Federated Learning for ICD Classification with Lightweight Models and Pretrained Embeddings
Pith reviewed 2026-05-22 00:51 UTC · model grok-4.3
The pith
Embedding quality outweighs classifier complexity for ICD code prediction, and federated learning matches centralized results under balanced conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Embedding quality substantially outweighs classifier complexity in determining predictive performance for multi-label ICD code classification, and federated learning can closely match centralized results in idealized conditions of even data splits and no communication failures.
What carries the argument
Frozen pretrained text embeddings paired with lightweight multilayer perceptron classifiers trained via federated averaging on distributed clinical notes.
If this is right
- Small MLP heads on strong frozen embeddings reach competitive F1 scores for both ICD-9 and ICD-10 without end-to-end fine-tuning.
- Federated averaging reproduces centralized performance when every site receives a balanced random subset of the same data distribution.
- Performance remains stable when the same pipeline is rerun on ten different stratified splits.
- Switching the embedding model changes results more than switching among the three tested MLP architectures.
Where Pith is reading between the lines
- Hospitals could pool predictive power without moving raw notes, provided future work solves uneven data volumes and differing local coding practices.
- The same lightweight pattern may transfer to other privacy-sensitive clinical tasks such as outcome prediction or billing validation.
- Adding modest local adaptation layers at each site could close remaining gaps once real-world heterogeneity is introduced.
Load-bearing premise
Data is evenly split across sites with identical label distributions and no communication failures or site-specific shifts.
What would settle it
Repeat the federated experiments on partitions with strong label imbalance or site-specific coding preferences and measure whether the performance gap to the centralized baseline widens substantially.
Figures

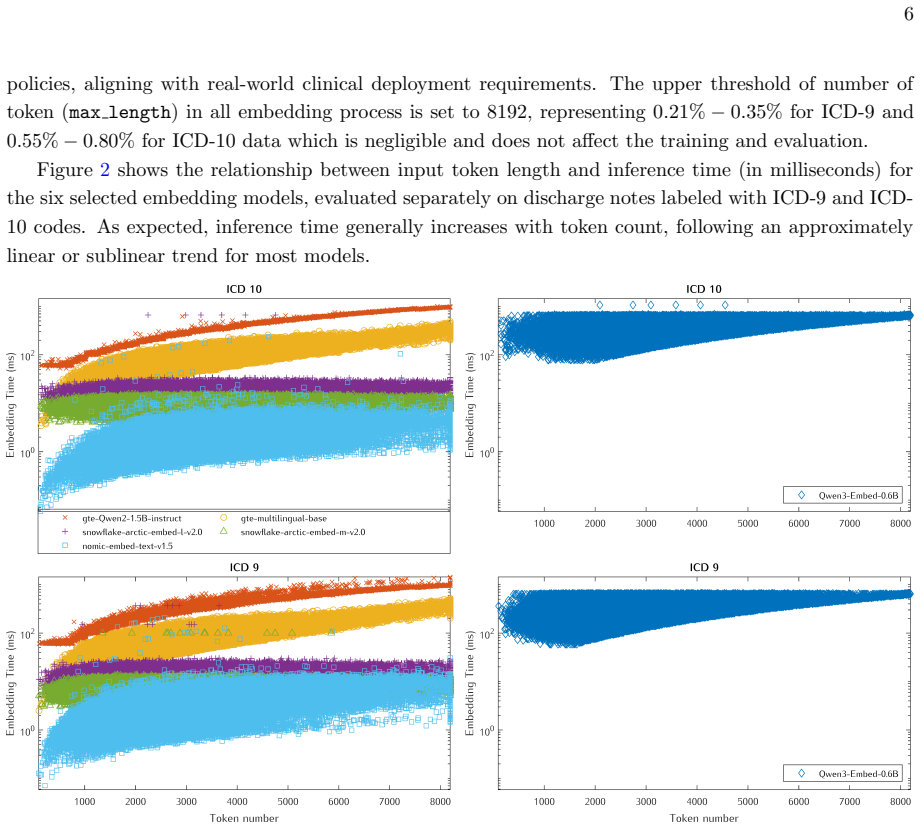


read the original abstract
This study investigates the feasibility and performance of federated learning (FL) for multi-label ICD code classification using clinical notes from the MIMIC-IV dataset. Unlike previous approaches that rely on centralized training or fine-tuned large language models, we propose a lightweight and scalable pipeline combining frozen text embeddings with simple multilayer perceptron (MLP) classifiers. This design offers a privacy-preserving and deployment-efficient alternative for clinical NLP applications, particularly suited to distributed healthcare settings. Extensive experiments across both centralized and federated configurations were conducted, testing six publicly available embedding models from Massive Text Embedding Benchmark leaderboard and three MLP classifier architectures under two medical coding (ICD-9 and ICD-10). Additionally, ablation studies over ten random stratified splits assess performance stability. Results show that embedding quality substantially outweighs classifier complexity in determining predictive performance, and that federated learning can closely match centralized results in idealized conditions. While the models are orders of magnitude smaller than state-of-the-art architectures and achieved competitive micro and macro F1 scores, limitations remain including the lack of end-to-end training and the simplified FL assumptions. Nevertheless, this work demonstrates a viable way toward scalable, privacy-conscious medical coding systems and offers a step toward for future research into federated, domain-adaptive clinical AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a lightweight federated learning pipeline for multi-label ICD code classification on MIMIC-IV clinical notes. It freezes six pretrained text embeddings from the MTEB leaderboard, pairs them with three simple MLP classifier architectures, and evaluates under both centralized and federated training for ICD-9 and ICD-10 coding across ten stratified random splits. The central claims are that embedding quality drives larger performance differences than classifier depth or width, and that idealized federated learning (even splits, no failures or label shift) can closely match centralized results while remaining orders of magnitude smaller than end-to-end LLMs.
Significance. If the empirical comparisons hold, the work supplies a practical, privacy-preserving baseline for distributed clinical coding that avoids fine-tuning large models. The ablation design directly quantifies the relative impact of embedding choice versus MLP complexity and demonstrates competitive micro/macro F1 under the stated idealized FL assumptions, which is useful for resource-constrained healthcare deployments.
major comments (3)
- [§4.2, Table 3] §4.2 and Table 3: the claim that 'embedding quality substantially outweighs classifier complexity' rests on point estimates without reported standard deviations or statistical tests across the ten splits; the largest observed gap between embeddings could be within noise for some MLP configurations.
- [§3.3] §3.3: the federated setup assumes perfectly balanced client data partitions and identical label distributions; no ablation or sensitivity experiment is shown for heterogeneous splits or label shift, which directly limits the scope of the 'closely match centralized results' conclusion.
- [§4.1] §4.1: the methods section does not specify the exact client participation rate, number of communication rounds, or aggregation details (e.g., FedAvg vs. other variants) used in the reported FL runs, making it impossible to reproduce the exact centralized-to-FL gap.
minor comments (3)
- [Figure 1, §2.2] Figure 1 caption and §2.2: clarify whether the embedding models are used in their original form or with any domain-specific preprocessing of clinical notes.
- [Table 1] Table 1: add the exact parameter counts for each of the three MLP architectures to support the 'lightweight' claim.
- [§5] §5: the limitations paragraph mentions lack of end-to-end training but does not discuss potential negative transfer when embeddings are frozen on out-of-domain clinical text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and have revised the manuscript accordingly to improve clarity, reproducibility, and the strength of our empirical claims.
read point-by-point responses
-
Referee: [§4.2, Table 3] §4.2 and Table 3: the claim that 'embedding quality substantially outweighs classifier complexity' rests on point estimates without reported standard deviations or statistical tests across the ten splits; the largest observed gap between embeddings could be within noise for some MLP configurations.
Authors: We agree that reporting variability strengthens the claim. In the revised manuscript we will update Table 3 to show mean and standard deviation of micro- and macro-F1 across the ten stratified splits for every embedding–MLP pair. While we did not conduct formal pairwise statistical tests, the consistent ranking of embeddings across all splits and classifier depths supports the conclusion that embedding quality produces larger and more stable differences than changes in MLP width or depth. The added statistics will allow readers to judge whether observed gaps exceed observed variability. revision: yes
-
Referee: [§3.3] §3.3: the federated setup assumes perfectly balanced client data partitions and identical label distributions; no ablation or sensitivity experiment is shown for heterogeneous splits or label shift, which directly limits the scope of the 'closely match centralized results' conclusion.
Authors: Our experiments deliberately use idealized, balanced partitions to isolate the effect of the federated training procedure itself under controlled conditions. The manuscript already lists simplified FL assumptions among its limitations. We will expand the text in §3.3 and the limitations paragraph to state explicitly that the reported centralized-to-FL gaps hold only under even splits and identical label distributions, and that real-world label shift or non-IID partitions may widen the gap. We view this as a scope clarification rather than a new experimental ablation at the minor-revision stage. revision: partial
-
Referee: [§4.1] §4.1: the methods section does not specify the exact client participation rate, number of communication rounds, or aggregation details (e.g., FedAvg vs. other variants) used in the reported FL runs, making it impossible to reproduce the exact centralized-to-FL gap.
Authors: We thank the referee for noting this omission. The revised §4.1 will state that every client participates in each round (100 % participation), that training proceeds for 50 communication rounds, and that the FedAvg algorithm is used for server-side aggregation. These exact settings were employed for all federated runs reported in the paper and will now be documented for full reproducibility. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports an empirical comparison of six pretrained embeddings against three MLP architectures for multi-label ICD classification on MIMIC-IV, measuring micro/macro F1 on held-out splits across ten stratified random partitions in both centralized and federated settings. All performance numbers are obtained by direct evaluation on test data rather than by any derivation, fitting step, or self-referential prediction; the idealized FL assumptions (even splits, no failures or label shift) are explicitly scoped and listed as limitations. No equations, uniqueness theorems, or ansatzes appear, and no self-citations are invoked to justify core claims. The central finding that embedding quality dominates classifier complexity is therefore a measured experimental outcome, not a reduction to the paper's own inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- MLP hidden size and depth
- Federated round count and client participation rate
axioms (2)
- domain assumption Data can be partitioned across simulated clients without label or feature shift that would break convergence.
- domain assumption Frozen embeddings require no further gradient updates for the target task.
Reference graph
Works this paper leans on
-
[1]
International classification of diseases - icd,
World Health Organization et al., “International classification of diseases - icd,” 2009. 18
work page 2009
-
[2]
Diagnosis code assignment: models and evaluation metrics,
A. Perotte, R. Pivovarov, K. Natarajan, N. Weiskopf, F. Wood, and N. Elhadad, “Diagnosis code assignment: models and evaluation metrics,” Journal of the American Medical Informatics Association, vol. 21, pp. 231–237, 12 2013
work page 2013
-
[3]
Ehr coding with multi-scale feature attention and struc- tured knowledge graph propagation,
X. Xie, Y. Xiong, P. S. Yu, and Y. Zhu, “Ehr coding with multi-scale feature attention and struc- tured knowledge graph propagation,” in Proceedings of the 28th ACM International Conference on Information and Knowledge Management , CIKM ’19, (New York, NY, USA), p. 649–658, Associ- ation for Computing Machinery, 2019
work page 2019
-
[4]
Explainable Prediction of Medical Codes from Clinical Text
J. Mullenbach, S. Wiegreffe, J. Duke, J. Sun, and J. Eisenstein, “Explainable prediction of medical codes from clinical text,” arXiv preprint arXiv:1802.05695 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Multi-label classification of patient notes: Case study on icd code assignment.,
T. Baumel, J. Nassour-Kassis, R. Cohen, M. Elhadad, and N. Elhadad, “Multi-label classification of patient notes: Case study on icd code assignment.,” in AAAI Workshops, pp. 409–416, 2018
work page 2018
-
[6]
Automated icd-9 coding via a deep learning approach,
M. Li, Z. Fei, M. Zeng, F. Wu, Y. Li, Y. Pan, and J. Wang, “Automated icd-9 coding via a deep learning approach,” IEEE/ACM Transactions on Computational Biology and Bioinformatics, vol. 16, pp. 1193–1202, July 2019
work page 2019
-
[7]
Joint embedding of words and labels for text classification,
G. Wang, C. Li, W. Wang, Y. Zhang, D. Shen, X. Zhang, R. Henao, and L. Carin, “Joint embedding of words and labels for text classification,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (I. Gurevych and Y. Miyao, eds.), (Melbourne, Australia), pp. 2321–2331, Association for Computationa...
work page 2018
-
[8]
G. Mujtaba, L. Shuib, R. G. Raj, R. Rajandram, K. Shaikh, and M. A. Al-Garadi, “Automatic icd- 10 multi-class classification of cause of death from plaintext autopsy reports through expert-driven feature selection,” PLOS ONE, vol. 12, pp. 1–27, 02 2017
work page 2017
-
[9]
Automatic classification of diseases from free-text death certificates for real-time surveillance,
B. Koopman, S. Karimi, A. Nguyen, R. McGuire, D. Muscatello, M. Kemp, D. Truran, M. Zhang, and S. Thackway, “Automatic classification of diseases from free-text death certificates for real-time surveillance,” BMC Medical Informatics and Decision Making , vol. 15, no. 1, pp. 53–, 2015
work page 2015
-
[10]
Automatic matching of icd-10 codes to diagnoses in discharge letters,
S. Boytcheva, “Automatic matching of icd-10 codes to diagnoses in discharge letters,” inProceedings of the second workshop on biomedical natural language processing , pp. 11–18, 2011
work page 2011
-
[11]
P.-F. Chen, T.-L. He, S.-C. Lin, Y.-C. Chu, C.-T. Kuo, F. Lai, S.-M. Wang, W.-X. Zhu, K.-C. Chen, L.-C. Kuo, F.-M. Hung, Y.-C. Lin, I.-C. Tsai, C.-H. Chiu, S.-C. Chang, and C.-Y. Yang, “Training a deep contextualized language model for international classification of diseases, 10th revision classification via federated learning: Model development and vali...
work page 2022
-
[12]
PLM-ICD: Automatic ICD coding with pretrained lan- guage models,
C.-W. Huang, S.-C. Tsai, and Y.-N. Chen, “PLM-ICD: Automatic ICD coding with pretrained lan- guage models,” in Proceedings of the 4th Clinical Natural Language Processing Workshop (T. Nau- mann, S. Bethard, K. Roberts, and A. Rumshisky, eds.), (Seattle, WA), pp. 10–20, Association for Computational Linguistics, July 2022
work page 2022
-
[13]
B. Xu, C. Gil-Jardin´ e, F. Thiessard, E. Tellier, M. Avalos, and E. Lagarde, “Pre-Training a neural language model improves the sample efficiency of an emergency room classification model,” in The 33rd Florida Artificial Intelligence Research Society Conference , 2020
work page 2020
-
[14]
Benchmarking pysyft federated learning framework on mimic-iii dataset,
A. Budrionis, M. Miara, P. Miara, S. Wilk, and J. G. Bellika, “Benchmarking pysyft federated learning framework on mimic-iii dataset,” IEEE Access, vol. 9, pp. 116869–116878, 2021. 19
work page 2021
-
[15]
Flicu: A federated learning workflow for intensive care unit mortality prediction,
L. Mondrejevski, I. Miliou, A. Montanino, D. Pitts, J. Hollm´ en, and P. Papapetrou, “Flicu: A federated learning workflow for intensive care unit mortality prediction,” in 2022 IEEE 35th In- ternational Symposium on Computer-Based Medical Systems (CBMS) , pp. 32–37, July 2022
work page 2022
-
[16]
Exploratory analysis of federated learning methods with differential privacy on mimic-iii,
A. N. Horvath, M. Berchier, F. Nooralahzadeh, A. Allam, and M. Krauthammer, “Exploratory analysis of federated learning methods with differential privacy on mimic-iii,” arXiv preprint arXiv:2302.04208, 2023
-
[17]
Mimic-iv-note: Deidentified free-text clinical notes,
A. Johnson, T. Pollard, S. Horng, L. A. Celi, and R. Mark, “Mimic-iv-note: Deidentified free-text clinical notes,” 2023
work page 2023
-
[18]
A. L. Goldberger, L. A. Amaral, L. Glass, J. M. Hausdorff, P. C. Ivanov, R. G. Mark, J. E. Mietus, G. B. Moody, C.-K. Peng, and H. E. Stanley, “Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals,”circulation, vol. 101, no. 23, pp. e215–e220, 2000
work page 2000
-
[19]
MTEB: Massive Text Embedding Benchmark
N. Muennighoff, N. Tazi, L. Magne, and N. Reimers, “Mteb: Massive text embedding benchmark,” arXiv preprint arXiv:2210.07316 , 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y. Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Lin, et al. , “Qwen3 embedding: Advancing text embedding and reranking through foundation models,” arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. , “Qwen3 technical report,” arXiv preprint arXiv:2505.09388 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Z. Li, X. Zhang, Y. Zhang, D. Long, P. Xie, and M. Zhang, “Towards general text embeddings with multi-stage contrastive learning,” arXiv preprint arXiv:2308.03281 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. Wei, H. Lin, J. Tang, J. Wang, J. Yang, J. Tu, J. Zhang, J. Ma, J. Yang, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K. Chen, K. Yang, M. Li, M. Xue, N. Ni, P. Zhang, P. Wang, R. Peng, R. Men, R. Gao, R. Lin, S. Wang, S. Bai, S. Tan, T. Zhu, T. Li, T...
work page 2024
-
[24]
X. Zhang, Y. Zhang, D. Long, W. Xie, Z. Dai, J. Tang, H. Lin, B. Yang, P. Xie, F. Huang, et al., “mgte: Generalized long-context text representation and reranking models for multilingual text retrieval,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp. 1393–1412, 2024
work page 2024
-
[25]
Arctic-embed 2.0: Multilingual retrieval without compromise, 2024
P. Yu, L. Merrick, G. Nuti, and D. Campos, “Arctic-embed 2.0: Multilingual retrieval without compromise,” arXiv preprint arXiv:2412.04506 , 2024
-
[26]
Nomic embed: Training a reproducible long context text embedder,
Z. Nussbaum, J. X. Morris, A. Mulyar, and B. Duderstadt, “Nomic embed: Training a reproducible long context text embedder,” Transactions on Machine Learning Research, 2025. Reproducibility Certification
work page 2025
-
[27]
Automated medical coding on mimic-iii and mimic-iv: A critical review and replicability study,
J. Edin, A. Junge, J. D. Havtorn, L. Borgholt, M. Maistro, T. Ruotsalo, and L. Maaløe, “Automated medical coding on mimic-iii and mimic-iv: A critical review and replicability study,” in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, (New York, NY, USA), p. 2572–2582, Association...
work page 2023
-
[28]
Icd coding from clinical text using multi-filter residual convolutional neural network,
F. Li and H. Yu, “Icd coding from clinical text using multi-filter residual convolutional neural network,” Proceedings of the AAAI Conference on Artificial Intelligence , vol. 34, pp. 8180–8187, Apr. 2020
work page 2020
-
[29]
A label attention model for icd coding from clinical text,
T. Vu, D. Q. Nguyen, and A. Nguyen, “A label attention model for icd coding from clinical text,” in Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI’20, 2021
work page 2021
-
[30]
Flower: A Friendly Federated Learning Research Framework
D. J. Beutel, T. Topal, A. Mathur, X. Qiu, J. Fernandez-Marques, Y. Gao, L. Sani, K. H. Li, T. Parcollet, P. P. B. de Gusm˜ ao,et al., “Flower: A friendly federated learning research framework,” arXiv preprint arXiv:2007.14390 , 2020
work page internal anchor Pith review arXiv 2007
- [31]
-
[32]
Fedlab: A flexible federated learning framework,
D. Zeng, S. Liang, X. Hu, H. Wang, and Z. Xu, “Fedlab: A flexible federated learning framework,” Journal of Machine Learning Research , vol. 24, no. 100, pp. 1–7, 2023
work page 2023
-
[33]
Secureboost: A lossless federated learning framework,
K. Cheng, T. Fan, Y. Jin, Y. Liu, T. Chen, D. Papadopoulos, and Q. Yang, “Secureboost: A lossless federated learning framework,” IEEE Intelligent Systems , vol. 36, pp. 87–98, Nov 2021
work page 2021
-
[34]
Mimic- iv-icd: A new benchmark for extreme multilabel classification,
T.-T. Nguyen, V. Schlegel, A. Kashyap, S. Winkler, S.-S. Huang, J.-J. Liu, and C.-J. Lin, “Mimic- iv-icd: A new benchmark for extreme multilabel classification,” arXiv preprint arXiv:2304.13998 , 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.