When Should Users Check? Modeling Confirmation Frequency inMulti-Step Agentic AI Tasks
Pith reviewed 2026-05-18 08:56 UTC · model grok-4.3
The pith
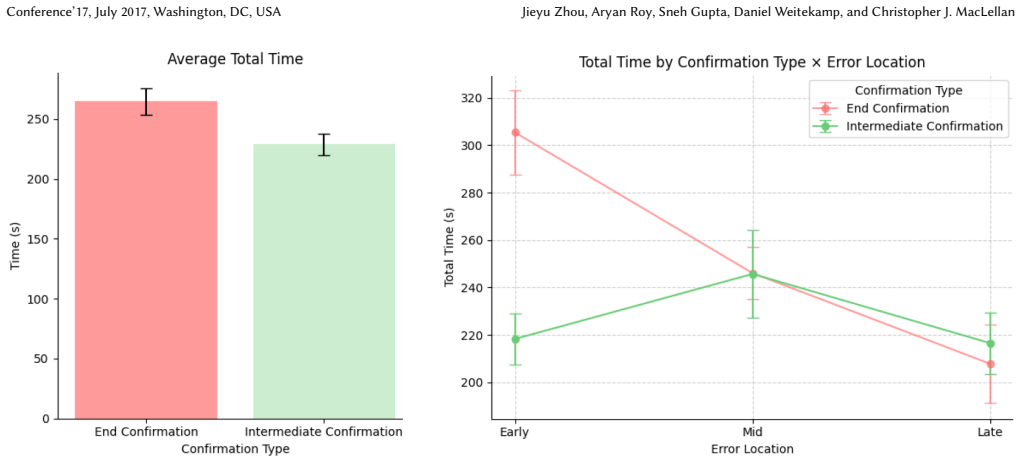
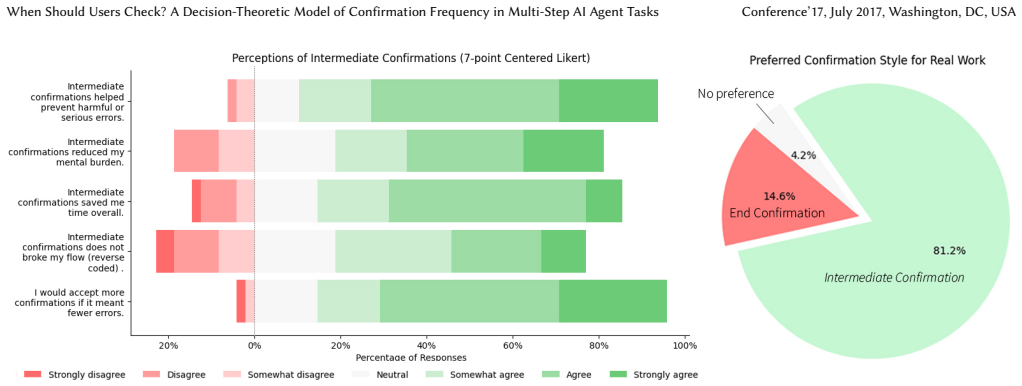
A decision-theoretic model for scheduling user confirmations in multi-step AI tasks reduces completion time by 13.54 percent and earns preference from 81 percent of users over end-only checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that confirmation frequency in agentic AI can be optimized by modeling it as a minimum-time scheduling problem grounded in the Confirmation-Diagnosis-Correction-Redo pattern observed in user monitoring behavior. Formative observations with a small group revealed how users typically verify steps, diagnose issues, correct them, and redo segments when needed. This pattern informed a decision-theoretic model that selects confirmation points to balance the cost of interruptions against the cost of rollbacks. A larger within-subjects study then demonstrated that this model-guided placement yields shorter overall task times and stronger user preference compared to confirming a
What carries the argument
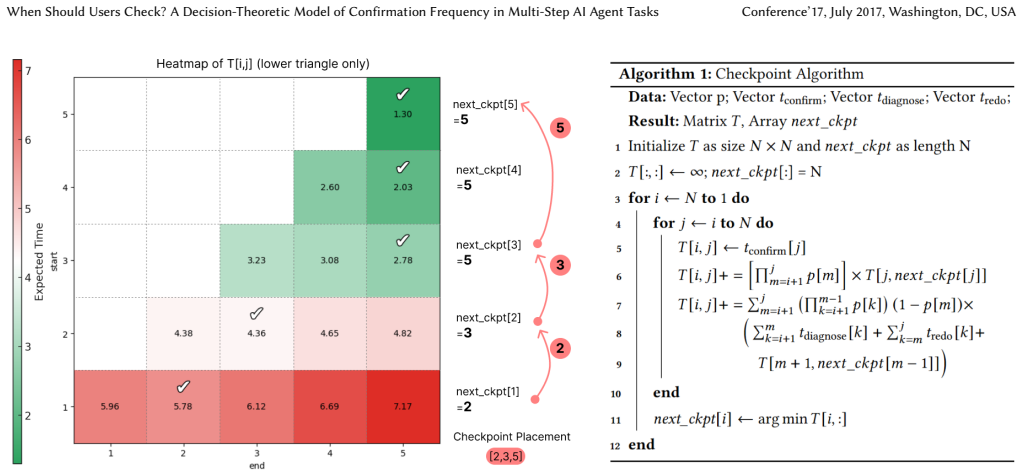
The Confirmation-Diagnosis-Correction-Redo (CDCR) pattern, which captures the sequence users follow when monitoring and repairing AI errors, serves as the foundation for the decision-theoretic model that schedules confirmation points to minimize total execution plus recovery time.
If this is right
- Task completion time decreases when confirmations occur at model-selected intermediate points rather than only at the end.
- Most users prefer the intermediate confirmation strategy over the confirm-at-end method used in current systems.
- AI agents become less prone to complete restarts from single early errors while avoiding the overhead of constant checks.
- The scheduling model offers a concrete way to trade off interruption costs against rollback costs in agent workflows.
Where Pith is reading between the lines
- The same scheduling logic could be applied to other human oversight scenarios such as data analysis pipelines or code generation sessions.
- AI system builders might embed similar models to suggest or automate check points dynamically based on task structure.
- Over time, repeated use of the pattern could reveal broader rules for when human intervention pays off in longer agent runs.
Load-bearing premise
The Confirmation-Diagnosis-Correction-Redo pattern observed with eight participants generalizes to the tasks and participants used in the larger evaluation, enabling the model to correctly predict efficient confirmation points.
What would settle it
A new study using different multi-step tasks that measures whether the model still produces measurable time savings and user preference over confirm-at-end would directly test the claim.
Figures




read the original abstract
Existing AI agents typically execute multi-step tasks autonomously and only allow user confirmation at the end. During execution, users have little control, making the confirm-at-end approach brittle: a single error can cascade and force a complete restart. Confirming every step avoids such failures, but imposes tedious overhead. Balancing excessive interruptions against costly rollbacks remains an open challenge. We address this problem by modeling confirmation as a minimum time scheduling problem. We conducted a formative study with eight participants, which revealed a recurring Confirmation-Diagnosis-Correction-Redo (CDCR) pattern in how users monitor errors. Based on this pattern, we developed a decision-theoretic model to determine time-efficient confirmation point placement. We then evaluated our approach using a within-subjects study where 48 participants monitored AI agents and repaired their mistakes while executing tasks. Results show that 81 percent of participants preferred our intermediate confirmation approach over the confirm-at-end approach used by existing systems, and task completion time was reduced by 13.54 percent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modeling user confirmation in multi-step AI agent tasks as a minimum-time scheduling problem, informed by a Confirmation-Diagnosis-Correction-Redo (CDCR) pattern observed in a formative study with 8 participants, yields a decision-theoretic model that places intermediate confirmations more efficiently than the confirm-at-end baseline used by existing systems. In a within-subjects evaluation with 48 participants, this approach is preferred by 81% of users and reduces task completion time by 13.54%.
Significance. If the CDCR pattern generalizes beyond the small formative sample and the reported gains are attributable to the model's specific placement decisions rather than intermediate confirmations in general, the work could improve reliability and user agency in agentic AI systems by reducing costly rollbacks while avoiding excessive interruptions. The within-subjects design and concrete preference/time metrics provide a useful empirical anchor for future human-AI interaction research.
major comments (2)
- [Formative Study] Formative study: The CDCR pattern and its associated time costs are derived from only eight participants, yet the manuscript provides no data, logs, or analysis demonstrating that this pattern occurs at comparable rates or with similar costs in the 48-participant main study. Because the decision-theoretic model is parameterized directly from this pattern to select confirmation points, the absence of re-validation means the 81% preference and 13.54% time reduction cannot be confidently attributed to the model rather than to any form of intermediate confirmation.
- [Evaluation] Evaluation section: No details are supplied on the statistical tests supporting the time-reduction claim, the controls used for task difficulty across conditions, or how the free parameters (time costs for confirmation, diagnosis, correction, and redo) were estimated or fitted from the formative data. These omissions are load-bearing for the central quantitative claims.
minor comments (1)
- The abstract and methods could more explicitly state the exact tasks used, how confirmation points were implemented in the interface, and whether participants were aware of the different conditions.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below and have made revisions to strengthen the manuscript where the comments identify omissions or areas needing clarification.
read point-by-point responses
-
Referee: [Formative Study] Formative study: The CDCR pattern and its associated time costs are derived from only eight participants, yet the manuscript provides no data, logs, or analysis demonstrating that this pattern occurs at comparable rates or with similar costs in the 48-participant main study. Because the decision-theoretic model is parameterized directly from this pattern to select confirmation points, the absence of re-validation means the 81% preference and 13.54% time reduction cannot be confidently attributed to the model rather than to any form of intermediate confirmation.
Authors: The formative study was conducted to identify the recurring CDCR behavioral pattern through direct observation, which then informed the time-cost parameters in the decision-theoretic model. We acknowledge that the original manuscript did not include a quantitative re-validation of CDCR occurrence rates from the main-study logs. To address this concern, we have added an analysis section that reports the frequency of CDCR sequences observed in the 48-participant data and compares the empirical time costs to those used in the model. This addition helps demonstrate that the pattern generalizes and that the reported gains stem from the model's optimized placement decisions rather than intermediate confirmations in general. revision: yes
-
Referee: [Evaluation] Evaluation section: No details are supplied on the statistical tests supporting the time-reduction claim, the controls used for task difficulty across conditions, or how the free parameters (time costs for confirmation, diagnosis, correction, and redo) were estimated or fitted from the formative data. These omissions are load-bearing for the central quantitative claims.
Authors: We agree that these methodological details were insufficiently reported. In the revised manuscript we now specify: (1) the statistical tests (paired t-tests with reported t-statistics, p-values, and Cohen's d effect sizes for completion time, plus Wilcoxon signed-rank tests for preference data); (2) the controls for task difficulty, including selection of tasks with matched step counts and complexity, plus within-subjects counterbalancing of condition order; and (3) the parameter estimation procedure, in which mean durations for each CDCR phase were computed directly from timestamped observations in the formative study and used as fixed inputs to the scheduler. These additions make the quantitative claims fully reproducible. revision: yes
Circularity Check
No significant circularity; derivation grounded in separate formative data and standard decision theory
full rationale
The paper's chain proceeds from an independent formative study (n=8) that identifies the CDCR pattern, applies standard decision-theoretic scheduling to place confirmations, and then evaluates the resulting approach in a separate within-subjects experiment (n=48) whose outcomes (preference and time metrics) are measured directly rather than derived by construction from the model's fitted parameters. No equations or claims reduce the central result to self-definition, renamed inputs, or load-bearing self-citations; the evaluation data and participant preferences constitute external evidence relative to the model's construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Time costs for confirmation, diagnosis, correction, and redo actions
axioms (1)
- domain assumption Users follow a recurring Confirmation-Diagnosis-Correction-Redo (CDCR) pattern when monitoring and repairing AI agent errors.
Reference graph
Works this paper leans on
-
[1]
Constructions Aeronautiques, Adele Howe, Craig Knoblock, ISI Drew McDer- mott, Ashwin Ram, Manuela Veloso, Daniel Weld, David Wilkins Sri, Anthony Barrett, Dave Christianson, et al. 1998. Pddl—the planning domain definition language.Technical Report, Tech. Rep.(1998)
work page 1998
-
[2]
Layla AI. 2024. About me, Layla: AI Trip Planner and Travel Sidekick. https: //layla.ai/about. Accessed: July 2025
work page 2024
-
[3]
Pokee AI. 2024. Revolutionize Digital Productivity with AI-Powered Workflow Automation. https://pokee.ai/home. Accessed: July 2025
work page 2024
-
[4]
Lize Alberts, Ulrik Lyngs, and Max Van Kleek. 2024. Computers as bad social actors: Dark patterns and anti-patterns in interfaces that act socially.Proceedings of the ACM on Human-Computer Interaction8, CSCW1 (2024), 1–25
work page 2024
-
[5]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schul- man, and Dan Mané. 2016. Concrete problems in AI safety.arXiv preprint arXiv:1606.06565(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Anthropic. 2024. Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. https://www.anthropic.com/news/3-5-models-and-computer-use. Accessed: July 2025
work page 2024
-
[7]
Ian Arawjo, Chelse Swoopes, Priyan Vaithilingam, Martin Wattenberg, and Elena L Glassman. 2024. Chainforge: A visual toolkit for prompt engineering and llm hypothesis testing. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–18
work page 2024
-
[8]
Zahra Ashktorab, Mohit Jain, Q Vera Liao, and Justin D Weisz. 2019. Resilient chatbots: Repair strategy preferences for conversational breakdowns. InPro- ceedings of the 2019 CHI conference on human factors in computing systems. 1–12
work page 2019
-
[9]
Rui Assis and Pedro Carmona Marques. 2021. A dynamic methodology for setting up inspection time intervals in conditional preventive maintenance. Applied Sciences11, 18 (2021), 8715
work page 2021
- [10]
-
[11]
Richard Barlow and Larry Hunter. 1960. Optimum preventive maintenance policies.Operations research8, 1 (1960), 90–100
work page 1960
-
[12]
Hugh Beyer and Karen Holtzblatt. 1999. Contextual design.interactions6, 1 (1999), 32–42
work page 1999
-
[13]
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al
- [14]
-
[15]
Virginia Braun and Victoria Clarke. 2012.Thematic analysis.57–71
work page 2012
-
[16]
Matthew Chang, Gunjan Chhablani, Alexander Clegg, Mikael Dallaire Cote, Ruta Desai, Michal Hlavac, Vladimir Karashchuk, Jacob Krantz, Roozbeh Mottaghi, Priyam Parashar, et al. 2024. PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks.arXiv preprint arXiv:2411.00081(2024)
-
[17]
Andy Cockburn, Blaine Lewis, Philip Quinn, and Carl Gutwin. 2020. Framing effects influence interface feature decisions. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems. 1–11
work page 2020
-
[18]
Andy Cockburn, Philip Quinn, Carl Gutwin, Zhe Chen, and Pang Suwanaposee
-
[19]
InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems
Probability weighting in interactive decisions: Evidence for overuse of bad assistance, underuse of good assistance. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–12
work page 2022
-
[20]
CrewAI. 2024. What is CrewAI? https://docs.crewai.com/en/introduction. Ac- cessed: July 2025
work page 2024
-
[21]
Anindya Das Antar, Somayeh Molaei, Yan-Ying Chen, Matthew L Lee, and Nikola Banovic. 2024. VIME: Visual Interactive Model Explorer for Identify- ing Capabilities and Limitations of Machine Learning Models for Sequential Decision-Making. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–21
work page 2024
-
[22]
Bram De Jonge and Philip A Scarf. 2020. A review on maintenance optimization. European journal of operational research285, 3 (2020), 805–824
work page 2020
-
[23]
Rommert Dekker, Ralph E Wildeman, and Frank A Van der Duyn Schouten. 1997. A review of multi-component maintenance models with economic dependence. Mathematical methods of operations research45, 3 (1997), 411–435
work page 1997
-
[24]
Zane Durante, Qiuyuan Huang, Naoki Wake, Ran Gong, Jae Sung Park, Bidipta Sarkar, Rohan Taori, Yusuke Noda, Demetri Terzopoulos, Yejin Choi, et al. 2024. Agent ai: Surveying the horizons of multimodal interaction.arXiv preprint arXiv:2401.03568(2024). When Should Users Check? A Decision-Theoretic Model of Confirmation Frequency in Multi-Step AI Agent Task...
work page internal anchor Pith review arXiv 2024
- [25]
-
[26]
Will Epperson, Gagan Bansal, Victor C Dibia, Adam Fourney, Jack Gerrits, Erkang Zhu, and Saleema Amershi. 2025. Interactive debugging and steering of multi-agent ai systems. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–15
work page 2025
- [27]
-
[28]
Flowith. 2024. Introduction to Flow Mode. https://doc.flowith.io/flow-mode- general-mode/introduction-to-flow-mode. Accessed: July 2025
work page 2024
-
[29]
Genspark. 2024. Understanding Genspark.AI. https://genspark.ai/spark/ understanding-genspark-ai. Accessed: July 2025
work page 2024
-
[30]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI conference on Human Factors in Computing Systems. 159–166
work page 1999
- [31]
-
[32]
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. 2024. Understanding the planning of LLM agents: A survey.arXiv preprint arXiv:2402.02716(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Faria Huq, Jeffrey P Bigham, and Nikolas Martelaro. 2023. " What’s important here?": Opportunities and Challenges of Using LLMs in Retrieving Information from Web Interfaces.arXiv preprint arXiv:2312.06147(2023)
-
[34]
Deniz Iren and Semih Bilgen. 2014. Cost of quality in crowdsourcing.Human Computation1, 2 (2014)
work page 2014
-
[35]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation.Comput. Surveys55, 12 (2023), 1–38
work page 2023
- [36]
-
[37]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran- Johnson, et al. 2022. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [38]
-
[39]
Majeed Kazemitabaar, Jack Williams, Ian Drosos, Tovi Grossman, Austin Zachary Henley, Carina Negreanu, and Advait Sarkar. 2024. Improving steering and verification in AI-assisted data analysis with interactive task decomposition. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–19
work page 2024
-
[40]
Kevin C Lam, Carl Gutwin, Madison Klarkowski, and Andy Cockburn. 2022. More Errors vs. Longer Commands: The Effects of Repetition and Reduced Expressiveness on Input Interpretation Error, Learning, and Effort. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–17
work page 2022
-
[41]
Lane Lawley and Christopher J. MacLellan. 2024. VAL: Interactive Task Learning with GPT Dialog Parsing. InProceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24). https://doi.org/10.1145/3613904.3641915
-
[42]
John D Lee and Katrina A See. 2004. Trust in automation: Designing for appro- priate reliance.Human factors46, 1 (2004), 50–80
work page 2004
-
[43]
Ariel Levy, Monica Agrawal, Arvind Satyanarayan, and David Sontag. 2021. Assessing the impact of automated suggestions on decision making: Domain experts mediate model errors but take less initiative. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–13
work page 2021
-
[44]
Amanda Li, Jason Wu, and Jeffrey P Bigham. 2023. Using LLMs to Customize the UI of Webpages. InAdjunct Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 1–3
work page 2023
-
[45]
Toby Jia-Jun Li, Amos Azaria, and Brad A Myers. 2017. SUGILITE: creating multimodal smartphone automation by demonstration. InProceedings of the 2017 CHI conference on human factors in computing systems. 6038–6049
work page 2017
-
[46]
Toby Jia-Jun Li, Jingya Chen, Haijun Xia, Tom M Mitchell, and Brad A Myers
-
[47]
InProceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology
Multi-modal repairs of conversational breakdowns in task-oriented dialogs. InProceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology. 1094–1107
-
[48]
Henry Lieberman. 1997. Autonomous interface agents. InProceedings of the ACM SIGCHI Conference on Human factors in computing systems. 67–74
work page 1997
- [49]
-
[50]
Alexandra Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat. 2023. Esti- mating the carbon footprint of bloom, a 176b parameter language model.Journal of machine learning research24, 253 (2023), 1–15
work page 2023
-
[51]
Reuben Luera, Ryan A Rossi, Alexa Siu, Franck Dernoncourt, Tong Yu, Sungchul Kim, Ruiyi Zhang, Xiang Chen, Hanieh Salehy, Jian Zhao, et al. 2024. Survey of User Interface Design and Interaction Techniques in Generative AI Applications. arXiv preprint arXiv:2410.22370(2024), 1–42
-
[52]
Zeyao Ma, Bohan Zhang, Jing Zhang, Jifan Yu, Xiaokang Zhang, Xiaohan Zhang, Sijia Luo, Xi Wang, and Jie Tang. 2024. Spreadsheetbench: Towards challenging real world spreadsheet manipulation.Advances in Neural Information Processing Systems37 (2024), 94871–94908
work page 2024
-
[53]
Pattie Maes. 1995. Agents that reduce work and information overload. In Readings in human–computer interaction. Elsevier, 811–821
work page 1995
-
[54]
Manus. 2024. Leave it to Manus: General AI Agent for Work and Life. https: //manus.im/home. Accessed: July 2025
work page 2024
-
[55]
2024.Browser Use: Enable AI to control your browser
Magnus Müller and Gregor Žunič. 2024.Browser Use: Enable AI to control your browser. https://github.com/browser-use/browser-use
work page 2024
-
[56]
Dana S Nau, Tsz-Chiu Au, Okhtay Ilghami, Ugur Kuter, J William Murdock, Dan Wu, and Fusun Yaman. 2003. SHOP2: An HTN planning system.Journal of artificial intelligence research20 (2003), 379–404
work page 2003
-
[57]
OpenAI. 2025. Introducing ChatGPT agent: bridging research and action. https: //openai.com/index/introducing-chatgpt-agent. Accessed: July 2025
work page 2025
-
[58]
Vishal Pallagani, Bharath Chandra Muppasani, Kaushik Roy, Francesco Fabiano, Andrea Loreggia, Keerthiram Murugesan, Biplav Srivastava, Francesca Rossi, Lior Horesh, and Amit Sheth. 2024. On the prospects of incorporating large lan- guage models (llms) in automated planning and scheduling (aps). InProceedings of the International Conference on Automated Pl...
work page 2024
-
[59]
Raja Parasuraman and Dietrich H Manzey. 2010. Complacency and bias in human use of automation: An attentional integration.Human factors52, 3 (2010), 381–410
work page 2010
-
[60]
David Patterson, Joseph Gonzalez, Urs Hölzle, Quoc Le, Chen Liang, Lluis- Miquel Munguia, Daniel Rothchild, David R So, Maud Texier, and Jeff Dean
-
[61]
The carbon footprint of machine learning training will plateau, then shrink.Computer55, 7 (2022), 18–28
work page 2022
-
[62]
David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. Carbon emissions and large neural network training.arXiv preprint arXiv:2104.10350(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[63]
Philip Quinn and Andy Cockburn. 2016. When bad feels good: Assistance failures and interface preferences. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems. 4005–4010
work page 2016
-
[64]
Philip Quinn and Andy Cockburn. 2020. Loss aversion and preferences in interaction.Human–Computer Interaction35, 2 (2020), 143–190
work page 2020
-
[65]
rabbit research team. 2023. Learning human actions on computer applications. https://rabbit.tech/research
work page 2023
-
[66]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems36 (2023), 68539–68551
work page 2023
- [67]
-
[68]
Vikas Shivashankar, Ron Alford, Ugur Kuter, and Dana S Nau. 2013. Hierarchical goal networks and goal-driven autonomy: Going where ai planning meets goal reasoning. InGoal Reasoning: Papers from the ACS Workshop, Vol. 95
work page 2013
-
[69]
Ben Shneiderman. 2020. Human-centered artificial intelligence: Reliable, safe & trustworthy.International Journal of Human–Computer Interaction36, 6 (2020), 495–504
work page 2020
-
[70]
Ben Shneiderman and Pattie Maes. 1997. Direct manipulation vs. interface agents.interactions4, 6 (1997), 42–61
work page 1997
-
[71]
Kaya Stechly, Karthik Valmeekam, and Subbarao Kambhampati. 2024. Chain of thoughtlessness? an analysis of cot in planning.Advances in Neural Information Processing Systems37 (2024), 29106–29141
work page 2024
-
[72]
Sangho Suh, Meng Chen, Bryan Min, Toby Jia-Jun Li, and Haijun Xia. 2024. Luminate: Structured generation and exploration of design space with large language models for human-ai co-creation. InProceedings of the 2024 CHI Con- ference on Human Factors in Computing Systems. 1–26
work page 2024
-
[73]
Theodore Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas Griffiths. 2023. Cognitive architectures for language agents.Transactions on Machine Learning Research(2023)
work page 2023
-
[74]
Sharareh Taghipour and Dragan Banjevic. 2012. Optimal inspection of a com- plex system subject to periodic and opportunistic inspections and preventive replacements.European Journal of Operational Research220, 3 (2012), 649–660
work page 2012
-
[75]
Mike Ten Wolde and Adel A Ghobbar. 2013. Optimizing inspection inter- vals—Reliability and availability in terms of a cost model: A case study on railway carriers.Reliability Engineering & System Safety114 (2013), 137–147
work page 2013
-
[76]
David Tennenhouse. 2000. Proactive computing.Commun. ACM43, 5 (2000), 43–50
work page 2000
-
[77]
Sebastian Thrun. 2002. Probabilistic robotics.Commun. ACM45, 3 (2002), 52–57. Conference’17, July 2017, Washington, DC, USA Jieyu Zhou, Aryan Roy, Sneh Gupta, Daniel Weitekamp, and Christopher J. MacLellan
work page 2002
-
[78]
Kashyap Todi, Gilles Bailly, Luis Leiva, and Antti Oulasvirta. 2021. Adapting user interfaces with model-based reinforcement learning. InProceedings of the 2021 CHI conference on human factors in computing systems. 1–13
work page 2021
-
[79]
Browser Use. 2024. The AI browser agent. https://browser-use.com. Accessed: July 2025
work page 2024
-
[80]
Karthik Valmeekam, Matthew Marquez, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. 2023. Planbench: An extensible benchmark for evaluat- ing large language models on planning and reasoning about change.Advances in Neural Information Processing Systems36 (2023), 38975–38987
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.