Accelerated Decentralized Constraint-Coupled Optimization: A Dual² Approach
Pith reviewed 2026-05-22 15:54 UTC · model grok-4.3
The pith
A dual squared approach produces two accelerated algorithms for decentralized optimization with shared constraints that converge under milder conditions on the public cost function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Building on a novel dual² approach, the paper develops the inexact Dual² Accelerated gradient method and the Multi-consensus inexact Dual² Accelerated gradient method. Both iD2A and MiD2A guarantee asymptotic convergence under a milder condition on h compared to existing algorithms. Under additional assumptions they establish linear convergence rates and significantly lower communication and computational complexity bounds.
What carries the argument
The dual² approach, which applies dualization twice to the constraint-coupled problem so that local dual updates can coordinate the shared equality constraint across the network while supporting acceleration and inexact steps.
If this is right
- The algorithms reach the optimal solution asymptotically whenever h meets the stated milder condition.
- Linear convergence holds when extra assumptions such as strong convexity are added.
- Communication rounds and per-agent computations drop below the bounds reported for earlier decentralized solvers of the same problem class.
- Multi-consensus steps in one variant further cut the number of neighbor exchanges needed for coordination.
Where Pith is reading between the lines
- The dual² construction could extend to problems with inequality constraints or time-varying networks if the connectivity requirement is relaxed.
- Lower complexity bounds suggest these methods might run on battery-limited sensors or edge devices that cannot afford frequent messaging.
- Similar dualization tricks may help other multi-agent problems where only partial information is shared among neighbors.
Load-bearing premise
The communication network must be undirected and connected so that information about the shared constraint propagates to every agent.
What would settle it
A numerical test or analytic counterexample in which iD2A or MiD2A fails to converge asymptotically on a problem where h satisfies only the paper's milder condition but not the stronger conditions used by prior methods.
Figures


read the original abstract
In this paper, we focus on a class of decentralized constraint-coupled optimization problem: $\min_{x_i \in \mathbb{R}^{d_i}, i \in \mathcal{I}; y \in \mathbb{R}^p}$ $\sum_{i=1}^n\left(f_i(x_i) + g_i(x_i)\right) + h(y) \ \text{s.t.} \ \sum_{i=1}^{n}A_ix_i = y$, over an undirected and connected network of $n$ agents. Here, $f_i$, $g_i$, and $A_i$ represent private information of agent $i \in \mathcal{I} = \{1, \cdots, n\}$, while $h$ is public for all agents. Building on a novel dual$^2$ approach, we develop two accelerated algorithms to solve this problem: the inexact Dual$^2$ Accelerated (iD2A) gradient method and the Multi-consensus inexact Dual$^2$ Accelerated (MiD2A) gradient method. We demonstrate that both iD2A and MiD2A can guarantee asymptotic convergence under a milder condition on $h$ compared to existing algorithms. Furthermore, under additional assumptions, we establish linear convergence rates and derive significantly lower communication and computational complexity bounds than those of existing algorithms. Several numerical experiments validate our theoretical analysis and demonstrate the practical superiority of the proposed algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript addresses a class of decentralized constraint-coupled optimization problems: minimize sum_i (f_i(x_i) + g_i(x_i)) + h(y) subject to sum_i A_i x_i = y, where f_i, g_i, A_i are private to agents on an undirected connected network and h is public. It introduces a dual² approach yielding two accelerated methods—the inexact Dual² Accelerated (iD2A) gradient method and the Multi-consensus inexact Dual² Accelerated (MiD2A) gradient method. The central claims are asymptotic convergence under a milder condition on h than prior algorithms, plus linear convergence rates and improved communication/computational complexity bounds under additional assumptions, supported by Lyapunov-style analysis and numerical experiments.
Significance. If the derivations hold, the work is significant for distributed optimization because it relaxes conditions on the public coupling function h while delivering lower complexity, which is valuable for scalable networked systems. The reliance on standard Lyapunov arguments for inexact accelerated updates and the explicit focus on communication efficiency are strengths; the post-hoc numerical validation helps but would be stronger with quantitative baseline comparisons.
major comments (2)
- [§4.2] §4.2, convergence theorem for iD2A: the milder condition on h is load-bearing for the headline claim; the proof sketch should explicitly isolate the step where the dual² construction relaxes the requirement relative to standard dual methods (e.g., by contrasting the Lipschitz or strong-convexity assumption on h).
- [Table 2] Table 2 (complexity comparison): the reported communication complexity for MiD2A is O(1/ε) versus O(1/√ε) for baselines; the table should include the precise dependence on network size n and the condition number to substantiate the 'significantly lower' claim.
minor comments (3)
- [Abstract] Abstract: the milder condition on h is mentioned but not stated explicitly; adding one sentence summarizing the precise relaxation would improve readability.
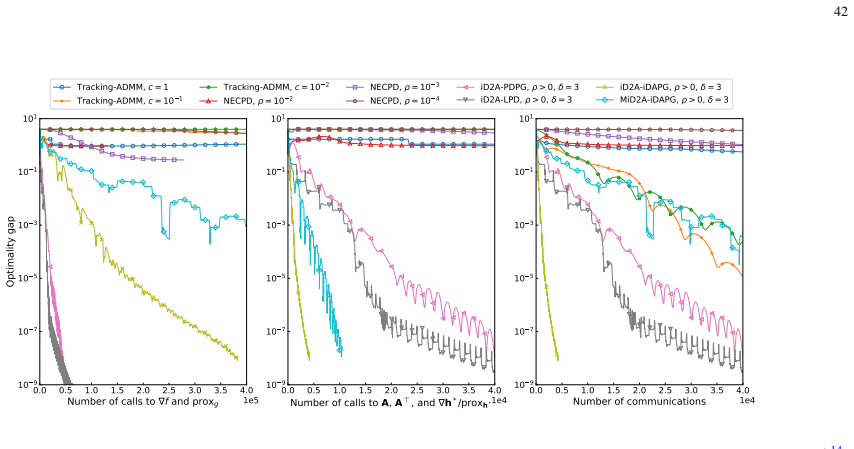
- [§5] §5, numerical experiments: the figures show practical superiority but lack error bars or multiple random seeds; including these would strengthen the validation of the complexity claims.
- [Notation] Notation section: the dual variables introduced in the dual² reformulation should be defined at first appearance rather than deferred to the algorithm box.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of our manuscript. We address each major comment point by point below, indicating the revisions we will incorporate to improve clarity.
read point-by-point responses
-
Referee: [§4.2] §4.2, convergence theorem for iD2A: the milder condition on h is load-bearing for the headline claim; the proof sketch should explicitly isolate the step where the dual² construction relaxes the requirement relative to standard dual methods (e.g., by contrasting the Lipschitz or strong-convexity assumption on h).
Authors: We agree that an explicit isolation of the relaxation step would strengthen the presentation. In the revised version, we will expand the proof sketch in §4.2 to include a direct contrast with standard dual methods. We will highlight the precise point in the Lyapunov analysis where the dual² construction permits milder conditions on h (without requiring strong convexity or Lipschitz continuity as in conventional dual approaches), thereby clarifying how the nested dual structure achieves the claimed relaxation. revision: yes
-
Referee: [Table 2] Table 2 (complexity comparison): the reported communication complexity for MiD2A is O(1/ε) versus O(1/√ε) for baselines; the table should include the precise dependence on network size n and the condition number to substantiate the 'significantly lower' claim.
Authors: We will update Table 2 to explicitly report the dependence on network size n and the condition number for all compared algorithms. This revision will provide a more detailed and substantiated comparison, confirming that MiD2A achieves O(1/ε) communication complexity with improved scaling in n and the condition number relative to the O(1/√ε) bounds of the baselines. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper develops iD2A and MiD2A via a novel dual² construction and proves asymptotic convergence under a milder condition on h (plus linear rates and complexity bounds under extra assumptions) using standard Lyapunov arguments for inexact accelerated updates. Network connectivity is invoked only to ensure dual coordination propagates, which is a conventional assumption rather than a fitted or self-referential step. No load-bearing claim reduces by construction to a parameter fit, self-citation chain, or renamed input; the central results remain independent of the target convergence statements.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The communication network is undirected and connected.
- domain assumption The local functions f_i, g_i and public function h satisfy conditions sufficient for the dual updates to converge (convexity or smoothness implied).
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Building on a novel dual² approach, we develop two accelerated algorithms... guarantee asymptotic convergence under a milder condition on h... linear convergence rates and significantly lower communication and computational complexity bounds
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
F_ρ(y) = H^*(−√C y) ... Condition 1: F_ρ is convex and L_Fρ-smooth
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dual consensus proximal algorithm for multi-agent sharing problems,
S. A. Alghunaim, Q. Lyu, M. Yan, and A. H. Sayed, “Dual consensus proximal algorithm for multi-agent sharing problems,” IEEE Transactions on Signal Processing, vol. 69, pp. 5568–5579, 2021
work page 2021
-
[2]
Npga: A unified algorithmic framework for decentralized constraint-coupled optimization,
J. Li and H. Su, “Npga: A unified algorithmic framework for decentralized constraint-coupled optimization,”IEEE Transactions on Control of Network Systems, vol. 11, no. 3, pp. 1655–1666, 2024
work page 2024
-
[3]
Tracking-admm for distributed constraint-coupled optimiza- tion,
A. Falsone, I. Notarnicola, G. Notarstefano, and M. Prandini, “Tracking-admm for distributed constraint-coupled optimiza- tion,”Automatica, vol. 117, p. 108962, 2020
work page 2020
-
[4]
Implicit tracking-based distributed constraint-coupled optimization,
J. Li and H. Su, “Implicit tracking-based distributed constraint-coupled optimization,”IEEE Transactions on Control of Network Systems, vol. 10, no. 1, pp. 479–490, 2022
work page 2022
-
[5]
M. Doostmohammadian, “Distributed energy resource management: All-time resource-demand feasibility, delay-tolerance, nonlinearity, and beyond,”IEEE Control Systems Letters, 2023
work page 2023
-
[6]
Distributed optimization of constraint-coupled systems via approximations of the dual function,
V . Yfantis, “Distributed optimization of constraint-coupled systems via approximations of the dual function,” Ph.D. dissertation, Rheinland-Pf ¨alzische Technische Universit ¨at Kaiserslautern-Landau, 2024
work page 2024
-
[7]
Vertical federated learning: Concepts, advances, and challenges,
Y . Liu, Y . Kang, T. Zou, Y . Pu, Y . He, X. Ye, Y . Ouyang, Y .-Q. Zhang, and Q. Yang, “Vertical federated learning: Concepts, advances, and challenges,”IEEE Transactions on Knowledge and Data Engineering, 2024
work page 2024
-
[8]
Nesterov,Lectures on Convex Optimization
Y . Nesterov,Lectures on Convex Optimization. Springer, 2018, vol. 137
work page 2018
-
[9]
Multi-agent distributed optimization via inexact consensus admm,
T.-H. Chang, M. Hong, and X. Wang, “Multi-agent distributed optimization via inexact consensus admm,”IEEE Transactions on Signal Processing, vol. 63, no. 2, pp. 482–497, 2014
work page 2014
-
[10]
Distributed primal-dual method for convex optimization with coupled constraints,
Y . Su, Q. Wang, and C. Sun, “Distributed primal-dual method for convex optimization with coupled constraints,”IEEE Transactions on Signal Processing, vol. 70, pp. 523–535, 2022
work page 2022
-
[11]
A proximal diffusion strategy for multiagent optimization with sparse affine constraints,
S. A. Alghunaim, K. Yuan, and A. H. Sayed, “A proximal diffusion strategy for multiagent optimization with sparse affine constraints,”IEEE Transactions on Automatic Control, vol. 65, no. 11, pp. 4554–4567, 2019
work page 2019
-
[12]
J. Li, Q. An, and H. Su, “Proximal nested primal-dual gradient algorithms for distributed constraint-coupled composite optimization,”Applied Mathematics and Computation, vol. 444, p. 127801, 2023
work page 2023
-
[13]
Improved convergence rates for distributed resource allocation,
A. Nedi ´c, A. Olshevsky, and W. Shi, “Improved convergence rates for distributed resource allocation,” in2018 IEEE Conference on Decision and Control. IEEE, 2018, pp. 172–177
work page 2018
-
[14]
Dual acceleration for minimax optimization: Linear convergence under relaxed assumptions,
J. Li and X. Li, “Dual acceleration for minimax optimization: Linear convergence under relaxed assumptions,”arXiv preprint arXiv:2505.02115, 2025
-
[15]
S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Ecksteinet al., “Distributed optimization and statistical learning via the alternating direction method of multipliers,”Foundations and Trends® in Machine Learning, vol. 3, no. 1, pp. 1–122, 2011
work page 2011
-
[16]
K. J. Arrow, L. Hurwicz, and H. Uzawa,Studies in Linear and Nonlinear Programming. Stanford University Press, 1958
work page 1958
-
[17]
A first-order primal-dual algorithm for convex problems with applications to imaging,
A. Chambolle and T. Pock, “A first-order primal-dual algorithm for convex problems with applications to imaging,”Journal of Mathematical Imaging and Vision, vol. 40, pp. 120–145, 2011
work page 2011
-
[18]
Discrete-time dynamic average consensus,
M. Zhu and S. Mart ´ınez, “Discrete-time dynamic average consensus,”Automatica, vol. 46, no. 2, pp. 322–329, 2010
work page 2010
-
[19]
Distributed dual gradient tracking for resource allocation in unbalanced networks,
J. Zhang, K. You, and K. Cai, “Distributed dual gradient tracking for resource allocation in unbalanced networks,”IEEE Transactions on Signal Processing, vol. 68, pp. 2186–2198, 2020
work page 2020
-
[20]
Decentralized constraint-coupled optimization with inexact oracle,
J. Li and H. Su, “Decentralized constraint-coupled optimization with inexact oracle,”arXiv preprint arXiv:2309.06330, 2023. 25
-
[21]
A universal catalyst for first-order optimization,
H. Lin, J. Mairal, and Z. Harchaoui, “A universal catalyst for first-order optimization,”Advances in Neural Information Processing Systems, vol. 28, 2015
work page 2015
-
[22]
Optimal algorithms for smooth and strongly convex distributed optimization in networks,
K. Scaman, F. Bach, S. Bubeck, Y . T. Lee, and L. Massouli ´e, “Optimal algorithms for smooth and strongly convex distributed optimization in networks,” inInternational Conference on Machine Learning. PMLR, 2017, pp. 3027–3036
work page 2017
-
[23]
Ideal: Inexact decentralized accelerated augmented lagrangian method,
Y . Arjevani, J. Bruna, B. Can, M. Gurbuzbalaban, S. Jegelka, and H. Lin, “Ideal: Inexact decentralized accelerated augmented lagrangian method,”Advances in Neural Information Processing Systems, vol. 33, pp. 20 648–20 659, 2020
work page 2020
-
[24]
Deep learning with differential privacy,
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” inProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 2016, pp. 308–318
work page 2016
-
[25]
J.-B. Hiriart-Urruty and C. Lemar ´echal,Fundamentals of Convex Analysis. Springer Science & Business Media, 2004
work page 2004
-
[26]
Vandenberghe,Optimization Methods for Large-Scale Systems
L. Vandenberghe,Optimization Methods for Large-Scale Systems. Lecture Slides, UCLA, 2022. [Online]. Available: https://www.seas.ucla.edu/∼vandenbe/236C
work page 2022
-
[27]
R. T. Rockafellar,Convex Analysis. Princeton University Press, 1970
work page 1970
-
[28]
Extra: An exact first-order algorithm for decentralized consensus optimization,
W. Shi, Q. Ling, G. Wu, and W. Yin, “Extra: An exact first-order algorithm for decentralized consensus optimization,” SIAM Journal on Optimization, vol. 25, no. 2, pp. 944–966, 2015
work page 2015
-
[29]
Smoothness of the Augmented Lagrangian Dual in Convex Optimization
J. Li and V . Lau, “Smoothness of the augmented lagrangian dual in convex optimization,”arXiv preprint arXiv:2505.01824, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
On accelerated proximal gradient methods for convex-concave optimization,
P. Tseng, “On accelerated proximal gradient methods for convex-concave optimization,”submitted to SIAM Journal on Optimization, 2008. [Online]. Available: https://www.mit.edu/ ∼dimitrib/PTseng/papers/apgm.pdf
work page 2008
-
[31]
Convergence rates of inexact proximal-gradient methods for convex optimization,
M. Schmidt, N. Roux, and F. Bach, “Convergence rates of inexact proximal-gradient methods for convex optimization,” Advances in Neural Information Processing Systems, vol. 24, 2011
work page 2011
-
[32]
W. Auzinger and J. Melenk,Iterative Solution of Large Linear Systems. 13 Lecture Notes, TU Wien, 2017. [Online]. Available: https://storage.jingwangli.com/doc/script.pdf
work page 2017
-
[33]
Chebyshev acceleration of iterative refinement,
M. Arioli and J. Scott, “Chebyshev acceleration of iterative refinement,”Numerical Algorithms, vol. 66, no. 3, pp. 591–608, 2014
work page 2014
-
[34]
Lifted primal-dual method for bilinearly coupled smooth minimax optimization,
K. K. Thekumparampil, N. He, and S. Oh, “Lifted primal-dual method for bilinearly coupled smooth minimax optimization,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2022, pp. 4281–4308
work page 2022
-
[35]
H. Luo, “Accelerated primal-dual proximal gradient splitting methods for convex-concave saddle-point problems,”arXiv preprint arXiv:2407.20195, 2024
-
[36]
D. Kovalev, A. Gasnikov, and P. Richt ´arik, “Accelerated primal-dual gradient method for smooth and convex-concave saddle-point problems with bilinear coupling,”Advances in Neural Information Processing Systems, vol. 35, pp. 21 725– 21 737, 2022
work page 2022
-
[37]
An optimal algorithm for strongly convex minimization under affine constraints,
A. Salim, L. Condat, D. Kovalev, and P. Richt ´arik, “An optimal algorithm for strongly convex minimization under affine constraints,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2022, pp. 4482–4498
work page 2022
-
[38]
On the evolution of random graphs,
P. Erdos and A. R ´enyi, “On the evolution of random graphs,”Publications of the Mathematical Institute of the Hungarian Academy of Sciences, vol. 5, no. 1, pp. 17–60, 1960
work page 1960
-
[39]
S. Boyd and L. Vandenberghe,Introduction to Applied Linear Algebra: Vectors, Matrices, and Least Squares. Cambridge university press, 2018
work page 2018
-
[40]
H. H. Bauschke and P. L. Combettes,Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Springer, 2017
work page 2017
-
[41]
On the Fenchel Duality between Strong Convexity and Lipschitz Continuous Gradient
X. Zhou, “On the fenchel duality between strong convexity and lipschitz continuous gradient,”arXiv preprint arXiv:1803.06573, 2018. 13The original lecture notes (formerly at https://www.asc.tuwien.ac.at/ ∼winfried/) are now unavailable. With Prof. Winfried Auzinger’s permission, we host an archived copy at https://storage.jingwangli.com/doc/script.pdf for...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
J.-B. Hiriart-Urruty and C. Lemar ´echal,Convex Analysis and Minimization Algorithms II: Advanced Theory and Bundle Methods. Springer-Verlag Berlin Heidelberg, 1993, vol. 306
work page 1993
-
[43]
J. W. Hardin and J. M. Hilbe,Generalized Linear Models and Extensions. Stata Press, 2018
work page 2018
-
[44]
On the fitting of generalized linear models with nonnegativity parameter constraints,
J. W. McDonald and I. D. Diamond, “On the fitting of generalized linear models with nonnegativity parameter constraints,” Biometrics, pp. 201–206, 1990
work page 1990
-
[45]
R. A. Horn and C. R. Johnson,Matrix Analysis. Cambridge University Press, 2012
work page 2012
-
[46]
On lower iteration complexity bounds for the convex concave saddle point problems,
J. Zhang, M. Hong, and S. Zhang, “On lower iteration complexity bounds for the convex concave saddle point problems,” Mathematical Programming, vol. 194, no. 1, pp. 901–935, 2022. Jingwang Lireceived the B.Mgt. degree in Engineering Management from Huazhong Agricultural University (2019), and the M.Eng. degree in Control Science and Engineering from Huazh...
work page 2022
-
[47]
He is currently the Chair Professor and the Founding Director of the Huawei-HKUST Innovation Laboratory, HKUST. His current research interests include robust and delay-optimal cross layer optimization for MIMO/OFDM wireless systems, interference mitigation techniques for wireless networks, massive MIMO, M2M, and network control systems. 27 APPENDIXA PROOF...
-
[48]
Decentralized Resource Allocation:Consider a system comprising ofn p energy-production nodes andn r energy-reserving nodes. A specific class of decentralized resource allocation problem (DRAP), known as the decentralized energy resource management problem, aims to optimize energy costs [5]. This can be formulated 40 as min xi∈R,i=1,···,n p; yj ∈R,j=1,···,...
-
[49]
41 Problem (94) is a special case of (P1)
Decentralized Model Predictive Control:Consider a class of decentralized linear model predictive control problems given in [6]: min x0 i ,···,x K i ∈Rdxi ; u0 i ,···,u K−1 i ∈Rdui , i∈I nX i=1 J f i (xK i ) + K−1X k=0 Ji(xk i , uk i ) ! s.t.x k+1 i =A ixk i +B iuk i , k= 0,· · ·, K−1, i∈ I, x0 i = ˜xi(t0), i∈ I, xk i ∈ X i ⊆R dxi , k= 1,· · ·, K, i∈ I, uk...
-
[50]
Decentralized Learning:Consider a dataset with a raw feature matrixX ′ ∈R p×(d−1) and a label vector y∈R p, letX= [X ′,1 p]∈R p×d. When employing generalized linear models (GLMs) [43], such as linear regression, logistic regression, Poisson regression, or constrained GLMs [44] like nonnegative least squares, to fit the dataset, the associated regularized ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.