset zero-shot tests on in-vivo data.
major comments (2)
- [Experimental evaluation] Experimental evaluation: the performance claims (EPE 2.64 px, depth MAE 2.55 mm, best SSIM/PSNR) are presented without ablation studies isolating the contribution of FE-Mamba. Controlled variants replacing Mamba blocks with equivalent-capacity CNN or transformer backbones (while holding training data, optimizer, and MFF fixed) are required to attribute gains to long-range dependency modeling rather than other design or training choices.
- [Zero-shot generalization] Zero-shot generalization section: evaluation on RIS2017 and StereoMIS relies on SSIM/PSNR from synthesized right images without ground-truth disparity. This indirect metric supports robustness claims but does not directly validate disparity accuracy under intraoperative conditions, especially given the ex-vivo to in-vivo domain shift.
minor comments (2)
- [Methods] Provide full training details, hyperparameters, and network diagrams to support reproducibility.
- [Results] Include error bars, multiple runs, or statistical tests for the reported metrics to strengthen the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below and outline the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation: the performance claims (EPE 2.64 px, depth MAE 2.55 mm, best SSIM/PSNR) are presented without ablation studies isolating the contribution of FE-Mamba. Controlled variants replacing Mamba blocks with equivalent-capacity CNN or transformer backbones (while holding training data, optimizer, and MFF fixed) are required to attribute gains to long-range dependency modeling rather than other design or training choices.
Authors: We agree that dedicated ablation studies are needed to isolate the contribution of the FE-Mamba module. In the revised manuscript we will add controlled experiments that replace the Mamba blocks with CNN and transformer backbones of matched capacity while keeping the training data, optimizer, and MFF module fixed. These results will be reported alongside the existing SOTA comparisons to more clearly attribute performance gains to long-range spatial dependency modeling. revision: yes
-
Referee: [Zero-shot generalization] Zero-shot generalization section: evaluation on RIS2017 and StereoMIS relies on SSIM/PSNR from synthesized right images without ground-truth disparity. This indirect metric supports robustness claims but does not directly validate disparity accuracy under intraoperative conditions, especially given the ex-vivo to in-vivo domain shift.
Authors: We acknowledge that SSIM/PSNR computed from synthesized right images constitutes an indirect metric when ground-truth disparity is unavailable. This evaluation protocol is standard in the stereo-matching literature for in-vivo data. In the revision we will expand the discussion to explicitly note the limitations of the metric and the challenges posed by the ex-vivo to in-vivo domain shift, while retaining the reported numbers as supporting evidence of generalization. revision: partial
Circularity Check
No circularity: empirical results from direct benchmark evaluation
full rationale
This is a standard empirical machine-learning paper proposing the StereoMamba architecture with FE-Mamba and MFF modules for stereo disparity estimation. All reported metrics (EPE 2.64 px, depth MAE 2.55 mm, SSIM 0.8970, PSNR 16.0761, FPS 21.28) are obtained via training on SCARED and zero-shot evaluation on RIS2017/StereoMIS, with no equations, derivations, or self-citations that reduce the claimed performance to quantities defined by the model's own fitted parameters or prior self-referential results. The central claims rest on external benchmark comparisons rather than any internal reduction by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Model hyperparameters and training schedule
axioms (1)
- domain assumption Mamba-based blocks can capture the long-range spatial dependencies needed for accurate stereo matching in surgical scenes.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose the FE-Mamba module... self-attention and cross-attention... SSM (A, B, C, x) ... Multidimensional Feature Fusion (MFF) module... group-wise correlation maps
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Msdesis: Multitask stereo disparity estimation and surgical instrument segmentation,
D. Psychogyios, E. Mazomenos, F. Vasconcelos, and D. Stoyanov, “Msdesis: Multitask stereo disparity estimation and surgical instrument segmentation,” IEEE Trans. Med. Imaging , vol. 41, no. 11, pp. 3218– 3230, 2022
work page 2022
-
[2]
Frsr: Framework for real-time scene reconstruction in robot-assisted minimally invasive surgery,
Z. Chen, et al., “Frsr: Framework for real-time scene reconstruction in robot-assisted minimally invasive surgery,” Comput. Biol. Med. , vol. 163, p. 107121, 2023
work page 2023
-
[3]
X. Feng, X. Zhang, X. Shi, L. Li, and S. Wang, “St-itef: Spatio- temporal intraoperative task estimating framework to recognize surgi- cal phase and predict instrument path based on multi-object tracking in keratoplasty,” Med. Image Anal. , vol. 91, p. 103026, 2024
work page 2024
-
[4]
Z. Chen, et al. , “Spatio-temporal layers based intra-operative stereo depth estimation network via hierarchical prediction and progressive training,” Comput. Methods Programs Biomed. , vol. 244, p. 107937, 2024
work page 2024
-
[5]
Group-wise correlation stereo network,
X. Guo, K. Yang, W. Yang, X. Wang, and H. Li, “Group-wise correlation stereo network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 3273–3282
work page 2019
-
[6]
Attention concatenation volume for accurate and efficient stereo matching,
G. Xu, J. Cheng, P. Guo, and X. Yang, “Attention concatenation volume for accurate and efficient stereo matching,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. , 2022, pp. 12 981–12 990
work page 2022
-
[7]
Hierarchical neural architecture search for deep stereo matching,
X. Cheng, et al. , “Hierarchical neural architecture search for deep stereo matching,” Adv. Neural Inf. Process. Syst. , vol. 33, pp. 22 158– 22 169, 2020
work page 2020
-
[8]
Selective-stereo: Adaptive frequency information selection for stereo matching,
X. Wang, G. Xu, H. Jia, and X. Yang, “Selective-stereo: Adaptive frequency information selection for stereo matching,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. , 2024, pp. 19 701–19 710
work page 2024
-
[9]
Pyramid stereo matching network,
J.-R. Chang and Y .-S. Chen, “Pyramid stereo matching network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. , 2018, pp. 5410– 5418
work page 2018
-
[10]
Transmvsnet: Global context-aware multi-view stereo network with transformers,
Y . Ding, et al., “Transmvsnet: Global context-aware multi-view stereo network with transformers,” in 2022 IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 8585–8594
work page 2022
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in Proc. Int. Conf. Learn. Represent. , 2021
work page 2021
-
[12]
Deep laparoscopic stereo matching with transformers,
X. Cheng, Y . Zhong, M. Harandi, T. Drummond, Z. Wang, and Z. Ge, “Deep laparoscopic stereo matching with transformers,” in Proc. Int. Conf. Med. Image Comput. Comput.-Assisted Intervention . Springer, 2022, pp. 464–474
work page 2022
-
[13]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” Proc. Int. Conf. Learn. Represent. , 2024
work page 2024
-
[14]
Efficiently modeling long sequences with structured state spaces,
A. Gu, K. Goel, and C. Re, “Efficiently modeling long sequences with structured state spaces,” in Proc. Int. Conf. Learn. Represent. , 2022
work page 2022
-
[15]
Vmamba: Visual state space model,
Y . Liu, et al., “Vmamba: Visual state space model,” Proc. Adv. Neural Inf. Process. Syst. , vol. 37, pp. 103 031–103 063, 2024
work page 2024
-
[16]
Vision mamba: Efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,” in Proc. Int. Conf. Mach. Learn. , vol. 235, 2024, pp. 62 429–62 442
work page 2024
-
[17]
Mambahsi: Spa- tial–spectral mamba for hyperspectral image classification,
Y . Li, Y . Luo, L. Zhang, Z. Wang, and B. Du, “Mambahsi: Spa- tial–spectral mamba for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens. , vol. 62, pp. 1–16, 2024
work page 2024
-
[18]
C. Ma and Z. Wang, “Semi-mamba-unet: Pixel-level contrastive and cross-supervised visual mamba-based unet for semi-supervised medi- cal image segmentation,” KNOWL-BASED SYST, vol. 300, p. 112203, 2024
work page 2024
-
[19]
Raft: Recurrent all-pairs field transforms for optical flow,
Z. Teed and J. Deng, “Raft: Recurrent all-pairs field transforms for optical flow,” in Proc. Eur . Conf. Comput. Vis. Springer, 2020, pp. 402–419
work page 2020
-
[20]
Raft-stereo: Multilevel recurrent field transforms for stereo matching,
L. Lipson, Z. Teed, and J. Deng, “Raft-stereo: Multilevel recurrent field transforms for stereo matching,” in 2021 International Conference on 3D Vision (3DV) . IEEE, 2021, pp. 218–227
work page 2021
-
[21]
Iterative geometry encoding volume for stereo matching,
G. Xu, X. Wang, X. Ding, and X. Yang, “Iterative geometry encoding volume for stereo matching,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2023, pp. 21 919–21 928
work page 2023
-
[22]
H. Shi, Z. Wang, Y . Zhou, D. Li, X. Yang, and Q. Li, “Bidirectional semi-supervised dual-branch cnn for robust 3d reconstruction of stereo endoscopic images via adaptive cross and parallel supervisions,” IEEE Trans. Med. Imaging , vol. 42, no. 11, pp. 3269–3282, 2023
work page 2023
-
[23]
T. Dao and A. Gu, “Transformers are ssms: Generalized models and efficient algorithms through structured state space duality,” Proc. Int. Conf. Mach. Learn. , pp. 31 788–31 812, 2024
work page 2024
-
[24]
Transformers are rnns: Fast autoregressive transformers with linear attention,
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are rnns: Fast autoregressive transformers with linear attention,” in Proc. Int. Conf. Mach. Learn. , 2020, pp. 5156–5165
work page 2020
-
[25]
N. Mayer, et al. , “A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. , 2016, pp. 4040–4048
work page 2016
-
[26]
Stereo correspondence and reconstruction of endoscopic data challenge
M. Allan, et al. , “Stereo correspondence and reconstruction of endo- scopic data challenge,” arXiv preprint arXiv:2101.01133 , 2021
-
[27]
2017 Robotic Instrument Segmentation Challenge
M. Allan, et al. , “2017 robotic instrument segmentation challenge,” arXiv preprint arXiv:1902.06426 , 2019
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Learning how to robustly estimate camera pose in endoscopic videos,
M. Hayoz, et al. , “Learning how to robustly estimate camera pose in endoscopic videos,” INT J COMPUT ASS RAD , vol. 18, no. 7, pp. 1185–1192, 2023
work page 2023
-
[29]
Disparity-aware domain adaptation in stereo image restoration,
B. Yan, C. Ma, B. Bare, W. Tan, and S. C. Hoi, “Disparity-aware domain adaptation in stereo image restoration,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. , 2020, pp. 13 179–13 187
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.