Unlocking Zero-Shot Geospatial Reasoning via Indirect Rewards
Pith reviewed 2026-05-18 11:39 UTC · model grok-4.3
The pith
Indirect verifiable rewards from geolocation metadata can induce generalizable zero-shot geospatial reasoning in vision-language models across dozens of tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Indirect verifiable rewards, derived from seemingly unrelated metadata, are sufficient to induce sophisticated and generalizable geospatial reasoning across a wide range of downstream tasks (25+). Geo-R1 implements this by replacing limited task-specific annotations with scalable proxy rewards based on cross-view alignment with geolocation information, then applies reinforcement learning at scale. The resulting model discovers and internalizes zero-shot geospatial reasoning that transfers to out-of-distribution benchmarks and surpasses fully supervised specialists on certain tasks.
What carries the argument
Indirect proxy rewards obtained from cross-view alignment between images and their geolocation metadata, optimized through reinforcement learning to drive discovery of spatial reasoning.
If this is right
- Models achieve strong zero-shot transfer on out-of-distribution geospatial benchmarks without any direct task labels.
- Performance on some tasks exceeds that of models trained with full task-specific supervision.
- Training becomes feasible at scale in domains where raw data is abundant but annotated examples are limited.
- Optimizing indirect verifiable rewards offers a general route to reasoning capabilities when direct supervision is unavailable.
Where Pith is reading between the lines
- The same metadata-driven reward strategy could be explored in other annotation-scarce domains that possess rich auxiliary data, such as medical or temporal imagery.
- Success here suggests that verifiable proxy tasks may serve as substitutes for direct supervision when building world models in vision-language systems.
- Combining these indirect rewards with small amounts of direct supervision might produce further gains in generalization.
Load-bearing premise
Rewards based on cross-view alignment with geolocation metadata supply a rich and non-gameable signal that produces broad reasoning rather than narrow optimization on the alignment task alone.
What would settle it
Training the same model architecture with the indirect alignment rewards removed or replaced by random signals, then measuring whether downstream geospatial task performance collapses to baseline levels, would directly test the claim.
Figures


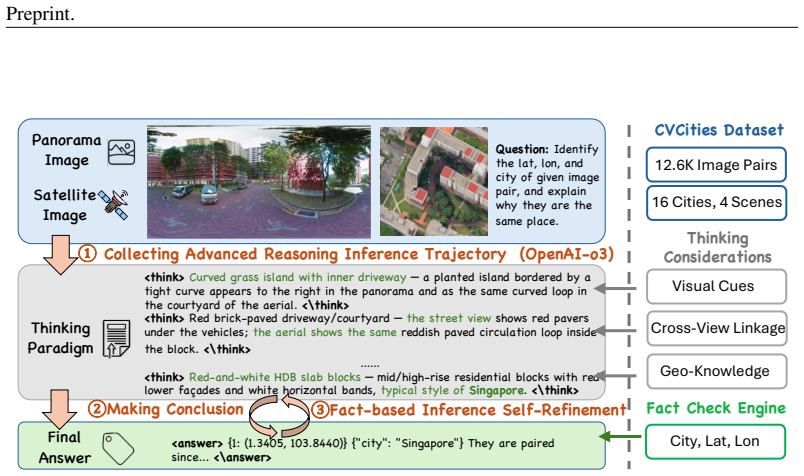





















read the original abstract
Training robust reasoning vision-language models (VLMs) in rare domains (such as geospatial) is fundamentally constrained by supervision scarcity. While raw geospatial imagery is abundant, the amount of task-direct supervision falls far behind that of common domains. In this work, we validate an important conclusion: indirect verifiable rewards, derived from seemingly unrelated metadata, are sufficient to induce sophisticated and generalizable geospatial reasoning across a wide range of downstream tasks (25+). We present Geo-R1 as one empirical instantiation of this paradigm. Rather than relying on limited task-specific annotations (i.e., direct rewards), Geo-R1 utilizes scalable, verifiable indirect proxy rewards based on cross-view alignment with metadata (geolocation information) to drive reinforcement learning at scale. Such indirect rewards successfully motivate the model to discover and internalize zero-shot geospatial reasoning across diverse tasks, achieving extraordinary zero-shot transfer on out-of-distribution benchmarks and even surpassing fully supervised specialists on certain benchmarks. These findings indicate that optimizing for indirect verifiable rewards may provide a scalable pathway to unlock generalized reasoning capabilities in rare domains with massive unlabeled data archives. Our code is availavle at: https://github.com/miniHuiHui/Geo-R1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Geo-R1, which uses reinforcement learning with indirect verifiable rewards from cross-view alignment with geolocation metadata to train VLMs for geospatial reasoning. It claims this induces generalizable zero-shot performance on over 25 downstream tasks, outperforming supervised models on some, without task-specific direct supervision.
Significance. This approach, if the empirical results are robust, offers a promising scalable method for developing reasoning capabilities in domains with abundant unlabeled data but scarce annotations. It highlights the potential of indirect rewards to unlock broader reasoning rather than narrow task optimization. The public code release supports reproducibility.
major comments (3)
- [§3] §3 (Methods), reward definition: the exact formulation of the cross-view alignment reward is not provided in sufficient detail to determine whether it functions as a rich semantic signal or reduces to coordinate regression. This directly bears on whether the observed transfer reflects internalized geospatial concepts (scale, invariance, layout) or narrow proxy optimization.
- [§4] §4 (Experiments): the reported outperformance over supervised specialists and zero-shot results on 25+ tasks lack ablation studies isolating the indirect reward, statistical significance tests, run-to-run variance, and control tasks orthogonal to geolocation. These omissions make it impossible to rule out the stress-test concern that gains arise from geolocation cue exploitation rather than general reasoning.
- [Table of main results] Table of main results (presumably in §4): without explicit comparison of data distributions and label access between the zero-shot Geo-R1 setting and the fully supervised baselines, the claim that indirect rewards surpass direct supervision cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: typo 'availavle' should read 'available'.
- [Throughout] Notation: ensure the reward function and any alignment loss are defined with consistent symbols across text and equations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address the concerns regarding the reward formulation, experimental rigor, and baseline comparisons. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [§3] §3 (Methods), reward definition: the exact formulation of the cross-view alignment reward is not provided in sufficient detail to determine whether it functions as a rich semantic signal or reduces to coordinate regression. This directly bears on whether the observed transfer reflects internalized geospatial concepts (scale, invariance, layout) or narrow proxy optimization.
Authors: We agree that the precise formulation must be explicit to support interpretation of the results. The cross-view alignment reward uses geolocation metadata to verify consistency between multiple views of the same scene at the level of semantic embeddings extracted by the VLM, rather than performing direct coordinate regression. In the revised manuscript we have added the complete mathematical definition of the reward (new Equation 3 in §3) together with a short derivation showing that the signal depends on feature-space alignment and view-invariant properties. This formulation is consistent with the observed transfer to tasks that do not require explicit geolocation output. revision: yes
-
Referee: [§4] §4 (Experiments): the reported outperformance over supervised specialists and zero-shot results on 25+ tasks lack ablation studies isolating the indirect reward, statistical significance tests, run-to-run variance, and control tasks orthogonal to geolocation. These omissions make it impossible to rule out the stress-test concern that gains arise from geolocation cue exploitation rather than general reasoning.
Authors: We acknowledge that stronger controls are required to isolate the contribution of the indirect reward. In the revised §4 we now include (i) an ablation that removes the cross-view alignment reward while keeping all other training elements fixed, (ii) statistical significance tests with p-values and (iii) standard deviations across five independent runs with different random seeds. We have also added control tasks that are deliberately orthogonal to geolocation (e.g., pure visual attribute recognition on non-geospatial imagery) to demonstrate that performance gains are not reducible to cue exploitation. revision: yes
-
Referee: [Table of main results] Table of main results (presumably in §4): without explicit comparison of data distributions and label access between the zero-shot Geo-R1 setting and the fully supervised baselines, the claim that indirect rewards surpass direct supervision cannot be evaluated.
Authors: We thank the referee for this clarification request. The revised manuscript now contains a dedicated paragraph and accompanying table in §4 that explicitly contrasts the two regimes: Geo-R1 receives only indirect, verifiable metadata rewards and zero task-specific labels, while the supervised baselines are trained with full task annotations on data drawn from the same underlying geospatial image distributions. This addition makes the supervision disparity transparent and supports the claim that indirect rewards can exceed direct supervision on certain benchmarks. revision: yes
Circularity Check
No significant circularity; rewards derived from external metadata keep derivation self-contained
full rationale
The paper constructs indirect rewards from cross-view alignment with geolocation metadata that is independent of the 25+ downstream task labels. No equations or steps reduce a claimed prediction or first-principles result to a fitted parameter or self-citation by construction. The RL objective uses verifiable external signals rather than target-task supervision, and success is evaluated on out-of-distribution benchmarks separate from the reward source. This satisfies the criteria for a self-contained derivation against external benchmarks with no load-bearing self-citation or renaming of known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning with verifiable indirect rewards from metadata can produce generalizable reasoning capabilities in VLMs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose the proxy RL task: matching a ground-level panoramic image to its corresponding satellite view image with confusers... reward r = λ_acc r_acc + λ_fmt r_fmt + ...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Geo-R1... two-stage methodology... scaffolding stage... elevating stage... GRPO-based reinforcement learning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harm- lessness from ai feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://doi.org/10.1038/s41586-025-09422-z
doi: 10.1038/ s41586-025-09422-z. URLhttps://doi.org/10.1038/s41586-025-09422-z. 10 Preprint. Gaoshuang Huang, Yang Zhou, Luying Zhao, and Wenjian Gan. Cv-cities: Advancing cross-view geo-localization in global cities.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 18:1592–1606,
-
[5]
doi: 10.1109/JSTARS.2024.3502160. Jeremy Andrew Irvin, Emily Ruoyu Liu, Joyce Chuyi Chen, Ines Dormoy, Jinyoung Kim, Samar Khanna, Zhuo Zheng, and Stefano Ermon. Teochat: A large vision-language assistant for tempo- ral earth observation data.arXiv preprint arXiv:2410.06234,
-
[6]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Xiang Li, Congcong Wen, Yuan Hu, and Nan Zhou
URLhttps://arxiv.org/abs/2508.01608. Xiang Li, Congcong Wen, Yuan Hu, and Nan Zhou. Rs-clip: Zero shot remote sensing scene classification via contrastive vision-language supervision.International Journal of Applied Earth Observation and Geoinformation, 124:103497,
-
[8]
Large language models have intrinsic self-correction ability.arXiv preprint arXiv:2406.15673, 2024a
Dancheng Liu, Amir Nassereldine, Ziming Yang, Chenhui Xu, Yuting Hu, Jiajie Li, Utkarsh Kumar, Changjae Lee, Ruiyang Qin, Yiyu Shi, et al. Large language models have intrinsic self-correction ability.arXiv preprint arXiv:2406.15673, 2024a. Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. Remoteclip: A...
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
E., B LUMENSTIEL , B., GHOSAL , R., DE OLIVEIRA , P
Daniela Szwarcman, Sujit Roy, Paolo Fraccaro, THorsteinn Eli Gislason, Benedikt Blumenstiel, Rinki Ghosal, Pedro Henrique de Oliveira, Joao Lucas de Sousa Almeida, Rocco Sedona, Yanghui Kang, et al. Prithvi-eo-2.0: A versatile multi-temporal foundation model for earth observation applications.arXiv preprint arXiv:2412.02732,
-
[12]
Demystifying Long Chain-of-Thought Reasoning in LLMs
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue. Demystifying long chain- of-thought reasoning in llms.arXiv preprint arXiv:2502.03373,
work page internal anchor Pith review arXiv
-
[13]
Geochain: Multimodal chain-of-thought for geographic reasoning.arXiv preprint arXiv:2506.00785, 2025
Sahiti Yerramilli, Nilay Pande, Rynaa Grover, and Jayant Sravan Tamarapalli. Geochain: Multi- modal chain-of-thought for geographic reasoning.arXiv preprint arXiv:2506.00785,
-
[14]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Association for Computational Linguis- tics. URLhttp://arxiv.org/abs/2403.13372. 12 Preprint. A COSINEREWARDS We use a cosine-shaped length reward (Yeo et al.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Table 2: Key training hyperparameters in SFT stage of Geo-R1
13 Preprint. Table 2: Key training hyperparameters in SFT stage of Geo-R1. Parameter Value Fine-tuning type Full Max input length 131072 Max samples 10M Batch size (per device) 1 Gradient accumulation steps 2 Learning rate1.0×10 −6 Epochs 2.0 Scheduler Cosine Warmup ratio 0.1 Precision bfloat16 DeepSpeed Config ZeRO-2 Freeze Vision Tower False Freeze Mult...
work page 2024
-
[16]
Training is launched withtorchrunon 8 A100 GPUs (single node)
as the training framework. Training is launched withtorchrunon 8 A100 GPUs (single node). We employ DeepSpeed ZeRO-3 for memory- efficient distributed optimization. Each GPU uses a per-device batch size of 4, with gradient accu- mulation of 2 steps, yielding an effective batch size of4×2×8 = 64prompts per update. For each prompt, the model generates 8 can...
work page 2048
-
[17]
A data sample is defined as: {
Table 3: System and parallel configuration for GRPO training. Item Setting GPUs per node 4/8 Nodes 1 Total GPUs 4/8 Precision bfloat16 Attention kernel FlashAttention-2 Gradient checkpointing Enabled DeepSpeed Config ZeRO-3 Table 4: Training schedule and bookkeeping. Item Setting Epochs 2 Per-device batch size 4 Gradient accumulation 2 Effective prompt ba...
work page 2048
-
[18]
grow→touch-cap→recede→stabilize
Completion lengths follow a “grow→touch-cap→recede→stabilize” trajectory. In the ex- ploratory phase, the model often hits the 2048-token limit, which, combined with the length/rep- etition shaping, lowers net returns and nudges the policy toward more compact and more accurate solutions. The stabilized regime features shorter completions that correlate wi...
work page 2048
-
[19]
Table 7: Results on GeoChain subproblems. Index Qwen2.5-VL-7B Geo-SFT Geo-R1-Zero Geo-R1 0 86.75 85.75 91.75 91.50 1 73.00 82.50 93.50 98.875 2 55.75 65.75 87.75 97.75 3 83.75 82.75 81.75 98.125 4 57.25 59.25 63.25 64.75 5 82.50 81.50 99.00 100.00 6 83.25 81.25 90.25 92.00 7 94.25 91.25 84.25 96.75 8 6.625 13.625 31.625 40.25 9 61.50 63.50 22.50 77.75 10 ...
-
[20]
Table 12: Model accuracy on MMMU Yue et al. (2024) Dev. and Validation splits. Model MMMU Dev. MMMU Val. Qwen2.5-VL-7B-Instruct 58.0 54.2 Geo-SFT 56.7 53.4 Geo-R1-Zero 50.7 54.3 Geo-R1 54.0 51.2 Table 13: Model performance on GPQA benchmark results (‘extended’ dataset). Model Accuracy (%) Refusal Rate (%) Geo-SFT 31.1 1.1 Geo-R1-Zero 33.0 1.5 Geo-R1 33.7 ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.