UTOPY: Unrolling Algorithm Learning via Fidelity Homotopy for Inverse Problems
Pith reviewed 2026-05-18 15:46 UTC · model grok-4.3
The pith
A homotopy continuation method trains unrolled networks for inverse problems by starting with a synthetic well-posed sensing matrix and transitioning smoothly to the target ill-posed operator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
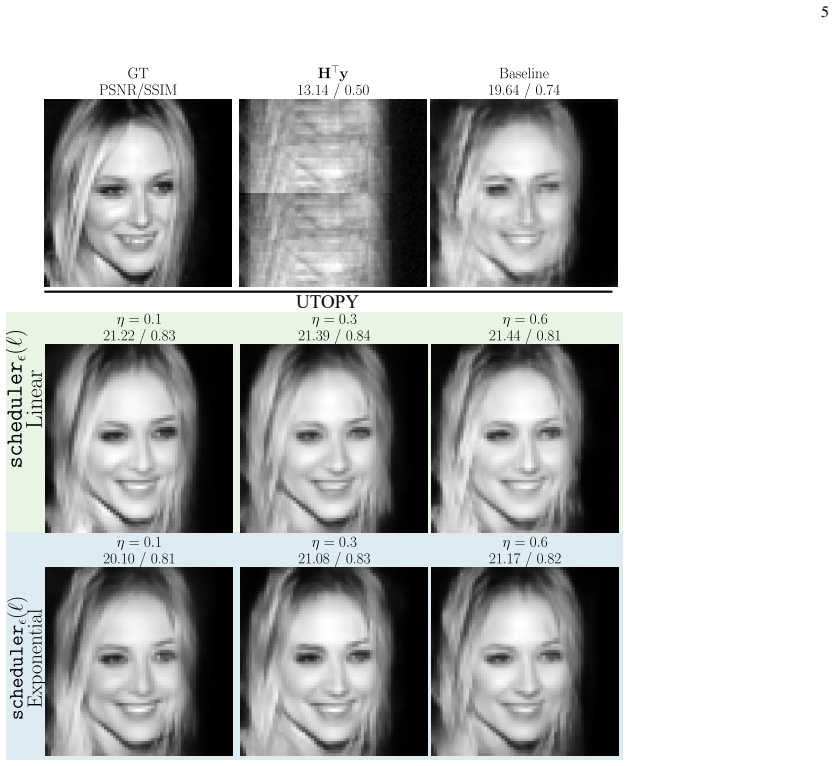
By formulating training as a fidelity homotopy continuation problem that transitions the sensing operator from a chosen synthetic well-posed matrix to the desired ill-posed operator, the method generates a smooth path of unrolling solutions for projected gradient descent-like models and yields higher reconstruction quality on imaging inverse problems.
What carries the argument
The fidelity homotopy continuation path that smoothly changes the data-fidelity term from a synthetic well-posed sensing matrix to the target ill-posed operator during network optimization.
If this is right
- The continuation strategy produces a smooth path of unrolling solutions for projected gradient descent-like models.
- Unrolled networks trained this way achieve higher reconstruction accuracy than those trained directly on the ill-posed operator.
- Performance gains reach up to 2.5 dB PSNR on compressive sensing and image deblurring tasks.
- The approach mitigates poor convergence that arises when gradient steps are taken on highly ill-posed data-fidelity terms.
Where Pith is reading between the lines
- The homotopy idea may apply to unrolling architectures beyond projected gradient descent.
- Similar gradual-difficulty training could help other optimization-based learning problems that suffer from ill-posedness.
- The results suggest that curriculum-style scheduling of problem difficulty can steer unrolled networks away from poor local minima.
- The method could be tested on additional inverse problems such as super-resolution where the degree of ill-posedness varies.
Load-bearing premise
A smooth homotopy path from a synthetic well-posed sensing matrix to the real ill-posed operator will let the unrolled network converge to a better solution without introducing instability or new local minima.
What would settle it
An experiment in which networks trained with the continuation path show no PSNR gain or exhibit instability relative to direct training on the target operator, or in which the theoretical smoothness of the solution path fails to hold.
Figures


read the original abstract
Imaging Inverse problems aim to reconstruct an underlying image from undersampled, coded, and noisy observations. Within the wide range of reconstruction frameworks, the unrolling algorithm is one of the most popular due to the synergistic integration of traditional model-based reconstruction methods and modern neural networks, providing an interpretable and highly accurate reconstruction. However, when the sensing operator is highly ill-posed, gradient steps on the data-fidelity term can hinder convergence and degrade reconstruction quality. To address this issue, we propose UTOPY, a homotopy continuation formulation for training the unrolling algorithm. Mainly, this method involves using a well-posed (synthetic) sensing matrix at the beginning of the unrolling network optimization. We define a continuation path strategy to transition smoothly from the synthetic fidelity to the desired ill-posed problem. This strategy enables the network to progressively transition from a simpler, well-posed inverse problem to the more challenging target scenario. We theoretically show that, for projected gradient descent-like unrolling models, the proposed continuation strategy generates a smooth path of unrolling solutions. Experiments on compressive sensing and image deblurring demonstrate that our method consistently surpasses conventional unrolled training, achieving up to 2.5 dB PSNR improvement in reconstruction performance. Source code at
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UTOPY, a homotopy continuation strategy for training unrolled networks on imaging inverse problems. It begins optimization with a synthetic well-posed sensing matrix and transitions via a continuation path to the target ill-posed operator. The central claims are a theoretical result that this strategy produces a smooth path of solutions for projected gradient descent-like unrollings, plus empirical gains of up to 2.5 dB PSNR over standard unrolled training on compressive sensing and deblurring tasks.
Significance. If the smoothness guarantee extends to the joint optimization regime actually used in training, the method offers a principled way to stabilize and improve unrolled models on severely ill-posed operators. The source-code release supports reproducibility and allows direct testing of the continuation path.
major comments (2)
- [Theoretical analysis] Theoretical analysis section: the smoothness result is derived for fixed-weight PGD-like unrollings in which only the sensing matrix varies along the homotopy path. The actual algorithm jointly optimizes network weights and the homotopy parameter; the provided proof does not address this coupled dynamics, which is load-bearing for the claim that the continuation strategy reliably generates a smooth path of learned solutions.
- [Experiments] Experiments section: the reported maximum 2.5 dB PSNR improvement is stated without accompanying standard deviations, number of random seeds, or statistical tests, making it impossible to judge whether the gain is robust or could be explained by optimization variance.
minor comments (2)
- [Method] The continuation path is described only at a high level; an explicit schedule or pseudocode for the homotopy parameter update would improve clarity.
- [Preliminaries] Notation for the synthetic and target operators should be introduced once and used consistently to avoid confusion between the well-posed proxy and the ill-posed target.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review of our manuscript. We appreciate the positive assessment of the method's potential and the source-code release. We address each major comment below, indicating planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the smoothness result is derived for fixed-weight PGD-like unrollings in which only the sensing matrix varies along the homotopy path. The actual algorithm jointly optimizes network weights and the homotopy parameter; the provided proof does not address this coupled dynamics, which is load-bearing for the claim that the continuation strategy reliably generates a smooth path of learned solutions.
Authors: We thank the referee for highlighting this distinction. The theoretical result in Section 3 is indeed derived under the assumption of fixed network weights, with only the sensing operator varying continuously along the homotopy path; this establishes that the sequence of PGD-like unrolling solutions remains smooth. The training procedure does jointly optimize the weights together with the homotopy schedule. We acknowledge that the current proof does not explicitly analyze the coupled dynamics of weight updates and homotopy progression. In the revised manuscript we will (i) explicitly state the fixed-weight assumption of the theorem, (ii) add a discussion clarifying that the continuation path is intended to provide a stabilizing curriculum even under joint optimization, and (iii) include additional empirical diagnostics (e.g., monitoring of solution-path continuity during training) to support the practical utility of the approach. We believe these clarifications will address the concern without overstating the theoretical coverage. revision: yes
-
Referee: [Experiments] Experiments section: the reported maximum 2.5 dB PSNR improvement is stated without accompanying standard deviations, number of random seeds, or statistical tests, making it impossible to judge whether the gain is robust or could be explained by optimization variance.
Authors: We agree that the absence of statistical reporting limits the ability to assess robustness. In the revised manuscript we will report mean PSNR and standard deviation over at least five independent random seeds for all compared methods, explicitly state the number of runs, and include paired statistical tests (e.g., Wilcoxon signed-rank or t-tests) to evaluate the significance of the observed improvements. These additions will be incorporated into the experimental tables and text. revision: yes
Circularity Check
No circularity: theoretical smoothness claim and empirical gains are independent of inputs
full rationale
The paper defines a homotopy continuation path from a synthetic well-posed sensing matrix to the target ill-posed operator and states a theoretical result that this path produces smooth unrolling solutions for projected gradient descent-like models. This result is presented as a derived property of the continuation strategy rather than a redefinition or fit of the network parameters themselves. No equation or claim reduces the smoothness guarantee or the reported PSNR gains to a parameter fitted inside the paper or to a self-citation chain; the continuation is an external training schedule whose effect on convergence is asserted separately from the network weights. The derivation therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel / dAlembert_cosh_solution_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define a continuation path strategy to transition smoothly from the synthetic fidelity to the desired ill-posed problem... Theorem 1 (Smooth path of unrolled solutions). Under A1–A2 the fixed-point equation x=T_α(x) admits a unique solution x̂_α=fix(T_α) for every α∈[0,1]. The mapping α↦x̂_α lies in C^1[0,1] and obeys ∥x̂_α1−x̂_α2∥2≤τL/(1−β(1−τL))|α1−α2|.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection / RCLCombiner_isCoupling_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
g_α(x)=(1−α)½∥y−Hx∥²₂ + α½∥y_t−H_t x∥²₂ ... α:1→0 during training
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Discovery of unobservable parameters via physical embedding
PEIL learns unobservable parameters by embedding them in a physics-based reconstruction loop, outperforming supervised baselines with ground-truth access while enabling zero-shot generalization and major data reductio...
Reference graph
Works this paper leans on
-
[1]
Linear inverse problems with discrete data. i. general formulation and singular system analysis,
M. Bertero, C. De Mol, and E. R. Pike, “Linear inverse problems with discrete data. i. general formulation and singular system analysis,” Inverse problems, vol. 1, no. 4, p. 301, 1985
work page 1985
-
[2]
Learning point spread function invertibility assessment for image deconvolution,
R. Gualdr ´on-Hurtado, R. Jacome, S. Urrea, H. Arguello, and L. Gonzalez, “Learning point spread function invertibility assessment for image deconvolution,” in 2024 32nd European Signal Processing Conference (EUSIPCO), 2024, pp. 501–505
work page 2024
- [3]
-
[4]
Image super-resolution via sparse representation,
J. Yang et al., “Image super-resolution via sparse representation,” IEEE transactions on image processing, vol. 19, no. 11, pp. 2861–2873, 2010
work page 2010
-
[5]
An introduction to compressive sampling,
E. J. Candes and M. B. Wakin, “An introduction to compressive sampling,” IEEE Signal Processing Magazine, vol. 25, no. 2, pp. 21–30, 2008
work page 2008
-
[6]
M. Lustig, D. L. Donoho, J. M. Santos, and J. M. Pauly, “Compressed sensing mri,” IEEE signal processing magazine, vol. 25, no. 2, pp. 72–82, 2008
work page 2008
-
[7]
Iterative reconstruction techniques for computed tomography part 1: technical principles,
M. J. Willemink, P. A. de Jong, T. Leiner, L. M. de Heer, R. A. Nievelstein, R. P. Budde, and A. M. Schilham, “Iterative reconstruction techniques for computed tomography part 1: technical principles,” European radiology, vol. 23, pp. 1623–1631, 2013
work page 2013
-
[8]
Deep learning techniques for inverse problems in imaging,
G. Ongie, A. Jalal, C. A. M. R. G. Baraniuk, A. G. Dimakis, and R. Willett, “Deep learning techniques for inverse problems in imaging,” IEEE Journal on Selected Areas in Information Theory, 2020
work page 2020
-
[9]
Deep learning methods for solving linear inverse problems: Research directions and paradigms,
Y . Bai, W. Chen, J. Chen, and W. Guo, “Deep learning methods for solving linear inverse problems: Research directions and paradigms,” Signal Processing, vol. 177, p. 107729, 2020
work page 2020
-
[10]
M. Bertero, P. Boccacci, and C. De Mol, Introduction to inverse problems in imaging. CRC press, 2021
work page 2021
-
[11]
Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing,
V . Monga, Y . Li, and Y . C. Eldar, “Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing,” IEEE Signal Processing Magazine, vol. 38, no. 2, pp. 18–44, 2021
work page 2021
-
[12]
Learning fast approximations of sparse coding,
K. Gregor and Y . LeCun, “Learning fast approximations of sparse coding,” in Proceedings of the 27th international conference on international conference on machine learning, 2010, pp. 399–406
work page 2010
-
[13]
Deep generalized unfolding networks for image restoration,
C. Mou, Q. Wang, and J. Zhang, “Deep generalized unfolding networks for image restoration,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 17 399–17 410
work page 2022
-
[14]
Modl: Model-based deep learning architecture for inverse problems,
H. K. Aggarwal, M. P. Mani, and M. Jacob, “Modl: Model-based deep learning architecture for inverse problems,” IEEE transactions on medical imaging, vol. 38, no. 2, pp. 394–405, 2018
work page 2018
-
[15]
Hyperspectral image reconstruction using a deep spatial-spectral prior,
L. Wang, C. Sun, Y . Fu, M. H. Kim, and H. Huang, “Hyperspectral image reconstruction using a deep spatial-spectral prior,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8032–8041
work page 2019
-
[16]
Graph-based algorithm unfolding for energy-aware power allocation in wireless networks,
B. Li, G. Verma, and S. Segarra, “Graph-based algorithm unfolding for energy-aware power allocation in wireless networks,” IEEE Transactions on Wireless Communications, vol. 22, no. 2, pp. 1359–1373, 2022
work page 2022
-
[17]
S. Pinilla, K. V . Mishra, I. Shevkunov, M. Soltanalian, V . Katkovnik, and K. Egiazarian, “Unfolding-aided bootstrapped phase retrieval in optical imaging: Explainable ai reveals new imaging frontiers,” IEEE Signal Processing Magazine, vol. 40, no. 2, pp. 46–60, 2023
work page 2023
-
[18]
Learning to optimize: A primer and a benchmark,
T. Chen, X. Chen, W. Chen, H. Heaton, J. Liu, Z. Wang, and W. Yin, “Learning to optimize: A primer and a benchmark,” Journal of Machine Learning Research, vol. 23, no. 189, pp. 1–59, 2022
work page 2022
-
[19]
E. L. Allgower and K. Georg, Introduction to numerical continuation methods. SIAM, 2003
work page 2003
-
[20]
Y . Bengio, J. Louradour, R. Collobert, and J. Weston, “Curriculum learning,” inProceedings of the 26th Annual International Conference on Machine Learning (ICML), 2009, pp. 41–48
work page 2009
-
[21]
Progressive growing of gans for improved quality, stability, and variation,
T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” in International Conference on Learning Representations (ICLR), 2018
work page 2018
-
[22]
Learned primal-dual reconstruction,
J. Adler and O. ¨Oktem, “Learned primal-dual reconstruction,” in International Conference on Learning Representations (ICLR), 2018
work page 2018
-
[23]
A simple homotopy algorithm for compressive sensing,
L. Zhang, T. Yang, R. Jin, and Z.-H. Zhou, “A simple homotopy algorithm for compressive sensing,” in Artificial Intelligence and Statistics. PMLR, 2015, pp. 1116–1124
work page 2015
-
[24]
Homotopy methods based on l {0}-norm for compressed sensing,
Z. Dong and W. Zhu, “Homotopy methods based on l {0}-norm for compressed sensing,” IEEE transactions on neural networks and learning systems, vol. 29, no. 4, pp. 1132–1146, 2017
work page 2017
-
[25]
H. Zheng, Y . Huang, Z. Huang, W. Hao, and G. Lin, “Hompinns: homotopy physics-informed neural networks for solving the inverse problems of nonlinear differential equations with multiple solutions,” Journal of Computational Physics, 2024
work page 2024
-
[26]
Deep equilibrium architectures for inverse problems in imaging,
D. Gilton, G. Ongie, and R. Willett, “Deep equilibrium architectures for inverse problems in imaging,” IEEE Transactions on Computational Imaging, vol. 7, pp. 1123–1133, 2021
work page 2021
-
[27]
A fast iterative shrinkage-thresholding algorithm for linear inverse problems,
A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM journal on imaging sciences, vol. 2, no. 1, pp. 183–202, 2009
work page 2009
-
[28]
A. Kofler, F. Altekr ¨uger, F. Antarou Ba, C. Kolbitsch, E. Papoutsellis, D. Schote, C. Sirotenko, F. F. Zimmermann, and K. Papafitsoros, “Learning regularization parameter-maps for variational image reconstruction using deep neural networks and algorithm unrolling,” SIAM Journal on Imaging Sciences, vol. 16, no. 4, pp. 2202–2246, 2023
work page 2023
-
[29]
Theoretical perspectives on deep learning methods in inverse problems,
J. Scarlett, R. Heckel, M. R. Rodrigues, P. Hand, and Y . C. Eldar, “Theoretical perspectives on deep learning methods in inverse problems,” IEEE journal on selected areas in information theory, vol. 3, no. 3, pp. 433–453, 2023
work page 2023
-
[30]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in Proceedings of International Conference on Computer Vision (ICCV), December 2015
work page 2015
-
[31]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014. 8
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Focal frequency loss for image reconstruction and synthesis,
L. Jiang, B. Dai, W. Wu, and C. C. Loy, “Focal frequency loss for image reconstruction and synthesis,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 13 919–13 929
work page 2021
-
[33]
Loss functions for image restoration with neural networks,
H. Zhao, O. Gallo, I. Frosio, and J. Kautz, “Loss functions for image restoration with neural networks,” IEEE Transactions on Computational Imaging, vol. 3, no. 1, pp. 47–57, 2017
work page 2017
-
[34]
Computational Optical Learning Library ,
“Computational Optical Learning Library ,” 2024. [Online]. Available: https://pycolibri.github.io/pycolibri/
work page 2024
-
[35]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
work page 2015
-
[36]
Single-pixel phase imaging by fourier spectrum sampling,
X. Hu, H. Zhang, Q. Zhao, P. Yu, Y . Li, and L. Gong, “Single-pixel phase imaging by fourier spectrum sampling,” Applied Physics Letters, vol. 114, no. 5, p. 051102, 2019
work page 2019
-
[37]
Single-pixel imaging via compressive sampling,
M. F. Duarte, M. A. Davenport, D. Takhar, J. N. Laska, T. Sun, K. F. Kelly, and R. G. Baraniuk, “Single-pixel imaging via compressive sampling,” IEEE signal processing magazine, vol. 25, no. 2, pp. 83–91, 2008
work page 2008
-
[38]
Hadamard row-wise generation algorithm,
B. Monroy and J. Bacca, “Hadamard row-wise generation algorithm,” CoRR, 2024
work page 2024
-
[39]
Kamilov et al., “Plug-and-play methods for integrating physical and learned models in computational imaging: Theory, algorithms, and applications,” IEEE Sig. Proc. Mag., vol. 40, no. 1, pp. 85–97, 2023
work page 2023
-
[40]
Plug-and-play image restoration with deep denoiser prior,
K. Zhang, Y . Li, W. Zuo, L. Zhang, L. Van Gool, and R. Timofte, “Plug-and-play image restoration with deep denoiser prior,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 6360–6376, 2021
work page 2021
-
[41]
Deepinverse: A python package for solving imaging inverse problems with deep learning,
J. Tachella, M. Terris, S. Hurault, A. Wang, D. Chen, M.-H. Nguyen, M. Song, T. Davies, L. Davy, J. Dong et al., “Deepinverse: A python package for solving imaging inverse problems with deep learning,” arXiv preprint arXiv:2505.20160, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.