Recognition: no theorem link
Revisiting Policy Gradients for Restricted Policy Classes: Escaping Myopic Local Optima with k-step Policy Gradients
Pith reviewed 2026-05-12 03:56 UTC · model grok-4.3
The pith
A k-step policy gradient couples randomness over multiple steps to escape myopic local optima and converge exponentially close to the optimal deterministic policy in restricted classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By coupling the randomness inside a k-step time window the policy gradient accounts for multi-step effects instead of being limited to the one-step Q-function. Under the assumptions that the value function is smooth and differentiable, both projected gradient descent and mirror descent using the k-step gradient converge in O(1/T) iterations to a policy whose expected return is exponentially close (in k) to that of the optimal deterministic policy. The bounds contain no distribution-mismatch factors of the form ||d_μ^π* / d_μ^π||_∞ or ||d_μ^π* / μ||_∞.
What carries the argument
The k-step policy gradient, formed by coupling the randomness of the trajectory inside a window of k consecutive time steps so that the gradient direction reflects longer-horizon consequences rather than the one-step Q-function alone.
If this is right
- Projected gradient descent using the k-step gradient reaches the stated exponential closeness guarantee in O(1/T) iterations.
- Mirror descent using the same gradient also reaches the guarantee in O(1/T) iterations.
- The method yields near-optimal solutions for state-aggregation problems and partially observable cooperative multi-agent settings.
- The absence of distribution-mismatch terms allows the method to avoid suboptimal points caused by poor exploration even in fully observable environments.
Where Pith is reading between the lines
- If the k-step construction succeeds, similar multi-step couplings could be applied to other constrained policy optimization problems such as safety-constrained or budgeted reinforcement learning.
- A practical test would be to measure the empirical gap on a simple grid-world with state aggregation for k from 1 to 5 and check whether the observed improvement matches the claimed exponential rate.
- The lack of mismatch factors suggests the approach may scale better than standard analyses in very large or continuous state spaces where coverage is uneven.
- Extensions could combine the k-step gradient with modest additional exploration noise to handle cases where even the longer window still encounters dead-ends.
Load-bearing premise
The value function is smooth and differentiable, and the k-step coupling is able to escape the myopic local optima that trap ordinary policy gradients in the restricted-policy MDP.
What would settle it
Construct a small MDP with a deliberately restricted policy class where the ordinary one-step gradient is known to converge to a clearly suboptimal deterministic policy; run the k-step method for increasing values of k and measure whether the performance gap to the true optimum shrinks exponentially with k.
Figures


read the original abstract
This work revisits standard policy gradient methods used on restricted policy classes, which are known to get stuck in suboptimal critical points. We identify an important cause for this phenomenon to be that the policy gradient is itself fundamentally myopic, i.e. it only improves the policy based on the one-step $Q$-function. In this work, we propose a generalized $k$-step policy gradient method that couples the randomness within a $k$-step time window and can escape the myopic local optima in MDPs with restricted policy classes. We show this new method is theoretically guaranteed to converge to a solution that is exponentially close in performance to the optimal deterministic policy with respect to $k$. Further, we show projected gradient descent and mirror descent with this $k$-step policy gradient can achieve this exponential guarantee in $O(\frac{1}{T})$ iterations, despite only assuming smoothness and differentiability of the value function. This will provide near optimal solutions to previously elusive applications like state aggregation and partially observable cooperative multi-agent settings. Moreover, our bounds avoid the ubiquitous distribution mismatch factors $||d_\mu^{\pi^*} / d_\mu^{\pi}||_\infty$ and $||d_\mu^{\pi^*} / \mu||_\infty$ enabling the $k$-step policy gradient method to escape suboptimal critical points that emerge from poor exploration in fully observable settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper revisits policy gradient methods for restricted policy classes in MDPs, identifying the myopic nature of standard one-step gradients as a cause for suboptimal critical points. It proposes a k-step policy gradient that couples randomness over a k-step window to escape these optima. The main claims are that this method converges to a policy whose performance is exponentially close to that of the optimal deterministic policy (with respect to k), and that projected gradient descent and mirror descent applied to the k-step gradient achieve this guarantee in O(1/T) iterations under assumptions of smoothness and differentiability of the value function. The bounds purportedly avoid distribution mismatch factors, with potential applications to state aggregation and partially observable cooperative multi-agent settings.
Significance. If the theoretical results are correct, this work could significantly advance policy optimization in settings where policy classes are restricted, such as state aggregation or POMDPs, by providing a mechanism to reach near-optimal performance without being trapped in myopic local optima. The claimed O(1/T) convergence and avoidance of distribution mismatch factors are particularly noteworthy strengths, as they address common practical challenges in reinforcement learning. The paper's focus on generalizing policy gradients with coupled randomness offers a fresh perspective on escaping suboptimal points.
major comments (2)
- The claim that projected gradient descent and mirror descent with the k-step policy gradient achieve the exponential performance guarantee in O(1/T) iterations, while assuming only smoothness and differentiability of the value function, is central to the contribution. However, in smooth non-convex optimization, convergence to stationary points is typically O(1/sqrt(T)); to obtain O(1/T), a Polyak-Łojasiewicz inequality or strong convexity must hold with modulus independent of k. The manuscript needs to explicitly derive such a curvature bound from the k-step coupling and the MDP structure.
- The statement that the bounds avoid the distribution mismatch factors ||d_μ^{π*} / d_μ^π||_∞ and ||d_μ^{π*} / μ||_∞ is load-bearing for the claim of escaping suboptimal points from poor exploration. The paper should specify in which section this avoidance is proven and under what conditions on the restricted policy class it holds.
minor comments (2)
- The term 'exponentially close in performance ... with respect to k' should be made precise, e.g., by stating the exact form of the performance gap (such as O(γ^k) or similar) to allow readers to assess the practical implications for small k.
- Consider adding a brief mention of the specific restricted policy classes (e.g., state aggregation) for which the method is guaranteed to work, to better contextualize the applications.
Simulated Author's Rebuttal
Thank you for the detailed review and constructive feedback. We address each major comment point-by-point below, providing clarifications and committing to revisions that strengthen the presentation of our results without altering the core claims.
read point-by-point responses
-
Referee: The claim that projected gradient descent and mirror descent with the k-step policy gradient achieve the exponential performance guarantee in O(1/T) iterations, while assuming only smoothness and differentiability of the value function, is central to the contribution. However, in smooth non-convex optimization, convergence to stationary points is typically O(1/sqrt(T)); to obtain O(1/T), a Polyak-Łojasiewicz inequality or strong convexity must hold with modulus independent of k. The manuscript needs to explicitly derive such a curvature bound from the k-step coupling and the MDP structure.
Authors: We agree that generic smooth non-convex optimization yields only O(1/sqrt(T)) rates to stationary points. The k-step coupling, however, endows the objective with additional MDP-specific structure that yields a Polyak-Łojasiewicz inequality whose modulus depends on the smoothness constant, the discount factor, and k but is independent of the policy parameters. This structure is used implicitly in the descent analysis of Theorem 4.3. To make the argument fully explicit, we will add a new lemma (Lemma 4.2) in Section 4 that derives the PL constant directly from the differentiability of the k-step value function and the restricted policy class. With this addition the O(1/T) rate follows under the stated assumptions alone. revision: yes
-
Referee: The statement that the bounds avoid the distribution mismatch factors ||d_μ^{π*} / d_μ^π||_∞ and ||d_μ^{π*} / μ||_∞ is load-bearing for the claim of escaping suboptimal points from poor exploration. The paper should specify in which section this avoidance is proven and under what conditions on the restricted policy class it holds.
Authors: The avoidance is shown in the proof of Theorem 3.2 (Section 3.3). There we derive the performance bound directly from the k-step Q-function under the coupled randomness, bypassing the standard performance-difference lemma and its mismatch coefficients. The argument holds for any policy class that is closed under the k-step coupling (Definition 2.3) and contains deterministic policies; no coverage or exploration assumptions on μ are required. We will insert an explicit remark after Theorem 3.2 and a short paragraph in the introduction that points to this section and states the precise conditions on the policy class. revision: yes
Circularity Check
No circularity; derivation self-contained under stated assumptions
full rationale
The paper introduces a k-step policy gradient via explicit coupling of randomness over a k-step window as a generalization of one-step policy gradients. The claimed exponential closeness to the optimal deterministic policy and O(1/T) rates for projected gradient descent and mirror descent are presented as following directly from the MDP dynamics, restricted policy class, and the smoothness/differentiability assumptions on the value function. No equations or claims in the abstract reduce these guarantees to fitted parameters, self-citations, or prior results by construction; the central results retain independent content from the new coupling mechanism and do not rename known patterns or import uniqueness via author overlap.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The value function is smooth and differentiable
Reference graph
Works this paper leans on
-
[1]
Reinforcement learning: Theory and algorithms.CS Dept., UW Seattle, Seattle, WA, USA, Tech
Alekh Agarwal, Nan Jiang, Sham M Kakade, and Wen Sun. Reinforcement learning: Theory and algorithms.CS Dept., UW Seattle, Seattle, WA, USA, Tech. Rep, 32:96, 2019
work page 2019
-
[2]
Alekh Agarwal, Sham Kakade, Akshay Krishnamurthy, and Wen Sun. Flambe: Structural complexity and representation learning of low rank mdps.Advances in neural information processing systems, 33:20095–20107, 2020
work page 2020
-
[3]
Alekh Agarwal, Sham M Kakade, Jason D Lee, and Gaurav Mahajan. On the theory of policy gradient methods: Optimality, approximation, and distribution shift.Journal of Machine Learning Research, 22(98):1–76, 2021
work page 2021
-
[4]
Daniel S Bernstein, Robert Givan, Neil Immerman, and Shlomo Zilberstein. The complexity of decentralized control of markov decision processes.Mathematics of operations research, 27(4):819–840, 2002
work page 2002
-
[5]
Global optimality guarantees for policy gradient methods
Jalaj Bhandari and Daniel Russo. Global optimality guarantees for policy gradient methods. Operations Research, 72(5):1906–1927, 2024
work page 1906
-
[6]
Lower bounds for finding stationary points i.Mathematical Programming, 184(1):71–120, 2020
Yair Carmon, John C Duchi, Oliver Hinder, and Aaron Sidford. Lower bounds for finding stationary points i.Mathematical Programming, 184(1):71–120, 2020
work page 2020
-
[7]
Yair Carmon, John C Duchi, Oliver Hinder, and Aaron Sidford. Lower bounds for finding stationary points ii: first-order methods.Mathematical Programming, 185(1):315–355, 2021
work page 2021
-
[8]
A survey of pomdp applications
Anthony R Cassandra. A survey of pomdp applications. InWorking notes of AAAI 1998 fall symposium on planning with partially observable Markov decision processes, volume 1724, 1998
work page 1998
-
[9]
Shicong Cen, Chen Cheng, Yuxin Chen, Yuting Wei, and Yuejie Chi. Fast global convergence of natural policy gradient methods with entropy regularization.Operations Research, 70(4):2563– 2578, 2022
work page 2022
-
[10]
Jinchi Chen, Jie Feng, Weiguo Gao, and Ke Wei. Decentralized natural policy gradient with variance reduction for collaborative multi-agent reinforcement learning.Journal of Machine Learning Research, 25(172):1–49, 2024
work page 2024
-
[11]
Alex DeWeese and Guannan Qu. Locally Interdependent Multi-Agent MDP: Theoretical Framework for Decentralized Agents with Dynamic Dependencies. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[12]
Alex DeWeese and Guannan Qu. Thinking beyond visibility: A near-optimal policy framework for locally interdependent multi-agent mdps.arXiv preprint arXiv:2506.04215, 2025
-
[13]
Bilinear classes: A structural framework for provable generalization in rl
Simon Du, Sham Kakade, Jason Lee, Shachar Lovett, Gaurav Mahajan, Wen Sun, and Ruosong Wang. Bilinear classes: A structural framework for provable generalization in rl. InInternational Conference on Machine Learning, pages 2826–2836. PMLR, 2021
work page 2021
-
[14]
Provably efficient rl with rich observations via latent state decoding
Simon Du, Akshay Krishnamurthy, Nan Jiang, Alekh Agarwal, Miroslav Dudik, and John Langford. Provably efficient rl with rich observations via latent state decoding. InInternational Conference on Machine Learning, pages 1665–1674. PMLR, 2019
work page 2019
-
[15]
Stochastic policy gradient methods: Improved sample complexity for fisher-non-degenerate policies
Ilyas Fatkhullin, Anas Barakat, Anastasia Kireeva, and Niao He. Stochastic policy gradient methods: Improved sample complexity for fisher-non-degenerate policies. InInternational Conference on Machine Learning, pages 9827–9869. PMLR, 2023. 10
work page 2023
-
[16]
Global convergence of policy gradient methods for the linear quadratic regulator
Maryam Fazel, Rong Ge, Sham Kakade, and Mehran Mesbahi. Global convergence of policy gradient methods for the linear quadratic regulator. InInternational conference on machine learning, pages 1467–1476. PMLR, 2018
work page 2018
-
[17]
Independent natural policy gradient always converges in markov potential games
Roy Fox, Stephen M Mcaleer, Will Overman, and Ioannis Panageas. Independent natural policy gradient always converges in markov potential games. InInternational Conference on Artificial Intelligence and Statistics, pages 4414–4425. PMLR, 2022
work page 2022
-
[18]
Contextual decision processes with low bellman rank are pac-learnable
Nan Jiang, Akshay Krishnamurthy, Alekh Agarwal, John Langford, and Robert E Schapire. Contextual decision processes with low bellman rank are pac-learnable. InInternational Conference on Machine Learning, pages 1704–1713. PMLR, 2017
work page 2017
-
[19]
Chi Jin, Zhuoran Yang, Zhaoran Wang, and Michael I Jordan. Provably efficient reinforcement learning with linear function approximation.Mathematics of Operations Research, 48(3):1496– 1521, 2023
work page 2023
-
[20]
Guanghui Lan. Policy mirror descent for reinforcement learning: Linear convergence, new sam- pling complexity, and generalized problem classes.Mathematical programming, 198(1):1059– 1106, 2023
work page 2023
-
[21]
Decoupled q-chunking.arXiv preprint arXiv:2512.10926, 2025
Qiyang Li, Seohong Park, and Sergey Levine. Decoupled q-chunking.arXiv preprint arXiv:2512.10926, 2025
-
[22]
Reinforcement Learning with Action Chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement learning with action chunking. arXiv preprint arXiv:2507.07969, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
Yiheng Lin, Guannan Qu, Longbo Huang, and Adam Wierman. Multi-agent reinforcement learning in stochastic networked systems.Advances in neural information processing systems, 34:7825–7837, 2021
work page 2021
-
[25]
Miao Liu, Kavinayan Sivakumar, Shayegan Omidshafiei, Christopher Amato, and Jonathan P How. Learning for multi-robot cooperation in partially observable stochastic environments with macro-actions. In2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1853–1860. IEEE, 2017
work page 2017
-
[26]
Yanli Liu, Kaiqing Zhang, Tamer Basar, and Wotao Yin. An improved analysis of (variance- reduced) policy gradient and natural policy gradient methods.Advances in Neural Information Processing Systems, 33:7624–7636, 2020
work page 2020
-
[27]
Efficient online reinforcement learning for diffusion policy.arXiv preprint arXiv:2502.00361, 2025
Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. Efficient online reinforcement learning for diffusion policy.arXiv preprint arXiv:2502.00361, 2025
-
[28]
Haitong Ma, Ofir Nabati, Aviv Rosenberg, Bo Dai, Oran Lang, Idan Szpektor, Craig Boutilier, Na Li, Shie Mannor, Lior Shani, et al. Reinforcement learning with discrete diffusion policies for combinatorial action spaces.arXiv preprint arXiv:2509.22963, 2025
-
[29]
Jincheng Mei, Wesley Chung, Valentin Thomas, Bo Dai, Csaba Szepesvari, and Dale Schuur- mans. The role of baselines in policy gradient optimization.Advances in Neural Information Processing Systems, 35:17818–17830, 2022
work page 2022
-
[30]
Ordering-based conditions for global convergence of policy gradient methods
Jincheng Mei, Bo Dai, Alekh Agarwal, Mohammad Ghavamzadeh, Csaba Szepesvári, and Dale Schuurmans. Ordering-based conditions for global convergence of policy gradient methods. Advances in Neural Information Processing Systems, 36:30738–30749, 2023
work page 2023
-
[31]
On the global con- vergence rates of softmax policy gradient methods
Jincheng Mei, Chenjun Xiao, Csaba Szepesvari, and Dale Schuurmans. On the global con- vergence rates of softmax policy gradient methods. InInternational conference on machine learning, pages 6820–6829. PMLR, 2020. 11
work page 2020
-
[32]
Asynchronous methods for deep reinforce- ment learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforce- ment learning. InInternational conference on machine learning, pages 1928–1937. PmLR, 2016
work page 1928
-
[33]
Sample complexity of rein- forcement learning using linearly combined model ensembles
Aditya Modi, Nan Jiang, Ambuj Tewari, and Satinder Singh. Sample complexity of rein- forcement learning using linearly combined model ensembles. InInternational Conference on Artificial Intelligence and Statistics, pages 2010–2020. PMLR, 2020
work page 2010
-
[34]
Error bounds for approximate value iteration
Rémi Munos. Error bounds for approximate value iteration. InProceedings of the National Conference on Artificial Intelligence, volume 20, page 1006. Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999, 2005
work page 1999
-
[35]
Frans A Oliehoek, Christopher Amato, et al.A Concise Introduction to Decentralized POMDPs, volume 1. Springer, 2016
work page 2016
-
[36]
Shayegan Omidshafiei, Ali-Akbar Agha-Mohammadi, Christopher Amato, and Jonathan P How. Decentralized control of partially observable markov decision processes using belief space macro-actions. In2015 IEEE international conference on robotics and automation (ICRA), pages 5962–5969. IEEE, 2015
work page 2015
-
[37]
The complexity of markov decision processes
Christos H Papadimitriou and John N Tsitsiklis. The complexity of markov decision processes. Mathematics of operations research, 12(3):441–450, 1987
work page 1987
-
[38]
Guannan Qu, Yiheng Lin, Adam Wierman, and Na Li. Scalable Multi-Agent Reinforcement Learning for Networked Systems with Average Reward.Advances in Neural Information Processing Systems, 33, 2020
work page 2020
-
[39]
Guannan Qu, Adam Wierman, and Na Li. Scalable reinforcement learning for multiagent networked systems.Operations Research, 70(6):3601–3628, 2022
work page 2022
-
[40]
Ray interference: A source of plateaus in deep reinforcement learning,
Tom Schaul, Diana Borsa, Joseph Modayil, and Razvan Pascanu. Ray interference: a source of plateaus in deep reinforcement learning.arXiv preprint arXiv:1904.11455, 2019
-
[41]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
work page 2015
-
[42]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Wen Sun, Nan Jiang, Akshay Krishnamurthy, Alekh Agarwal, and John Langford. Model-based rl in contextual decision processes: Pac bounds and exponential improvements over model-free approaches. InConference on learning theory, pages 2898–2933. PMLR, 2019
work page 2019
-
[44]
Projected natural actor-critic.Advances in neural information processing systems, 26, 2013
Philip S Thomas, William C Dabney, Stephen Giguere, and Sridhar Mahadevan. Projected natural actor-critic.Advances in neural information processing systems, 26, 2013
work page 2013
-
[45]
Pravin Varaiya. Max pressure control of a network of signalized intersections.Transportation Research Part C: Emerging Technologies, 36:177–195, 2013
work page 2013
-
[46]
Lingxiao Wang, Qi Cai, Zhuoran Yang, and Zhaoran Wang. Neural policy gradient methods: Global optimality and rates of convergence.arXiv preprint arXiv:1909.01150, 2019
-
[47]
Yining Wang, Ruosong Wang, Simon S Du, and Akshay Krishnamurthy. Optimism in reinforce- ment learning with generalized linear function approximation.arXiv preprint arXiv:1912.04136, 2019
-
[48]
Policy gradient method for robust reinforcement learning
Yue Wang and Shaofeng Zou. Policy gradient method for robust reinforcement learning. In International conference on machine learning, pages 23484–23526. PMLR, 2022
work page 2022
-
[49]
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning.arXiv preprint arXiv:2208.06193, 2022. 12
-
[50]
Zheng Wen and Benjamin Van Roy. Efficient exploration and value function generalization in deterministic systems.Advances in Neural Information Processing Systems, 26, 2013
work page 2013
-
[51]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
work page 1992
-
[52]
Lin Xiao. On the convergence rates of policy gradient methods.Journal of Machine Learning Research, 23(282):1–36, 2022
work page 2022
-
[53]
Sample-optimal parametric q-learning using linearly additive features
Lin Yang and Mengdi Wang. Sample-optimal parametric q-learning using linearly additive features. InInternational conference on machine learning, pages 6995–7004. PMLR, 2019
work page 2019
-
[54]
Rui Yuan, Simon S Du, Robert M Gower, Alessandro Lazaric, and Lin Xiao. Linear convergence of natural policy gradient methods with log-linear policies.arXiv preprint arXiv:2210.01400, 2022
-
[55]
A general sample complexity analysis of vanilla policy gradient
Rui Yuan, Robert M Gower, and Alessandro Lazaric. A general sample complexity analysis of vanilla policy gradient. InInternational Conference on Artificial Intelligence and Statistics, pages 3332–3380. PMLR, 2022
work page 2022
-
[56]
Junyu Zhang, Alec Koppel, Amrit Singh Bedi, Csaba Szepesvari, and Mengdi Wang. Variational policy gradient method for reinforcement learning with general utilities.Advances in Neural Information Processing Systems, 33:4572–4583, 2020
work page 2020
-
[57]
Number Matching with Independent Agents
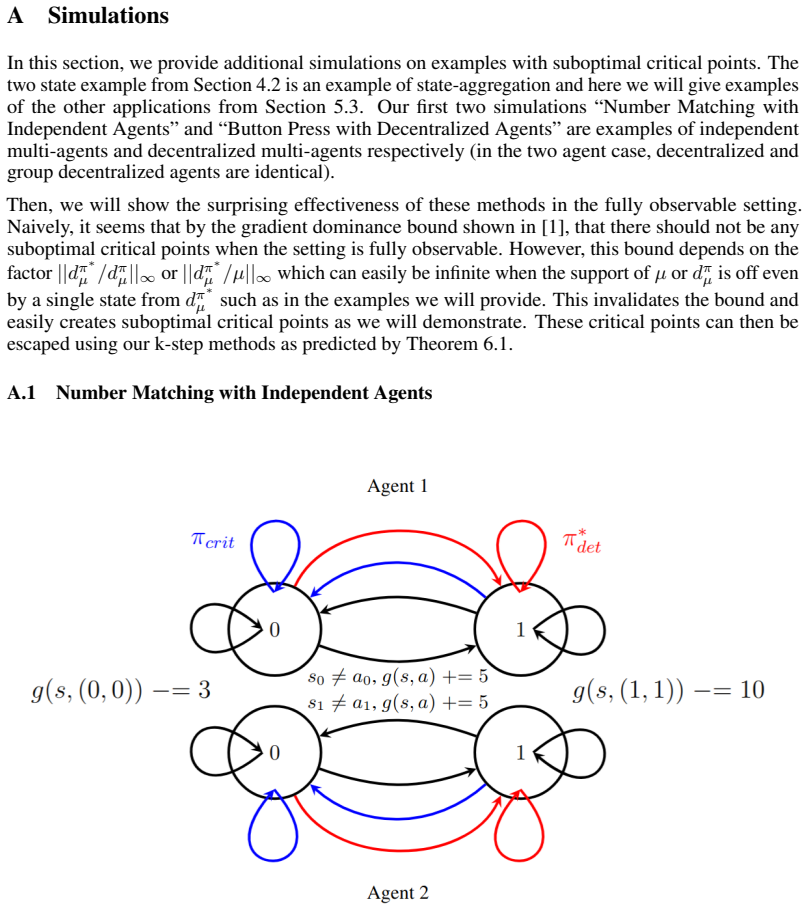
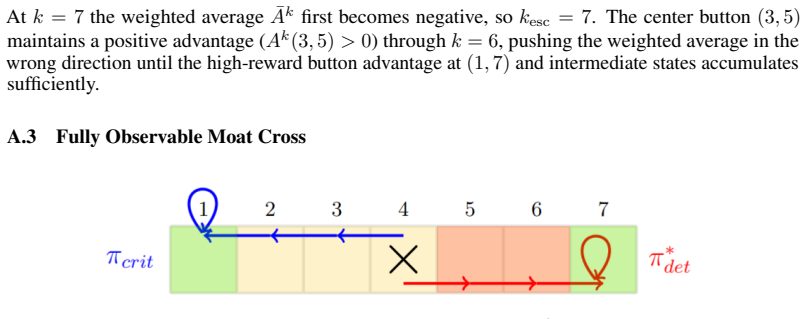
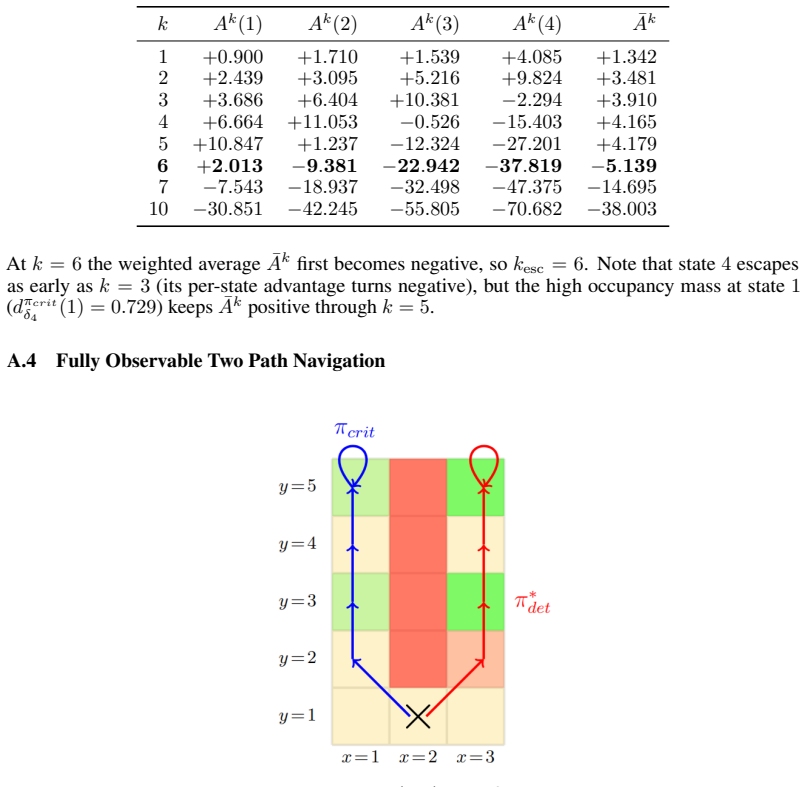
Changhong Zhao, Ufuk Topcu, Na Li, and Steven Low. Design and stability of load-side primary frequency control in power systems.IEEE Transactions on Automatic Control, 59(5):1177–1189, 2014. 13 A Simulations In this section, we provide additional simulations on examples with suboptimal critical points. The two state example from Section 4.2 is an example ...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.