FMC-DETR: Frequency-Decoupled Multi-Domain Coordination for Aerial-View Object Detection
Pith reviewed 2026-05-18 13:10 UTC · model grok-4.3
The pith
FMC-DETR detects small objects in aerial images better by decoupling frequencies and coordinating multi-domain features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
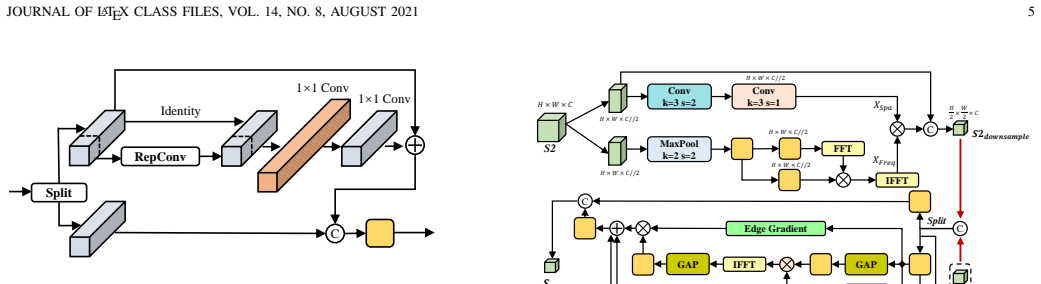
FMC-DETR is a frequency-decoupled fusion framework that employs the WeKat backbone with cascaded wavelet transforms to enhance global low-frequency structure perception in shallow features and Kolmogorov-Arnold networks for adaptive nonlinear modeling of multi-scale dependencies, the MDFC module for partial-channel spatial, spectral, and structural coordination to strengthen small-object feature responses, and the CPF module for compact multi-branch aggregation with progressive partial refinement to improve feature diversity and multi-scale interaction, leading to state-of-the-art performance on multiple remote sensing benchmarks.
What carries the argument
The Wavelet Kolmogorov-Arnold Transformer (WeKat) backbone, which employs cascaded wavelet transforms for global low-frequency structure and Kolmogorov-Arnold networks for nonlinear multi-scale modeling, supported by the Multi-Domain Feature Coordination (MDFC) module and Compact Partial Fusion (CPF) module.
If this is right
- Refined shallow representations lead to better detection of tiny objects in high-resolution aerial scenes.
- Strengthened feature responses in cluttered environments through cross-scale and multi-domain coordination.
- Improved feature diversity and stable information flow from compact partial fusion.
- Superior performance over baseline detectors on remote sensing object detection tasks.
Where Pith is reading between the lines
- The frequency separation technique could be tested in other computer vision tasks involving scale variance, such as instance segmentation in natural images.
- Individual ablation of the WeKat, MDFC, and CPF components on other detectors might reveal which part contributes most to the gains.
- Extending the multi-domain coordination to temporal domains could benefit video-based aerial surveillance applications.
Load-bearing premise
The proposed WeKat backbone, MDFC module, and CPF module directly resolve delayed contextual interaction and limited nonlinear reasoning to refine shallow representations for small objects.
What would settle it
Experiments on remote sensing benchmarks showing that FMC-DETR fails to outperform the baseline detector in small-object detection metrics would falsify the central claim.
Figures





read the original abstract
Remote sensing object detection is a critical technology for real-world applications such as natural resource monitoring, traffic management, and UAV-based rescue. Detecting tiny objects in high-resolution aerial imagery remains challenging due to weak visual cues and insufficient global context modeling in complex scenes. Existing methods often suffer from delayed contextual interaction and limited nonlinear reasoning, which restrict their ability to effectively refine shallow representations and ultimately lead to suboptimal performance. To address these challenges, we propose FMC-DETR, a frequency-decoupled fusion framework for aerial-view object detection. First, we propose the Wavelet Kolmogorov-Arnold Transformer (WeKat) backbone, which employs cascaded wavelet transforms to enhance global low-frequency structure perception in shallow features while preserving fine-grained details, and further leverages Kolmogorov-Arnold networks for adaptive nonlinear modeling of multi-scale dependencies. Second, we introduce the Multi-Domain Feature Coordination (MDFC) module, which refines cross-scale fused representations through partial-channel spatial, spectral, and structural coordination, thereby strengthening small-object-related feature responses in cluttered scenes. Finally, we design the Compact Partial Fusion (CPF) module, which performs compact multi-branch aggregation with progressive partial refinement to improve feature diversity and multi-scale interaction while preserving stable information flow and reducing redundant perturbation. Extensive experiments across multiple remote sensing benchmarks demonstrate that FMC-DETR achieves state-of-the-art performance and significantly outperforming the baseline detector. Code is available at https://github.com/bloomingvision/FMC-DETR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce FMC-DETR, a frequency-decoupled multi-domain coordination framework for aerial-view object detection. It proposes the WeKat backbone using cascaded wavelets and Kolmogorov-Arnold networks to enhance global low-frequency perception and nonlinear modeling, the MDFC module for partial-channel spatial/spectral/structural coordination, and the CPF module for compact multi-branch progressive refinement. Extensive experiments on remote sensing benchmarks are said to demonstrate state-of-the-art performance, significantly outperforming the baseline detector.
Significance. If validated with proper controls, this could contribute to improving detection of small objects in complex aerial scenes by better handling contextual interaction and nonlinear reasoning in shallow features. The modular design and code availability are strengths that could facilitate further research in remote sensing applications.
major comments (2)
- [§4 (Experiments)] The SOTA performance claim relies on attributing gains to the WeKat, MDFC, and CPF modules. However, the manuscript does not appear to provide controlled ablations that fix parameter count and training schedule while replacing these with standard counterparts (e.g., standard multi-head attention instead of KAN or conventional fusion instead of MDFC). This leaves open the possibility that gains arise from increased capacity rather than the frequency-decoupled mechanisms, undermining the central claim about resolving delayed contextual interaction and limited nonlinear reasoning.
- [Abstract] The abstract asserts 'extensive experiments' and SOTA results but provides no quantitative metrics, specific benchmark names, ablation details, or baseline comparisons. This gap hinders verification of whether reported gains trace to the claimed modules.
minor comments (2)
- [Abstract] Grammatical issue: 'significantly outperforming the baseline detector' should read 'significantly outperforms the baseline detector' for proper sentence structure.
- [Throughout] Ensure all module acronyms (WeKat, MDFC, CPF) are clearly defined on first use in the main text and that figure captions explicitly label all components.
Simulated Author's Rebuttal
We thank the referee for the thorough review and insightful comments on our manuscript. We address each of the major comments point by point below. We believe these revisions will clarify the contributions and strengthen the experimental validation of our proposed modules.
read point-by-point responses
-
Referee: [§4 (Experiments)] The SOTA performance claim relies on attributing gains to the WeKat, MDFC, and CPF modules. However, the manuscript does not appear to provide controlled ablations that fix parameter count and training schedule while replacing these with standard counterparts (e.g., standard multi-head attention instead of KAN or conventional fusion instead of MDFC). This leaves open the possibility that gains arise from increased capacity rather than the frequency-decoupled mechanisms, undermining the central claim about resolving delayed contextual interaction and limited nonlinear reasoning.
Authors: We appreciate this important point regarding the need for controlled experiments to isolate the effects of our proposed components. Upon re-examination, our current ablation studies compare variants of the modules but do not strictly match parameter counts across all replacements. In the revised version, we will add new ablation experiments that maintain equivalent parameter budgets and identical training schedules when substituting WeKat with a standard transformer backbone, MDFC with conventional multi-scale fusion, and CPF with standard feature aggregation. These will be presented in an expanded Section 4 to demonstrate that the performance gains stem from the frequency-decoupled design rather than mere capacity increases. revision: yes
-
Referee: [Abstract] The abstract asserts 'extensive experiments' and SOTA results but provides no quantitative metrics, specific benchmark names, ablation details, or baseline comparisons. This gap hinders verification of whether reported gains trace to the claimed modules.
Authors: We agree that including specific quantitative highlights in the abstract would improve readability and allow readers to quickly assess the results. In the revised manuscript, we will update the abstract to incorporate key performance metrics from our experiments on the remote sensing benchmarks, along with brief mentions of the ablation studies and comparisons to the baseline detector. revision: yes
Circularity Check
No circularity: architecture proposal with external benchmark validation
full rationale
The paper presents a new detector architecture (WeKat backbone, MDFC, CPF) motivated by stated limitations in prior detectors, then reports empirical results on standard remote-sensing benchmarks. No equations, fitted parameters, or self-citations are shown to reduce the central performance claim to a tautology or input by construction. The derivation chain consists of design choices followed by independent evaluation; gains are attributed to the modules but remain falsifiable via external testing rather than internally forced.
Axiom & Free-Parameter Ledger
free parameters (1)
- training hyperparameters
axioms (2)
- domain assumption Cascaded wavelet transforms enhance global low-frequency structure perception while preserving fine-grained details in shallow features.
- domain assumption Kolmogorov-Arnold networks enable adaptive nonlinear modeling of multi-scale dependencies.
invented entities (3)
-
WeKat backbone
no independent evidence
-
MDFC module
no independent evidence
-
CPF module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rcbevdet: Radar-camera fusion in bird’s eye view for 3d object detection,
Z. Lin, Z. Liu, Z. Xia, X. Wang, Y . Wang, S. Qi, Y . Dong, N. Dong, L. Zhang, and C. Zhu, “Rcbevdet: Radar-camera fusion in bird’s eye view for 3d object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14928– 14937, 2024
work page 2024
-
[2]
G. Zhang, X. Ji, B. Qiu, Y . Cai, Y . Liu, X. Sui, and Q. Chen, “Sfnet: A dual-enhanced rgbt tracker via global-local modality refinement and frequency-spatial cross-modal fusion,”Optics and Lasers in Engineer- ing, vol. 194, p. 109201, 2025
work page 2025
-
[3]
Optisar-net: A cross-domain ship detec- tion method for multi-source remote sensing data,
J. Dong, J. Feng, and X. Tang, “Optisar-net: A cross-domain ship detec- tion method for multi-source remote sensing data,”IEEE Transactions on Geoscience and Remote Sensing, 2024
work page 2024
-
[4]
Spatio-temporal feature fusion and guide aggregation network for remote sensing change detection,
H. Wei, N. Wang, Y . Liu, P. Ma, D. Pang, X. Sui, and Q. Chen, “Spatio-temporal feature fusion and guide aggregation network for remote sensing change detection,”IEEE Transactions on Geoscience and Remote Sensing, 2024
work page 2024
-
[5]
B. Du, Y . Huang, J. Chen, and D. Huang, “Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13435–13444, 2023
work page 2023
-
[6]
Dtssnet: Dynamic training sample selection network for uav object detection,
L. Chen, C. Liu, W. Li, Q. Xu, and H. Deng, “Dtssnet: Dynamic training sample selection network for uav object detection,”IEEE transactions on geoscience and remote sensing, vol. 62, pp. 1–16, 2024
work page 2024
-
[7]
Fbrt-yolo: Faster and better for real- time aerial image detection,
Y . Xiao, T. Xu, Y . Xin, and J. Li, “Fbrt-yolo: Faster and better for real- time aerial image detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, pp. 8673–8681, 2025
work page 2025
-
[8]
A global-local self-adaptive network for drone-view object detection,
S. Deng, S. Li, K. Xie, W. Song, X. Liao, A. Hao, and H. Qin, “A global-local self-adaptive network for drone-view object detection,” IEEE Transactions on Image Processing, vol. 30, pp. 1556–1569, 2020
work page 2020
-
[9]
Yolo-dcti: small object detection in remote sensing base on contextual transformer enhancement,
L. Min, Z. Fan, Q. Lv, M. Reda, L. Shen, and B. Wang, “Yolo-dcti: small object detection in remote sensing base on contextual transformer enhancement,”Remote Sensing, vol. 15, no. 16, p. 3970, 2023
work page 2023
-
[10]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[11]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly,et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 10012–10022, 2021
work page 2021
-
[13]
Visdrone-det2021: The vision meets drone object detection challenge results,
Y . Cao, Z. He, L. Wang, W. Wang, Y . Yuan, D. Zhang, J. Zhang, P. Zhu, L. Van Gool, J. Han,et al., “Visdrone-det2021: The vision meets drone object detection challenge results,” inProceedings of the IEEE/CVF International conference on computer vision, pp. 2847–2854, 2021
work page 2021
-
[14]
Hazydet: Open-source benchmark for drone-view object detec- tion with depth-cues in hazy scenes,
C. Feng, Z. Chen, X. Li, C. Wang, J. Yang, M.-M. Cheng, Y . Dai, and Q. Fu, “Hazydet: Open-source benchmark for drone-view object detec- tion with depth-cues in hazy scenes,”arXiv preprint arXiv:2409.19833, 2024
-
[15]
Multisized object detection using spaceborne optical imagery,
M. Haroon, M. Shahzad, and M. M. Fraz, “Multisized object detection using spaceborne optical imagery,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 13, pp. 3032– 3046, 2020
work page 2020
- [16]
-
[17]
Yolov9: Learning what you want to learn using programmable gradient information,
C.-Y . Wang, I.-H. Yeh, and H.-Y . Mark Liao, “Yolov9: Learning what you want to learn using programmable gradient information,” inEuro- pean conference on computer vision, pp. 1–21, Springer, 2024
work page 2024
-
[18]
Yolov10: Real-time end-to-end object detection,
A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han,et al., “Yolov10: Real-time end-to-end object detection,”Advances in Neural Information Processing Systems, vol. 37, pp. 107984–108011, 2024
work page 2024
- [19]
-
[20]
YOLOv12: Attention-Centric Real-Time Object Detectors
Y . Tian, Q. Ye, and D. Doermann, “Yolov12: Attention-centric real-time object detectors,”arXiv preprint arXiv:2502.12524, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Yolov13: Real-time object detection with hypergraph- enhanced adaptive visual perception,
M. Lei, S. Li, Y . Wu, H. Hu, Y . Zhou, X. Zheng, G. Ding, S. Du, Z. Wu, and Y . Gao, “Yolov13: Real-time object detection with hypergraph- enhanced adaptive visual perception,”arXiv preprint arXiv:2506.17733, 2025
-
[22]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision, pp. 213–229, Springer, 2020
work page 2020
-
[23]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,”arXiv preprint arXiv:2010.04159, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[24]
Detrs beat yolos on real-time object detection,
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, and J. Chen, “Detrs beat yolos on real-time object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16965–16974, 2024
work page 2024
-
[25]
D-fine: Redefine regression task in detrs as fine-grained distribution refinement,
Y . Peng, H. Li, P. Wu, Y . Zhang, X. Sun, and F. Wu, “D-fine: Redefine regression task in detrs as fine-grained distribution refinement,”arXiv preprint arXiv:2410.13842, 2024
-
[26]
Deim: Detr with improved matching for fast convergence,
S. Huang, Z. Lu, X. Cun, Y . Yu, X. Zhou, and X. Shen, “Deim: Detr with improved matching for fast convergence,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 15162–15171, 2025
work page 2025
-
[27]
Low-light image enhancement with multi-scale attention and frequency-domain optimization,
Z. He, W. Ran, S. Liu, K. Li, J. Lu, C. Xie, Y . Liu, and H. Lu, “Low-light image enhancement with multi-scale attention and frequency-domain optimization,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 4, pp. 2861–2875, 2023
work page 2023
-
[28]
Elwnet: An extremely lightweight approach for real-time salient ob- ject detection,
Z. Wang, Y . Zhang, Y . Liu, D. Zhu, S. A. Coleman, and D. Kerr, “Elwnet: An extremely lightweight approach for real-time salient ob- ject detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 11, pp. 6404–6417, 2023
work page 2023
-
[29]
Unleashing channel potential: Space-frequency selection convolution for sar object detection,
K. Li, D. Wang, Z. Hu, W. Zhu, S. Li, and Q. Wang, “Unleashing channel potential: Space-frequency selection convolution for sar object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17323–17332, 2024
work page 2024
-
[30]
Scaling up your kernels to 31x31: Revisiting large kernel design in cnns,
X. Ding, X. Zhang, J. Han, and G. Ding, “Scaling up your kernels to 31x31: Revisiting large kernel design in cnns,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11963–11975, 2022
work page 2022
-
[31]
KAN: Kolmogorov-Arnold Networks
Z. Liu, Y . Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Solja ˇci´c, T. Y . Hou, and M. Tegmark, “Kan: Kolmogorov-arnold networks,”arXiv preprint arXiv:2404.19756, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Kolmogorov-arnold transformer,
X. Yang and X. Wang, “Kolmogorov-arnold transformer,”arXiv preprint arXiv:2409.10594, 2024
-
[33]
Deep roots: Improving cnn efficiency with hierarchical filter groups,
Y . Ioannou, D. Robertson, R. Cipolla, and A. Criminisi, “Deep roots: Improving cnn efficiency with hierarchical filter groups,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 1231–1240, 2017
work page 2017
-
[34]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convo- lutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Run, don’t walk: chasing higher flops for faster neural networks,
J. Chen, S.-h. Kao, H. He, W. Zhuo, S. Wen, C.-H. Lee, and S.-H. G. Chan, “Run, don’t walk: chasing higher flops for faster neural networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12021–12031, 2023
work page 2023
-
[36]
Split to be slim: An overlooked redundancy in vanilla convolution,
Q. Zhang, Z. Jiang, Q. Lu, J. Han, Z. Zeng, S.-H. Gao, and A. Men, “Split to be slim: An overlooked redundancy in vanilla convolution,” arXiv preprint arXiv:2006.12085, 2020
-
[37]
Ghostnet: More features from cheap operations,
K. Han, Y . Wang, Q. Tian, J. Guo, C. Xu, and C. Xu, “Ghostnet: More features from cheap operations,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1580–1589, 2020
work page 2020
-
[38]
Sparse detr: Efficient end-to-end object detection with learnable sparsity,
B. Roh, J. Shin, W. Shin, and S. Kim, “Sparse detr: Efficient end-to-end object detection with learnable sparsity,”arXiv preprint arXiv:2111.14330, 2021
-
[39]
Mamba yolo: A simple baseline for object detection with state space model,
Z. Wang, C. Li, H. Xu, X. Zhu, and H. Li, “Mamba yolo: A simple baseline for object detection with state space model,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, pp. 8205–8213, 2025
work page 2025
-
[40]
Emsd-detr: efficient small object detection for uav aerial images based on enhanced rt-detr model,
C. Zhang and J. Yang, “Emsd-detr: efficient small object detection for uav aerial images based on enhanced rt-detr model,”The Journal of Supercomputing, vol. 81, no. 9, pp. 1–33, 2025
work page 2025
-
[41]
X. Wang and H. Chen, “Hps-detr: Enhancing small object detection with lightweight feature extraction and transformer integration,”Authorea Preprints, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.