Beyond Memorization: Extending Reasoning Depth with Recurrence, Memory and Test-Time Compute Scaling
Pith reviewed 2026-05-18 20:44 UTC · model grok-4.3
The pith
Neural models infer hidden rules accurately but lose performance over longer chains of reasoning steps
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
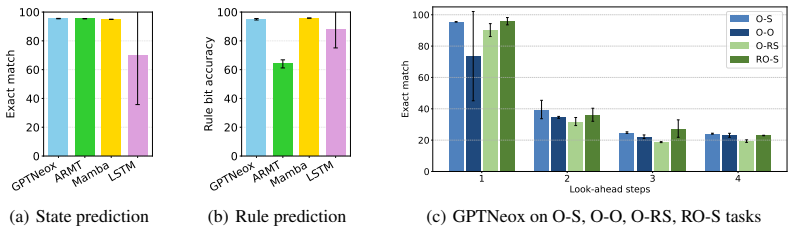
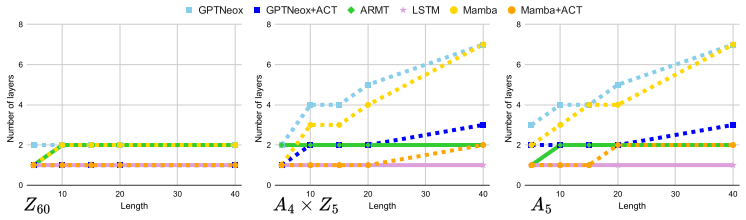
In the 1dCA task with disjoint training and test rules, most neural architectures learn to infer the hidden local rule and achieve high next-step prediction accuracy, yet performance drops sharply once the number of required intermediate reasoning steps grows. Increasing model depth is crucial; augmenting with recurrence, memory, or test-time compute scaling extends reachable depth but leaves performance bounded.
What carries the argument
The disjoint-rule 1d cellular automata prediction task, which forces models to infer a hidden local update rule from examples and then chain repeated applications of that rule over many steps.
If this is right
- Deeper models reach accurate predictions over longer chains of rule applications than shallower ones.
- Recurrent connections let the model reuse the inferred rule across additional steps without losing state information as quickly.
- Extra memory or test-time compute allows the model to simulate greater depth and improves results on multi-step predictions.
- Even after these extensions, accuracy eventually declines, indicating that current architectures still face a hard limit on effective reasoning length.
Where Pith is reading between the lines
- Combining recurrence, memory, and test-time scaling might produce larger gains than any one technique alone, which could be tested directly in the same 1dCA setup.
- The observed bound suggests that reliable long-horizon reasoning may need new ways to detect and correct errors that accumulate over many steps.
- This controlled task could serve as a benchmark for comparing future architectures on pure rule chaining without language or memorization confounds.
Load-bearing premise
The 1dCA task with disjoint train/test rules isolates genuine multi-step rule chaining rather than other factors such as accumulating prediction error or sensitivity to initial state representation.
What would settle it
A model achieving sustained high accuracy across arbitrarily many future steps on the disjoint-rule 1dCA task without any recurrence, memory, or added test-time compute would falsify the claim that performance is inherently bounded by reasoning depth.
Figures










read the original abstract
Reasoning is a core capability of large language models, yet how multi-step reasoning is learned and executed remains unclear. We study this question in a controlled cellular-automata (1dCA) framework that excludes memorisation by using disjoint training and test rules. Given a short state sequence, the model is required to infer the hidden local rule and then chain it to predict multiple future steps. Our evaluation shows that LLMs largely fail to reliably solve a natural-language proxy of the proposed task. We find that most neural architectures trained from scratch can learn rule inference and achieve high next-step accuracy, but performance drops sharply as the required number of intermediate reasoning steps increases. Experiments show that increasing model depth is crucial, and extending effective depth via recurrence, memory, or test-time compute improves results but remains bounded. The code is available on github: https://github.com/RodkinIvan/associative-recurrent-memory-transformer/tree/ACT
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a 1D cellular automata (1dCA) benchmark to investigate multi-step reasoning in neural networks, designed to avoid memorization by using disjoint sets of rules for training and testing. The core experiment requires models to infer a local rule from a short sequence of states and then apply it autoregressively over multiple future steps. Results indicate high accuracy for single-step predictions across various architectures trained from scratch, but a sharp decline as the number of required reasoning steps increases. The authors explore enhancements through increased model depth, recurrence, memory mechanisms, and test-time compute scaling, observing improvements that are nonetheless bounded. Additionally, large language models are shown to underperform on a natural language formulation of the task.
Significance. If substantiated with clearer controls, the findings would be significant for the field of machine learning and AI reasoning. The controlled nature of the 1dCA task provides a clean testbed for studying inference chaining without the confounds of natural language or memorization. The demonstration that recurrence and test-time scaling can extend effective reasoning depth, even if bounded, offers actionable directions for architecture design. The public availability of the code further strengthens the contribution by enabling verification and extension by the community.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and evaluation protocol: the central claim that performance drops sharply with more intermediate reasoning steps reflects a limit on multi-step rule inference depth is load-bearing, yet the 1dCA autoregressive setup does not include controls (e.g., teacher-forced evaluation or oracle rule provision) to separate genuine chaining difficulty from compounding prediction errors due to early state inaccuracies. This leaves open whether recurrence/memory/test-time scaling primarily mitigates depth limits or improves robustness to error propagation.
- [Results] Results on bounded improvements: the statement that extensions via recurrence, memory, or test-time compute 'remain bounded' is central but lacks precise quantification (specific accuracy curves vs. depth/scaling factors, with error bars) to establish the magnitude and robustness of the claimed gains over baseline depth increases.
minor comments (3)
- The abstract and results would benefit from inclusion of quantitative tables reporting exact next-step and multi-step accuracies, standard deviations across runs, and full ablations for each proposed extension (recurrence, memory, test-time compute).
- Clarify notation and implementation details for the 'associative recurrent memory transformer' architecture referenced in the code repository, including how recurrence and memory are integrated with the base transformer.
- Figures showing performance vs. reasoning depth should include error bars, legends, and axis labels for clarity; the natural-language LLM proxy task would benefit from explicit prompt templates and failure mode analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have revised the paper accordingly to improve the evaluation protocol and results presentation.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and evaluation protocol: the central claim that performance drops sharply with more intermediate reasoning steps reflects a limit on multi-step rule inference depth is load-bearing, yet the 1dCA autoregressive setup does not include controls (e.g., teacher-forced evaluation or oracle rule provision) to separate genuine chaining difficulty from compounding prediction errors due to early state inaccuracies. This leaves open whether recurrence/memory/test-time scaling primarily mitigates depth limits or improves robustness to error propagation.
Authors: We agree that the original autoregressive setup leaves some ambiguity between chaining limits and error propagation. In the revised manuscript, we have added teacher-forced evaluation (providing ground-truth states at each step) and an oracle rule provision condition. These controls show that accuracy still declines sharply with depth even when prior states are perfect, indicating a genuine limit on multi-step rule inference rather than solely error accumulation. The new results clarify that recurrence, memory, and test-time compute primarily extend effective reasoning depth. We have updated Section 4 with the revised protocol and added corresponding figures. revision: yes
-
Referee: [Results] Results on bounded improvements: the statement that extensions via recurrence, memory, or test-time compute 'remain bounded' is central but lacks precise quantification (specific accuracy curves vs. depth/scaling factors, with error bars) to establish the magnitude and robustness of the claimed gains over baseline depth increases.
Authors: We acknowledge the need for more precise quantification. The revised results section now includes detailed accuracy curves plotting performance against reasoning depth for different depths, recurrence steps, memory sizes, and test-time compute budgets. All curves include error bars from multiple independent runs. A new table summarizes the maximum reliable depth achieved by each method relative to baseline depth scaling. These additions demonstrate the magnitude of gains and confirm their bounded nature, with improvements plateauing at higher scaling factors. revision: yes
Circularity Check
Empirical evaluation with no circular derivation chain
full rationale
The paper reports experimental results on neural architectures trained from scratch in a 1dCA framework with disjoint train/test rules. Claims about performance drops with increasing reasoning steps and improvements from recurrence, memory, or test-time compute are supported by measured accuracies on held-out data rather than any first-principles derivation, fitted parameters renamed as predictions, or self-citation chains. No equations, ansatzes, or uniqueness theorems are invoked that reduce to the inputs by construction; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The cellular automata update rule is strictly local and deterministic.
- domain assumption Disjoint training and test rules eliminate memorization of specific rule instances.
Forward citations
Cited by 1 Pith paper
-
Diagnosing CFG Interpretation in LLMs
LLMs maintain surface syntax for novel CFGs but fail to preserve semantics under recursion and branching, relying on keyword bootstrapping rather than pure symbolic reasoning.
Reference graph
Works this paper leans on
-
[1]
M. Aach, J. H. Goebbert, and J. Jitsev. Generalization over different cellular automata rules learned by a deep feed-forward neural network, 2021
work page 2021
-
[2]
L. M. Antunes. Cellpylib: A python library for working with cellular automata. Journal of Open Source Software, 6(67):3608, 2021. doi: 10.21105/joss.03608. URL https://doi.org/ 10.21105/joss.03608
- [3]
-
[4]
M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P. Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 17682–17690, 2024
work page 2024
-
[5]
S. Bhattamishra, A. Patel, and N. Goyal. On the computational power of transformers and its implications in sequence modeling. arXiv preprint arXiv:2006.09286, 2020
-
[6]
A. Bibin and A. Dereventsov. Data-centric approach to constrained machine learning: A case study on conway’s game of life.arXiv preprint arXiv:2408.12778, 2024
-
[7]
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
S. Black, S. Biderman, E. Hallahan, Q. Anthony, L. Gao, L. Golding, H. He, C. Leahy, K. McDonell, J. Phang, M. Pieler, U. S. Prashanth, S. Purohit, L. Reynolds, J. Tow, B. Wang, and S. Weinbach. Gpt-neox-20b: An open-source autoregressive language model, 2022. URL https://arxiv.org/abs/2204.06745
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
A. Bulatov, Y . Kuratov, and M. S. Burtsev. Recurrent memory transformer. arXiv preprint arXiv:2207.06881, 2022
-
[9]
A. Bulatov, Y . Kuratov, and M. S. Burtsev. Recurrent memory transformer, 2022
work page 2022
-
[10]
A. Chevalier, A. Wettig, A. Ajith, and D. Chen. Adapting language models to compress contexts. arXiv preprint arXiv:2305.14788, 2023
-
[11]
G. Cybenko. Approximations by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems, 2:183–192, 1989
work page 1989
-
[12]
Z. Dai, Z. Yang, Y . Yang, J. G. Carbonell, Q. Le, and R. Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2978–2988, 2019
work page 2019
-
[13]
M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and L. Kaiser. Universal transformers. In International Conference on Learning Representations, 2019. URL https://openreview. net/forum?id=HyzdRiR9Y7
work page 2019
-
[14]
G. Deletang, A. Ruoss, J. Grau-Moya, T. Genewein, L. K. Wenliang, E. Catt, C. Cundy, M. Hutter, S. Legg, J. Veness, et al. Neural networks and the chomsky hierarchy. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
- [15]
-
[16]
V . Elser. Reconstructing cellular automata rules from observations at nonconsecutive times. Physical Review E, 104(3):034301, 2021
work page 2021
-
[17]
G. Feng, B. Zhang, Y . Gu, H. Ye, D. He, and L. Wang. Towards revealing the mystery behind chain of thought: a theoretical perspective. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
- [18]
- [19]
-
[20]
W. Gilpin. Cellular automata as convolutional neural networks. Physical Review E, 100(3): 032402, 2019
work page 2019
-
[21]
Better & Faster Large Language Models via Multi-token Prediction
F. Gloeckle, B. Y . Idrissi, B. Rozière, D. Lopez-Paz, and G. Synnaeve. Better & faster large language models via multi-token prediction. arXiv preprint arXiv:2404.19737, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [22]
-
[23]
D. Grattarola, L. Livi, and C. Alippi. Learning graph cellular automata. Advances in Neural Information Processing Systems, 34:20983–20994, 2021
work page 2021
-
[24]
A. Graves. Adaptive computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[25]
A. Graves, G. Wayne, and I. Danihelka. Neural turing machines.arXiv preprint arXiv:1410.5401, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
A. Gu, K. Goel, and C. Re. Efficiently modeling long sequences with structured state spaces. In International Conference on Learning Representations, 2021
work page 2021
-
[28]
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
S. Hao, S. Sukhbaatar, D. Su, X. Li, Z. Hu, J. Weston, and Y . Tian. Training large language models to reason in a continuous latent space. arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
S. Hao, S. Sukhbaatar, D. Su, X. Li, Z. Hu, J. Weston, and Y . Tian. Training large language models to reason in a continuous latent space, 2024. URL https://arxiv.org/abs/2412. 06769
work page 2024
-
[31]
A. Havrilla, Y . Du, S. C. Raparthy, C. Nalmpantis, J. Dwivedi-Yu, M. Zhuravinskyi, E. Hambro, S. Sukhbaatar, and R. Raileanu. Teaching large language models to reason with reinforcement learning. arXiv preprint arXiv:2403.04642, 2024
-
[32]
D. Herel and T. Mikolov. Thinking tokens for language modeling. arXiv preprint arXiv:2405.08644, 2024
-
[33]
S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 9(8): 1735–1780, 1997
work page 1997
- [34]
- [35]
-
[36]
B. Kang, H. Kumar, M. Lee, B. Chakraborty, and S. Mukhopadhyay. Learning locally interacting discrete dynamical systems: Towards data-efficient and scalable prediction. In A. Abate, M. Cannon, K. Margellos, and A. Papachristodoulou, editors, Proceedings of the 6th Annual Learning for Dynamics and Control Conference , volume 242 of Proceedings of Machine L...
work page 2024
-
[37]
H. Karloff, S. Suri, and S. Vassilvitskii. A model of computation for mapreduce. InProceedings of the twenty-first annual ACM-SIAM symposium on Discrete Algorithms , pages 938–948. SIAM, 2010
work page 2010
-
[38]
Training Language Models to Self-Correct via Reinforcement Learning
A. Kumar, V . Zhuang, R. Agarwal, Y . Su, J. D. Co-Reyes, A. Singh, K. Baumli, S. Iqbal, C. Bishop, R. Roelofs, et al. Training language models to self-correct via reinforcement learning. arXiv preprint arXiv:2409.12917, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
W. Merrill and A. Sabharwal. The expresssive power of transformers with chain of thought. arXiv preprint arXiv:2310.07923, 2023
-
[40]
W. Merrill and A. Sabharwal. The parallelism tradeoff: Limitations of log-precision transformers. Transactions of the Association for Computational Linguistics, 11:531–545, 2023
work page 2023
-
[41]
W. Merrill and A. Sabharwal. The expressive power of transformers with chain of thought. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[42]
W. Merrill, A. Sabharwal, and N. A. Smith. Saturated transformers are constant-depth threshold circuits. Transactions of the Association for Computational Linguistics, 10:843–856, 2022
work page 2022
-
[43]
W. Merrill, J. Petty, and A. Sabharwal. The illusion of state in state-space models. InProceedings of the 41st International Conference on Machine Learning, pages 35492–35506, 2024
work page 2024
-
[44]
P. Mondorf and B. Plank. Liar, liar, logical mire: A benchmark for suppositional reasoning in large language models. arXiv preprint arXiv:2406.12546, 2024
-
[45]
A. Mordvintsev, E. Randazzo, E. Niklasson, and M. Levin. Growing neural cellular automata. Distill, 5(2):e23, 2020
work page 2020
-
[46]
F. Nowak, A. Svete, A. Butoi, and R. Cotterell. On the representational capacity of neural language models with chain-of-thought reasoning. In L.-W. Ku, A. Martins, and V . Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 12510–12548, Bangkok, Thailand, Aug. 2024. A...
work page 2024
-
[47]
OpenAI. Learning to reason with llms. https://openai.com/index/ learning-to-reason-with-llms/ , 2024. Accessed: 2024-09-23
work page 2024
- [48]
-
[49]
R. Pande and D. Grattarola. Hierarchical neural cellular automata. In Artificial Life Conference Proceedings 35, volume 2023, page 20. MIT Press One Rogers Street, Cambridge, MA 02142- 1209, USA journals-info . . . , 2023
work page 2023
- [50]
-
[51]
J. Pfau, W. Merrill, and S. R. Bowman. Let’s think dot by dot: Hidden computation in transformer language models. In First Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=NikbrdtYvG
work page 2024
-
[52]
J. W. Rae, A. Potapenko, S. M. Jayakumar, C. Hillier, and T. P. Lillicrap. Compressive transformers for long-range sequence modelling. arXiv preprint, 2019. URL https://arxiv. org/abs/1911.05507. 14
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[53]
A. D. Richardson, T. Antal, R. A. Blythe, and L. J. Schumacher. Learning spatio-temporal patterns with neural cellular automata. PLOS Computational Biology, 20(4):e1011589, 2024
work page 2024
- [54]
- [55]
-
[56]
C. Sanford, D. Hsu, and M. Telgarsky. Transformers, parallel computation, and logarithmic depth. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[57]
C. Sanford, D. J. Hsu, and M. Telgarsky. Representational strengths and limitations of trans- formers. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[58]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[59]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
P. Shojaee, I. Mirzadeh, K. Alizadeh, M. Horton, S. Bengio, and M. Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity, 2025. URL https://arxiv.org/abs/2506.06941
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
J. M. Springer and G. T. Kenyon. It’s hard for neural networks to learn the game of life. In2021 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2021
work page 2021
-
[62]
Transformers as recognizers of formal languages: A survey on expressivity
L. Strobl, W. Merrill, G. Weiss, D. Chiang, and D. Angluin. Transformers as recognizers of formal languages: A survey on expressivity. arXiv preprint arXiv:2311.00208, 2023
- [63]
-
[64]
M. Tesfaldet, D. Nowrouzezahrai, and C. Pal. Attention-based neural cellular automata. Ad- vances in Neural Information Processing Systems, 35:8174–8186, 2022
work page 2022
-
[65]
Solving math word problems with process- and outcome-based feedback
J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[66]
K. Valmeekam, K. Stechly, and S. Kambhampati. Llms still can’t plan; can lrms? a preliminary evaluation of openai’s o1 on planbench.arXiv preprint arXiv:2409.13373, 2024
-
[67]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is All you Need. In Advances in neural information processing systems , pages 5998–6008, 2017. URL http://papers.nips.cc/paper/ 7181-attention-is-all-you-need
work page 2017
-
[68]
Y . Wan, W. Wang, Y . Yang, Y . Yuan, J.-t. Huang, P. He, W. Jiao, and M. Lyu. LogicAsker: Evaluating and improving the logical reasoning ability of large language models. In Y . Al- Onaizan, M. Bansal, and Y .-N. Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2124–2155, Miami, Florida, USA, Nov...
-
[69]
P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y . Li, D. Chen, Y . Wu, and Z. Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. In L.-W. Ku, A. Martins, and V . Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, Bangkok, Thailand...
-
[70]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022. 15
work page 2022
-
[71]
J. Weston, S. Chopra, and A. Bordes. Memory networks. In Y . Bengio and Y . LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1410.3916
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[72]
N. Wulff and J. A. Hertz. Learning cellular automaton dynamics with neural networks.Advances in Neural Information Processing Systems, 5, 1992
work page 1992
- [73]
-
[74]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
- [75]
- [76]
- [77]
-
[78]
Y . Zhang and H. Bölcskei. Cellular automata, many-valued logic, and deep neural networks. arXiv preprint arXiv:2404.05259, 2024. 16 A Related Work Computational Expressivity. Sanford et al. [56] show that in setups where the input context length grows but the model depth remains constant, transformers achieve logarithmic complexity scaling in input size ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.