From Pixels to Places: A Systematic Benchmark for Evaluating Image Geolocalization Ability in Large Language Models
Pith reviewed 2026-05-21 23:45 UTC · model grok-4.3
The pith
Large language models display geospatial biases in image geolocalization, performing better in high-resource regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
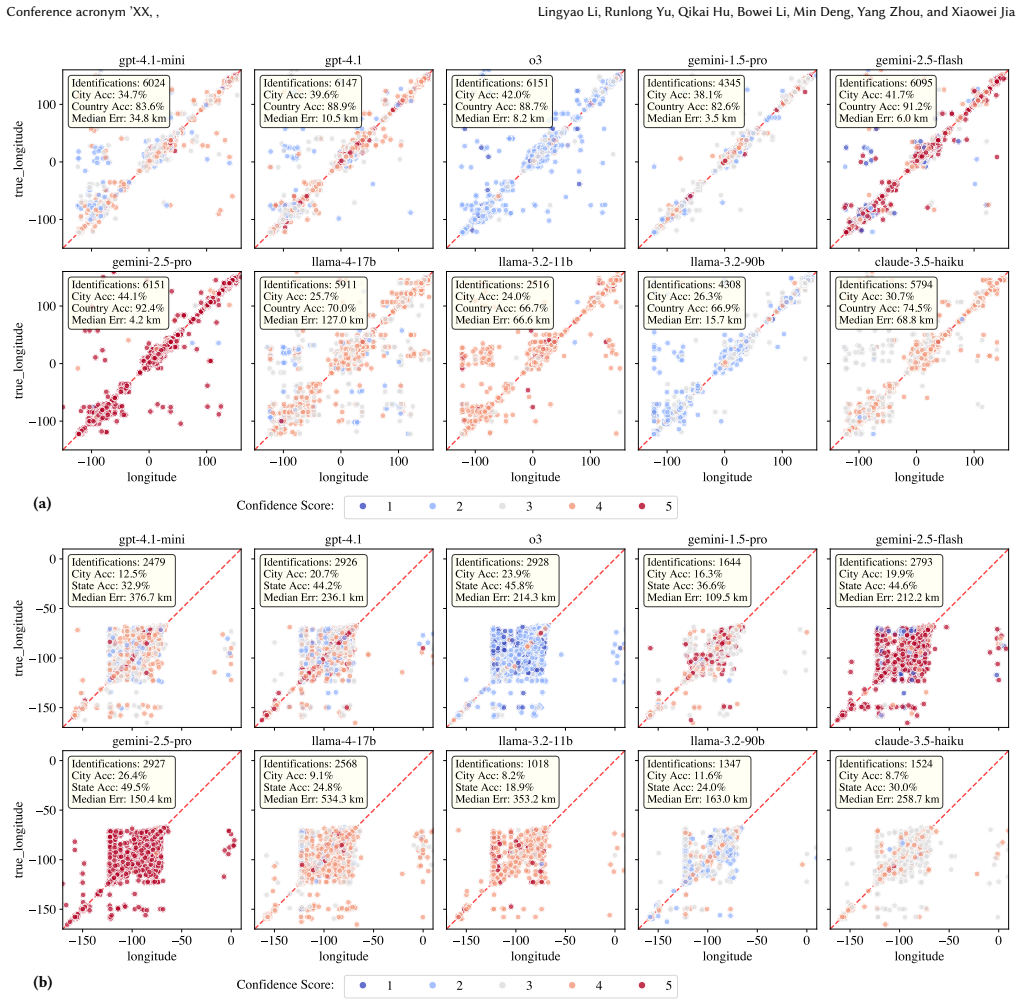
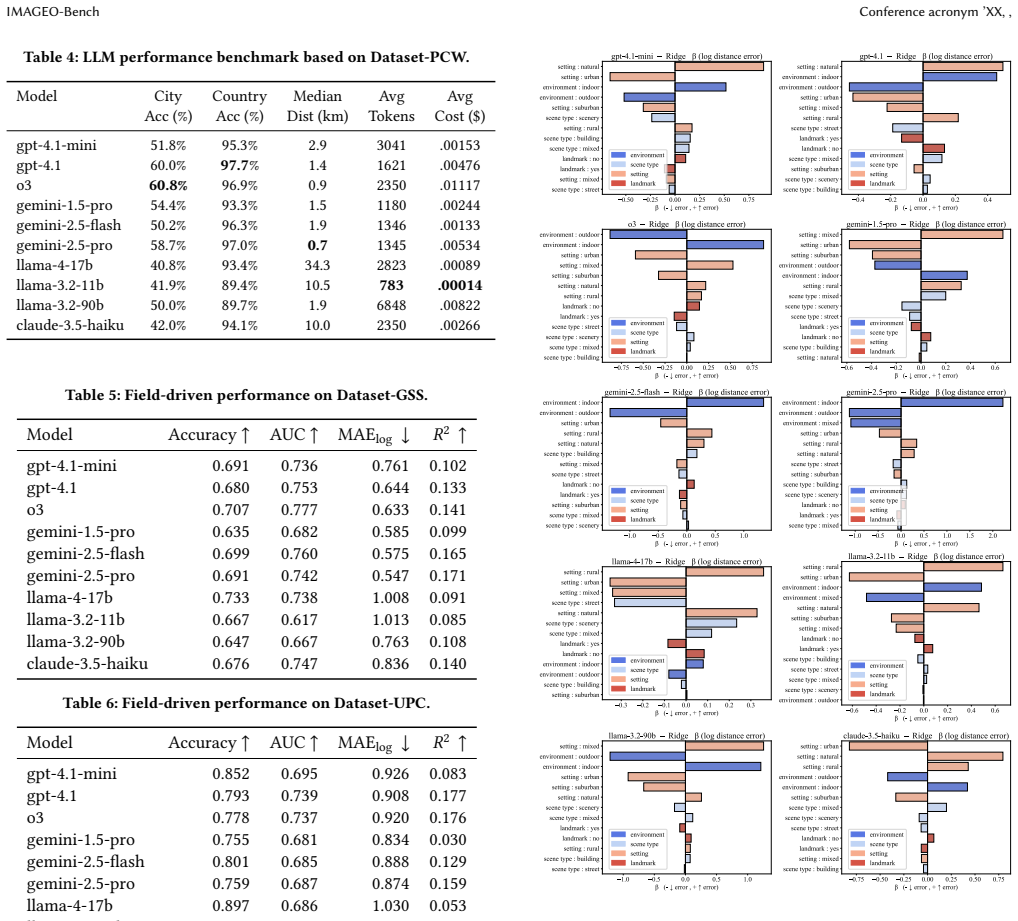
Experiments on IMAGEO-Bench demonstrate that closed-source LLMs generally outperform open-source models in image geolocalization accuracy and reasoning quality. LLMs achieve stronger results in high-resource regions such as North America, Western Europe, and California while showing degraded performance in underrepresented areas. Regression diagnostics indicate that successful geolocalization depends primarily on recognizing urban settings, outdoor environments, street-level imagery, and identifiable landmarks.
What carries the argument
IMAGEO-Bench, a benchmark that measures LLM geolocalization through accuracy, distance error, geospatial bias, and reasoning traces across three datasets of global street scenes, U.S. points of interest, and unseen private images.
If this is right
- Closed-source LLMs are currently more reliable for image-based location tasks than open-source alternatives.
- Geolocation-aware AI systems will inherit uneven accuracy favoring well-documented regions.
- Applications in crisis response and digital forensics may underperform when images come from underrepresented areas.
- Training data imbalances are a plausible driver of the observed regional performance gaps.
- The benchmark supplies a repeatable method for tracking progress toward more balanced spatial reasoning in future models.
Where Pith is reading between the lines
- Diversifying training images from low-resource regions could reduce the performance gaps observed in the benchmark.
- The bias pattern suggests that visual reasoning in current LLMs is shaped more by example frequency than by universal spatial understanding.
- Explicit geospatial modules or region-balanced fine-tuning might be needed to make geolocalization equitable across all locations.
- In digital forensics, location evidence extracted from images in underrepresented regions may carry higher uncertainty.
Load-bearing premise
The regression diagnostics accurately isolate the primary drivers of successful geolocalization without significant confounding from dataset composition or model-specific training data.
What would settle it
Finding no measurable performance difference between high-resource regions such as California and low-resource regions across all tested models on the same image sets would falsify the geospatial bias claim.
Figures











read the original abstract
Image geolocalization, the task of identifying the geographic location depicted in an image, is important for applications in crisis response, digital forensics, and location-based intelligence. While recent advances in large language models (LLMs) offer new opportunities for visual reasoning, their ability to perform image geolocalization remains underexplored. In this study, we introduce a benchmark called IMAGEO-Bench that systematically evaluates accuracy, distance error, geospatial bias, and reasoning process. Our benchmark includes three diverse datasets covering global street scenes, points of interest (POIs) in the United States, and a private collection of unseen images. Through experiments on 10 state-of-the-art LLMs, including both open- and closed-source models, we reveal clear performance disparities, with closed-source models generally showing stronger reasoning. Importantly, we uncover geospatial biases as LLMs tend to perform better in high-resource regions (e.g., North America, Western Europe, and California) while exhibiting degraded performance in underrepresented areas. Regression diagnostics demonstrate that successful geolocalization is primarily dependent on recognizing urban settings, outdoor environments, street-level imagery, and identifiable landmarks. Overall, IMAGEO-Bench provides a rigorous lens into the spatial reasoning capabilities of LLMs and offers implications for building geolocation-aware AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IMAGEO-Bench, a new benchmark for assessing image geolocalization capabilities in LLMs. It evaluates 10 state-of-the-art models (open- and closed-source) across three datasets—global street scenes, US points of interest, and a private unseen collection—reporting accuracy, distance error, geospatial biases, and reasoning traces. Key findings include performance advantages for closed-source models and systematic geospatial biases favoring high-resource regions (North America, Western Europe, California) over underrepresented areas. Regression diagnostics are used to attribute successful geolocalization primarily to urban settings, outdoor environments, street-level imagery, and identifiable landmarks.
Significance. If the empirical results and regression hold after addressing potential confounds, this benchmark offers a timely, systematic lens on LLM spatial reasoning with direct relevance to applications in crisis response, forensics, and location intelligence. The multi-dataset design and inclusion of both quantitative metrics and qualitative reasoning analysis are strengths; the work also provides reproducible experimental protocols and falsifiable predictions about regional performance gaps.
major comments (2)
- [§4.3] §4.3 Regression Diagnostics: The claim that successful geolocalization depends primarily on urban settings, outdoor environments, street-level imagery, and identifiable landmarks rests on regression coefficients. However, the analysis does not report region fixed effects, dataset-specific controls, or explicit checks for feature prevalence imbalances across the three datasets (e.g., higher fraction of street-level/landmark images in North America/Western Europe subsets). This risks attributing performance gaps to the listed features when they may instead reflect training-data exposure or sampling composition, directly affecting the geospatial-bias conclusions.
- [§3.2] §3.2 Private Unseen Collection: The description of the private dataset lacks quantitative details on sample size, geographic distribution, collection protocol, and exclusion criteria. Without these, it is difficult to verify that the reported performance disparities and regression results generalize beyond the public datasets or to rule out inherited collection biases that could confound the primary-driver interpretation.
minor comments (3)
- [Table 2] Table 2: The distance-error metric is reported without units or normalization details, complicating direct comparison of absolute performance across models and regions.
- [Figure 3] Figure 3: The geospatial bias heatmaps would benefit from explicit legend values and a statement on how 'high-resource' vs. 'underrepresented' regions were thresholded.
- [§5] §5 Discussion: The implications for geolocation-aware AI systems are stated at a high level; adding concrete recommendations (e.g., data-augmentation strategies for underrepresented regions) would strengthen the applied contribution.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us identify areas for improvement in our manuscript on IMAGEO-Bench. Below, we provide point-by-point responses to the major comments and describe the revisions we plan to implement.
read point-by-point responses
-
Referee: [§4.3] §4.3 Regression Diagnostics: The claim that successful geolocalization depends primarily on urban settings, outdoor environments, street-level imagery, and identifiable landmarks rests on regression coefficients. However, the analysis does not report region fixed effects, dataset-specific controls, or explicit checks for feature prevalence imbalances across the three datasets (e.g., higher fraction of street-level/landmark images in North America/Western Europe subsets). This risks attributing performance gaps to the listed features when they may instead reflect training-data exposure or sampling composition, directly affecting the geospatial-bias conclusions.
Authors: The referee correctly identifies a limitation in our regression diagnostics in §4.3. We did not include region fixed effects or perform explicit checks for feature prevalence imbalances, which could indeed affect the interpretation of whether the performance differences stem from the image characteristics or from differential exposure in training data. In the revised version, we will augment the regression analysis with region fixed effects and dataset-specific controls. We will also include an analysis of feature distributions across regions to address potential confounds. These changes will provide a more rigorous basis for our claims about the primary drivers of geolocalization success and the geospatial biases. revision: yes
-
Referee: [§3.2] §3.2 Private Unseen Collection: The description of the private dataset lacks quantitative details on sample size, geographic distribution, collection protocol, and exclusion criteria. Without these, it is difficult to verify that the reported performance disparities and regression results generalize beyond the public datasets or to rule out inherited collection biases that could confound the primary-driver interpretation.
Authors: We agree that additional details on the private unseen collection are necessary for full transparency. In the revised manuscript, we will provide quantitative information regarding the sample size, geographic distribution (in aggregated form to maintain privacy), collection protocol, and exclusion criteria. This will help readers evaluate the generalizability of the results and assess any potential collection biases that might influence the regression findings. revision: yes
Circularity Check
Empirical benchmark study with no derivations or self-referential reductions
full rationale
This is an empirical benchmark paper that introduces IMAGEO-Bench, evaluates 10 LLMs across three datasets (global street scenes, US POIs, private unseen images), and reports performance metrics, geospatial biases, and regression diagnostics on factors such as urban settings and landmarks. All central claims rest on experimental outcomes and statistical associations rather than any mathematical derivation chain, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations. No equations, ansatzes, or uniqueness theorems appear in the provided text; the regression diagnostics are presented as post-hoc analysis of observed results, not as a closed loop that reduces the reported biases or drivers to inputs defined within the paper itself. The work is therefore self-contained against external benchmarks and falsifiable through replication on new images or models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard machine learning evaluation metrics (accuracy, distance error) and regression analysis can reliably measure and explain LLM geolocalization performance.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Regression diagnostics demonstrate that successful geolocalization is primarily dependent on recognizing urban settings, outdoor environments, street-level imagery, and identifiable landmarks.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We uncover geospatial biases as LLMs tend to perform better in high-resource regions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Unlocking Zero-Shot Geospatial Reasoning via Indirect Rewards
Geo-R1 uses indirect proxy rewards from cross-view alignment with geolocation metadata to drive reinforcement learning, enabling zero-shot geospatial reasoning that transfers across 25+ tasks and sometimes exceeds sup...
-
A Guide to Using Social Media as a Geospatial Lens for Studying Public Opinion and Behavior
Social media data functions as passive geospatial sensing for public opinion and behavior via a structured workflow and case studies on topics like COVID-19 vaccines and urban accessibility.
Reference graph
Works this paper leans on
-
[1]
Relja Arandjelović, Petr Gronat, Akihiko Torii, Tomáš Pajdla, and Josef Sivic
-
[2]
NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). 5297–5307. https://doi.org/10.1109/CVPR.2016.572
-
[3]
Jan Brejcha and Martin Čadík. 2017. State-of-the-art in visual geo-localization. Pattern Analysis and Applications20, 3 (2017), 613–637
work page 2017
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
work page 2020
-
[5]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. 14455–14465
work page 2024
-
[6]
Brandon Clark, Alec Kerrigan, Parth Parag Kulkarni, Vicente Vivanco Cepeda, and Mubarak Shah. 2023. Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23182– 23190
work page 2023
- [7]
-
[8]
Jiaxian Guo, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Boyang Li, Dacheng Tao, and Steven Hoi. 2023. From images to textual prompts: Zero-shot visual question answering with frozen large language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10867–10877
work page 2023
-
[9]
James Hays and Alexei A Efros. 2008. IM2GPS: estimating geographic information from a single image. In2008 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 1–8. https://doi.org/10.1109/CVPR.2008.4587784
-
[10]
James Hays and Alexei A Efros. 2014. Large-scale image geolocalization. In Multimodal location estimation of videos and images. Springer, 41–62
work page 2014
-
[11]
Yujun Hou, Matias Quintana, Maxim Khomiakov, Winston Yap, Jiani Ouyang, Koichi Ito, Zeyu Wang, Tianhong Zhao, and Filip Biljecki. 2024. Global Streetscapes—A comprehensive dataset of 10 million street-level images across 688 cities for urban science and analytics.ISPRS Journal of Photogrammetry and Remote Sensing215 (2024), 216–238
work page 2024
-
[12]
Anwen Hu, Yaya Shi, Haiyang Xu, Jiabo Ye, Qinghao Ye, Ming Yan, Chenliang Li, Qi Qian, Ji Zhang, and Fei Huang. 2024. mplug-paperowl: Scientific diagram analysis with the multimodal large language model. InProceedings of the 32nd ACM International Conference on Multimedia. 6929–6938
work page 2024
- [13]
- [14]
-
[15]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yunhsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling Up Visual and Vision-Language Representation Learning with Noisy Text Supervision. InProc. Int. Conf. on Machine Learning (ICML). 4904–4916
work page 2021
-
[16]
Hyo Jin Kim, Enrique Dunn, and Jan-Michael Frahm. 2017. Learned contex- tual feature reweighting for image geo-localization. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2136–2145
work page 2017
-
[17]
VijayaKumar Kadha, Sambit Bakshi, and Santos Kumar Das. 2025. Unravelling Digital Forgeries: A Systematic Survey on Image Manipulation Detection and Localization.Comput. Surveys57, 12 (2025), 1–36
work page 2025
-
[18]
Jiayi Kuang, Ying Shen, Jingyou Xie, Haohao Luo, Zhe Xu, Ronghao Li, Yinghui Li, Xianfeng Cheng, Xika Lin, and Yu Han. 2025. Natural language understanding and inference with mllm in visual question answering: A survey.Comput. Surveys 57, 8 (2025), 1–36
work page 2025
-
[19]
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, et al. 2023. Geo-bench: Toward foundation models for earth monitoring. Advances in Neural Information Processing Systems36 (2023), 51080–51093
work page 2023
-
[20]
Hao Li, Fabian Deuser, Wenping Yin, Xuanshu Luo, Paul Walther, Gengchen Mai, Wei Huang, and Martin Werner. 2025. Cross-view geolocalization and disaster mapping with street-view and VHR satellite imagery: A case study of Hurricane IAN.ISPRS Journal of Photogrammetry and Remote Sensing220 (2025), 841–854
work page 2025
-
[21]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: Boot- strapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. InProc. 40th Int. Conf. on Machine Learning (ICML), Vol. 202. PMLR, 19730–19742
work page 2023
- [22]
- [23]
-
[24]
Xin Li, Yunfei Wu, Xinghua Jiang, Zhihao Guo, Mingming Gong, Haoyu Cao, Yinsong Liu, Deqiang Jiang, and Xing Sun. 2024. Enhancing visual document understanding with contrastive learning in large visual-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15546–15555
work page 2024
-
[25]
Tsung-Yi Lin, Serge Belongie, and James Hays. 2013. Cross-view image geolo- calization. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 891–898
work page 2013
-
[26]
Eric Muller-Budack, Kader Pustu-Iren, and Ralph Ewerth. 2018. Geolocation estimation of photos using a hierarchical model and scene classification. In Proceedings of the European conference on computer vision (ECCV). 563–579
work page 2018
-
[27]
Shraman Pramanick, Ewa M Nowara, Joshua Gleason, Carlos D Castillo, and Rama Chellappa. 2022. Where in the world is this image? transformer-based geo-localization in the wild. InEuropean Conference on Computer Vision. Springer, 196–215
work page 2022
-
[28]
Alec Radford, Jong Wook Kim, and Christopheret al.Hallacy. 2021. Learning Transferable Visual Models from Natural Language Supervision. InProc. Int. Conf. on Machine Learning (ICML). 8748–8763
work page 2021
-
[29]
Noe Samano, Mengjie Zhou, and Andrew Calway. 2020. You are here: Geolocation by embedding maps and images. InEuropean Conference on Computer Vision. Springer, 502–518
work page 2020
-
[30]
Paul Hongsuck Seo, Tobias Weyand, Jack Sim, and Bohyung Han. 2018. Cplanet: Enhancing image geolocalization by combinatorial partitioning of maps. InPro- ceedings of the European Conference on Computer Vision (ECCV). 536–551
work page 2018
- [31]
-
[32]
Zhicheng Shi, Yang Li, Siyu Li, and Jiebo Luo. 2020. SAFA: Structure-Aware Feature Aggregation for Cross-View Image-Based Geo-Localization. InProc. ACM Int. Conf. on Multimedia (MM). 1633–1641. https://doi.org/10.1145/3394171. 3413569
- [33]
-
[34]
Yicong Tian, Chen Chen, and Mubarak Shah. 2017. Cross-view image matching for geo-localization in urban environments. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3608–3616
work page 2017
-
[35]
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. 2023. Geo- CLIP: Clip-Inspired Alignment between Locations and Images for Effective World- wide Geo-localization. InAdvances in Neural Information Processing Systems (NeurIPS)
work page 2023
-
[36]
Nam Vo and David W. Jacobs. 2017. Revisiting IM2GPS in the Deep Learning Era. arXiv preprint arXiv:1705.04838(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [37]
-
[38]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
work page 2022
-
[39]
Tobias Weyand, Ilya Kostrikov, and James Philbin. 2016. PlaNet - Photo Geoloca- tion with Convolutional Neural Networks. InEuropean Conference on Computer Vision (ECCV). Springer, 37–55. https://doi.org/10.1007/978-3-319-46484-8_3
-
[40]
Scott Workman, Richard Souvenir, and Nathan Jacobs. 2015. Wide-area image geolocalization with aerial reference imagery. InProceedings of the IEEE Interna- tional Conference on Computer Vision. 3961–3969
work page 2015
-
[41]
Meiliu Wu and Qunying Huang. 2022. Im2city: image geo-localization via multi- modal learning. InProceedings of the 5th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery. 50–61
work page 2022
-
[42]
Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, and Furu Wei. 2024. Mind’s eye of LLMs: visualization-of-thought elicits spatial reasoning in large language models.Advances in Neural Information Processing Systems37 (2024), 90277–90317
work page 2024
-
[43]
Shixiong Xu, Chenghao Zhang, Lubin Fan, Gaofeng Meng, Shiming Xiang, and Jieping Ye. 2024. Addressclip: Empowering vision-language models for city-wide image address localization. InEuropean Conference on Computer Vision. Springer, 76–92
work page 2024
-
[44]
An Yan, Zhankui He, Jiacheng Li, Tianyang Zhang, and Julian McAuley. 2023. Personalized showcases: Generating multi-modal explanations for recommenda- tions. InProceedings of the 46th International ACM SIGIR Conference on Research Conference acronym ’XX, , Lingyao Li, Runlong Yu, Qikai Hu, Bowei Li, Min Deng, Yang Zhou, and Xiaowei Jia and Development in ...
work page 2023
-
[45]
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
-
[46]
InProceedings of the Computer Vision and Pattern Recognition Conference
Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference. 10632–10643
- [47]
-
[48]
Wenping Yin, Yong Xue, Ziqi Liu, Hao Li, and Martin Werner. 2025. LLM- enhanced disaster geolocalization using implicit geoinformation from multimodal data: A case study of Hurricane Harvey.International Journal of Applied Earth Observation and Geoinformation137 (2025), 104423
work page 2025
-
[49]
Amir Roshan Zamir and Mubarak Shah. 2014. Image geo-localization based on multiplenearest neighbor feature matching usinggeneralized graphs.IEEE transactions on pattern analysis and machine intelligence36, 8 (2014), 1546–1558
work page 2014
-
[50]
Yanhua Zhong, Yuqiang Wu, Sheng Zheng, Yi Yang, and Zhiwu Ma. 2021. VIGOR: Cross-View Image Geo-Localization Beyond One-to-One Retrieval. In Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR). 8636–
work page 2021
-
[51]
https://doi.org/10.1109/CVPR46437.2021.00853
-
[52]
Zhongliang Zhou, Jielu Zhang, Zihan Guan, Mengxuan Hu, Ni Lao, Lan Mu, Sheng Li, and Gengchen Mai. 2024. Img2Loc: Revisiting image geolocalization using multi-modality foundation models and image-based retrieval-augmented generation. InProceedings of the 47th international acm sigir conference on research and development in information retrieval. 2749–2754
work page 2024
-
[53]
Sijie Zhu, Mubarak Shah, and Chen Chen. 2022. Transgeo: Transformer is all you need for cross-view image geo-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1162–1171. A Sample Images from Benchmark Datasets Sample images from our three datasets in the benchmark are pre- sented in Figure 7. B Data Distrib...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.