ReDef: Do Code Language Models Truly Understand Code Changes for Just-in-Time Software Defect Prediction?
Pith reviewed 2026-05-18 18:20 UTC · model grok-4.3
The pith
Code language models detect defects from superficial cues in diffs rather than genuine semantic understanding of changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
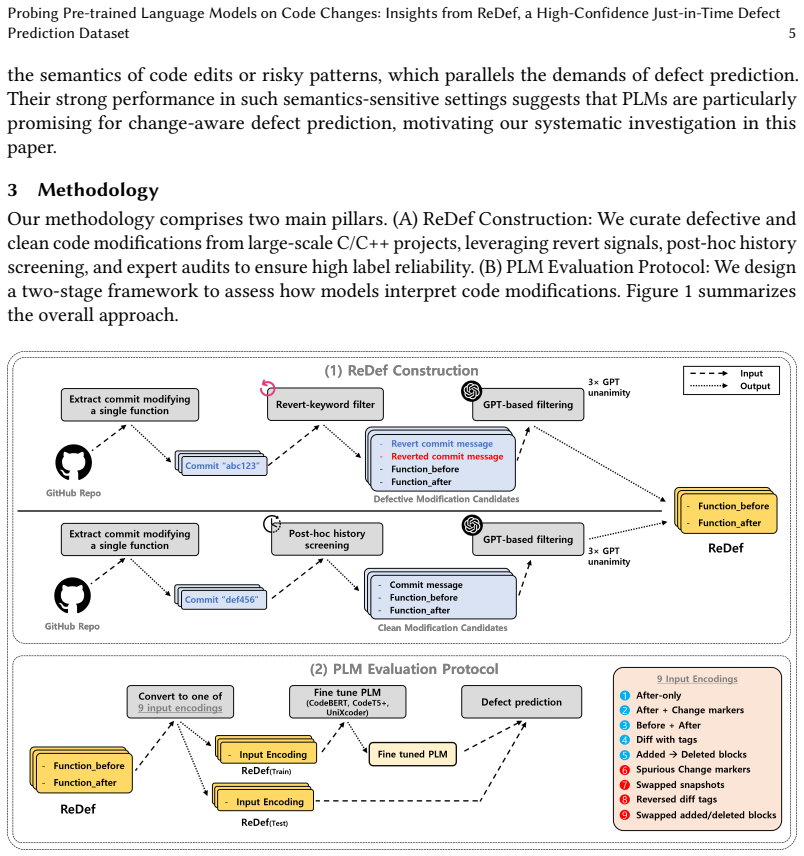
ReDef supplies 3,164 defective and 10,268 clean modifications with reliable labels derived from revert commits and conservative GPT triage. Across CodeBERT, CodeT5+, UniXcoder, and Qwen2.5, compact diff-style encodings yield higher predictive performance than full-function formats. Four counterfactual strategies that distort change semantics leave performance essentially unchanged, which the paper interprets as evidence that models rely on superficial cues rather than semantic understanding of modifications.
What carries the argument
Counterfactual perturbation strategies (swapping added/deleted blocks, inverting diff polarity) applied as diagnostic probes on top of the ReDef dataset to test whether models capture change semantics.
If this is right
- Compact diff-style encodings improve JIT defect prediction accuracy for current code language models.
- Models that remain stable under semantic distortions will likely fail on novel or complex change patterns.
- High-quality datasets anchored by revert commits enable more trustworthy comparisons of model robustness.
- Current evaluation practices may overstate model capability for real-world code review assistance.
- Training objectives that penalize performance on perturbed inputs could be needed to build genuine change understanding.
Where Pith is reading between the lines
- The same superficial-cue reliance may appear in other code-related tasks that involve diffs or edits.
- One extension would be to fine-tune models explicitly on ReDef plus its perturbed variants and measure whether robustness improves.
- The results connect to broader questions about whether language models learn causal semantics or statistical associations in structured inputs like code.
- Similar counterfactual probes could be applied to non-CLM approaches such as graph-based or rule-based defect predictors.
Load-bearing premise
Revert commits accurately mark bug-inducing changes and the GPT-assisted multi-vote triage removes ambiguous cases without systematic bias in labels.
What would settle it
A clear drop in model accuracy on a held-out set of verified bug-inducing changes after applying the same block-swap or polarity-inversion perturbations that produced stable results in the reported tests.
Figures

read the original abstract
Just-in-Time software defect prediction (JIT-SDP) plays a critical role in prioritizing risky code changes during code review and continuous integration. However, existing datasets often suffer from noisy labels and low precision in identifying bug-inducing commits. To address this, we present ReDef (Revert-based Defect dataset), a high-confidence benchmark of function-level modifications curated from 22 large-scale C/C++ projects. Defective cases are anchored by revert commits, while clean cases are validated through post-hoc history checks. Ambiguous instances are conservatively filtered out via a GPT-assisted triage process involving multiple votes and audits. This pipeline yields 3,164 defective and 10,268 clean modifications, offering substantially more reliable labels than prior resources. Beyond dataset construction, we provide a systematic evaluation of how Code Language Models (CLMs)-specifically CodeBERT, CodeT5+, UniXcoder, and Qwen2.5-reason about code modifications. We first investigate which input encodings most effectively expose change information under five different strategies. We then design four counterfactual perturbation strategies (e.g., swapping added/deleted blocks, inverting diff polarity) to serve as diagnostic probes. We posit that if models genuinely capture change semantics, such distortions should lead to a clear decline in predictive performance. Our results show that compact diff-style encodings consistently outperform whole-function formats across all CLMs, supported by rigorous statistical confirmation. However, under counterfactual tests, performance remains effectively stable, revealing that what appears to be robustness in fact reflects a reliance on superficial cues rather than true semantic understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReDef, a new high-confidence benchmark dataset for just-in-time software defect prediction (JIT-SDP) comprising 3,164 defective and 10,268 clean function-level modifications from 22 large-scale C/C++ projects. Defective cases are anchored by revert commits and clean cases by post-hoc history checks plus GPT-assisted multi-vote triage to filter ambiguous instances. The authors systematically evaluate Code Language Models (CodeBERT, CodeT5+, UniXcoder, Qwen2.5) across five input encoding strategies for code changes and apply four counterfactual perturbation probes (e.g., swapping added/deleted blocks, inverting diff polarity). They report that compact diff-style encodings outperform whole-function formats with statistical confirmation, yet model performance remains stable under perturbations, concluding that apparent robustness reflects reliance on superficial cues rather than true semantic understanding of code changes.
Significance. If the ReDef labels are shown to be high-precision, the work offers a valuable diagnostic contribution to the field by demonstrating that current CLMs may not capture genuine change semantics in defect prediction tasks. The use of counterfactual tests as probes and the focus on encoding formats provide a useful framework for future evaluations. The dataset itself could serve as a stronger baseline for JIT-SDP research compared to noisier prior resources, provided label validity is established.
major comments (2)
- [Dataset Construction] The central interpretive claim—that stable performance under counterfactual perturbations reveals reliance on superficial cues rather than semantic understanding—depends entirely on the reliability of the ReDef labels. In the dataset construction pipeline, the assumption that revert commits reliably mark bug-inducing changes (and that GPT multi-vote triage introduces no systematic bias) is asserted but not supported by quantitative validation, such as manual audit rates or analysis of non-bug revert reasons (e.g., refactoring or dependency updates). This is load-bearing for both the performance gap results and the counterfactual conclusions.
- [Results and Analysis] The abstract states that compact diff-style encodings 'consistently outperform whole-function formats across all CLMs, supported by rigorous statistical confirmation.' However, without reported details on the specific statistical tests, p-values, effect sizes, or confidence intervals (presumably in the results section or associated tables), the strength of this outperformance claim cannot be fully assessed and risks overinterpretation of the encoding comparison.
minor comments (2)
- [Counterfactual Perturbation Strategies] The description of the four counterfactual perturbation strategies is high-level; including one or two concrete before/after examples (perhaps in a table or figure) would clarify how the probes are implemented and aid reproducibility.
- [Dataset Construction] Project selection criteria for the 22 C/C++ repositories are not detailed in the provided summary; adding a brief justification or table of project characteristics (size, domain, history length) would strengthen the dataset description.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating where we agree and what revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Dataset Construction] The central interpretive claim—that stable performance under counterfactual perturbations reveals reliance on superficial cues rather than semantic understanding—depends entirely on the reliability of the ReDef labels. In the dataset construction pipeline, the assumption that revert commits reliably mark bug-inducing changes (and that GPT multi-vote triage introduces no systematic bias) is asserted but not supported by quantitative validation, such as manual audit rates or analysis of non-bug revert reasons (e.g., refactoring or dependency updates). This is load-bearing for both the performance gap results and the counterfactual conclusions.
Authors: We agree that explicit quantitative validation of label quality is important for supporting the interpretive claims. Revert commits are a standard anchoring mechanism in JIT-SDP literature precisely because they provide direct evidence of defect introduction, and our pipeline applies additional post-hoc checks plus conservative multi-vote GPT triage with audits to exclude ambiguous cases. To directly address the concern, we will add a dedicated subsection to the dataset construction section that reports manual audit results on a random sample of 200 instances (stratified by project and label), including agreement rates, and a breakdown of revert commit reasons to quantify the proportion attributable to non-bug factors such as refactoring. revision: yes
-
Referee: [Results and Analysis] The abstract states that compact diff-style encodings 'consistently outperform whole-function formats across all CLMs, supported by rigorous statistical confirmation.' However, without reported details on the specific statistical tests, p-values, effect sizes, or confidence intervals (presumably in the results section or associated tables), the strength of this outperformance claim cannot be fully assessed and risks overinterpretation of the encoding comparison.
Authors: The manuscript reports the statistical analysis supporting the encoding comparison in Section 5.2 and the associated tables, using Wilcoxon signed-rank tests with p-values and effect sizes. To improve clarity and prevent any risk of overinterpretation, we will revise the abstract to explicitly name the statistical test employed and will add a brief summary paragraph in the results section that highlights the key p-values, effect sizes, and confidence intervals for the encoding comparisons. revision: partial
Circularity Check
No circularity: empirical dataset and evaluation study
full rationale
This is an empirical paper focused on constructing the ReDef dataset from external open-source project histories (revert commits for defective labels, post-hoc checks for clean labels, and GPT multi-vote filtering) and then running controlled experiments on CLMs with different input encodings and counterfactual perturbations. No mathematical derivations, equations, fitted parameters, or first-principles claims appear in the provided text. All performance comparisons and robustness conclusions are grounded in direct experimental measurements on the curated external data rather than reducing to self-definitions, self-citations, or renamings of inputs. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Revert commits reliably indicate bug-inducing changes
- domain assumption GPT-assisted multi-vote triage accurately filters ambiguous instances without bias
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
compact diff-style encodings consistently outperform whole-function formats... performance remains effectively stable under counterfactual tests
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Manar Abu Talib, Ali Bou Nassif, Mohammad Azzeh, Yaser Alesh, and Yaman Afadar. Parameter-efficient fine-tuning of pre-trained code models for just-in-time defect prediction.Neural Computing and Applications, 36(27):16911–16940, 2024
work page 2024
-
[2]
Petar Afric, Davor Vukadin, Marin Silic, and Goran Delac. Empirical study: How issue classification influences software defect prediction.IEEE access, 11:11732–11748, 2023
work page 2023
-
[3]
Syafiq Al Atiiq, Christian Gehrmann, and Kevin Dahlén. Vulnerability detection in popular programming languages with language models.arXiv preprint arXiv:2412.15905, 2024
-
[4]
A Balaram and S Vasundra. Prediction of software fault-prone classes using ensemble random forest with adaptive synthetic sampling algorithm.Automated Software Engineering, 29(1):6, 2022
work page 2022
-
[5]
Robert M Bell, Thomas J Ostrand, and Elaine J Weyuker. The limited impact of individual developer data on software defect prediction.Empirical Software Engineering, 18(3):478–505, 2013
work page 2013
-
[6]
Diversevul: A new vulnerable source code dataset for deep learning based vulnerability detection
Yizheng Chen, Zhoujie Ding, Lamya Alowain, Xinyun Chen, and David Wagner. Diversevul: A new vulnerable source code dataset for deep learning based vulnerability detection. InProceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses, pages 654–668, 2023
work page 2023
-
[7]
Jacob Cohen.Statistical power analysis for the behavioral sciences. routledge, 2013
work page 2013
-
[8]
Abdelhalim Dahou, Ansgar Scherp, Sebastian Kurten, Brigitte Mathiak, and Madhu Chauhan. Semantic source code segmentation using small and large language models.arXiv preprint arXiv:2507.08992, 2025
-
[9]
Yangruibo Ding, Yanjun Fu, Omniyyah Ibrahim, Chawin Sitawarin, Xinyun Chen, Basel Alomair, David Wagner, Baishakhi Ray, and Yizheng Chen. Vulnerability detection with code language models: How far are we?arXiv preprint arXiv:2403.18624, 2024. 16 Nam et al
-
[10]
Predicting defect-prone software modules using support vector machines
Karim O Elish and Mahmoud O Elish. Predicting defect-prone software modules using support vector machines. Journal of Systems and Software, 81(5):649–660, 2008
work page 2008
-
[11]
Ac/c++ code vulnerability dataset with code changes and cve summaries
Jiahao Fan, Yi Li, Shaohua Wang, and Tien N Nguyen. Ac/c++ code vulnerability dataset with code changes and cve summaries. InProceedings of the 17th international conference on mining software repositories, pages 508–512, 2020
work page 2020
-
[12]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. Codebert: A pre-trained model for programming and natural languages.arXiv preprint arXiv:2002.08155, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[13]
Shuzheng Gao, Wenxin Mao, Cuiyun Gao, Li Li, Xing Hu, Xin Xia, and Michael R Lyu. Learning in the wild: Towards leveraging unlabeled data for effectively tuning pre-trained code models. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, 2024
work page 2024
-
[14]
Anastasiia Grishina, Max Hort, and Leon Moonen. The earlybird catches the bug: On exploiting early layers of encoder models for more efficient code classification. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 895–907, 2023
work page 2023
-
[15]
UniXcoder: Unified Cross-Modal Pre-training for Code Representation
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. Unixcoder: Unified cross-modal pre-training for code representation.arXiv preprint arXiv:2203.03850, 2022
work page internal anchor Pith review arXiv 2022
-
[16]
A study on the impact of pre-trained model on just-in-time defect prediction
Yuxiang Guo, Xiaopeng Gao, Zhenyu Zhang, Wing Kwong Chan, and Bo Jiang. A study on the impact of pre-trained model on just-in-time defect prediction. In2023 IEEE 23rd International Conference on Software Quality, Reliability, and Security (QRS), pages 105–116. IEEE, 2023
work page 2023
-
[17]
Steffen Herbold, Alexander Trautsch, Fabian Trautsch, and Benjamin Ledel. Problems with szz and features: An empirical study of the state of practice of defect prediction data collection.Empirical Software Engineering, 27(2):42, 2022
work page 2022
-
[18]
Deepjit: an end-to-end deep learning framework for just-in-time defect prediction
Thong Hoang, Hoa Khanh Dam, Yasutaka Kamei, David Lo, and Naoyasu Ubayashi. Deepjit: an end-to-end deep learning framework for just-in-time defect prediction. In2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), pages 34–45. IEEE, 2019
work page 2019
-
[19]
Cc2vec: Distributed representations of code changes
Thong Hoang, Hong Jin Kang, David Lo, and Julia Lawall. Cc2vec: Distributed representations of code changes. In Proceedings of the ACM/IEEE 42nd international conference on software engineering, pages 518–529, 2020
work page 2020
-
[20]
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian journal of statistics, pages 65–70, 1979
work page 1979
-
[21]
A framework for software defect prediction and metric selection.IEEE access, 6:2844–2858, 2017
Shamsul Huda, Sultan Alyahya, Md Mohsin Ali, Shafiq Ahmad, Jemal Abawajy, Hmood Al-Dossari, and John Yearwood. A framework for software defect prediction and metric selection.IEEE access, 6:2844–2858, 2017
work page 2017
-
[22]
Adversarial Examples for Evaluating Reading Comprehension Systems
Robin Jia and Percy Liang. Adversarial examples for evaluating reading comprehension systems.arXiv preprint arXiv:1707.07328, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Yuze Jiang, Beijun Shen, and Xiaodong Gu. Just-in-time software defect prediction via bi-modal change representation learning.Journal of Systems and Software, 219:112253, 2025
work page 2025
-
[24]
Defects4j: A database of existing faults to enable controlled testing studies for java programs
René Just, Darioush Jalali, and Michael D Ernst. Defects4j: A database of existing faults to enable controlled testing studies for java programs. InProceedings of the 2014 international symposium on software testing and analysis, pages 437–440, 2014
work page 2014
-
[25]
Yasutaka Kamei, Emad Shihab, Bram Adams, Ahmed E Hassan, Audris Mockus, Anand Sinha, and Naoyasu Ubayashi. A large-scale empirical study of just-in-time quality assurance.IEEE Transactions on Software Engineering, 39(6): 757–773, 2012
work page 2012
-
[26]
Yasutaka Kamei, Takafumi Fukushima, Shane McIntosh, Kazuhiro Yamashita, Naoyasu Ubayashi, and Ahmed E Hassan. Studying just-in-time defect prediction using cross-project models.Empirical Software Engineering, 21(5):2072–2106, 2016
work page 2072
-
[27]
Yusuf Kartal, E Kaan Akdeniz, and Kemal Özkan. Automating modern code review processes with code similarity measurement.Information and Software Technology, 173:107490, 2024
work page 2024
-
[28]
Tree-based software quality estimation models for fault prediction
Taghi M Khoshgoftaar and Naeem Seliya. Tree-based software quality estimation models for fault prediction. In Proceedings Eighth IEEE Symposium on Software Metrics, pages 203–214. IEEE, 2002
work page 2002
-
[29]
Sunghun Kim, E James Whitehead, and Yi Zhang. Classifying software changes: Clean or buggy?IEEE Transactions on software engineering, 34(2):181–196, 2008
work page 2008
-
[30]
Logistic regression in rare events data.Political analysis, 9(2):137–163, 2001
Gary King and Langche Zeng. Logistic regression in rare events data.Political analysis, 9(2):137–163, 2001
work page 2001
-
[31]
Daniël Lakens. Calculating and reporting effect sizes to facilitate cumulative science: a practical primer for t-tests and anovas.Frontiers in psychology, 4:863, 2013
work page 2013
-
[32]
Automating code review activities by large-scale pre-training
Zhiyu Li, Shuai Lu, Daya Guo, Nan Duan, Shailesh Jannu, Grant Jenks, Deep Majumder, Jared Green, Alexey Svy- atkovskiy, Shengyu Fu, et al. Automating code review activities by large-scale pre-training. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1035–1047, 202...
work page 2022
-
[33]
Cct5: A code-change-oriented pre-trained model
Bo Lin, Shangwen Wang, Zhongxin Liu, Yepang Liu, Xin Xia, and Xiaoguang Mao. Cct5: A code-change-oriented pre-trained model. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1509–1521, 2023
work page 2023
-
[34]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
work page 2017
-
[35]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Yunbo Lyu, Hong Jin Kang, Ratnadira Widyasari, Julia Lawall, and David Lo. Evaluating szz implementations: An empirical study on the linux kernel.IEEE Transactions on Software Engineering, 50(9):2219–2239, 2024
work page 2024
-
[37]
Ruchika Malhotra. A systematic review of machine learning techniques for software fault prediction.Applied Soft Computing, 27:504–518, 2015
work page 2015
-
[38]
Applying codebert for automated program repair of java simple bugs
Ehsan Mashhadi and Hadi Hemmati. Applying codebert for automated program repair of java simple bugs. In2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR), pages 505–509. IEEE, 2021
work page 2021
-
[39]
Topic-based defect prediction (nier track)
Tung Thanh Nguyen, Tien N Nguyen, and Tu Minh Phuong. Topic-based defect prediction (nier track). InProceedings of the 33rd international conference on software engineering, pages 932–935, 2011
work page 2011
-
[40]
Chao Ni, Wei Wang, Kaiwen Yang, Xin Xia, Kui Liu, and David Lo. The best of both worlds: integrating semantic features with expert features for defect prediction and localization. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 672–683, 2022
work page 2022
-
[41]
Function-level vulnerability detection through fusing multi-modal knowledge
Chao Ni, Xinrong Guo, Yan Zhu, Xiaodan Xu, and Xiaohu Yang. Function-level vulnerability detection through fusing multi-modal knowledge. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 1911–1918. IEEE, 2023
work page 1911
-
[42]
An empirical comparison of pre- trained models of source code
Changan Niu, Chuanyi Li, Vincent Ng, Dongxiao Chen, Jidong Ge, and Bin Luo. An empirical comparison of pre- trained models of source code. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 2136–2148. IEEE, 2023
work page 2023
-
[43]
Feifei Niu, Junqian Shao, Christoph Mayr-Dorn, Liguo Huang, Wesley KG Assunção, Chuanyi Li, Jidong Ge, and Alexander Egyed. Refactoring ≠ bug-inducing: Improving defect prediction with code change tactics analysis.arXiv preprint arXiv:2507.19714, 2025
-
[44]
Deep learning for software defect prediction: A survey
Safa Omri and Carsten Sinz. Deep learning for software defect prediction: A survey. InProceedings of the IEEE/ACM 42nd international conference on software engineering workshops, pages 209–214, 2020
work page 2020
-
[45]
How to measure success of fault prediction models
Thomas J Ostrand and Elaine J Weyuker. How to measure success of fault prediction models. InFourth international workshop on Software quality assurance: in conjunction with the 6th ESEC/FSE joint meeting, pages 25–30, 2007
work page 2007
-
[46]
Semantically equivalent adversarial rules for debugging nlp models
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. Semantically equivalent adversarial rules for debugging nlp models. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (volume 1: long papers), pages 856–865, 2018
work page 2018
-
[47]
An industrial study on the risk of software changes
Emad Shihab, Ahmed E Hassan, Bram Adams, and Zhen Ming Jiang. An industrial study on the risk of software changes. InProceedings of the ACM SIGSOFT 20th International Symposium on the Foundations of Software Engineering, pages 1–11, 2012
work page 2012
-
[48]
When do changes induce fixes?ACM sigsoft software engineering notes, 30(4):1–5, 2005
Jacek Śliwerski, Thomas Zimmermann, and Andreas Zeller. When do changes induce fixes?ACM sigsoft software engineering notes, 30(4):1–5, 2005
work page 2005
-
[49]
Automatic code summarization via chatgpt: How far are we?arXiv preprint arXiv:2305.12865, 2023
Weisong Sun, Chunrong Fang, Yudu You, Yun Miao, Yi Liu, Yuekang Li, Gelei Deng, Shenghan Huang, Yuchen Chen, Quanjun Zhang, et al. Automatic code summarization via chatgpt: How far are we?arXiv preprint arXiv:2305.12865, 2023
-
[50]
An introduction to the bootstrap.Monographs on statistics and applied probability, 57(1):1–436, 1993
Robert J Tibshirani and Bradley Efron. An introduction to the bootstrap.Monographs on statistics and applied probability, 57(1):1–436, 1993
work page 1993
-
[51]
Ayşe Tosun, Burak Turhan, and Ayşe Bener. Practical considerations in deploying ai for defect prediction: a case study within the turkish telecommunication industry. InProceedings of the 5th International Conference on Predictor Models in Software Engineering, pages 1–9, 2009
work page 2009
-
[52]
Burak Turhan, Tim Menzies, Ayşe B Bener, and Justin Di Stefano. On the relative value of cross-company and within-company data for defect prediction.Empirical Software Engineering, 14(5):540–578, 2009
work page 2009
-
[53]
Romi Satria Wahono. A systematic literature review of software defect prediction.Journal of software engineering, 1 (1):1–16, 2015
work page 2015
-
[54]
Jun Wang, Beijun Shen, and Yuting Chen. Compressed c4. 5 models for software defect prediction. In2012 12th International Conference on quality software, pages 13–16. IEEE, 2012
work page 2012
-
[55]
Deep semantic feature learning for software defect prediction
Song Wang, Taiyue Liu, Jaechang Nam, and Lin Tan. Deep semantic feature learning for software defect prediction. IEEE Transactions on Software Engineering, 46(12):1267–1293, 2018
work page 2018
-
[56]
Rap-gen: Retrieval-augmented patch generation with codet5 for automatic program repair
Weishi Wang, Yue Wang, Shafiq Joty, and Steven CH Hoi. Rap-gen: Retrieval-augmented patch generation with codet5 for automatic program repair. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 146–158, 2023. 18 Nam et al
work page 2023
-
[57]
CodeT5+: Open Code Large Language Models for Code Understanding and Generation
Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi DQ Bui, Junnan Li, and Steven CH Hoi. Codet5+: Open code large language models for code understanding and generation.arXiv preprint arXiv:2305.07922, 2023
work page internal anchor Pith review arXiv 2023
-
[58]
Ziliang Wang, Ge Li, Jia Li, Yihong Dong, Yingfei Xiong, and Zhi Jin. Line-level semantic structure learning for code vulnerability detection.arXiv preprint arXiv:2407.18877, 2024
-
[59]
Individual comparisons by ranking methods.Biometrics bulletin, 1(6):80–83, 1945
Frank Wilcoxon. Individual comparisons by ranking methods.Biometrics bulletin, 1(6):80–83, 1945
work page 1945
-
[60]
Automated program repair in the era of large pre-trained language models
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1482–1494. IEEE, 2023
work page 2023
-
[61]
Yan Xiao, Xinyue Zuo, Lei Xue, Kailong Wang, Jin Song Dong, and Ivan Beschastnikh. Empirical study on transformer- based techniques for software engineering.arXiv preprint arXiv:2310.00399, 2023
-
[62]
Characterizing and identifying reverted commits
Meng Yan, Xin Xia, David Lo, Ahmed E Hassan, and Shanping Li. Characterizing and identifying reverted commits. Empirical Software Engineering, 24(4):2171–2208, 2019
work page 2019
-
[63]
Deep learning for just-in-time defect prediction
Xinli Yang, David Lo, Xin Xia, Yun Zhang, and Jianling Sun. Deep learning for just-in-time defect prediction. In2015 IEEE International conference on software quality, reliability and security, pages 17–26. IEEE, 2015
work page 2015
-
[64]
Tong Ye, Lingfei Wu, Tengfei Ma, Xuhong Zhang, Yangkai Du, Peiyu Liu, Shouling Ji, and Wenhai Wang. Tram: A token-level retrieval-augmented mechanism for source code summarization.arXiv preprint arXiv:2305.11074, 2023
-
[65]
Ting Zhang, Ivana Clairine Irsan, Ferdian Thung, and David Lo. Revisiting sentiment analysis for software engineering in the era of large language models.ACM Transactions on Software Engineering and Methodology, 34(3):1–30, 2025
work page 2025
-
[66]
Benchmarking Large Language Models for Multi-Language Software Vulnerability Detection,
Ting Zhang, Chengran Yang, Yindu Su, Martin Weyssow, Hung Nguyen, Tan Bui, Hong Jin Kang, Yikun Li, Eng Lieh Ouh, Lwin Khin Shar, et al. Benchmarking large language models for multi-language software vulnerability detection. arXiv preprint arXiv:2503.01449, 2025
-
[67]
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks.Advances in neural information processing systems, 32, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.