Reinforcement Learning with Discrete Diffusion Policies for Combinatorial Action Spaces
Pith reviewed 2026-05-21 21:10 UTC · model grok-4.3
The pith
Discrete diffusion models can serve as stable policies for RL in large combinatorial action spaces by matching to policy mirror descent targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By defining an ideal regularized target policy via policy mirror descent and framing the update as a distributional matching problem, the discrete diffusion model can be trained to replicate this target, yielding stable and effective policy improvement in combinatorial action spaces.
What carries the argument
Distributional matching of a discrete diffusion model to a policy mirror descent regularized target distribution, which decouples the expressive policy representation from the stability of the update rule.
If this is right
- Superior performance and sample efficiency on DNA sequence generation tasks.
- Effective handling of macro-actions in reinforcement learning.
- Strong results in multi-agent systems with combinatorial action spaces.
- Stable policy updates without requiring additional post-hoc stabilization techniques.
Where Pith is reading between the lines
- The same matching approach could be tested with other generative models as policy classes for discrete spaces.
- This may reduce reliance on hand-crafted action hierarchies in domains like molecular design or logistics planning.
- Extensions to partially observable or non-stationary combinatorial environments remain open for empirical check.
Load-bearing premise
That training the diffusion policy to match the PMD-derived regularized target will produce stable online policy improvement without introducing new instabilities in combinatorial spaces.
What would settle it
If the diffusion policies show no improvement in sample efficiency or final performance over standard baselines on the DNA sequence generation or multi-agent benchmarks, the central claim would be falsified.
Figures









read the original abstract
Reinforcement learning (RL) struggles to scale to large, combinatorial action spaces common in many real-world problems. This paper introduces a novel framework for training discrete diffusion models as highly effective policies in these complex settings. Our key innovation is an efficient online training process that ensures stable and effective policy improvement. By leveraging policy mirror descent (PMD) to define an ideal, regularized target policy distribution, we frame the policy update as a distributional matching problem, training the expressive diffusion model to replicate this stable target. This decoupled approach stabilizes learning and significantly enhances training performance. Our method achieves state-of-the-art results and superior sample efficiency across a diverse set of challenging combinatorial benchmarks, including DNA sequence generation, RL with macro-actions, and multi-agent systems. Experiments demonstrate that our diffusion policies attain superior performance compared to other baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for RL in large combinatorial action spaces by using discrete diffusion models as policies. It defines a regularized target policy distribution via policy mirror descent (PMD) and frames the update as a distributional matching problem, training the diffusion model to replicate the PMD target. This decoupled approach is claimed to stabilize online learning. Experiments on DNA sequence generation, macro-action RL, and multi-agent systems reportedly yield SOTA performance and superior sample efficiency over baselines.
Significance. If the stability and performance claims are substantiated, the work could meaningfully advance scalable RL for high-dimensional discrete problems by combining mirror-descent regularization with the expressivity of diffusion models. This has potential relevance for domains such as biological sequence design and multi-agent planning. The explicit decoupling of target definition from model fitting is a constructive idea worth further development if the approximation errors are shown not to undermine improvement.
major comments (2)
- [§3.2] §3.2 (Policy Update via Distributional Matching): The central claim that matching the diffusion model to the PMD-derived target produces stable online improvement rests on the assumption that approximation error in the diffusion fit does not reintroduce divergence. No explicit error bound, contraction argument, or sensitivity analysis is provided showing how finite-capacity diffusion training interacts with the shifting online target; this is load-bearing for the stability and SOTA sample-efficiency assertions.
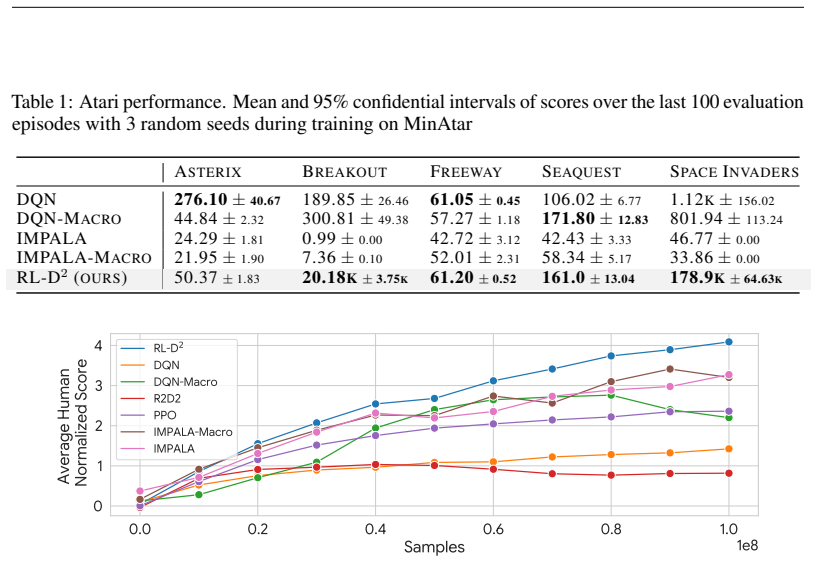
- [§4] §4 (Experimental Evaluation), Tables 1–3: The reported superiority lacks error bars, run counts, statistical tests, and full baseline hyperparameter details. Without these, it is impossible to confirm that gains are not attributable to implementation choices or weak baselines, directly affecting the strength of the combinatorial-benchmark claims.
minor comments (2)
- [§2] Notation for the discrete diffusion forward/reverse processes in §2 could be augmented with a small schematic to improve readability for readers unfamiliar with diffusion policies.
- A few citations to recent discrete diffusion RL works appear incomplete; adding them would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We have carefully considered each point and provide point-by-point responses below. Where appropriate, we have revised the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Policy Update via Distributional Matching): The central claim that matching the diffusion model to the PMD-derived target produces stable online improvement rests on the assumption that approximation error in the diffusion fit does not reintroduce divergence. No explicit error bound, contraction argument, or sensitivity analysis is provided showing how finite-capacity diffusion training interacts with the shifting online target; this is load-bearing for the stability and SOTA sample-efficiency assertions.
Authors: We acknowledge that the manuscript would benefit from a more explicit treatment of approximation errors. In the revised version, we have added a discussion in Section 3.2 on the potential impact of diffusion model approximation errors on policy improvement. Additionally, we include a sensitivity analysis in the experiments section demonstrating that the learned policies remain stable and continue to improve despite finite-capacity fitting. While deriving a rigorous contraction bound for the combined PMD and diffusion approximation is challenging and left for future work, the empirical evidence supports the stability claims. revision: partial
-
Referee: [§4] §4 (Experimental Evaluation), Tables 1–3: The reported superiority lacks error bars, run counts, statistical tests, and full baseline hyperparameter details. Without these, it is impossible to confirm that gains are not attributable to implementation choices or weak baselines, directly affecting the strength of the combinatorial-benchmark claims.
Authors: We agree that providing statistical details is essential for validating the experimental claims. We have revised the experimental section to include error bars (mean ± standard deviation) over multiple independent runs (specifically 5 runs per method), reported the number of runs, included p-values from paired t-tests to assess statistical significance, and expanded the appendix with full hyperparameter configurations for all baselines and our method. These changes strengthen the reliability of the reported SOTA performance and sample efficiency. revision: yes
Circularity Check
No significant circularity: decoupled PMD target definition followed by independent diffusion matching
full rationale
The paper's core construction uses policy mirror descent to first define a regularized target policy distribution, then frames the update as training a discrete diffusion model to match that target. This is explicitly described as a decoupled process in the abstract, with no indication that the target distribution is computed from or fitted to the diffusion parameters themselves. No equations or steps reduce a prediction to its own inputs by construction, and there are no load-bearing self-citations invoking uniqueness theorems or ansatzes from prior author work. The derivation remains self-contained against external benchmarks, as performance claims are evaluated on combinatorial tasks rather than relying on internal redefinitions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Revisiting Policy Gradients for Restricted Policy Classes: Escaping Myopic Local Optima with $k$-step Policy Gradients
The k-step policy gradient converges exponentially close to the optimal deterministic policy in restricted classes, achieving O(1/T) rates under smoothness assumptions without distribution mismatch factors.
Reference graph
Works this paper leans on
-
[1]
Maximum a Posteriori Policy Optimisation
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Riedmiller. Maximum a posteriori policy optimisation. arXiv preprint arXiv:1806.06920, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. arXiv preprint arXiv:2503.09573, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Structured denoising diffusion models in discrete state-spaces
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces. Advances in neural information processing systems, 34: 0 17981--17993, 2021
work page 2021
-
[4]
Effective gene expression prediction from sequence by integrating long-range interactions
Z iga Avsec, Vikram Agarwal, Daniel Visentin, Joseph R Ledsam, Agnieszka Grabska-Barwinska, Kyle R Taylor, Yannis Assael, John Jumper, Pushmeet Kohli, and David R Kelley. Effective gene expression prediction from sequence by integrating long-range interactions. Nature methods, 18 0 (10): 0 1196--1203, 2021
work page 2021
-
[5]
Mirror descent and nonlinear projected subgradient methods for convex optimization
Amir Beck and Marc Teboulle. Mirror descent and nonlinear projected subgradient methods for convex optimization. Operations Research Letters, 31 0 (3): 0 167--175, 2003
work page 2003
-
[6]
The arcade learning environment: An evaluation platform for general agents
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of artificial intelligence research, 47: 0 253--279, 2013
work page 2013
-
[7]
A continuous time framework for discrete denoising models
Andrew Campbell, Joe Benton, Valentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models. Advances in Neural Information Processing Systems, 35: 0 28266--28279, 2022
work page 2022
-
[8]
Budgeted reinforcement learning in continuous state space
Nicolas Carrara, Edouard Leurent, Romain Laroche, Tanguy Urvoy, Odalric-Ambrym Maillard, and Olivier Pietquin. Budgeted reinforcement learning in continuous state space. In Advances in Neural Information Processing Systems 32 (NeurIPS-19), 2019
work page 2019
-
[9]
Dime: Diffusion-based maximum entropy reinforcement learning
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palanicek, Jan Peters, Georgia Chalvatzaki, and Gerhard Neumann. Dime: Diffusion-based maximum entropy reinforcement learning. arXiv preprint arXiv:2502.02316, 2025
-
[10]
Greedification operators for policy optimization: Investigating forward and reverse kl divergences
Alan Chan, Hugo Silva, Sungsu Lim, Tadashi Kozuno, A Rupam Mahmood, and Martha White. Greedification operators for policy optimization: Investigating forward and reverse kl divergences. Journal of Machine Learning Research, 23 0 (253): 0 1--79, 2022
work page 2022
-
[11]
Decision transformer: Reinforcement learning via sequence modeling
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34: 0 15084--15097, 2021
work page 2021
-
[12]
Diffusion-based reinforcement learning via q-weighted variational policy optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via q-weighted variational policy optimization. arXiv preprint arXiv:2405.16173, 2024
-
[13]
Deep Reinforcement Learning With Macro-Actions
Ishan P Durugkar, Clemens Rosenbaum, Stefan Dernbach, and Sridhar Mahadevan. Deep reinforcement learning with macro-actions. arXiv:1606.04615, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. In International conference on machine learning, pp.\ 1407--1416. PMLR, 2018
work page 2018
-
[15]
Model predictive control: Theory and practice—a survey
Carlos E Garcia, David M Prett, and Manfred Morari. Model predictive control: Theory and practice—a survey. Automatica, 25 0 (3): 0 335--348, 1989
work page 1989
-
[16]
Machine-guided design of synthetic cell type-specific cis-regulatory elements
Sager J Gosai, Rodrigo I Castro, Natalia Fuentes, John C Butts, Susan Kales, Ramil R Noche, Kousuke Mouri, Pardis C Sabeti, Steven K Reilly, and Ryan Tewhey. Machine-guided design of synthetic cell type-specific cis-regulatory elements. bioRxiv, 2023
work page 2023
-
[17]
Protein design with guided discrete diffusion
Nate Gruver, Samuel Stanton, Nathan Frey, Tim GJ Rudner, Isidro Hotzel, Julien Lafrance-Vanasse, Arvind Rajpal, Kyunghyun Cho, and Andrew G Wilson. Protein design with guided discrete diffusion. Advances in neural information processing systems, 36: 0 12489--12517, 2023
work page 2023
-
[18]
Latent space policies for hierarchical reinforcement learning
Tuomas Haarnoja, Kristian Hartikainen, Pieter Abbeel, and Sergey Levine. Latent space policies for hierarchical reinforcement learning. In International Conference on Machine Learning, pp.\ 1851--1860. PMLR, 2018
work page 2018
-
[19]
Hierarchical solution of Markov decision processes using macro-actions
Milos Hauskrecht, Nicolas Meuleau, Leslie Pack Kaelbling, Thomas Dean, and Craig Boutilier. Hierarchical solution of Markov decision processes using macro-actions. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence (UAI-98), pp.\ 220--229, Madison, WI, 1998
work page 1998
-
[20]
Pablo Hernandez-Leal, Bilal Kartal, and Matthew E. Taylor. A survey and critique of multiagent deep reinforcement learning. Autonomous Agents and Multi-Agent Systems, 33 0 (6): 0 750--797, 2019
work page 2019
-
[21]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
work page 2020
-
[23]
Acme: A research framework for distributed reinforcement learning
Matthew W Hoffman, Bobak Shahriari, John Aslanides, Gabriel Barth-Maron, Nikola Momchev, Danila Sinopalnikov, Piotr Sta \'n czyk, Sabela Ramos, Anton Raichuk, Damien Vincent, et al. Acme: A research framework for distributed reinforcement learning. arXiv preprint arXiv:2006.00979, 2020
-
[24]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[25]
Distributed Prioritized Experience Replay
Dan Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado Van Hasselt, and David Silver. Distributed prioritized experience replay. arXiv preprint arXiv:1803.00933, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
SlateQ : A tractable decomposition for reinforcement learning with recommendation sets
Eugene Ie, Vihan Jain, Jing Wang, Sanmit Narvekar, Ritesh Agarwal, Rui Wu, Heng-Tze Cheng, Tushar Chandra, and Craig Boutilier. SlateQ : A tractable decomposition for reinforcement learning with recommendation sets. In Proceedings of the Twenty-eighth International Joint Conference on Artificial Intelligence (IJCAI-19), pp.\ 2592--2599, Macau, 2019
work page 2019
-
[27]
Recurrent experience replay in distributed reinforcement learning
Steven Kapturowski, Georg Ostrovski, John Quan, Remi Munos, and Will Dabney. Recurrent experience replay in distributed reinforcement learning. In International conference on learning representations, 2018
work page 2018
-
[28]
Google research football: A novel reinforcement learning environment
Karol Kurach, Anton Raichuk, Piotr Sta \'n czyk, Micha Zaj a c, Olivier Bachem, Lasse Espeholt, Carlos Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet, et al. Google research football: A novel reinforcement learning environment. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp.\ 4501--4510, 2020
work page 2020
-
[29]
Guanghui Lan. Policy mirror descent for reinforcement learning: Linear convergence, new sampling complexity, and generalized problem classes. Mathematical programming, 198 0 (1): 0 1059--1106, 2023
work page 2023
-
[30]
Analysis of classification-based policy iteration algorithms
Alessandro Lazaric, Mohammad Ghavamzadeh, and R \'e mi Munos. Analysis of classification-based policy iteration algorithms. Journal of Machine Learning Research, 17 0 (19): 0 1--30, 2016
work page 2016
-
[31]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. arXiv preprint arXiv:2310.16834, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Soft diffusion actor-critic: Efficient online reinforcement learning for diffusion policy
Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. Soft diffusion actor-critic: Efficient online reinforcement learning for diffusion policy. arXiv preprint arXiv:2502.00361, 2025
-
[33]
Human-level control through deep reinforcement learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. nature, 518 0 (7540): 0 529--533, 2015
work page 2015
-
[34]
Data-efficient hierarchical reinforcement learning
Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning. Advances in neural information processing systems, 31, 2018
work page 2018
-
[35]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Unlocking guidance for discrete state-space diffusion and flow models
Hunter Nisonoff, Junhao Xiong, Stephan Allenspach, and Jennifer Listgarten. Unlocking guidance for discrete state-space diffusion and flow models. arXiv preprint arXiv:2406.01572, 2024
-
[37]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. arXiv preprint arXiv:2406.03736, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Diffusion Policy Policy Optimization
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. arXiv preprint arXiv:2409.00588, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Simple and effective masked diffusion language models
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and Volodymyr Kuleshov. Simple and effective masked diffusion language models. Advances in Neural Information Processing Systems, 37: 0 130136--130184, 2024
work page 2024
-
[40]
Mastering atari, go, chess and shogi by planning with a learned model
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 588 0 (7839): 0 604--609, 2020
work page 2020
-
[41]
Trust Region Policy Optimization
John Schulman. Trust region policy optimization. arXiv preprint arXiv:1502.05477, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[42]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Adaptive trust region policy optimization: Global convergence and faster rates for regularized mdps
Lior Shani, Yonathan Efroni, and Shie Mannor. Adaptive trust region policy optimization: Global convergence and faster rates for regularized mdps. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp.\ 5668--5675, 2020
work page 2020
-
[44]
Simplified and generalized masked diffusion for discrete data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data. Advances in neural information processing systems, 37: 0 103131--103167, 2024
work page 2024
-
[45]
Mastering the game of go with deep neural networks and tree search
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, 529 0 (7587): 0 484--489, 2016
work page 2016
-
[46]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Jascha Sohl-Dickstein , Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep Unsupervised Learning using Nonequilibrium Thermodynamics . In Proceedings of the 32nd International Conference on Machine Learning , pp.\ 2256--2265. PMLR, June 2015
work page 2015
-
[47]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pp.\ 2256--2265. pmlr, 2015
work page 2015
-
[48]
Yan Song, He Jiang, Haifeng Zhang, Zheng Tian, Weinan Zhang, and Jun Wang. Boosting studies of multi-agent reinforcement learning on google research football environment: The past, present, and future. arXiv preprint arXiv:2309.12951, 2023
-
[49]
Reinforcement learning with sequences of motion primitives for robust manipulation
Freek Stulp, Evangelos A Theodorou, and Stefan Schaal. Reinforcement learning with sequences of motion primitives for robust manipulation. IEEE Transactions on robotics, 28 0 (6): 0 1360--1370, 2012
work page 2012
-
[50]
Score-based continuous-time discrete diffusion models
Haoran Sun, Lijun Yu, Bo Dai, Dale Schuurmans, and Hanjun Dai. Score-based continuous-time discrete diffusion models. arXiv preprint arXiv:2211.16750, 2022
-
[51]
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning
Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence, 112 0 (1-2): 0 181--211, 1999 a
work page 1999
-
[52]
Sutton, Doina Precup, and Satinder P
Richard S. Sutton, Doina Precup, and Satinder P. Singh. Between MDPs and Semi-MDPs : Learning, planning, and representing knowledge at multiple temporal scales. Artificial Intelligence, 112: 0 181--211, 1999 b
work page 1999
-
[53]
The natural language of actions
Guy Tennenholtz and Shie Mannor. The natural language of actions. In International Conference on Machine Learning, pp.\ 6196--6205. PMLR, 2019
work page 2019
-
[55]
Mirror descent policy optimization, 2021
Manan Tomar, Lior Shani, Yonathan Efroni, and Mohammad Ghavamzadeh. Mirror descent policy optimization, 2021. URL https://arxiv.org/abs/2005.09814
-
[56]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[57]
Feudal networks for hierarchical reinforcement learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. In International conference on machine learning, pp.\ 3540--3549. PMLR, 2017
work page 2017
-
[58]
Grandmaster level in starcraft ii using multi-agent reinforcement learning
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Micha \"e l Mathieu, Andrew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. nature, 575 0 (7782): 0 350--354, 2019
work page 2019
-
[59]
Chenyu Wang, Masatoshi Uehara, Yichun He, Amy Wang, Tommaso Biancalani, Avantika Lal, Tommi Jaakkola, Sergey Levine, Hanchen Wang, and Aviv Regev. Fine-tuning discrete diffusion models via reward optimization with applications to dna and protein design. arXiv preprint arXiv:2410.13643, 2024 a
-
[60]
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling. arXiv preprint arXiv:2503.00307, 2025
-
[61]
Diffusion Actor-Critic with Entropy Regulator , December 2024 b
Yinuo Wang, Likun Wang, Yuxuan Jiang, Wenjun Zou, Tong Liu, Xujie Song, Wenxuan Wang, Liming Xiao, Jiang Wu, Jingliang Duan, and Shengbo Eben Li. Diffusion Actor-Critic with Entropy Regulator , December 2024 b
work page 2024
-
[62]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv preprint arXiv:2208.06193, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[63]
Multi-agent reinforcement learning is a sequence modeling problem
Muning Wen, Jakub Kuba, Ruiqing Lin, Weinan Zhang, Ying Wen, Jun Wang, and Yaodong Yang. Multi-agent reinforcement learning is a sequence modeling problem. In Advances in Neural Information Processing Systems, volume 35, pp.\ 16706--16719, 2022 a . URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/6b0928e участия82d7349b604bebc53aa1e-Abstract...
work page 2022
-
[64]
Multi-agent reinforcement learning is a sequence modeling problem
Muning Wen, Jakub Kuba, Runji Lin, Weinan Zhang, Ying Wen, Jun Wang, and Yaodong Yang. Multi-agent reinforcement learning is a sequence modeling problem. Advances in Neural Information Processing Systems, 35: 0 16509--16521, 2022 b
work page 2022
-
[65]
Practical and asymptotically exact conditional sampling in diffusion models
Luhuan Wu, Brian Trippe, Christian Naesseth, David Blei, and John P Cunningham. Practical and asymptotically exact conditional sampling in diffusion models. Advances in Neural Information Processing Systems, 36: 0 31372--31403, 2023
work page 2023
-
[66]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
MinAtar: An Atari-Inspired Testbed for Thorough and Reproducible Reinforcement Learning Experiments
Kenny Young and Tian Tian. Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments. arXiv preprint arXiv:1903.03176, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[68]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.