Thinking Sparks!: Emergent Attention Heads in Reasoning Models During Post Training
Pith reviewed 2026-05-18 13:24 UTC · model grok-4.3
The pith
Post-training on complex reasoning tasks causes new specialized attention heads to emerge inside large models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Post-training for complex reasoning sparks the emergence of novel, functionally specialized attention heads. These heads collectively support structured reasoning and computation. Comparative analysis across model families shows that distillation and SFT add stable reasoning heads in a cumulative way. GRPO instead runs a dynamic search in which few heads are activated, evaluated, and pruned, with survival tied to task reward changes. Controllable think on/off models lack dedicated thinking heads and instead activate broader but less efficient compensatory heads when explicit reasoning is disabled. Ablation studies tie these circuit changes to a performance trade-off in which stronger heads,
What carries the argument
Circuit analysis and targeted ablation of attention heads to measure their causal contribution to reasoning performance after post-training.
If this is right
- Distillation and SFT produce cumulative addition of stable reasoning heads.
- GRPO runs a dynamic process of head activation, evaluation, and pruning that tracks reward fluctuations.
- Controllable think on/off models recruit broader compensatory heads instead of dedicated thinking heads.
- Strengthened heads improve sophisticated strategies on hard problems but create over-thinking errors such as calculation mistakes or logical loops on simpler tasks.
Where Pith is reading between the lines
- Designers could add post-training steps that selectively prune heads linked to over-thinking while preserving those needed for hard problems.
- The same emergence pattern may appear in other post-training goals such as tool use or multi-step planning.
- Targeted head-level interventions after training might be tested as a way to reduce logical loops without retraining the whole model.
Load-bearing premise
The circuit analysis and ablation studies correctly identify the causal contributions of the observed attention heads to reasoning performance without significant confounding from other model components or training artifacts.
What would settle it
Ablating the identified emergent attention heads produces no measurable drop in performance on complex reasoning tasks while leaving simple-task accuracy unchanged.
Figures








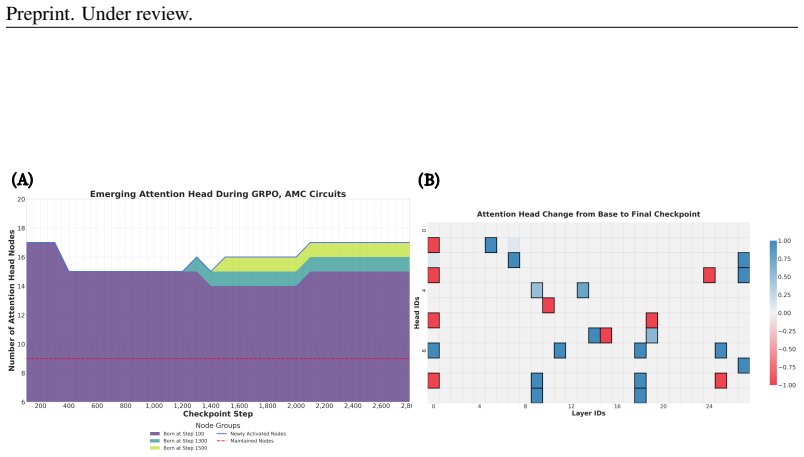
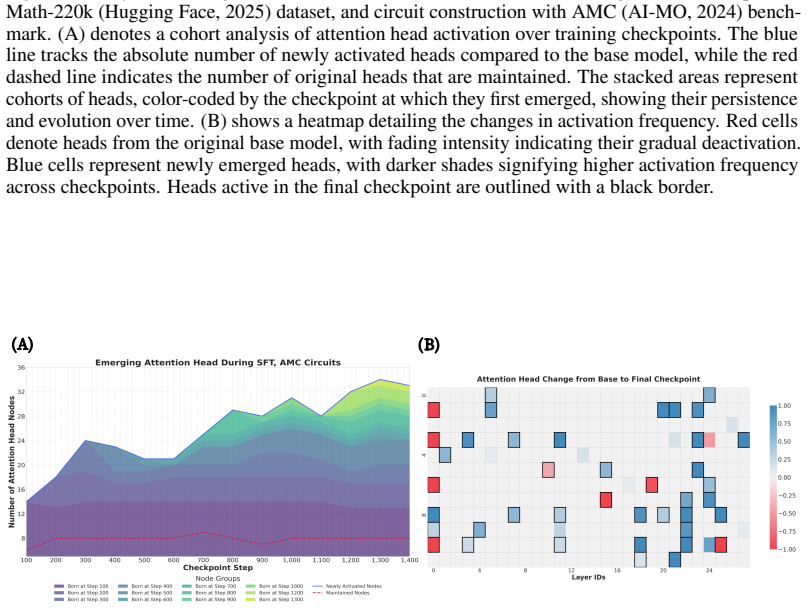




read the original abstract
The remarkable capabilities of modern large reasoning models are largely unlocked through post-training techniques such as supervised fine-tuning (SFT) and reinforcement learning (RL). However, the architectural mechanisms behind such improvements remain largely opaque. In this work, we use circuit analysis to demonstrate that post-training for complex reasoning sparks the emergence of novel, functionally specialized attention heads. These heads collectively support structured reasoning and computation. Our comparative analysis across various model families reveals that these emergent heads evolve differently under different training regimes. Distillation and SFT foster a cumulative addition of stable reasoning heads. In contrast, group relative policy optimization (GRPO) operates in a dynamic search mode: relatively few attention heads are iteratively activated, evaluated, and pruned, with their survival closely tracking fluctuations in the task reward signal. Furthermore, we find that controllable "think on/off" models do not possess dedicated "thinking" heads. Instead, turning off explicit reasoning triggers a broader-but less efficient-set of compensatory heads. Through ablation and qualitative analyses, we connect these circuit-level dynamics to a crucial performance trade-off: strengthened heads enable sophisticated problem-solving strategies for difficult problems but can also introduce "over-thinking" failure modes, such as calculation errors or logical loops on simpler tasks. These findings connect circuit-level dynamics to macro-level performance, identifying an inherent tension where complex reasoning comes at the cost of elementary computations. More broadly, our work points to future directions for training policy design, emphasizing the need to balance the development of effective reasoning strategies with the assurance of reliable, flawless execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that post-training (SFT, distillation, GRPO) for complex reasoning induces the emergence of novel, functionally specialized attention heads in transformers, identified via circuit analysis. These heads support structured reasoning, with distinct evolutionary patterns across regimes: cumulative stable addition under distillation/SFT versus dynamic activation-evaluation-pruning under GRPO that tracks reward signals. Ablations and qualitative analyses link the heads to performance gains on hard problems but also to over-thinking failures (e.g., loops, calculation errors) on simple tasks; controllable think on/off models rely on compensatory rather than dedicated heads.
Significance. If the causal claims hold, the work supplies concrete mechanistic evidence connecting post-training dynamics to reasoning improvements and an inherent trade-off between sophisticated strategies and reliable execution. The cross-regime comparison and circuit-level to macro-performance linkage could inform training policy design to mitigate over-thinking while preserving gains. The use of ablation studies to tie heads to specific failure modes is a strength if the interventions are sufficiently controlled.
major comments (2)
- [Ablation experiments (results section describing head removal)] Ablation experiments (results section describing head removal): performance degradation after ablating the identified heads is presented as evidence of their causal role in reasoning, but the studies do not report controls that freeze MLPs or other heads while varying only the target set, nor direct comparisons to non-reasoning post-training runs; without these, compensatory rerouting or correlated training effects cannot be excluded as alternative explanations for the observed changes.
- [GRPO dynamics (section on comparative analysis across training regimes)] GRPO dynamics (section on comparative analysis across training regimes): the characterization of GRPO as a 'dynamic search mode' with heads 'iteratively activated, evaluated, and pruned' whose survival tracks reward fluctuations is central to the contrast with SFT/distillation, yet the manuscript provides no quantitative metrics (e.g., activation frequency histograms, survival curves with error bars, or statistical tests against baseline RL dynamics) to establish that this pattern is distinct from standard optimization artifacts.
minor comments (2)
- [Methods] Clarify in the methods or appendix how 'emergent' heads are operationally defined (e.g., activation threshold, comparison to base model, or statistical criterion) to allow replication.
- [Figures] Figure captions for circuit diagrams and ablation plots should explicitly state the number of runs, random seeds, and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify the strength of our causal claims and the presentation of our comparative analysis. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Ablation experiments (results section describing head removal)] Ablation experiments (results section describing head removal): performance degradation after ablating the identified heads is presented as evidence of their causal role in reasoning, but the studies do not report controls that freeze MLPs or other heads while varying only the target set, nor direct comparisons to non-reasoning post-training runs; without these, compensatory rerouting or correlated training effects cannot be excluded as alternative explanations for the observed changes.
Authors: We agree that the ablation results would be more convincing with additional controls to isolate the contribution of the identified heads and to exclude alternative explanations such as compensatory rerouting or general post-training effects. In the revised manuscript we will add (i) ablations of randomly selected heads of matched size and (ii) ablations performed while freezing the MLPs, and (iii) a direct comparison against models post-trained on non-reasoning tasks. These new controls will be reported alongside the existing results. revision: yes
-
Referee: [GRPO dynamics (section on comparative analysis across training regimes)] GRPO dynamics (section on comparative analysis across training regimes): the characterization of GRPO as a 'dynamic search mode' with heads 'iteratively activated, evaluated, and pruned' whose survival tracks reward fluctuations is central to the contrast with SFT/distillation, yet the manuscript provides no quantitative metrics (e.g., activation frequency histograms, survival curves with error bars, or statistical tests against baseline RL dynamics) to establish that this pattern is distinct from standard optimization artifacts.
Authors: We acknowledge that the current description of GRPO dynamics would benefit from quantitative support to distinguish the observed pattern from generic optimization behavior. In the revised manuscript we will augment the comparative analysis section with activation-frequency histograms, head-survival curves (with error bars across multiple random seeds), and statistical tests against a baseline RL run that uses a non-reasoning reward signal. These additions will make the claimed distinction between regimes more rigorous. revision: yes
Circularity Check
No circularity; empirical circuit analysis and ablations are independent of inputs
full rationale
The paper presents an empirical study using circuit analysis and ablation experiments on post-trained reasoning models to observe emergent attention heads. No mathematical derivation chain, equations, or predictions are claimed that reduce to fitted parameters or self-referential definitions. Claims rely on comparative observations across model families and training regimes (SFT, GRPO, distillation), with performance links established via direct interventions rather than self-citation chains or ansatzes. The analysis is self-contained against external model behaviors and does not rename known results or import uniqueness theorems from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Circuit analysis techniques can reliably identify functionally specialized attention heads and their causal roles
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
AI-MO. Amc 2023 , 2024. URL https://huggingface.co/datasets/AI-MO/ aimo-validation-amc
work page 2023
-
[3]
AIME problems and solutions, 2025
AIME . AIME problems and solutions, 2025. URL https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions
work page 2025
-
[4]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
work page 2025
-
[5]
Mechanistic interpretability for AI safety - a review
Leonard Bereska and Stratis Gavves. Mechanistic interpretability for AI safety - a review. Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=ePUVetPKu6. Survey Certification, Expert Certification
work page 2024
-
[6]
Iteration head: A mechanistic study of chain-of-thought
Vivien Cabannes, Charles Arnal, Wassim Bouaziz, Xingyu Yang, Francois Charton, and Julia Kempe. Iteration head: A mechanistic study of chain-of-thought. Advances in Neural Information Processing Systems, 37: 0 109101--109122, 2024
work page 2024
-
[7]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms. arXiv preprint arXiv:2412.21187, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
SFT memorizes, RL generalizes: A comparative study of foundation model post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. SFT memorizes, RL generalizes: A comparative study of foundation model post-training. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=dYur3yabMj
work page 2025
-
[10]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Towards automated circuit discovery for mechanistic interpretability
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adri \`a Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. Advances in Neural Information Processing Systems, 36: 0 16318--16352, 2023
work page 2023
-
[12]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
work page 2021
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms
Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov. Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=TZ0CCGDcuT
work page 2024
-
[15]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face . Open r1: A fully open reproduction of deepseek-r1, January 2025. URL https://github.com/huggingface/open-r1
work page 2025
-
[16]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension. In Regina Barzilay and Min-Yen Kan (eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1601--1611, Vancouver, Canada, July 2017....
-
[18]
Knowledge-augmented reasoning distillation for small language models in knowledge-intensive tasks
Minki Kang, Seanie Lee, Jinheon Baek, Kenji Kawaguchi, and Sung Ju Hwang. Knowledge-augmented reasoning distillation for small language models in knowledge-intensive tasks. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Systems, volume 36, pp.\ 48573--48602. Curran Associates, Inc.,...
work page 2023
-
[19]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=v8L0pN6EOi
work page 2024
-
[20]
Jack Lindsey, Wes Gurnee, Emmanuel Ameisen, Brian Chen, Adam Pearce, Nicholas L. Turner, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
work page 2025
-
[21]
Reasoning models can be effective without thinking
Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, and Matei Zaharia. Reasoning models can be effective without thinking. arXiv preprint arXiv:2504.09858, 2025
-
[22]
Reinforcement learning finetunes small subnetworks in large language models
Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, and Hao Peng. Reinforcement learning finetunes small subnetworks in large language models. arXiv preprint arXiv:2505.11711, 2025
-
[23]
Attribution Patching : Activation Patching At Industrial Scale
Neel Nanda. Attribution Patching : Activation Patching At Industrial Scale . 2023. URL https://www.neelnanda.io/mechanistic-interpretability/attribution-patching
work page 2023
-
[24]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=9XFSbDPmdW
work page 2023
-
[25]
Zoom in: An introduction to circuits
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits. Distill, 2020. doi:10.23915/distill.00024.001. https://distill.pub/2020/circuits/zoom-in
- [26]
- [27]
-
[28]
How do LLM s acquire new knowledge? a knowledge circuits perspective on continual pre-training
Yixin Ou, Yunzhi Yao, Ningyu Zhang, Hui Jin, Jiacheng Sun, Shumin Deng, Zhenguo Li, and Huajun Chen. How do LLM s acquire new knowledge? a knowledge circuits perspective on continual pre-training. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\...
-
[29]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35: 0 27730--27744, 2022
work page 2022
-
[30]
Does time have its place? temporal heads: Where language models recall time-specific information
Yein Park, Chanwoong Yoon, Jungwoo Park, Minbyul Jeong, and Jaewoo Kang. Does time have its place? temporal heads: Where language models recall time-specific information. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: ...
-
[31]
Neel Rajani, Aryo Pradipta Gema, Seraphina Goldfarb-Tarrant, and Ivan Titov. Scalpel vs. hammer: Grpo amplifies existing capabilities, sft replaces them. arXiv preprint arXiv:2507.10616, 2025
-
[32]
The mechanistic basis of data dependence and abrupt learning in an in-context classification task
Gautam Reddy. The mechanistic basis of data dependence and abrupt learning in an in-context classification task. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=aN4Jf6Cx69
work page 2024
-
[33]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA : A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=Ti67584b98
work page 2024
-
[34]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=4FWAwZtd2n
work page 2025
-
[37]
Stop overthinking: A survey on efficient reasoning for large language models
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, Hanjie Chen, and Xia Hu. Stop overthinking: A survey on efficient reasoning for large language models. Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=HvoG8SxggZ
work page 2025
-
[38]
Openmathinstruct-1: A 1.8 million math instruction tuning dataset
Shubham Toshniwal, Ivan Moshkov, Sean Narenthiran, Daria Gitman, Fei Jia, and Igor Gitman. Openmathinstruct-1: A 1.8 million math instruction tuning dataset. Advances in Neural Information Processing Systems, 37: 0 34737--34774, 2024
work page 2024
-
[39]
R e FT : Reasoning with reinforced fine-tuning
Luong Trung, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. R e FT : Reasoning with reinforced fine-tuning. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 7601--7614, Bangkok, Thailand, August 2024. Association fo...
-
[40]
Learning when to think: Shaping adaptive reasoning in r1-style models via multi-stage rl
Songjun Tu, Jiahao Lin, Qichao Zhang, Xiangyu Tian, Linjing Li, Xiangyuan Lan, and Dongbin Zhao. Learning when to think: Shaping adaptive reasoning in r1-style models via multi-stage rl. arXiv preprint arXiv:2505.10832, 2025
-
[41]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[42]
Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In Anna Korhonen, David Traum, and Llu \'i s M \`a rquez (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp.\ 5797--5808, Florence, It...
-
[43]
Interpretability in the wild: a circuit for indirect object identification in GPT -2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT -2 small. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=NpsVSN6o4ul
work page 2023
-
[44]
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2022 a . URL https://openreview.net/forum?id=gEZrGCozdqR
work page 2022
-
[45]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 0 24824--24837, 2022 b
work page 2022
-
[46]
Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond
Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, and Xiangzheng Zhang. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond. arXiv preprint arXiv:2503.10460, 2025
-
[47]
Tong Wu, Chong Xiang, Jiachen T Wang, G Edward Suh, and Prateek Mittal. Effectively controlling reasoning models through thinking intervention. arXiv preprint arXiv:2503.24370, 2025 a
-
[48]
Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving. In The Thirteenth International Conference on Learning Representations, 2025 b . URL https://openreview.net/forum?id=VNckp7JEHn
work page 2025
-
[49]
Training large language models for reasoning through reverse curriculum reinforcement learning
Zhiheng Xi, Wenxiang Chen, Boyang Hong, Senjie Jin, Rui Zheng, Wei He, Yiwen Ding, Shichun Liu, Xin Guo, Junzhe Wang, et al. Training large language models for reasoning through reverse curriculum reinforcement learning. In International Conference on Machine Learning, pp.\ 54030--54048. PMLR, 2024
work page 2024
-
[50]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Knowledge circuits in pretrained transformers
Yunzhi Yao, Ningyu Zhang, Zekun Xi, Mengru Wang, Ziwen Xu, Shumin Deng, and Huajun Chen. Knowledge circuits in pretrained transformers. Advances in Neural Information Processing Systems, 37: 0 118571--118602, 2024
work page 2024
-
[53]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
A Survey of Reinforcement Learning for Large Reasoning Models
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, et al. A survey of reinforcement learning for large reasoning models. arXiv preprint arXiv:2509.08827, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu Zhang, Wenyue Hua, Haolun Wu, Zhihan Guo, Yufei Wang, Niklas Muennighoff, et al. A survey on test-time scaling in large language models: What, how, where, and how well? arXiv preprint arXiv:2503.24235, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
When to continue thinking: Adaptive thinking mode switching for efficient reasoning
Xiaoyun Zhang, Jingqing Ruan, Xing Ma, Yawen Zhu, Haodong Zhao, Hao Li, Jiansong Chen, Ke Zeng, and Xunliang Cai. When to continue thinking: Adaptive thinking mode switching for efficient reasoning. arXiv preprint arXiv:2505.15400, 2025 c
-
[57]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[58]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[59]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[60]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.