Diverse LLMs or Diverse Question Interpretations? That is the Ensembling Question
Pith reviewed 2026-05-21 23:21 UTC · model grok-4.3
The pith
Question interpretation diversity improves LLM ensemble accuracy more than model diversity for binary questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
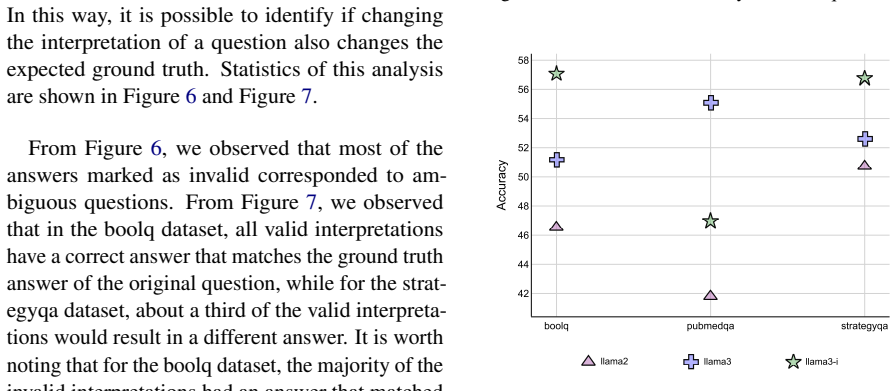
Question interpretation diversity, achieved by prompting the same LLM with multiple framings of a binary question and taking a majority vote, consistently produces higher ensemble accuracy than model diversity, which uses multiple distinct LLMs on the unchanged question. Across BoolQ, StrategyQA, and PubMedQA, the interpretation-based ensembles outperform. Model-diversity ensembles typically fall between the best and worst individual member performances without reliable net gains.
What carries the argument
Majority-vote ensembling over either multiple model outputs on one question or multiple question interpretations from one model.
If this is right
- Interpretation diversity yields higher accuracy than model diversity on BoolQ, StrategyQA, and PubMedQA under majority voting.
- Model diversity ensembles usually produce results between their best and worst members without consistent gains.
- Majority voting extracts more value from varied question framings than from varied models for binary QA tasks.
Where Pith is reading between the lines
- Prompt variation techniques could serve as a lower-cost substitute for running multiple separate models in production ensembles.
- The results highlight that LLMs may benefit more from explicit handling of question ambiguity than from simply averaging across architectures.
- Similar gains might appear in non-binary tasks if automatic methods for generating diverse interpretations can be developed.
Load-bearing premise
The different question framings must produce sufficiently independent model outputs rather than near-duplicate answers for the majority vote to deliver real improvement.
What would settle it
Re-running the experiments with question framings deliberately made very similar to each other and finding that the accuracy advantage over single models or model-diversity ensembles disappears.
Figures







read the original abstract
Effectively leveraging diversity has been shown to improve performance for various machine learning models, including large language models (LLMs). However, determining the most effective way of using diversity remains a challenge. In this work, we compare two diversity approaches for answering binary questions using LLMs: model diversity, which relies on multiple models answering the same question, and question interpretation diversity, which relies on using the same model to answer the same question framed in different ways. For both cases, we apply majority voting as the ensemble consensus heuristic to determine the final answer. Our experiments on boolq, strategyqa, and pubmedqa show that question interpretation diversity consistently leads to better ensemble accuracy compared to model diversity. Furthermore, our analysis of GPT and LLaMa shows that model diversity typically produces results between the best and the worst ensemble members without clear improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares two diversity strategies for LLM ensembles on binary QA tasks: model diversity (distinct models answering the same question) versus question-interpretation diversity (one model answering multiple rephrasings of the question). Using majority voting, experiments on BoolQ, StrategyQA, and PubMedQA report that interpretation diversity yields higher ensemble accuracy than model diversity; model-diversity ensembles are also shown to lie between the best and worst constituent models without consistent gains.
Significance. If the attribution to interpretation diversity is validated, the result would indicate that prompt variation offers a more accessible and effective route to ensemble gains than multi-model setups, with practical implications for reducing inference costs while improving reliability on standard QA benchmarks.
major comments (3)
- [Experimental setup] The manuscript provides no details on the procedure used to generate the alternative question interpretations (number of variants, manual vs. automatic creation, or prompting strategy), which is required to evaluate whether the reported accuracy lift on BoolQ, StrategyQA, and PubMedQA can be attributed to diversity rather than prompt engineering effects.
- [Results and analysis] No output-diversity metrics (pairwise agreement rates, output entropy, or disagreement frequency) are reported for the interpretation variants, nor is a same-framing repeated-prompt control included; without these, the central claim that interpretation diversity outperforms model diversity remains insecure, as gains could arise from sampling variation or repetition.
- [Results] Statistical significance or confidence intervals for the accuracy differences between the two ensemble types are not provided across the three datasets, leaving the claim of 'consistent' superiority without quantitative support.
minor comments (1)
- [Abstract] The abstract refers to 'GPT and LLaMa' without specifying model sizes or exact variants used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and have revised the paper accordingly to improve clarity, reproducibility, and analytical rigor.
read point-by-point responses
-
Referee: [Experimental setup] The manuscript provides no details on the procedure used to generate the alternative question interpretations (number of variants, manual vs. automatic creation, or prompting strategy), which is required to evaluate whether the reported accuracy lift on BoolQ, StrategyQA, and PubMedQA can be attributed to diversity rather than prompt engineering effects.
Authors: We agree that the original manuscript lacked sufficient detail on this point. In the revised version, we have added a dedicated subsection under Experimental Setup that specifies the automatic generation process: we used a fixed prompt template with GPT-4 to produce exactly five rephrasings per original question. The full prompt template is now provided in the appendix, and we confirm that no manual editing was performed. This addition directly addresses the concern and supports attribution to interpretation diversity. revision: yes
-
Referee: [Results and analysis] No output-diversity metrics (pairwise agreement rates, output entropy, or disagreement frequency) are reported for the interpretation variants, nor is a same-framing repeated-prompt control included; without these, the central claim that interpretation diversity outperforms model diversity remains insecure, as gains could arise from sampling variation or repetition.
Authors: We acknowledge the value of these additional controls and metrics for securing the central claim. In the revision, we have computed and reported pairwise agreement rates, output entropy, and disagreement frequency across the interpretation variants. We have also added a same-framing repeated-prompt control (querying the identical prompt five times with temperature sampling) and show that interpretation diversity yields further gains beyond repetition alone. These results are now included in a new analysis subsection. revision: yes
-
Referee: [Results] Statistical significance or confidence intervals for the accuracy differences between the two ensemble types are not provided across the three datasets, leaving the claim of 'consistent' superiority without quantitative support.
Authors: We agree that quantitative support via statistical measures strengthens the results. The revised manuscript now includes bootstrap confidence intervals and paired statistical tests for the accuracy differences between model-diversity and interpretation-diversity ensembles on all three datasets (BoolQ, StrategyQA, PubMedQA). These additions provide the requested quantitative backing for the observed superiority. revision: yes
Circularity Check
No circularity: purely empirical comparison on public benchmarks
full rationale
The paper reports direct experimental measurements of majority-vote ensemble accuracy for model diversity versus question-interpretation diversity on BoolQ, StrategyQA, and PubMedQA. No equations, derivations, fitted parameters, or self-citation chains appear in the provided text. Claims rest on held-out test-set accuracies rather than any reduction to inputs by construction. The absence of output-diversity controls noted by the skeptic is an experimental-design concern, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Survey on In-context Learning
Understanding the resilience of neural network ensembles against faulty training data. In 2021 IEEE 21st International Conference on Software Quality, Reliability and Security (QRS), pages 1100–1111. Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising difficulty of ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Paperqa: Retrieval-augmented generative agent for scientific research,
Optimizing memory placement using evolu- tionary graph reinforcement learning. In Interna- tional Conference on Learning Representations. Gangwoo Kim, Sungdong Kim, Byeongguk Jeon, Joon- suk Park, and Jaewoo Kang. 2023. Tree of clarifica- tions: Answering ambiguous questions with retrieval- augmented large language models. In Proceedings of the 2023 Confe...
-
[3]
Yifei Li, Zeqi Lin, Shizhuo Zhang, Qiang Fu, Bei Chen, Jian-Guang Lou, and Weizhu Chen
Curran Associates, Inc. Yifei Li, Zeqi Lin, Shizhuo Zhang, Qiang Fu, Bei Chen, Jian-Guang Lou, and Weizhu Chen. 2023. Making Large Language Models better reasoners with step- aware verifier. CoRR, cs.CL/2206.02336v3. Anne-Laure Ligozat, Brigitte Grau, Anne Vilnat, Is- abelle Robba, and Arnaud Grappy. 2007. Towards an automatic validation of answers in que...
-
[4]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Improve mathematical reasoning in language models by automated process supervision. CoRR, abs/2406.06592. Bo Lv, Chen Tang, Yanan Zhang, Xin Liu, Ping Luo, and Yue Yu. 2024. URG: A unified ranking and generation method for ensembling language models. In Findings of the Association for Computational Linguistics: ACL 2024, pages 4421–4434, Bangkok, Thailand...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Quality diversity: A new frontier for evolution- ary computation. Frontiers Robotics AI, 3:40. Mathieu Ravaut, Shafiq Joty, and Nancy Chen. 2022. SummaReranker: A multi-task mixture-of-experts re-ranking framework for abstractive summarization. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
work page 2022
-
[6]
Assessing the impact of diversity on the re- silience of deep learning ensembles: A comparative study on model architecture, output, activation, and attribution. In IEEE/CVF International Conference on Computer Vision, ICCV 2023 - Workshops, Paris, France, October 2-6, 2023, pages 4408–4418. IEEE. Sara Rosenthal, Mihaela A. Bornea, Avirup Sil, Radu Floria...
-
[7]
HoneyBee: Progressive instruction finetuning of large language models for materials science. In Findings of the Association for Computational Lin- guistics: EMNLP 2023, pages 5724–5739, Singapore. Association for Computational Linguistics. Haitian Sun, William W. Cohen, and Ruslan Salakhutdi- nov. 2023. Answering ambiguous questions with a database of que...
-
[8]
Llama 2: Open Foundation and Fine-Tuned Chat Models
An analysis of diversity measures. Mach. Learn., 65(1):247–271. Bernadette Tix and Kim Binsted. 2024. Better results through ambiguity resolution: Large language mod- els that ask clarifying questions. In Augmented Cog- nition - 18th International Conference, AC 2024, Held as Part of the 26th HCI International Confer- ence, HCII Proceedings, Part II, volu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
does the size of a rain gauge matter
Environmental interpretation: In an environ- mental context, the question ’does the size of a rain gauge matter’ could be interpreted as a query about the impact of rainfall on the environment. Rain- fall is an important factor in many environmental processes, such as plant growth, erosion, and wa- ter availability. Therefore, the question could be asking...
-
[12]
Scientific interpretation: In a scientific context, the question ’does the size of a rain gauge matter’ could be interpreted as a query about the accuracy of rainfall measurements. Rain gauges are used to collect and measure precipitation, and the size of the gauge can affect the accuracy of the measure- ment. A larger rain gauge may collect more water, b...
-
[13]
Engineers may be interested in designing rain gauges that are more efficient or cost-effective
Engineering interpretation: In an engineering context, the question ’does the size of a rain gauge matter’ could be interpreted as a query about the design of rain gauges. Engineers may be interested in designing rain gauges that are more efficient or cost-effective. Therefore, the question could be asking whether the size of a rain gauge affects its perf...
-
[14]
Environmental interpretation: In an environ- mental context, the question ’does the size of a rain gauge matter’ could be interpreted as a query about the impact of rainfall on the environment. Rain- fall is an important factor in many environmental processes, such as plant growth, erosion, and wa- ter availability. Therefore, the question could be asking...
work page 2020
-
[15]
Engineering interpretation: In an engineering context, the question ’does the size of a rain gauge matter’ could be interpreted as a query about the design of rain gauges. Engineers may be interested in designing rain gauges that are more efficient or cost-effective. Therefore, the question could be asking whether the size of a rain gauge affects its perf...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.