Robustness via Referencing: Defending against Prompt Injection Attacks by Referencing the Executed Instruction
Pith reviewed 2026-05-22 19:07 UTC · model grok-4.3
The pith
LLMs defend against prompt injections by referencing the original instructions they follow when generating answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that LLMs remain aware of which instructions they are executing even when they respond to injected ones. Prompting the model to produce answers together with references to the source instructions inside the original prompt allows a simple filter to retain only answers tied to the legitimate instructions and to drop those derived from injected commands.
What carries the argument
The instruction referencing mechanism, in which the model is prompted to state the source instruction used for each generated answer segment so that post-processing can filter responses accordingly.
If this is right
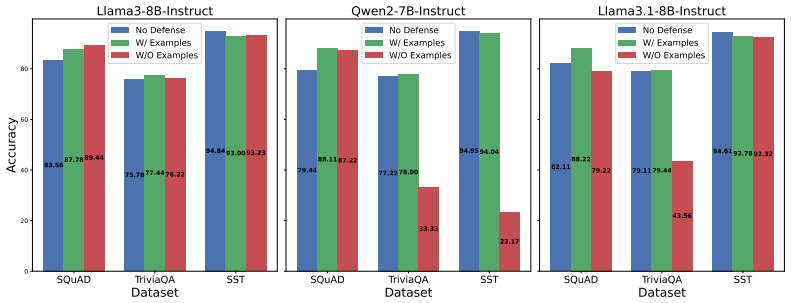
- Attack success rate falls to zero percent in multiple tested prompt injection scenarios.
- The method achieves results comparable to fine-tuning defenses without any model retraining.
- Utility on clean, non-attacked inputs shows only minimal change.
- Performance exceeds that of existing prompt-engineering baselines.
Where Pith is reading between the lines
- The same reference-and-filter step could be added as lightweight post-processing to any LLM pipeline that ingests untrusted external text.
- Improvements in a model's ability to track its own instruction sources would make the defense stronger with lighter prompting.
- The technique points toward practical ways to increase transparency about which directives an LLM actually followed.
Load-bearing premise
Large language models can accurately identify and report the exact instructions from the original prompt that they are following when they produce each part of an answer.
What would settle it
A set of test cases in which the model, even when explicitly prompted to reference the executed instruction, produces wrong or missing references for answers that were shaped by injected instructions, so that the filter fails to remove the attack.
Figures


read the original abstract
Large language models (LLMs) have demonstrated impressive performance and have come to dominate the field of natural language processing (NLP) across various tasks. However, due to their strong instruction-following capabilities and inability to distinguish between instructions and data content, LLMs are vulnerable to prompt injection attacks. These attacks manipulate LLMs into deviating from the original input instructions and executing maliciously injected instructions within data content, such as web documents retrieved from search engines. Existing defense methods, including prompt-engineering and fine-tuning approaches, typically instruct models to follow the original input instructions while suppressing their tendencies to execute injected instructions. However, our experiments reveal that suppressing instruction-following tendencies is challenging. Through analyzing failure cases, we observe that although LLMs tend to respond to any recognized instructions, they are aware of which specific instructions they are executing and can correctly reference them within the original prompt. Motivated by these findings, we propose a novel defense method that leverages, rather than suppresses, the instruction-following abilities of LLMs. Our approach prompts LLMs to generate responses that include both answers and their corresponding instruction references. Based on these references, we filter out answers not associated with the original input instructions. Comprehensive experiments demonstrate that our method outperforms prompt-engineering baselines and achieves performance comparable to fine-tuning methods, reducing the attack success rate (ASR) to 0 percent in some scenarios. Moreover, our approach has minimal impact on overall utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a defense against prompt injection attacks by prompting LLMs to generate responses that explicitly reference the specific instruction being executed. A downstream filter then retains only those responses whose referenced instruction matches the original user instruction, discarding others. This is motivated by the observation that LLMs remain aware of which instruction they follow even in failure cases and can correctly cite it. Experiments are reported to show the method reduces attack success rate (ASR) to 0% in some scenarios, outperforms prompt-engineering baselines, matches fine-tuning performance, and preserves utility with minimal overhead.
Significance. If substantiated, the result is significant because it offers a lightweight, training-free defense that exploits rather than suppresses the model's instruction-following behavior, addressing a limitation of prior prompt-engineering approaches. Prompt injection is a practical threat in retrieval-augmented and agentic LLM deployments; a method achieving 0% ASR in tested cases while remaining comparable to fine-tuning would be a useful addition to the defense toolkit. The empirical grounding and focus on leveraging observed model capabilities are constructive strengths.
major comments (2)
- [Motivating observation] Motivating observation (introduction and §3): the key assumption that LLMs will correctly reference the actually executed instruction is derived from non-adversarial failure-case analysis. The manuscript does not demonstrate that this holds when an adversary crafts an injection that simultaneously causes the model to follow the malicious instruction and emit a reference to the original instruction; such a misattribution would allow the filter to accept the attack output and collapse the reported ASR reduction.
- [Experimental evaluation] Experimental evaluation (abstract and results section): the claim of 0% ASR in some scenarios requires explicit confirmation that the tested attacks include attempts to manipulate or spoof the reference output itself. Without such coverage, the evaluation may not address the primary failure mode implied by the motivating observation.
minor comments (2)
- [Method] Method description: a short pseudocode or explicit filtering rule would clarify exactly how references are parsed and matched against the original instruction.
- [Results] Tables reporting ASR and utility: include error bars or statistical tests to support claims of comparability to fine-tuning.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments identify a key assumption in our motivating observation and a corresponding gap in the experimental coverage. We address each point below and commit to revisions that directly strengthen the manuscript without overstating current results.
read point-by-point responses
-
Referee: [Motivating observation] Motivating observation (introduction and §3): the key assumption that LLMs will correctly reference the actually executed instruction is derived from non-adversarial failure-case analysis. The manuscript does not demonstrate that this holds when an adversary crafts an injection that simultaneously causes the model to follow the malicious instruction and emit a reference to the original instruction; such a misattribution would allow the filter to accept the attack output and collapse the reported ASR reduction.
Authors: We agree that the motivating observation was obtained from non-adversarial failure cases. The manuscript therefore does not yet contain a direct demonstration that the reference behavior remains reliable when an adversary explicitly attempts to induce execution of the injected instruction while forcing a reference to the original instruction. We will revise the introduction and §3 to explicitly acknowledge this scope limitation and add a new subsection that analyzes the difficulty of crafting such a targeted misattribution attack. In addition, we will include new experiments that test prompts designed to produce a false reference while executing the malicious instruction, reporting both success rates and any observed degradation in the defense. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation (abstract and results section): the claim of 0% ASR in some scenarios requires explicit confirmation that the tested attacks include attempts to manipulate or spoof the reference output itself. Without such coverage, the evaluation may not address the primary failure mode implied by the motivating observation.
Authors: The current experiments evaluate against standard prompt-injection attacks drawn from prior literature; these attacks aim to override the original instruction but do not specifically optimize for spoofing the generated reference. The reported 0% ASR therefore reflects performance under those attack distributions. We will revise the abstract and results section to state this scope clearly and add a new set of experiments that include reference-spoofing attempts. These additional results will be presented alongside the existing numbers so readers can assess whether the defense holds when the reference itself is adversarially manipulated. revision: yes
Circularity Check
Empirical prompting defense with no circular derivation
full rationale
The paper presents an empirical defense: it reports an observation from failure-case analysis that LLMs can reference the specific instructions they execute, then describes a prompting-plus-filtering procedure that uses those references to discard answers tied to injected instructions. No equations, fitted parameters, or self-citations are invoked as load-bearing premises; the method is a heuristic grounded in direct experimental observation rather than any derivation that reduces to its own inputs by construction. The central claim therefore remains independent of the inputs it is evaluated against.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs are aware of which specific instructions they are executing and can correctly reference them within the original prompt
Forward citations
Cited by 1 Pith paper
-
Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges
A survey that taxonomizes threats to agentic AI, reviews benchmarks and evaluation methods, discusses technical and governance defenses, and identifies open challenges.
Reference graph
Works this paper leans on
-
[1]
https://learnprompting.org/docs/prompt_hacking/ defensive_measures/instruction, 2023
Instruction defense. https://learnprompting.org/docs/prompt_hacking/ defensive_measures/instruction, 2023
work page 2023
-
[2]
https://learnprompting.org/docs/prompt_hacking/defensive_ measures/sandwich_defense, 2023
Sandwich defense. https://learnprompting.org/docs/prompt_hacking/defensive_ measures/sandwich_defense, 2023
work page 2023
- [3]
-
[4]
Don’t you (forget nlp): Prompt injection with control characters in chatgpt
Mark Breitenbach, Adrian Wood, Win Suen, and Po-Ning Tseng. Don’t you (forget nlp): Prompt injection with control characters in chatgpt. https://dropbox.tech/machine-learning/ prompt-injection-with-control-characters_openai-chatgpt-llm , 2023
work page 2023
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde, Jared Kaplan, Harrison Edwards, Yura Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winte...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Struq: Defending against prompt injection with structured queries
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. Struq: Defending against prompt injection with structured queries. arXiv preprint arXiv:2402.06363, 2024
-
[7]
Secalign: Defending against prompt injection with preference optimization,
Sizhe Chen, Arman Zharmagambetov, Saeed Mahloujifar, Kamalika Chaudhuri, and Chuan Guo. Aligning llms to be robust against prompt injection. arXiv preprint arXiv:2410.05451, 2024
-
[8]
Can indirect prompt injection attacks be detected and removed?, 2025
Yulin Chen, Haoran Li, Yuan Sui, Yufei He, Yue Liu, Yangqiu Song, and Bryan Hooi. Can indirect prompt injection attacks be detected and removed?, 2025
work page 2025
-
[9]
De- fense against prompt injection attack by leveraging attack techniques
Yulin Chen, Haoran Li, Zihao Zheng, Yangqiu Song, Dekai Wu, and Bryan Hooi. De- fense against prompt injection attack by leveraging attack techniques. arXiv preprint arXiv:2411.00459, 2024
-
[10]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1107–1128, 2024
work page 2024
-
[11]
The llama 3 herd of models, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, et al. The llama 3 herd of models, 2024
work page 2024
-
[12]
Alpacafarm: A simulation framework for methods that learn from human feedback
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy S Liang, and Tatsunori B Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback. Advances in Neural Information Processing Systems, 36, 2024. 11
work page 2024
-
[13]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, pages 79–90, 2023
work page 2023
-
[14]
Yufei He, Yuexin Li, Jiaying Wu, Yuan Sui, Yulin Chen, and Bryan Hooi. Evaluating the paperclip maximizer: Are rl-based language models more likely to pursue instrumental goals? arXiv preprint arXiv:2502.12206, 2025
-
[15]
Unigraph: Learning a unified cross-domain foundation model for text-attributed graphs
Yufei He, Yuan Sui, Xiaoxin He, and Bryan Hooi. Unigraph: Learning a unified cross-domain foundation model for text-attributed graphs. arXiv preprint arXiv:2402.13630, 2024
-
[16]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kici- man. Defending against indirect prompt injection attacks with spotlighting. arXiv preprint arXiv:2403.14720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Semantic-guided prompt organization for universal goal hijacking against llms
Yihao Huang, Chong Wang, Xiaojun Jia, Qing Guo, Felix Juefei-Xu, Jian Zhang, Geguang Pu, and Yang Liu. Semantic-guided prompt organization for universal goal hijacking against llms. arXiv preprint arXiv:2405.14189, 2024
-
[18]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Wayne Xin Zhao, and Ji-Rong Wen. Structgpt: A general framework for large language model to reason over structured data. arXiv preprint arXiv:2305.09645, 2023
-
[20]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv e-prints, page arXiv:1705.03551, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems, volume 35, pages 22199–22213, 2022
work page 2022
-
[22]
Evaluating the instruction-following robustness of large language models to prompt injection
Zekun Li, Baolin Peng, Pengcheng He, and Xifeng Yan. Evaluating the instruction-following robustness of large language models to prompt injection. 2023
work page 2023
-
[23]
Universal and context-independent triggers for precise control of llm outputs
Jiashuo Liang, Guancheng Li, and Yang Yu. Universal and context-independent triggers for precise control of llm outputs. arXiv preprint arXiv:2411.14738, 2024
-
[24]
Automatic and universal prompt injection attacks against large language models,
Xiaogeng Liu, Zhiyuan Yu, Yizhe Zhang, Ning Zhang, and Chaowei Xiao. Automatic and uni- versal prompt injection attacks against large language models. arXiv preprint arXiv:2403.04957, 2024
-
[25]
Prompt Injection attack against LLM-integrated Applications
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, et al. Prompt injection attack against llm-integrated applications. arXiv preprint arXiv:2306.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Guardreasoner: Towards reasoning-based llm safeguards
Yue Liu, Hongcheng Gao, Shengfang Zhai, Xia Jun, Tianyi Wu, Zhiwei Xue, Yulin Chen, Kenji Kawaguchi, Jiaheng Zhang, and Bryan Hooi. Guardreasoner: Towards reasoning-based llm safeguards. arXiv preprint arXiv:2501.18492, 2025
-
[27]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In USENIX Security Symposium, 2024
work page 2024
-
[28]
Towards deep learning models resistant to adversarial attacks
Aleksander M ˛ adry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. stat, 1050(9), 2017
work page 2017
-
[29]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019
work page 2019
-
[30]
Ignore Previous Prompt: Attack Techniques For Language Models
Fábio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Jatmo: Prompt Injection Defense by Task-Specific Finetuning,
Julien Piet, Maha Alrashed, Chawin Sitawarin, Sizhe Chen, Zeming Wei, Elizabeth Sun, Basel Alomair, and David Wagner. Jatmo: Prompt injection defense by task-specific finetuning. arXiv preprint arXiv:2312.17673, 2023. 12
-
[32]
SQuAD: 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In Jian Su, Kevin Duh, and Xavier Carreras, editors, Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas, November 2016. Association for Computational Linguistics
work page 2016
-
[33]
Machine against the rag: Jamming retrieval-augmented generation with blocker documents
Avital Shafran, Roei Schuster, and Vitaly Shmatikov. Machine against the rag: Jamming retrieval-augmented generation with blocker documents. arXiv preprint arXiv:2406.05870, 2024
-
[34]
Making llms vulner- able to prompt injection via poisoning alignment,
Zedian Shao, Hongbin Liu, Jaden Mu, and Neil Zhenqiang Gong. Making llms vulnerable to prompt injection via poisoning alignment. arXiv preprint arXiv:2410.14827, 2024
-
[35]
Optimization-based prompt injection attack to llm-as-a-judge
Jiawen Shi, Zenghui Yuan, Yinuo Liu, Yue Huang, Pan Zhou, Lichao Sun, and Neil Zhen- qiang Gong. Optimization-based prompt injection attack to llm-as-a-judge. arXiv preprint arXiv:2403.17710, 2024
-
[36]
On the exploitability of instruction tuning
Manli Shu, Jiongxiao Wang, Chen Zhu, Jonas Geiping, Chaowei Xiao, and Tom Goldstein. On the exploitability of instruction tuning. Advances in Neural Information Processing Systems, 36:61836–61856, 2023
work page 2023
-
[37]
Recursive deep models for semantic compositionality over a sentiment treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642, 2013
work page 2013
-
[38]
Alis: Aligned llm instruction security strategy for unsafe input prompt
Xinhao Song, Sufeng Duan, and Gongshen Liu. Alis: Aligned llm instruction security strategy for unsafe input prompt. In Proceedings of the 31st International Conference on Computational Linguistics, pages 9124–9146, 2025
work page 2025
-
[39]
Xuchen Suo. Signed-prompt: A new approach to prevent prompt injection attacks against llm-integrated applications. arXiv preprint arXiv:2401.07612, 2024
-
[40]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training llms to prioritize privileged instructions. arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Safety in large reasoning models: A survey
Cheng Wang, Yue Liu, Baolong Li, Duzhen Zhang, Zhongzhi Li, and Junfeng Fang. Safety in large reasoning models: A survey. arXiv preprint arXiv:2504.17704, 2025
-
[42]
Fath: Authentication-based test-time defense against indirect prompt injection attacks
Jiongxiao Wang, Fangzhou Wu, Wendi Li, Jinsheng Pan, Edward Suh, Z Morley Mao, Muhao Chen, and Chaowei Xiao. Fath: Authentication-based test-time defense against indirect prompt injection attacks. arXiv preprint arXiv:2410.21492, 2024
-
[43]
Delimiters won’t save you from prompt injection.https://simonwillison
Simon Willison. Delimiters won’t save you from prompt injection.https://simonwillison. net/2023/May/11/delimiters-wont-save-you , 2023
work page 2023
-
[44]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei...
work page 2024
-
[45]
Benchmarking and defending against indirect prompt injection attacks on large language models,
Jingwei Yi, Yueqi Xie, Bin Zhu, Keegan Hines, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Benchmarking and defending against indirect prompt injection attacks on large language models. arXiv preprint arXiv:2312.14197, 2023
-
[46]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. arXiv preprint arXiv:2403.02691, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Rtbas: Defending llm agents against prompt injection and privacy leakage,
Peter Yong Zhong, Siyuan Chen, Ruiqi Wang, McKenna McCall, Ben L Titzer, and Heather Miller. Rtbas: Defending llm agents against prompt injection and privacy leakage. arXiv preprint arXiv:2502.08966, 2025. 13
-
[48]
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V Le, and Ed H. Chi. Least-to-most prompting enables complex reasoning in large language models. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[49]
Melon: Indirect prompt injection defense via masked re-execution and tool comparison
Kaijie Zhu, Xianjun Yang, Jindong Wang, Wenbo Guo, and William Yang Wang. Melon: Indirect prompt injection defense via masked re-execution and tool comparison. arXiv preprint arXiv:2502.05174, 2025
-
[50]
Auto- DAN: Automatic and Interpretable Adversarial Attacks on Large Language Models,
Sicheng Zhu, Ruiyi Zhang, Bang An, Gang Wu, Joe Barrow, Zichao Wang, Furong Huang, Ani Nenkova, and Tong Sun. Autodan: interpretable gradient-based adversarial attacks on large language models. arXiv preprint arXiv:2310.15140, 2023
-
[51]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023. 14 Appendix / supplemental material A Implementation Detail. We conduct our defense experiments using PyTorch 2.1.0 [29]. The experiments are performed on ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
The “max_length” is set to 8192. The word number of each line K is set to 32. B Baselines B.1 Attack Baselines Naive attack. The naive attack method involves simply appending the injected instruction to the original data content, as shown in Table 10. Ignore attack [30]. The ignore attack firstly append an ignoring instruction and then the injected instru...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.