IoDResearch: Deep Research on Private Heterogeneous Data via the Internet of Data
Pith reviewed 2026-05-18 11:20 UTC · model grok-4.3
The pith
IoDResearch enables effective deep research on private heterogeneous data by encapsulating it as FAIR digital objects and building knowledge graphs for multi-granularity retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
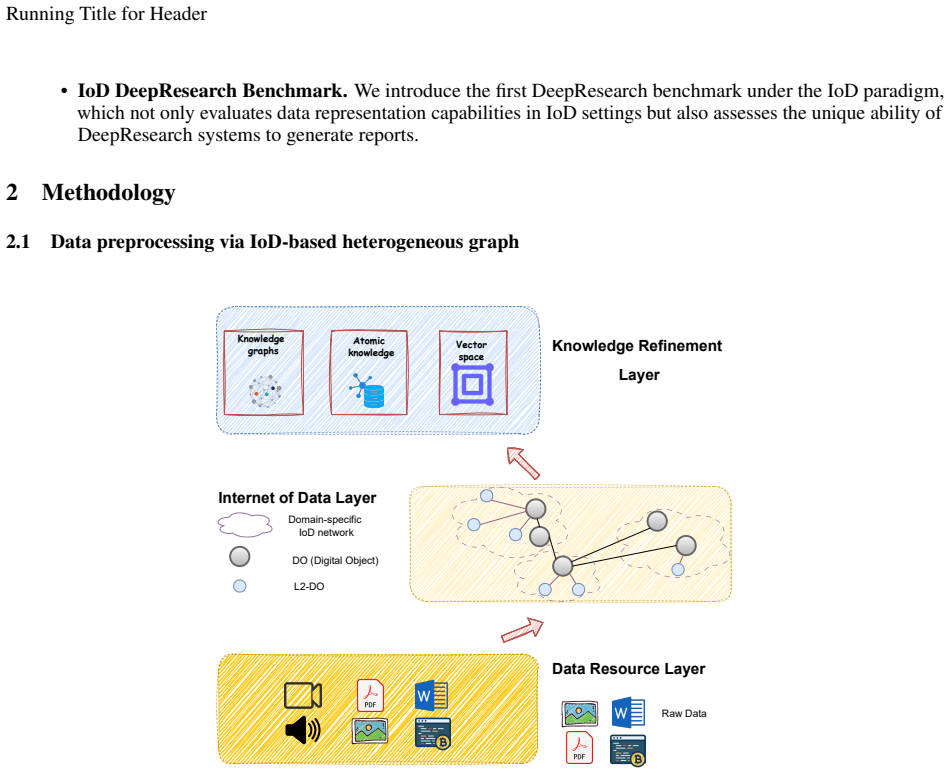
IoDResearch operationalizes the Internet of Data paradigm by encapsulating heterogeneous private resources as FAIR-compliant digital objects. These are refined into atomic knowledge units and knowledge graphs that form a heterogeneous graph index supporting multi-granularity retrieval. A multi-agent system built on this index handles both reliable question answering and structured scientific report generation. The authors introduce the IoD DeepResearch Benchmark to evaluate these capabilities, with experiments demonstrating that IoDResearch surpasses representative RAG and Deep Research baselines across retrieval, QA, and report-writing tasks.
What carries the argument
The heterogeneous graph index, formed by refining FAIR-compliant digital objects into atomic knowledge units and knowledge graphs, which enables multi-granularity retrieval and underpins the multi-agent system for question answering and report generation.
If this is right
- Private heterogeneous data becomes accessible for systematic retrieval and analysis through graph-based indexing.
- Multi-agent systems can produce higher quality structured reports from local data sources.
- The framework supports better compliance with FAIR principles, enhancing data reusability in research.
- Deep research capabilities extend beyond web search to include private data environments.
Where Pith is reading between the lines
- If the approach scales, it could enable integration of proprietary datasets into larger automated discovery systems without compromising privacy.
- Similar encapsulation techniques might apply to dynamic data streams, requiring updates to the knowledge graphs over time.
- This points toward a future where scientific reports are generated with references to both public and private sources in a unified way.
Load-bearing premise
Heterogeneous private data resources can be effectively encapsulated as FAIR-compliant digital objects and refined into atomic knowledge units and knowledge graphs to form a heterogeneous graph index that enables reliable multi-granularity retrieval and supports a multi-agent system for question answering and report generation.
What would settle it
Experiments on private heterogeneous datasets where IoDResearch does not outperform standard RAG methods in retrieval accuracy, question answering correctness, or report quality would indicate that the proposed data representation and indexing do not deliver the claimed advantages.
Figures




read the original abstract
The rapid growth of multi-source, heterogeneous, and multimodal scientific data has increasingly exposed the limitations of traditional data management. Most existing DeepResearch (DR) efforts focus primarily on web search while overlooking local private data. Consequently, these frameworks exhibit low retrieval efficiency for private data and fail to comply with the FAIR principles, ultimately resulting in inefficiency and limited reusability. To this end, we propose IoDResearch (Internet of Data Research), a private data-centric Deep Research framework that operationalizes the Internet of Data paradigm. IoDResearch encapsulates heterogeneous resources as FAIR-compliant digital objects, and further refines them into atomic knowledge units and knowledge graphs, forming a heterogeneous graph index for multi-granularity retrieval. On top of this representation, a multi-agent system supports both reliable question answering and structured scientific report generation. Furthermore, we establish the IoD DeepResearch Benchmark to systematically evaluate both data representation and Deep Research capabilities in IoD scenarios. Experimental results on retrieval, QA, and report-writing tasks show that IoDResearch consistently surpasses representative RAG and Deep Research baselines. Overall, IoDResearch demonstrates the feasibility of private-data-centric Deep Research under the IoD paradigm, paving the way toward more trustworthy, reusable, and automated scientific discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes IoDResearch, a private data-centric Deep Research framework that encapsulates heterogeneous private data resources as FAIR-compliant digital objects, refines them into atomic knowledge units and knowledge graphs to create a heterogeneous graph index enabling multi-granularity retrieval, and utilizes a multi-agent system for question answering and structured report generation. It introduces the IoD DeepResearch Benchmark and demonstrates through experiments that the system outperforms representative RAG and Deep Research baselines on retrieval, QA, and report-writing tasks.
Significance. Should the core claims be validated, this contribution would be significant for the information retrieval and AI research communities by addressing the underutilization of private heterogeneous data in deep research systems. By operationalizing the Internet of Data paradigm with FAIR principles, it could improve data reusability and enable more automated, trustworthy scientific discovery. The benchmark establishment is particularly valuable for future comparative studies.
major comments (3)
- [Section 3.2] Section 3.2: The refinement of encapsulated data into atomic knowledge units and knowledge graphs is described at a high level without specifying the algorithm, any fidelity or information-loss metrics, or privacy-preserving mechanisms. This step is load-bearing for the claim that the resulting heterogeneous graph index enables reliable multi-granularity retrieval.
- [Section 5.1] Section 5.1 and Table 2: The experimental results claim consistent outperformance, yet the manuscript supplies insufficient detail on exact metrics (e.g., nDCG@10, answer accuracy, report coherence scores), baseline implementations, dataset statistics, or statistical significance tests. Without these, the magnitude and robustness of the reported gains cannot be verified.
- [Section 4.3] Section 4.3: No ablation study isolates the contribution of the IoD representation (FAIR objects + graph index) from the multi-agent layer. This is required to substantiate that the data representation, rather than the agent architecture or benchmark construction, drives the improvements over RAG and Deep Research baselines.
minor comments (2)
- The abstract and introduction should define all acronyms (FAIR, RAG, IoD) on first use.
- [Figure 3] Figure 3 (system overview) would benefit from explicit arrows and labels showing the data flow from private sources through refinement to the heterogeneous graph index.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and provide point-by-point responses below. We agree that additional details and analyses will strengthen the paper and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2: The refinement of encapsulated data into atomic knowledge units and knowledge graphs is described at a high level without specifying the algorithm, any fidelity or information-loss metrics, or privacy-preserving mechanisms. This step is load-bearing for the claim that the resulting heterogeneous graph index enables reliable multi-granularity retrieval.
Authors: We acknowledge that the current description in Section 3.2 is at a high level. In the revised manuscript, we will expand this section to specify the exact algorithms for refining data into atomic knowledge units and constructing knowledge graphs. We will also introduce quantitative fidelity and information-loss metrics (e.g., semantic similarity scores and reconstruction error) and detail the privacy-preserving mechanisms, such as local differential privacy and encrypted indexing, to support the reliability claims for multi-granularity retrieval. revision: yes
-
Referee: [Section 5.1] Section 5.1 and Table 2: The experimental results claim consistent outperformance, yet the manuscript supplies insufficient detail on exact metrics (e.g., nDCG@10, answer accuracy, report coherence scores), baseline implementations, dataset statistics, or statistical significance tests. Without these, the magnitude and robustness of the reported gains cannot be verified.
Authors: We agree that greater experimental detail is required for verification and reproducibility. The revised manuscript will include precise definitions and reported values for all metrics (nDCG@10, answer accuracy, report coherence), full descriptions of baseline implementations, comprehensive dataset statistics, and results of statistical significance tests (e.g., paired t-tests with p-values) to substantiate the robustness of the performance gains. revision: yes
-
Referee: [Section 4.3] Section 4.3: No ablation study isolates the contribution of the IoD representation (FAIR objects + graph index) from the multi-agent layer. This is required to substantiate that the data representation, rather than the agent architecture or benchmark construction, drives the improvements over RAG and Deep Research baselines.
Authors: We recognize the value of component isolation. We will add a dedicated ablation study in the revised manuscript that evaluates performance with and without the IoD representation (FAIR objects and heterogeneous graph index) while holding the multi-agent system constant, as well as the reverse, to clearly attribute the observed improvements to the data representation. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents a system design that encapsulates private data as FAIR digital objects, refines them into atomic units and knowledge graphs to build a heterogeneous index, then layers a multi-agent system for QA and reporting. All central claims are evaluated via comparative experiments against external RAG and Deep Research baselines on a newly constructed benchmark. No equations, fitted parameters relabeled as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The architecture and results rest on independent empirical validation rather than reducing to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous scientific data can be encapsulated as FAIR-compliant digital objects without significant information loss or privacy violation.
invented entities (2)
-
atomic knowledge units
no independent evidence
-
heterogeneous graph index
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
encapsulates heterogeneous resources as FAIR-compliant digital objects, and further refines them into atomic knowledge units and knowledge graphs, forming a heterogeneous graph index for multi-granularity retrieval
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-agent system supports both reliable question answering and structured scientific report generation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Towards operationalizing heterogeneous data discovery.arXiv preprint arXiv:2504.02059, 2025
Jin Wang and et al. Towards operationalizing heterogeneous data discovery.arXiv preprint arXiv:2504.02059, 2025. 7 Running Title for Header
-
[2]
Heterogeneous data integration: Challenges and opportunities.Data in Brief, 56:110853, 2024
I Made Putrama and et al. Heterogeneous data integration: Challenges and opportunities.Data in Brief, 56:110853, 2024
work page 2024
-
[3]
Yang Jingru and et al. A technical framework of cross-center trusted sharing of scientific data for the new paradigm of convergence science.Frontiers of Data and Computing, 6(4):22–33, 2024
work page 2024
-
[4]
Lauri Himanen and et al. Data-driven materials science: Status, challenges, and perspectives.Advanced Science, 6(21):1900808, 2019
work page 2019
-
[5]
Knowledge graph-empowered materials discovery
Xintong Zhao and et al. Knowledge graph-empowered materials discovery. In2021 IEEE International Conference on Big Data (Big Data), pages 4628–4632, 2021
work page 2021
-
[6]
Chaoran Luo and et al. Internet of data:a solution for dataspace infrastructure and its technical challenges.Big Data Research (2096-0271), 9(2):110, 2023
work page 2096
-
[7]
Identifier resolution technology for human-cyber-physical ternary based on internet of data
Ning Zhang and et al. Identifier resolution technology for human-cyber-physical ternary based on internet of data. Journal of Software, 35(10):4681–4695, 2023
work page 2023
-
[8]
Robert Kahn, Robert Wilensky, et al. A framework for distributed digital object services.International Journal on Digital Libraries, 6(2):115–123, 2006
work page 2006
-
[9]
Mark D Wilkinson and et al. The fair guiding principles for scientific data management and stewardship.Scientific data, 3(1):1–9, 2016
work page 2016
-
[10]
Deep research agents: A systematic examination and roadmap.arXiv preprint arXiv:2506.18096, 2025
Yuxuan Huang and et al. Deep research agents: A systematic examination and roadmap.arXiv preprint arXiv:2506.18096, 2025
-
[11]
Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers
Chenglei Si and et al. Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers. arXiv preprint arXiv:2409.04109, 2024
-
[12]
Xiang Hu and et al. Nova: An iterative planning and search approach to enhance novelty and diversity of llm generated ideas.arXiv preprint arXiv:2410.14255, 2024
-
[13]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Xiaoxi Li and et al. Search-o1: Agentic search-enhanced large reasoning models.CoRR, abs/2501.05366, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin and et al. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada and et al. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
OpenResearcher: Unleashing AI for accelerated scientific research
Yuxiang Zheng and et al. OpenResearcher: Unleashing AI for accelerated scientific research. In Delia Irazu and et al, editors,2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 209–218. Association for Computational Linguistics, November 2024
work page 2024
-
[17]
Meta data retrieval for data infrastructure via rag
Zhuofan Shi and et al. Meta data retrieval for data infrastructure via rag. In2024 IEEE International Conference on Web Services (ICWS), pages 100–107, 2024
work page 2024
-
[18]
Mineru: An open-source solution for precise document content extraction, 2024
Bin Wang and et al. Mineru: An open-source solution for precise document content extraction, 2024
work page 2024
-
[19]
Ragas: Automated Evaluation of Retrieval Augmented Generation
Shahul Es and et al. RAGAS: Automated Evaluation of Retrieval Augmented Generation.arXiv e-prints, page arXiv:2309.15217, September 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Patrick Lewis and et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[21]
Lightrag: Simple and fast retrieval-augmented generation, 2024
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation, 2024
work page 2024
-
[22]
ZillizTech. Deepsearcher. https://github.com/zilliztech/deep-searcher, 2025. Accessed: 2025-09- 03
work page 2025
-
[23]
An Yang and et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.