DR-SAC: Distributionally Robust Soft Actor-Critic for Reinforcement Learning under Uncertainty
Pith reviewed 2026-05-19 09:06 UTC · model grok-4.3
The pith
DR-SAC extends actor-critic methods to distributionally robust offline RL in continuous spaces by optimizing against worst-case transitions in a KL ball.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DR-SAC maximizes the entropy-regularized rewards against the worst possible transition models within a KL-divergence constrained uncertainty set. The algorithm derives the distributionally robust version of soft policy iteration, proves its convergence, and uses generative modeling to estimate the unknown nominal transition model. This construction enables the first actor-critic DR-RL method that operates in continuous action spaces for offline learning.
What carries the argument
Distributionally robust soft policy iteration, which replaces standard expectation over transitions with a worst-case optimization inside the KL ball around the nominal model.
If this is right
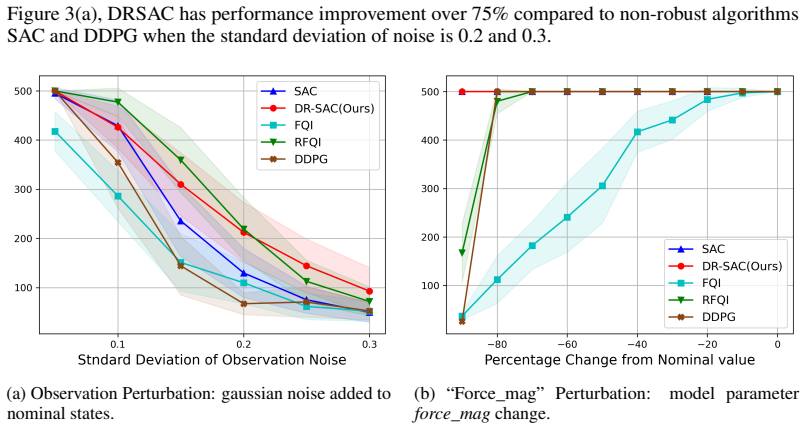
- DR-SAC achieves up to 9.8 times higher average reward than the SAC baseline under common perturbations.
- DR-SAC improves computing efficiency and applicability to large-scale problems relative to prior DR-RL algorithms.
- The method supplies a convergence guarantee for its distributionally robust soft policy iteration.
- It supports offline learning directly in continuous action spaces.
Where Pith is reading between the lines
- If the nominal model is estimated well from offline data, the approach could narrow the gap between simulated training and real-world execution in robotics.
- The KL-ball construction might be combined with other base RL algorithms to test whether the robustness gain is specific to the soft actor-critic objective.
- Structured uncertainties such as sensor bias or actuator wear could be used to check whether the current uncertainty set remains sufficiently expressive.
Load-bearing premise
The generative modeling step must produce a nominal transition model accurate enough that the KL ball around it covers the uncertainty actually met at deployment.
What would settle it
If DR-SAC is applied to a continuous control task whose true perturbations lie outside the estimated KL ball and it then fails to outperform plain SAC, the robustness benefit would be falsified.
Figures






read the original abstract
Deep reinforcement learning (RL) has achieved remarkable success, yet its deployment in real-world scenarios is often limited by vulnerability to environmental uncertainties. Distributionally robust RL (DR-RL) algorithms have been proposed to resolve this challenge, but existing approaches are largely restricted to value-based methods in tabular settings. In this work, we introduce Distributionally Robust Soft Actor-Critic (DR-SAC), the first actor-critic based DR-RL algorithm for offline learning in continuous action spaces. DR-SAC maximizes the entropy-regularized rewards against the worst possible transition models within an KL-divergence constrained uncertainty set. We derive the distributionally robust version of the soft policy iteration with a convergence guarantee and incorporate a generative modeling approach to estimate the unknown nominal transition models. Experiment results on five continuous RL tasks demonstrate our algorithm achieves up to 9.8 times higher average reward than the SAC baseline under common perturbations. Additionally, DR-SAC significantly improves computing efficiency and applicability to large-scale problems compared with existing DR-RL algorithms. Code is publicly available at github.com/Lemutisme/DR-SAC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Distributionally Robust Soft Actor-Critic (DR-SAC), the first actor-critic DR-RL method for offline learning in continuous action spaces. It extends soft actor-critic by maximizing entropy-regularized rewards against worst-case transition models inside a KL-divergence ball around a nominal transition kernel estimated via generative modeling. The authors derive a distributionally robust version of soft policy iteration with a claimed convergence guarantee, and report up to 9.8 times higher average reward than SAC on five continuous control tasks under common perturbations, along with improved computational efficiency over prior DR-RL algorithms.
Significance. If the convergence guarantee holds and the generative modeling step reliably places the true deployment dynamics inside the KL-ball, the work would be significant for extending distributionally robust RL to practical continuous-control settings where actor-critic methods dominate. The public code release and empirical evaluation on five tasks under perturbations are positive features that support reproducibility and applicability claims. However, the significance is tempered by the lack of explicit verification that the estimated nominal model satisfies the coverage condition required for the robustness guarantee to translate to real uncertainty.
major comments (2)
- The central robustness claim rests on the generative modeling step producing a nominal transition estimate P̂ such that the true (unknown) dynamics P* lie inside the KL-ball B(P̂, ε) for the chosen radius. The manuscript reports gains under 'common perturbations' but provides no quantitative diagnostic (e.g., estimated KL distance between P̂ and held-out perturbed trajectories, or sensitivity analysis over ε) confirming that condition (i) in the skeptic note holds. Without this check, the observed improvement could be an artifact of the particular test perturbations rather than a consequence of the distributionally robust objective.
- The derivation of the distributionally robust soft policy iteration is presented as a direct extension that yields a convergence guarantee. However, the manuscript does not show that the resulting robust Bellman operator is a contraction (or satisfies the conditions for the guarantee) independently of the specific generative model; the circularity concern that the construction reduces to a fitted parameter by the paper's own equations remains unaddressed in the provided theoretical section.
minor comments (2)
- The abstract states 'up to 9.8 times higher average reward' but the experimental section should clarify whether this is the maximum over tasks or an average, and include standard errors or statistical significance tests across the five environments.
- Notation for the uncertainty set radius ε and the generative model training procedure should be introduced earlier and used consistently when describing how the nominal kernel is obtained from offline data.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the presentation of our results and theory.
read point-by-point responses
-
Referee: The central robustness claim rests on the generative modeling step producing a nominal transition estimate P̂ such that the true (unknown) dynamics P* lie inside the KL-ball B(P̂, ε) for the chosen radius. The manuscript reports gains under 'common perturbations' but provides no quantitative diagnostic (e.g., estimated KL distance between P̂ and held-out perturbed trajectories, or sensitivity analysis over ε) confirming that condition (i) in the skeptic note holds. Without this check, the observed improvement could be an artifact of the particular test perturbations rather than a consequence of the distributionally robust objective.
Authors: We agree that explicit verification of the coverage condition would strengthen the robustness claims. In the revised manuscript we will add a new subsection with quantitative diagnostics: estimated KL distances between the learned nominal model and held-out trajectories collected under the perturbed dynamics, together with a sensitivity analysis of performance across a range of ε values. These additions will directly address whether the true dynamics lie inside the uncertainty set for the radii used in our experiments. revision: yes
-
Referee: The derivation of the distributionally robust soft policy iteration is presented as a direct extension that yields a convergence guarantee. However, the manuscript does not show that the resulting robust Bellman operator is a contraction (or satisfies the conditions for the guarantee) independently of the specific generative model; the circularity concern that the construction reduces to a fitted parameter by the paper's own equations remains unaddressed in the provided theoretical section.
Authors: We thank the referee for this observation. The convergence proof for the robust soft policy iteration appears in the appendix and establishes that the robust Bellman operator is a contraction under the standard assumptions on the entropy-regularized objective and the KL-ball uncertainty set. The contraction property holds for any nominal kernel inside the ball and does not rely on the particular generative model used to estimate that kernel. To eliminate any appearance of circularity we will add a short clarifying paragraph in Section 4 that explicitly states the independence from the generative-model details and references the relevant steps in the appendix proof. revision: yes
Circularity Check
Derivation of robust soft policy iteration presented as extension; no reduction to fitted inputs or self-citation chains
full rationale
The paper derives a distributionally robust variant of soft policy iteration from the standard SAC framework and incorporates a separate generative modeling step to estimate the nominal transition kernel before applying the KL-ball. No equation in the provided abstract or skeptic analysis shows a claimed prediction or first-principles result that algebraically equals a fitted parameter or prior self-citation by construction. The generative modeling step is an input to the robust objective rather than a tautological output. This yields a self-contained derivation chain against external benchmarks such as standard SAC, with only minor self-citation risk at the level of the base algorithm.
Axiom & Free-Parameter Ledger
free parameters (1)
- KL-ball radius
axioms (2)
- standard math Soft policy iteration converges to an optimal policy under standard entropy-regularized MDP assumptions.
- domain assumption The nominal transition model can be estimated from offline data via generative modeling.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DR-SAC maximizes the entropy-regularized rewards against the worst possible transition models within a KL-divergence constrained uncertainty set... derive the distributionally robust version of the soft policy iteration... incorporate a generative modeling approach to estimate the unknown nominal transition models.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We utilize the interchange property to reformulate the optimization problem within the KL-constrained uncertainty set into functional optimization.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
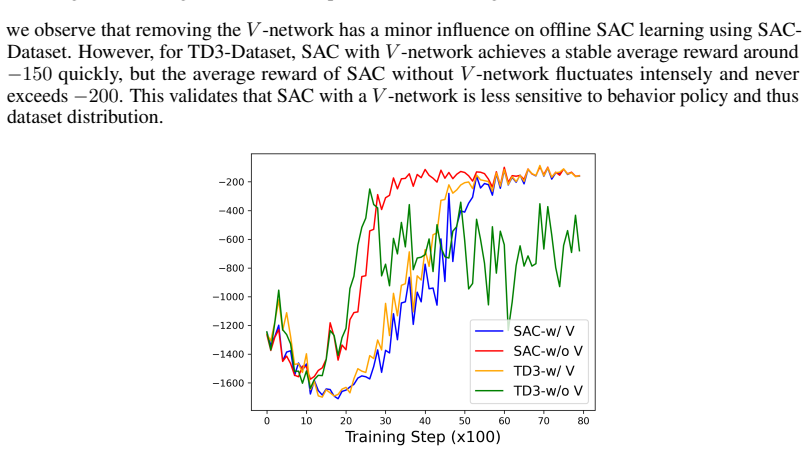
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gaon An, Seungyong Moon, Jang-Hyun Kim, and Hyun Oh Song. Uncertainty-based offline reinforcement learning with diversified q-ensemble.Advances in neural information processing systems, 34:7436–7447, 2021
work page 2021
-
[2]
Deep reinforcement learning: A brief survey.IEEE Signal Processing Magazine, 34(6):26–38, 2017
Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath. Deep reinforcement learning: A brief survey.IEEE Signal Processing Magazine, 34(6):26–38, 2017
work page 2017
-
[3]
Jiayu Chen, Bhargav Ganguly, Yang Xu, Yongsheng Mei, Tian Lan, and Vaneet Aggarwal. Deep generative models for offline policy learning: Tutorial, survey, and perspectives on future directions.arXiv preprint arXiv:2402.13777, 2024
-
[4]
Corrected soft actor critic for continuous control.arXiv preprint arXiv:2410.16739, 2024
Yanjun Chen, Xinming Zhang, Xianghui Wang, Zhiqiang Xu, Xiaoyu Shen, and Wei Zhang. Corrected soft actor critic for continuous control.arXiv preprint arXiv:2410.16739, 2024
-
[5]
Adversarially trained actor critic for offline reinforcement learning
Ching-An Cheng, Tengyang Xie, Nan Jiang, and Alekh Agarwal. Adversarially trained actor critic for offline reinforcement learning. InInternational Conference on Machine Learning, pages 3852–3878. PMLR, 2022
work page 2022
-
[6]
Pierre Clavier, Erwan Le Pennec, and Matthieu Geist. Towards minimax optimality of model- based robust reinforcement learning.arXiv preprint arXiv:2302.05372, 2023
-
[7]
Soft-Robust Actor-Critic Policy-Gradient
Esther Derman, Daniel J Mankowitz, Timothy A Mann, and Shie Mannor. Soft-robust actor- critic policy-gradient.arXiv preprint arXiv:1803.04848, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Esther Derman and Shie Mannor. Distributional robustness and regularization in reinforcement learning.arXiv preprint arXiv:2003.02894, 2020
-
[9]
Tobias Enders, James Harrison, and Maximilian Schiffer. Risk-sensitive soft actor-critic for robust deep reinforcement learning under distribution shifts.arXiv preprint arXiv:2402.09992, 2024
-
[10]
Vincent Francois-Lavet, Peter Henderson, Riashat Islam, Marc G Bellemare, Joelle Pineau, et al. An introduction to deep reinforcement learning.Foundations and Trends® in Machine Learning, 11(3-4):219–354, 2018
work page 2018
-
[11]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational Conference on Machine Learning, pages 1582–1591, 2018
work page 2018
-
[12]
Off-policy deep reinforcement learning without exploration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. InInternational conference on machine learning, pages 2052–2062. PMLR, 2019
work page 2052
-
[13]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
work page 2018
-
[14]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and applications.arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Risk-sensitive markov decision processes.Manage- ment science, 18(7):356–369, 1972
Ronald A Howard and James E Matheson. Risk-sensitive markov decision processes.Manage- ment science, 18(7):356–369, 1972
work page 1972
-
[16]
Zhaolin Hu and L Jeff Hong. Kullback-leibler divergence constrained distributionally robust optimization.Available at Optimization Online, 1(2):9, 2013
work page 2013
-
[17]
Garud N. Iyengar. Robust dynamic programming.Mathematics of Operations Research, 30(2):257–280, 2005
work page 2005
-
[18]
David Jacobson. Optimal stochastic linear systems with exponential performance criteria and their relation to deterministic differential games.IEEE Transactions on Automatic control, 18(2):124–131, 1973. 10
work page 1973
-
[19]
Auto-encoding variational bayes, 2013
Diederik P Kingma, Max Welling, et al. Auto-encoding variational bayes, 2013
work page 2013
-
[20]
Arash Bahari Kordabad, Rafael Wisniewski, and Sebastien Gros. Safe reinforcement learning using wasserstein distributionally robust mpc and chance constraint.IEEE Access, 10:130058– 130067, 2022
work page 2022
-
[21]
Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off- policy q-learning via bootstrapping error reduction.Advances in neural information processing systems, 32, 2019
work page 2019
-
[22]
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning.Advances in neural information processing systems, 33:1179– 1191, 2020
work page 2020
-
[23]
Single- trajectory distributionally robust reinforcement learning, 2024
Zhipeng Liang, Xiaoteng Ma, Jose Blanchet, Jiheng Zhang, and Zhengyuan Zhou. Single- trajectory distributionally robust reinforcement learning, 2024
work page 2024
-
[24]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Zhishuai Liu and Pan Xu. Minimax optimal and computationally efficient algorithms for distributionally robust offline reinforcement learning.arXiv preprint arXiv:2403.09621, 2024
-
[26]
Distributionally robust q-learning
Zijian Liu, Qinxun Bai, Jose Blanchet, Perry Dong, Wei Xu, Zhengqing Zhou, and Zhengyuan Zhou. Distributionally robust q-learning. InInternational Conference on Machine Learning, pages 13623–13643. PMLR, 2022
work page 2022
-
[27]
Soft-robust algorithms for batch reinforcement learning.arXiv preprint arXiv:2011.14495, 2020
Elita A Lobo, Mohammad Ghavamzadeh, and Marek Petrik. Soft-robust algorithms for batch reinforcement learning.arXiv preprint arXiv:2011.14495, 2020
-
[28]
Miao Lu, Han Zhong, Tong Zhang, and Jose Blanchet. Distributionally robust reinforcement learning with interactive data collection: Fundamental hardness and near-optimal algorithm. arXiv preprint arXiv:2404.03578, 2024
-
[29]
Jiafei Lyu, Xiaoteng Ma, Xiu Li, and Zongqing Lu. Mildly conservative q-learning for offline reinforcement learning.Advances in Neural Information Processing Systems, 35:1711–1724, 2022
work page 2022
-
[30]
Distributionally robust offline reinforcement learning with linear function approximation, 2023
Xiaoteng Ma, Zhipeng Liang, Jose Blanchet, Mingwen Liu, Li Xia, Jiheng Zhang, Qianchuan Zhao, and Zhengyuan Zhou. Distributionally robust offline reinforcement learning with linear function approximation, 2023
work page 2023
-
[31]
Daniel J Mankowitz, Nir Levine, Rae Jeong, Yuanyuan Shi, Jackie Kay, Abbas Abdolmaleki, Jost Tobias Springenberg, Timothy Mann, Todd Hester, and Martin Riedmiller. Robust re- inforcement learning for continuous control with model misspecification.arXiv preprint arXiv:1906.07516, 2019
-
[32]
Viraj Mehta, Biswajit Paria, Jeff Schneider, Stefano Ermon, and Willie Neiswanger. An experimental design perspective on model-based reinforcement learning.arXiv preprint arXiv:2112.05244, 2021
-
[33]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
work page 2015
-
[34]
Arnab Nilim and Laurent El Ghaoui. Robust control of markov decision processes with uncertain transition matrices.Operations Research, 53(5):780–798, 2005
work page 2005
-
[35]
Risk averse robust adversarial reinforce- ment learning
Xinlei Pan, Daniel Seita, Yang Gao, and John Canny. Risk averse robust adversarial reinforce- ment learning. In2019 International Conference on Robotics and Automation (ICRA), pages 8522–8528. IEEE, 2019. 11
work page 2019
-
[36]
Sample complexity of robust reinforcement learning with a generative model
Kishan Panaganti and Dileep Kalathil. Sample complexity of robust reinforcement learning with a generative model. InInternational Conference on Artificial Intelligence and Statistics, pages 9582–9602. PMLR, 2022
work page 2022
-
[37]
Robust rein- forcement learning using offline data
Kishan Panaganti, Zaiyan Xu, Dileep Kalathil, and Mohammad Ghavamzadeh. Robust rein- forcement learning using offline data. InAdvances in Neural Information Processing Systems, volume 35, pages 32211–32224. Curran Associates, Inc., 2022
work page 2022
-
[38]
Robust adversarial reinforcement learning
Lerrel Pinto, James Davidson, Rahul Sukthankar, and Abhinav Gupta. Robust adversarial reinforcement learning. InInternational conference on machine learning, pages 2817–2826. PMLR, 2017
work page 2017
-
[39]
James Queeney and Mouhacine Benosman. Risk-averse model uncertainty for distributionally robust safe reinforcement learning.Advances in Neural Information Processing Systems, 36:1659–1680, 2023
work page 2023
-
[40]
Distributionally robust model-based reinforcement learning with large state spaces
Shyam Sundhar Ramesh, Pier Giuseppe Sessa, Yifan Hu, Andreas Krause, and Ilija Bogunovic. Distributionally robust model-based reinforcement learning with large state spaces. InInterna- tional Conference on Artificial Intelligence and Statistics, pages 100–108. PMLR, 2024
work page 2024
-
[41]
Konrad Rawlik, Marc Toussaint, and Sethu Vijayakumar. On stochastic optimal control and reinforcement learning by approximate inference.Proceedings of Robotics: Science and Systems VIII, 2012
work page 2012
-
[42]
Springer Science & Business Media, 2009
R Tyrrell Rockafellar and Roger J-B Wets.Variational analysis, volume 317. Springer Science & Business Media, 2009
work page 2009
-
[43]
Takuma Seno and Michita Imai. d3rlpy: An offline deep reinforcement learning library.Journal of Machine Learning Research, 23(315):1–20, 2022
work page 2022
-
[44]
Distributionally robust stochastic programming.SIAM Journal on Opti- mization, 27(4):2258–2275, 2017
Alexander Shapiro. Distributionally robust stochastic programming.SIAM Journal on Opti- mization, 27(4):2258–2275, 2017
work page 2017
-
[45]
Laixi Shi and Yuejie Chi. Distributionally robust model-based offline reinforcement learning with near-optimal sample complexity.Journal of Machine Learning Research, 25(200):1–91, 2024
work page 2024
-
[46]
Improving robustness via risk averse distributional reinforcement learning
Rahul Singh, Qinsheng Zhang, and Yongxin Chen. Improving robustness via risk averse distributional reinforcement learning. InLearning for Dynamics and Control, pages 958–968. PMLR, 2020
work page 2020
-
[47]
Distributionally Robust Reinforcement Learning
Elena Smirnova, Elvis Dohmatob, and Jérémie Mary. Distributionally robust reinforcement learning.arXiv preprint arXiv:1902.08708, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[48]
Aviv Tamar, Yinlam Chow, Mohammad Ghavamzadeh, and Shie Mannor. Policy gradient for coherent risk measures.Advances in neural information processing systems, 28, 2015
work page 2015
-
[49]
General duality between optimal control and estimation
Emanuel Todorov. General duality between optimal control and estimation. In2008 47th IEEE conference on decision and control, pages 4286–4292. IEEE, 2008
work page 2008
-
[50]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE, 2012
work page 2012
-
[51]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goulão, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. Gymnasium: A standard interface for reinforcement learning environments.arXiv preprint arXiv:2407.17032, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Stable reinforcement learning with autoencoders for tactile and visual data
Herke Van Hoof, Nutan Chen, Maximilian Karl, Patrick Van Der Smagt, and Jan Peters. Stable reinforcement learning with autoencoders for tactile and visual data. In2016 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 3928–3934. IEEE, 2016. 12
work page 2016
-
[53]
A finite sample complexity bound for distributionally robust q-learning
Shengbo Wang, Nian Si, Jose Blanchet, and Zhengyuan Zhou. A finite sample complexity bound for distributionally robust q-learning. InProceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 ofProceedings of Machine Learning Research, pages 3370–3398. PMLR, 2023
work page 2023
-
[54]
Shengbo Wang, Nian Si, Jose Blanchet, and Zhengyuan Zhou. Sample complexity of variance- reduced distributionally robust q-learning.Journal of Machine Learning Research, 25(341):1– 77, 2024
work page 2024
-
[55]
Online robust reinforcement learning with model uncertainty
Yue Wang and Shaofeng Zou. Online robust reinforcement learning with model uncertainty. Advances in Neural Information Processing Systems, 34:7193–7206, 2021
work page 2021
-
[56]
Hua Wei, Deheng Ye, Zhao Liu, Hao Wu, Bo Yuan, Qiang Fu, Wei Yang, and Zhenhui Li. Boosting offline reinforcement learning with residual generative modeling.arXiv preprint arXiv:2106.10411, 2021
-
[57]
Peter Whittle. Risk-sensitive linear/quadratic/gaussian control.Advances in Applied Probability, 13(4):764–777, 1981
work page 1981
-
[58]
Robust markov decision processes
Wolfram Wiesemann, Daniel Kuhn, and Berc Rustem. Robust markov decision processes. Mathematics of Operations Research, 38(1):153–183, 2013
work page 2013
-
[59]
Constraints penalized q-learning for safe offline reinforcement learning
Haoran Xu, Xianyuan Zhan, and Xiangyu Zhu. Constraints penalized q-learning for safe offline reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 8753–8760, 2022
work page 2022
-
[60]
Huan Xu and Shie Mannor. Distributionally robust markov decision processes.Advances in Neural Information Processing Systems, 23, 2010
work page 2010
-
[61]
Improved sample complexity bounds for distributionally robust reinforcement learning
Zaiyan Xu, Kishan Panaganti, and Dileep Kalathil. Improved sample complexity bounds for distributionally robust reinforcement learning. InProceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 ofProceedings of Machine Learning Research, pages 9728–9754. PMLR, 2023
work page 2023
-
[62]
Distributionally robust counterpart in markov decision processes
Pengqian Yu and Huan Xu. Distributionally robust counterpart in markov decision processes. IEEE Transactions on Automatic Control, 61(9):2538–2543, 2015
work page 2015
-
[63]
Huan Zhang, Hongge Chen, Chaowei Xiao, Bo Li, Mingyan Liu, Duane Boning, and Cho- Jui Hsieh. Robust deep reinforcement learning against adversarial perturbations on state observations.Advances in Neural Information Processing Systems, 33:21024–21037, 2020
work page 2020
-
[64]
Ruida Zhou, Tao Liu, Min Cheng, Dileep Kalathil, PR Kumar, and Chao Tian. Natural actor- critic for robust reinforcement learning with function approximation.Advances in neural information processing systems, 36:97–133, 2023
work page 2023
-
[65]
Finite-sample regret bound for distributionally robust offline tabular reinforcement learning
Zhengqing Zhou, Zhengyuan Zhou, Qinxun Bai, Linhai Qiu, Jose Blanchet, and Peter Glynn. Finite-sample regret bound for distributionally robust offline tabular reinforcement learning. In International Conference on Artificial Intelligence and Statistics, pages 3331–3339. PMLR, 2021
work page 2021
-
[66]
Zhengyuan Zhou, Michael Bloem, and Nicholas Bambos. Infinite time horizon maximum causal entropy inverse reinforcement learning.IEEE Transactions on Automatic Control, 63(9):2787–2802, 2018
work page 2018
-
[67]
Carnegie Mellon University, 2010
Brian D Ziebart.Modeling purposeful adaptive behavior with the principle of maximum causal entropy. Carnegie Mellon University, 2010
work page 2010
-
[68]
Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, Anind K Dey, et al. Maximum entropy inverse reinforcement learning. InAaai, volume 8, pages 1433–1438. Chicago, IL, USA, 2008. 13 Appendix Contents A Discussion 14 A.1 Necessity of V AE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 A.2 Algorithm Details . . . . . . . . . . . . . ...
work page 2008
-
[69]
or directly estimating the expected value under nominal distributions[23]. None of these methods is applicable in continuous space offline RL tasks. A.2 Algorithm Details In this section, we present a detailed description of the DR-SAC algorithm. In our algorithm, we use neural networks Vψ(s), Qθ(s, a) and πϕ(a|s) to approximate the the value function, th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.