Less LLM, More Documents: Searching for Improved RAG
Pith reviewed 2026-05-18 11:10 UTC · model grok-4.3
The pith
Scaling the document corpus in RAG can match the accuracy gains of moving to a larger language model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across multiple open-domain QA benchmarks, corpus scaling consistently strengthens RAG and can in many cases match the gains of moving to a larger model tier, though with diminishing returns at larger scales. Small- and mid-sized generators paired with larger corpora often rival much larger models with smaller corpora; mid-sized models tend to gain the most, while tiny and very large models benefit less. These improvements arise primarily from increased coverage of answer-bearing passages, while utilization efficiency remains largely unchanged.
What carries the argument
The corpus-generator trade-off, in which the scale of the document collection is varied against the size of the generative language model to measure resulting accuracy on question answering tasks.
If this is right
- Small- and mid-sized generators reach performance levels close to those of much larger models when given access to a larger corpus.
- Mid-sized models receive the largest relative lift from corpus expansion.
- Performance improvements stem chiefly from broader coverage of answer-containing passages rather than higher utilization of each retrieved document.
- Corpus scaling exhibits diminishing returns once the collection grows beyond a certain point.
Where Pith is reading between the lines
- Resource-limited deployments could substitute corpus growth for model growth to achieve comparable accuracy at lower inference cost.
- The same trade-off may appear in other retrieval-based tasks such as summarization or fact verification if answer coverage is the dominant factor.
- System designers might identify an optimal corpus size for each model tier rather than scaling both dimensions simultaneously.
Load-bearing premise
The measured gains come mainly from retrieving more passages that contain the correct answer rather than from shifts in retrieval quality, query distribution, or model-specific patterns that might not hold outside the tested benchmarks.
What would settle it
An experiment that keeps retrieval quality fixed while increasing corpus size and shows no corresponding rise in the number of answer-bearing passages retrieved, or no accuracy improvement on the same QA benchmarks.
Figures


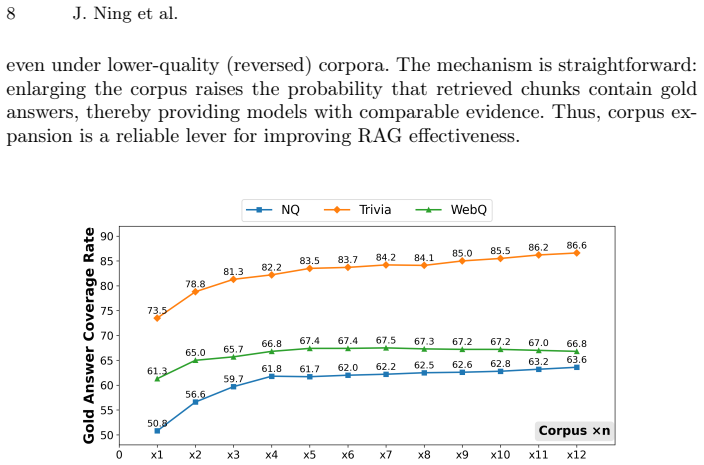


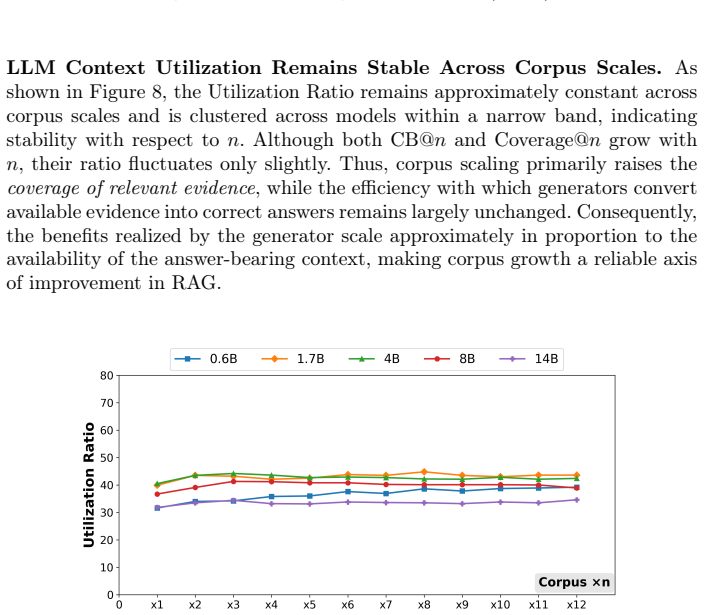

read the original abstract
Retrieval-Augmented Generation (RAG) couples document retrieval with large language models (LLMs). While scaling generators often improves accuracy, it also increases inference and deployment overhead. We study an orthogonal axis: enlarging the retriever's corpus, and how it trades off with generator scale. Across multiple open-domain QA benchmarks, corpus scaling consistently strengthens RAG and can in many cases match the gains of moving to a larger model tier, though with diminishing returns at larger scales. Small- and mid-sized generators paired with larger corpora often rival much larger models with smaller corpora; mid-sized models tend to gain the most, while tiny and very large models benefit less. Our analysis suggests that these improvements arise primarily from increased coverage of answer-bearing passages, while utilization efficiency remains largely unchanged. Overall, our results characterize a corpus-generator trade-off in RAG and provide empirical guidance on how corpus scale and model capacity interact in this setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the trade-off between scaling the retrieval corpus and scaling the generator LLM in RAG for open-domain QA. Across benchmarks, larger corpora improve accuracy, often matching gains from larger models (with diminishing returns), and mid-sized generators benefit most. The authors attribute gains primarily to increased coverage of answer-bearing passages while utilization efficiency remains largely unchanged, providing empirical guidance on corpus vs. model scaling.
Significance. If the central empirical findings hold, the work offers practical, actionable insights into cost-effective RAG design by showing corpus expansion as a viable alternative or complement to model scaling. The multi-benchmark evaluation and interaction analysis with model sizes strengthen its utility for practitioners. The study is empirical benchmarking without machine-checked proofs or parameter-free derivations, but its falsifiable predictions on scaling behavior are a positive.
major comments (1)
- [Analysis section] Analysis section (on coverage vs. utilization): The claim that gains arise primarily from increased coverage of answer-bearing passages (with utilization unchanged) is load-bearing for the corpus-vs-model trade-off recommendation. This requires explicit evidence that top-k recall of gold passages rises or holds steady with corpus growth; if recall degrades due to more distractors outranking answers, the measured accuracy improvements could stem from other factors such as query distribution shifts or benchmark artifacts rather than coverage. The abstract's statement on utilization does not by itself address retrieval-quality degradation.
minor comments (3)
- [Experimental setup] Provide exact corpus sizes, document counts, and retrieval hyperparameters (e.g., k values, embedding models) in the experimental setup to allow reproduction.
- [Results] Include error bars, statistical significance tests, or variance across runs for the reported accuracy gains to support claims of consistent directional findings.
- [Analysis] Clarify the precise definition of 'utilization efficiency' and how it was measured (e.g., via passage ranking position or attention patterns).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comment on the analysis section point by point below and outline the planned revisions.
read point-by-point responses
-
Referee: [Analysis section] Analysis section (on coverage vs. utilization): The claim that gains arise primarily from increased coverage of answer-bearing passages (with utilization unchanged) is load-bearing for the corpus-vs-model trade-off recommendation. This requires explicit evidence that top-k recall of gold passages rises or holds steady with corpus growth; if recall degrades due to more distractors outranking answers, the measured accuracy improvements could stem from other factors such as query distribution shifts or benchmark artifacts rather than coverage. The abstract's statement on utilization does not by itself address retrieval-quality degradation.
Authors: We agree that explicit evidence of top-k recall behavior is important to substantiate the coverage-based explanation and rule out retrieval degradation as a confounding factor. The current manuscript reports increased coverage of answer-bearing passages together with largely unchanged utilization efficiency, but does not present direct top-k recall curves for gold passages across corpus scales. We will revise the analysis section to include these measurements for each benchmark and model size. Our existing experimental logs show that top-k recall either improves modestly or remains stable as the corpus grows, consistent with the coverage gains we report; distractor interference does not appear to dominate within the top-k regime we study. The revised text will explicitly link these recall results to the abstract statement and to the corpus-vs-model scaling recommendations. revision: yes
Circularity Check
No circularity: purely empirical benchmarking study
full rationale
The paper conducts direct experimental comparisons of RAG accuracy under varying corpus sizes and generator scales on open-domain QA benchmarks. No derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations are present. Claims rest on measured outcomes against external benchmarks rather than reducing to inputs by construction, satisfying the self-contained criterion for score 0.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our analysis suggests that these improvements arise primarily from increased coverage of answer-bearing passages, while utilization efficiency remains largely unchanged.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
n⋆(xsmall → xlarge) := min n such that Pm(n, xsmall) ≥ Pm(1, xlarge)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2013 Conference on Empirical Meth- ods in Natural Language Processing
Berant, J., Chou, A., Frostig, R., Liang, P.: Semantic parsing on Freebase from question-answer pairs. In: Proceedings of the 2013 Conference on Empirical Meth- ods in Natural Language Processing. pp. 1533–1544. Association for Computa- tional Linguistics, Seattle, Washington, USA (Oct 2013),https://www.aclweb. org/anthology/D13-1160
work page 2013
-
[2]
Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., van den Driessche, G., Lespiau, J.B., Damoc, B., Clark, A., de Las Casas, D., Guy, A., Menick, J., Ring, R.,Hennigan, T., Huang, S.,Maggiore, L., Jones, C.,Cassirer, A., Brock, A., Paganini, M., Irving, G., Vinyals, O., Osindero, S., Simonyan, K., Rae, J.W., Elsen, E., Sifre, L...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Win- ter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H.W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prab- hakaran, V., Reif, E., Du, N., Hutchinson, B., Pope, R., Bradbury, J., Austin, J., Isard, M., Gur-Ari, G., Yin, P., Duke, T., Levsk...
work page 2023
- [5]
-
[6]
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., Wang, H.: Retrieval-augmented generation for large language models: A survey (2024),https://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Ghorbani, B., Firat, O., Freitag, M., Bapna, A., Krikun, M., Garcia, X., Chelba, C., Cherry, C.: Scaling laws for neural machine translation. In: International Con- ference on Learning Representations (2022),https://openreview.net/forum?id= hR_SMu8cxCV
work page 2022
- [8]
-
[9]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.N
He, Z., Jiang, H., Wang, Z., Yang, Y., Qiu, L.K., Qiu, L.: Position engineer- ing: Boosting large language models through positional information manipula- tion. In: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 7333–
work page 2024
-
[10]
Association for Computational Linguistics, Miami, Florida, USA (Nov 2024). 14 J. Ning et al. https://doi.org/10.18653/v1/2024.emnlp-main.417,https://aclanthology. org/2024.emnlp-main.417/
-
[11]
In: First Conference on Language Modeling (2024),https://openreview.net/forum?id= 3X2L2TFr0f
Hu, S., Tu, Y., Han, X., Cui, G., He, C., Zhao, W., Long, X., Zheng, Z., Fang, Y., Huang, Y., Zhang, X., Thai, Z.L., Wang, C., Yao, Y., Zhao, C., Zhou, J., Cai, J., Zhai, Z., Ding, N., Jia, C., Zeng, G., dahai li, Liu, Z., Sun, M.: MiniCPM: Unveiling the potential of small language models with scalable training strategies. In: First Conference on Language...
work page 2024
-
[12]
Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., Grave, E.: Unsupervised dense information retrieval with contrastive learn- ing (2021).https://doi.org/10.48550/ARXIV.2112.09118,https://arxiv.org/ abs/2112.09118
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2112.09118 2021
-
[13]
Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., Schick, T., Dwivedi- Yu, J., Joulin, A., Riedel, S., Grave, E.: Atlas: few-shot learning with retrieval augmented language models. J. Mach. Learn. Res.24(1) (Jan 2023)
work page 2023
-
[14]
Joshi, M., Choi, E., Weld, D., Zettlemoyer, L.: TriviaQA: A large scale dis- tantly supervised challenge dataset for reading comprehension. In: Barzilay, R., Kan, M.Y. (eds.) Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1601–1611. Asso- ciation for Computational Linguistics, Vancouver...
-
[15]
Kaplan, J., McCandlish, S., Henighan, T., Brown, T.B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., Amodei, D.: Scaling laws for neural language models (2020),https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[16]
In: Webber, B., Cohn, T., He, Y., Liu, Y
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., Yih, W.t.: Dense passage retrieval for open-domain question answering. In: Webber, B., Cohn, T., He, Y., Liu, Y. (eds.) Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 6769–6781. Association for Computational Linguistics, Online (...
work page 2020
-
[17]
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., Toutanova, K., Jones, L., Kelcey, M., Chang, M.W., Dai, A.M., Uszkoreit, J., Le, Q., Petrov, S.: Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics7,...
-
[18]
In: Proceedings of the 34th Interna- tional Conference on Neural Information Processing Systems
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge-intensive nlp tasks. In: Proceedings of the 34th Interna- tional Conference on Neural Information Processing Systems. NIPS ’20, Curran Associates Inc., Red Hook, NY...
work page 2020
-
[19]
In: Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S
Li, S., Stenzel, L., Eickhoff, C., Bahrainian, S.A.: Enhancing retrieval-augmented generation: A study of best practices. In: Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S. (eds.) Proceedings of the 31st Inter- national Conference on Computational Linguistics. pp. 6705–6717. Association for Computational Linguistics,...
work page 2025
-
[20]
Narayanan, D., Shoeybi, M., Casper, J., LeGresley, P., Patwary, M., Korthikanti, V., Vainbrand, D., Kashinkunti, P., Bernauer, J., Catanzaro, B., Phanishayee, A., Zaharia, M.: Efficient large-scale language model training on gpu clusters using Less LLM, More Documents: Searching for Improved RAG 15 megatron-lm.In:ProceedingsoftheInternationalConferencefor...
- [21]
-
[22]
Patterson, D., Gonzalez, J., Le, Q., Liang, C., Munguia, L.M., Rothchild, D., So, D., Texier, M., Dean, J.: Carbon emissions and large neural network train- ing (2021),https://arxiv.org/abs/2104.10350
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
In: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems
Reynolds, L., McDonell, K.: Prompt programming for large language models: Be- yond the few-shot paradigm. In: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems. CHI EA ’21, Association for Comput- ing Machinery, New York, NY, USA (2021).https://doi.org/10.1145/3411763. 3451760,https://doi.org/10.1145/3411763.3451760
-
[24]
Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., Zaharia, M.: ColBERTv2: Effective and efficient retrieval via lightweight late interaction. In: Carpuat, M., de Marneffe, M.C., Meza Ruiz, I.V. (eds.) Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: HumanLanguageTechnologies.pp.3715–3...
-
[25]
Shao, R., He, J., Asai, A., Shi, W., Dettmers, T., Min, S., Zettlemoyer, L., Koh, P.W.: Scaling retrieval-based language models with a trillion-token datastore. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=iAkhPz7Qt3
work page 2024
-
[26]
In: Duh, K., Gomez, H., Bethard, S
Shi, W., Min, S., Yasunaga, M., Seo, M., James, R., Lewis, M., Zettlemoyer, L., Yih, W.t.: REPLUG: Retrieval-augmented black-box language models. In: Duh, K., Gomez, H., Bethard, S. (eds.) Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies (Volume 1: Long Papers)...
-
[27]
Curran Associates Inc., Red Hook, NY, USA (2019)
Subramanya, S.J., Devvrit, Kadekodi, R., Krishaswamy, R., Simhadri, H.V.: DiskANN: fast accurate billion-point nearest neighbor search on a single node. Curran Associates Inc., Red Hook, NY, USA (2019)
work page 2019
-
[28]
Thakur, N., Reimers, N., Rücklé, A., Srivastava, A., Gurevych, I.: BEIR: A het- erogeneous benchmark for zero-shot evaluation of information retrieval models. In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) (2021),https://openreview.net/forum?id= wCu6T5xFjeJ
work page 2021
-
[29]
Natural Language Processing Journal8, 100088 (2024).https://doi.org/https://doi.org/10
Upadhyay, P., Agarwal, R., Dhiman, S., Sarkar, A., Chaturvedi, S.: A com- prehensive survey on answer generation methods using nlp. Natural Language Processing Journal8, 100088 (2024).https://doi.org/https://doi.org/10. 1016/j.nlp.2024.100088,https://www.sciencedirect.com/science/article/ pii/S2949719124000360
-
[30]
In: Chiruzzo, L., Ritter, A., Wang, L
Vladika, J., Matthes, F.: On the influence of context size and model choice in retrieval-augmented generation systems. In: Chiruzzo, L., Ritter, A., Wang, L. (eds.) Findings of the Association for Computational Linguistics: NAACL 2025. 16 J. Ning et al. pp. 6724–6736. Association for Computational Linguistics, Albuquerque, New Mexico (Apr 2025).https://do...
-
[31]
In: Gavrilidou, M., Carayannis, G., Markantonatou, S., Piperidis, S., Stainhauer, G
Voorhees, E.M., Tice, D.M.: The TREC-8 question answering track. In: Gavrilidou, M., Carayannis, G., Markantonatou, S., Piperidis, S., Stainhauer, G. (eds.) Pro- ceedings of the Second International Conference on Language Resources and Eval- uation (LREC’00). European Language Resources Association (ELRA), Athens, Greece (May 2000),https://aclanthology.or...
work page 2000
- [32]
-
[33]
https://openreview.net/forum?id=1PL1NIMMrw
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N.A., Khashabi, D., Hajishirzi, H.: Self-instruct: Aligning language models with self-generated instructions. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Proceedings of the 61st An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13484–13508. Association fo...
-
[34]
Xiong, L., Xiong, C., Li, Y., Tang, K.F., Liu, J., Bennett, P.N., Ahmed, J., Over- wijk, A.: Approximate nearest neighbor negative contrastive learning for dense text retrieval. In: International Conference on Learning Representations (2021), https://openreview.net/forum?id=zeFrfgyZln
work page 2021
- [35]
-
[36]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
arXiv preprint arXiv:2308.10792 (2023)
Zhang, S., Dong, L., Li, X., Zhang, S., Sun, X., Wang, S., Li, J., Hu, R., Zhang, T., Wu, F., et al.: Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792 (2023)
-
[38]
Zhu, X., Li, J., Liu, Y., Ma, C., Wang, W.: A survey on model compression for large language models. Transactions of the Association for Computational Linguistics12, 1556–1577 (11 2024).https://doi.org/10.1162/tacl_a_00704, https://doi.org/10.1162/tacl_a_00704
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.