Failure Modes of Maximum Entropy RLHF
Pith reviewed 2026-05-18 13:57 UTC · model grok-4.3
The pith
Maximum entropy RL applied to online RLHF produces overoptimization and unstable KL dynamics, even when entropy regularization is used.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
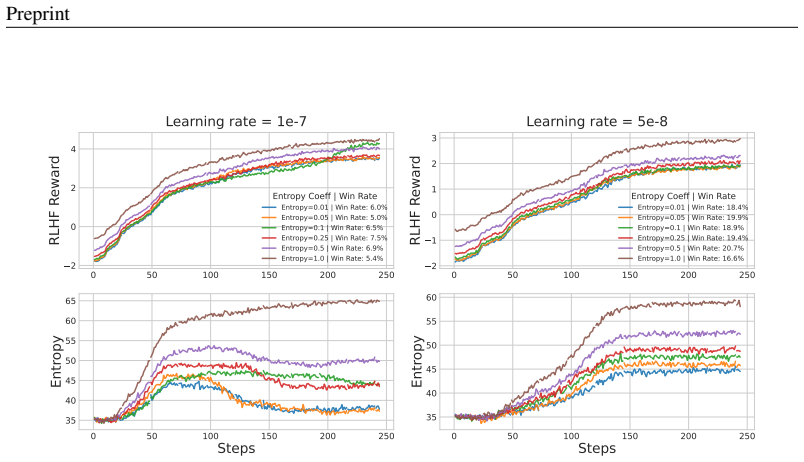
SimPO is equivalent to maximum entropy RL. When the same objective is used for online RLHF, training exhibits overoptimization and unstable KL dynamics across scales. Entropy regularization fails to prevent reward hacking and, in the reported runs, correlates with the start of overoptimization rather than protecting against it. Configurations that remain stable do not owe their stability to the entropy term. The paper contrasts these outcomes with KL-constrained methods that maintain more reliable behavior and discusses why the offline success of SimPO does not transfer to the online regime.
What carries the argument
Derivation of SimPO as a maximum-entropy RL objective followed by its empirical deployment in online RLHF to expose failure modes.
If this is right
- KL-constrained methods keep training stable while entropy regularization does not.
- Overoptimization appears even at conservative learning rates in some configurations.
- Entropy regularization is not the source of stability in runs that remain stable.
- Reference-free methods encounter separate difficulties in online versus offline preference learning.
Where Pith is reading between the lines
- Hybrid objectives that combine entropy with an explicit reference-model KL term may be needed for stable online use of reference-free methods.
- The difference between offline and online regimes may stem from how on-policy sampling amplifies reward-model errors without a fixed reference distribution.
- A direct test would be to add a reference model to the maximum-entropy objective and measure whether the reported instabilities decrease.
Load-bearing premise
The tested model scales, learning rates, and preference datasets are representative enough that the observed overoptimization can be attributed primarily to entropy regularization rather than other implementation choices.
What would settle it
Re-run the online RLHF experiments with the maximum-entropy objective at the reported scales and learning rates while monitoring whether KL divergence stays bounded and reward hacking remains absent.
Figures








read the original abstract
In this paper, we show that Simple Preference Optimization (SimPO) can be derived as Maximum Entropy Reinforcement Learning, providing a theoretical foundation for this reference-free method. Motivated by SimPO's strong performance in offline preference optimization, we investigate whether Maximum Entropy RL can achieve similar results in online RLHF settings. Our experiments find that Maximum Entropy RL frequently exhibits overoptimization and unstable KL dynamics across model scales, with overoptimization persisting even at conservative learning rates for some configurations. Unlike KL-constrained methods that maintain stable training, entropy regularization fails to reliably prevent reward hacking and, in our experiments, correlates with the onset of overoptimization rather than guarding against it. Even in configurations where training remains stable, entropy regularization is not the stabilizing factor. Lastly, we discuss possible explanations for why SimPO succeeds in offline settings while Maximum Entropy RL struggles in online scenarios. Our findings suggest that reference-free approaches may face distinct challenges when applied to online versus offline preference learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives Simple Preference Optimization (SimPO) as an instance of Maximum Entropy Reinforcement Learning and then empirically investigates MaxEnt RL in online RLHF. It reports that MaxEnt RL exhibits overoptimization and unstable KL dynamics across model scales, that entropy regularization fails to prevent reward hacking (unlike KL-constrained baselines), and that these issues persist even at conservative learning rates; the authors discuss why SimPO succeeds offline while MaxEnt RL struggles online.
Significance. If the empirical claims are substantiated with rigorous controls and metrics, the work would usefully document failure modes of entropy regularization in online preference optimization and clarify the offline-online gap for reference-free methods, informing safer RLHF design.
major comments (3)
- [§4] §4 (Experiments): The abstract and results assert 'frequent overoptimization' and 'unstable KL dynamics' yet supply no quantitative metrics (e.g., reward scores, KL values with error bars), baseline comparisons, or statistical tests. Without these, the strength of the central empirical claim cannot be assessed.
- [§4.2] §4.2 and §5: The attribution of overoptimization and KL instability primarily to entropy regularization (rather than reward-model quality, online sampling, learning-rate schedules, or base-model initialization) requires explicit ablations that hold all other pipeline elements fixed while varying only the regularizer. The current controls do not isolate this causal factor.
- [§3] §3 (Derivation): The claim that SimPO is exactly MaxEnt RL should specify whether the equivalence is exact or approximate and how the entropy coefficient maps to the SimPO loss; any definitional overlap with the fitted regularization term should be clarified to avoid circularity in the instability analysis.
minor comments (2)
- [Abstract] Abstract: Adding one sentence on the specific model scales, preference datasets, and learning-rate ranges used would help readers gauge the generality of the reported failure modes.
- [Notation] Notation: The manuscript should consistently distinguish the entropy coefficient from any implicit KL terms when comparing MaxEnt RL to KL-constrained baselines.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We have carefully considered each comment and revised the paper to strengthen the empirical evidence and clarify the theoretical aspects. Below we provide point-by-point responses.
read point-by-point responses
-
Referee: [§4] The abstract and results assert 'frequent overoptimization' and 'unstable KL dynamics' yet supply no quantitative metrics (e.g., reward scores, KL values with error bars), baseline comparisons, or statistical tests. Without these, the strength of the central empirical claim cannot be assessed.
Authors: We agree that quantitative metrics and statistical support would strengthen the presentation. In the revised manuscript we have added tables reporting mean reward scores and KL values with standard deviations across multiple random seeds, direct side-by-side comparisons against KL-constrained baselines, and p-values for the reported differences. These appear in Section 4 and the appendix. revision: yes
-
Referee: [§4.2] The attribution of overoptimization and KL instability primarily to entropy regularization (rather than reward-model quality, online sampling, learning-rate schedules, or base-model initialization) requires explicit ablations that hold all other pipeline elements fixed while varying only the regularizer. The current controls do not isolate this causal factor.
Authors: We appreciate the call for tighter isolation. The revised version includes new ablation experiments that keep the reward model, sampling distribution, learning-rate schedule, and base-model initialization fixed while varying only the choice of regularizer (entropy versus KL penalty). The additional results continue to associate the observed instabilities with entropy regularization in the online regime. revision: yes
-
Referee: [§3] The claim that SimPO is exactly MaxEnt RL should specify whether the equivalence is exact or approximate and how the entropy coefficient maps to the SimPO loss; any definitional overlap with the fitted regularization term should be clarified to avoid circularity in the instability analysis.
Authors: We thank the referee for this precision request. Section 3 presents an exact equivalence between SimPO and MaxEnt RL under the standard assumptions of the framework; the entropy coefficient maps directly to the SimPO beta hyper-parameter via the closed-form derivation we now display explicitly. We have also clarified that the regularization term in SimPO is the entropy objective itself rather than a separately fitted component, removing any potential circularity when analyzing online instability. revision: yes
Circularity Check
No significant circularity; derivation is a mathematical equivalence and experiments are independent empirical observations
full rationale
The paper's core derivation shows SimPO can be obtained from MaxEnt RL objectives via standard RLHF reformulation steps, which constitutes an equivalence rather than a self-referential loop or fitted parameter renamed as prediction. The subsequent empirical investigation of overoptimization and KL instability in online settings relies on direct training runs across model scales and learning rates, without reducing to quantities defined by the same regularization term or self-citation chains. No load-bearing uniqueness theorems, ansatz smuggling, or renaming of known results appear; the claims about entropy regularization failing to stabilize training are presented as observed outcomes, not tautological consequences of the initial derivation. The work is therefore self-contained against external benchmarks for both the theoretical step and the reported failure modes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Maximum Entropy RL is a suitable framework for modeling reference-free preference optimization in both offline and online regimes
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that SimPO can be derived as Maximum Entropy Reinforcement Learning with length-normalized temperature... max_π E[r(x,y)] + α H[π(y|x)]
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
entropy regularization fails to reliably prevent reward hacking and... correlates with the onset of overoptimization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maximum a Posteriori Policy Optimisation
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Riedmiller. Maximum a posteriori policy optimisation. arXiv preprint arXiv:1806.06920, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, and Hao Peng. The unreasonable effectiveness of entropy minimization in llm reasoning, 2025. URL https://arxiv.org/abs/2505.15134
work page internal anchor Pith review arXiv 2025
-
[3]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms, 2024. URL https://arxiv.org/abs/2402.14740
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Understanding the impact of entropy on policy optimization
Zafarali Ahmed, Nicolas Le Roux, Mohammad Norouzi, and Dale Schuurmans. Understanding the impact of entropy on policy optimization. In International conference on machine learning, pp.\ 151--160. PMLR, 2019
work page 2019
-
[5]
A practical analysis of human alignment with *po, 2025
Kian Ahrabian, Xihui Lin, Barun Patra, Vishrav Chaudhary, Alon Benhaim, Jay Pujara, and Xia Song. A practical analysis of human alignment with *po, 2025. URL https://arxiv.org/abs/2407.15229
-
[6]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in ai safety, 2016. URL https://arxiv.org/abs/1606.06565
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
A general theoretical paradigm to understand learning from human preferences, 2023
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. A general theoretical paradigm to understand learning from human preferences, 2023. URL https://arxiv.org/abs/2310.12036
-
[8]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Yoshua Bengio, Tegan Maharaj, Luke Ong, Stuart Russell, Dawn Song, Max Tegmark, Lan Xue, Ya-Qin Zhang, Stephen Casper, Wan Sie Lee, Sören Mindermann, Vanessa Wilfred, Vidhisha Balachandran, Fazl Barez, Michael Belinsky, Imane Bello, Malo Bourgon, Mark Brakel, Siméon Campos, Duncan Cass-Beggs, Jiahao Chen, Rumman Chowdhury, Kuan Chua Seah, Jeff Clune, Junt...
-
[10]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling, 2023. URL https://arxiv.org/abs/2304.01373
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [11]
-
[12]
Deep reinforcement learning from human preferences
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences, 2023. URL https://arxiv.org/abs/1706.03741
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
UltraFeedback: Boosting Language Models with Scaled AI Feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with scaled ai feedback, 2024. URL https://arxiv.org/abs/2310.01377
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. Raft: Reward ranked finetuning for generative foundation model alignment, 2023. URL https://arxiv.org/abs/2304.06767
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Maximum entropy exploration in contextual bandits with neural networks and energy based models
Adam Elwood, Marco Leonardi, Ashraf Mohamed, and Alessandro Rozza. Maximum entropy exploration in contextual bandits with neural networks and energy based models. Entropy, 25 0 (2): 0 188, January 2023. ISSN 1099-4300. doi:10.3390/e25020188. URL http://dx.doi.org/10.3390/e25020188
-
[16]
Maximum entropy rl (provably) solves some robust rl problems
Benjamin Eysenbach and Sergey Levine. Maximum entropy rl (provably) solves some robust rl problems. arXiv preprint arXiv:2103.06257, 2021
-
[17]
Taming the Noise in Reinforcement Learning via Soft Updates
Roy Fox, Ari Pakman, and Naftali Tishby. Taming the noise in reinforcement learning via soft updates. arXiv preprint arXiv:1512.08562, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Scaling laws for reward model overoptimization, 2022
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization, 2022. URL https://arxiv.org/abs/2210.10760
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava S...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Game theory, maximum entropy, minimum discrepancy and robust bayesian decision theory
Peter D Gr \"u nwald and A Philip Dawid. Game theory, maximum entropy, minimum discrepancy and robust bayesian decision theory. 2004
work page 2004
-
[21]
Aman Gupta, Shao Tang, Qingquan Song, Sirou Zhu, Jiwoo Hong, Ankan Saha, Viral Gupta, Noah Lee, Eunki Kim, Siyu Zhu, Parag Agrawal, Natesh Pillai, and S. Sathiya Keerthi. Alphapo: Reward shape matters for llm alignment, 2025. URL https://arxiv.org/abs/2501.03884
-
[22]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ 1861--1870, Stockholmsmässan, Stockholm Sweden, 10--15 Jul 2018. PMLR
work page 2018
-
[23]
Dylan Hadfield-Menell, Smitha Milli, Pieter Abbeel, Stuart Russell, and Anca Dragan. Inverse reward design, 2020. URL https://arxiv.org/abs/1711.02827
-
[24]
A max-min entropy framework for reinforcement learning
Seungyul Han and Youngchul Sung. A max-min entropy framework for reinforcement learning. Advances in Neural Information Processing Systems, 34: 0 25732--25745, 2021
work page 2021
-
[25]
Provably efficient maximum entropy exploration
Elad Hazan, Sham Kakade, Karan Singh, and Abby Van Soest. Provably efficient maximum entropy exploration. In International Conference on Machine Learning, pp.\ 2681--2691. PMLR, 2019
work page 2019
-
[26]
ORPO: Monolithic Preference Optimization without Reference Model
Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model, 2024. URL https://arxiv.org/abs/2403.07691
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Lee, Wen Sun, Akshay Krishnamurthy, and Dylan J
Audrey Huang, Wenhao Zhan, Tengyang Xie, Jason D. Lee, Wen Sun, Akshay Krishnamurthy, and Dylan J. Foster. Correcting the mythos of kl-regularization: Direct alignment without overoptimization via chi-squared preference optimization, 2025. URL https://arxiv.org/abs/2407.13399
-
[28]
A2c is a special case of ppo, 2022
Shengyi Huang, Anssi Kanervisto, Antonin Raffin, Weixun Wang, Santiago Ontañón, and Rousslan Fernand Julien Dossa. A2c is a special case of ppo, 2022. URL https://arxiv.org/abs/2205.09123
-
[29]
The n+ implementation details of rlhf with ppo: A case study on tl;dr summarization, 2024
Shengyi Huang, Michael Noukhovitch, Arian Hosseini, Kashif Rasul, Weixun Wang, and Lewis Tunstall. The n+ implementation details of rlhf with ppo: A case study on tl;dr summarization, 2024. URL https://arxiv.org/abs/2403.17031
-
[30]
An adaptive entropy-regularization framework for multi-agent reinforcement learning
Woojun Kim and Youngchul Sung. An adaptive entropy-regularization framework for multi-agent reinforcement learning. In International Conference on Machine Learning, pp.\ 16829--16852. PMLR, 2023
work page 2023
-
[31]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Qi Liu, Jingqing Ruan, Hao Li, Haodong Zhao, Desheng Wang, Jiansong Chen, Wan Guanglu, Xunliang Cai, Zhi Zheng, and Tong Xu. Amopo: Adaptive multi-objective preference optimization without reward models and reference models, 2025. URL https://arxiv.org/abs/2506.07165
-
[33]
Understanding reference policies in direct preference optimization, 2024
Yixin Liu, Pengfei Liu, and Arman Cohan. Understanding reference policies in direct preference optimization, 2024. URL https://arxiv.org/abs/2407.13709
-
[34]
Leveraging exploration in off-policy algorithms via normalizing flows
Bogdan Mazoure, Thang Doan, Audrey Durand, Joelle Pineau, and R Devon Hjelm. Leveraging exploration in off-policy algorithms via normalizing flows. In Conference on Robot Learning, pp.\ 430--444. PMLR, 2020
work page 2020
-
[35]
Simpo: Simple preference optimization with a reference-free reward, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward, 2024. URL https://arxiv.org/abs/2405.14734
-
[36]
Combining policy gradient and Q-learning
Brendan O'Donoghue, Remi Munos, Koray Kavukcuoglu, and Volodymyr Mnih. Combining policy gradient and q-learning. arXiv preprint arXiv:1611.01626, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[37]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mądry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alex...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
The effects of reward misspecification: Mapping and mitigating misaligned models, 2022
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models, 2022. URL https://arxiv.org/abs/2201.03544
- [40]
-
[41]
Scaling laws for reward model overoptimization in direct alignment algorithms, 2024 a
Rafael Rafailov, Yaswanth Chittepu, Ryan Park, Harshit Sikchi, Joey Hejna, Bradley Knox, Chelsea Finn, and Scott Niekum. Scaling laws for reward model overoptimization in direct alignment algorithms, 2024 a . URL https://arxiv.org/abs/2406.02900
-
[42]
From r to q^* : Your language model is secretly a q-function, 2024 b
Rafael Rafailov, Joey Hejna, Ryan Park, and Chelsea Finn. From r to q^* : Your language model is secretly a q-function, 2024 b . URL https://arxiv.org/abs/2404.12358
-
[43]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model, 2024 c . URL https://arxiv.org/abs/2305.18290
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
On stochastic optimal control and reinforcement learning by approximate inference
Konrad Rawlik, Marc Toussaint, and Sethu Vijayakumar. On stochastic optimal control and reinforcement learning by approximate inference. 2013
work page 2013
-
[45]
Artificial Intelligence and the Problem of Control, pp.\ 19--24
Stuart Russell. Artificial Intelligence and the Problem of Control, pp.\ 19--24. 01 2022. ISBN 978-3-030-86143-8. doi:10.1007/978-3-030-86144-5_3
-
[46]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URL https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [47]
-
[48]
Learning to summarize from human feedback
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback, 2022. URL https://arxiv.org/abs/2009.01325
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
Robust preference optimization via dynamic target margins, 2025
Jie Sun, Junkang Wu, Jiancan Wu, Zhibo Zhu, Xingyu Lu, Jun Zhou, Lintao Ma, and Xiang Wang. Robust preference optimization via dynamic target margins, 2025. URL https://arxiv.org/abs/2506.03690
-
[50]
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. The MIT Press, second edition, 2018. URL http://incompleteideas.net/book/the-book-2nd.html
work page 2018
-
[51]
Robot trajectory optimization using approximate inference
Marc Toussaint. Robot trajectory optimization using approximate inference. In Proceedings of the 26th annual international conference on machine learning, pp.\ 1049--1056, 2009
work page 2009
-
[52]
Trl: Transformer reinforcement learning
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020
work page 2020
-
[53]
Truly proximal policy optimization, 2020
Yuhui Wang, Hao He, Chao Wen, and Xiaoyang Tan. Truly proximal policy optimization, 2020. URL https://arxiv.org/abs/1903.07940
-
[54]
Foster, Akshay Krishnamurthy, Corby Rosset, Ahmed Awadallah, and Alexander Rakhlin
Tengyang Xie, Dylan J. Foster, Akshay Krishnamurthy, Corby Rosset, Ahmed Awadallah, and Alexander Rakhlin. Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf, 2024. URL https://arxiv.org/abs/2405.21046
-
[55]
Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation, 2024 a . URL https://arxiv.org/abs/2401.08417
-
[56]
Jing Xu, Andrew Lee, Sainbayar Sukhbaatar, and Jason Weston. Some things are more cringe than others: Iterative preference optimization with the pairwise cringe loss, 2024 b . URL https://arxiv.org/abs/2312.16682
- [57]
-
[58]
Rrhf: Rank responses to align language models with human feedback without tears, 2023
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. Rrhf: Rank responses to align language models with human feedback without tears, 2023. URL https://arxiv.org/abs/2304.05302
-
[59]
When maximum entropy misleads policy optimization, 2025
Ruipeng Zhang, Ya-Chien Chang, and Sicun Gao. When maximum entropy misleads policy optimization, 2025. URL https://arxiv.org/abs/2506.05615
- [60]
-
[61]
Modeling purposeful adaptive behavior with the principle of maximum causal entropy
Brian D Ziebart. Modeling purposeful adaptive behavior with the principle of maximum causal entropy. Carnegie Mellon University, 2010
work page 2010
-
[62]
Maximum entropy inverse reinforcement learning
Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, Anind K Dey, et al. Maximum entropy inverse reinforcement learning. In Aaai, volume 8, pp.\ 1433--1438. Chicago, IL, USA, 2008
work page 2008
-
[63]
Maximum causal entropy correlated equilibria for markov games
Brian D Ziebart, Drew Bagnell, and Anind K Dey. Maximum causal entropy correlated equilibria for markov games. In Workshops at the Twenty-Fourth AAAI Conference on Artificial Intelligence, 2010
work page 2010
-
[64]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences, 2020. URL https://arxiv.org/abs/1909.08593
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[65]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[66]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[67]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[68]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.