TelecomTS: A Multi-Modal Observability Dataset for Time Series and Language Analysis
Pith reviewed 2026-05-21 20:19 UTC · model grok-4.3
The pith
A new 5G observability dataset shows that current time series and multi-modal models struggle with abrupt, noisy, high-variance dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TelecomTS is a heterogeneous, de-anonymized observability dataset from a 5G network that retains explicit absolute scale in covariates and supports downstream tasks such as anomaly detection, root cause analysis, and multi-modal question-answering; evaluations show that existing time series, language, reasoning, and multi-modal foundation models struggle with its abrupt, noisy, and high-variance dynamics, underscoring the importance of preserving and natively leveraging scale information.
What carries the argument
The TelecomTS dataset supplying raw-scale 5G network metrics and associated multi-modal tasks that expose model limitations on stochastic observability data.
If this is right
- Foundation time series models should be designed to accept and use absolute scale information in covariates rather than assuming normalized inputs.
- Approaches trained primarily on low-variance domains will likely underperform on high-stochasticity monitoring data without adaptation.
- Multi-modal models can now be directly compared on root cause analysis and question-answering using paired time series and textual descriptions from the same system.
- Public benchmarks for observability applications must retain raw scale values to remain representative of production environments.
Where Pith is reading between the lines
- Comparable datasets from cloud or IoT monitoring could reveal whether the observed model limitations generalize beyond telecommunications.
- Pretraining objectives that explicitly model zero-inflation and abrupt shifts might yield more robust observability-specific models.
- Routine preservation of absolute scale during data collection could become standard practice for time series applications in other noisy domains.
Load-bearing premise
The dataset drawn from one 5G network is representative of general enterprise observability data and the selected tasks reflect authentic real-world challenges without selection bias.
What would settle it
A replication showing that current models reach high accuracy on TelecomTS tasks after standard fine-tuning, or that the same performance gap does not appear on other observability datasets, would challenge the central claim.
Figures
















read the original abstract
Modern enterprises generate vast streams of time series metrics when monitoring complex systems, known as observability data. Unlike conventional time series from domains such as climate, observability data are zero-inflated, highly stochastic, and exhibit minimal temporal structure. Despite their importance, observability datasets remain underrepresented in public benchmarks due to proprietary restrictions and privacy concerns. Existing datasets are often anonymized and normalized, removing scale information and limiting their use for tasks such as anomaly detection, root cause analysis, and multi-modal reasoning. To address this gap, we introduce TelecomTS, a large-scale observability dataset derived from a 5G telecommunications network. TelecomTS features heterogeneous, de-anonymized covariates with explicit absolute scale information and provides a diverse suite of downstream tasks, including anomaly detection, root cause analysis, and multi-modal question-answering. Benchmarking state-of-the-art time series, language, reasoning, and multi-modal foundation models reveals that existing approaches struggle with the abrupt, noisy, and high-variance dynamics characteristic of observability data. Our experiments further underscore the importance of preserving covariates' absolute scale, emphasizing the need for foundation time series models that natively leverage scale information for practical real-world observability applications. The code is available at: https://github.com/Ali-maatouk/TelecomTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TelecomTS, a large-scale multi-modal observability dataset derived from a single 5G telecommunications network. It provides heterogeneous, de-anonymized covariates retaining absolute scale information and defines downstream tasks including anomaly detection, root cause analysis, and multi-modal question-answering. Benchmarking of state-of-the-art time series, language, reasoning, and multi-modal foundation models is reported to show that existing approaches struggle with the abrupt, noisy, and high-variance dynamics of observability data, with additional emphasis on the importance of preserving absolute scale.
Significance. If the empirical findings hold, the work is significant for releasing a public dataset that fills a gap in observability benchmarks, which are typically anonymized or normalized and thus limited for tasks requiring scale and noise modeling. The explicit availability of code at the cited GitHub repository supports reproducibility. The focus on scale information could usefully guide future foundation model development for real-world monitoring applications, though the single-network origin constrains broader generalization.
major comments (2)
- [Experiments section] Experiments section: The benchmarking claims that models struggle with observability dynamics are presented without sufficient detail on model variants, exact evaluation metrics, hyperparameter choices, or statistical significance tests; this prevents verification of the performance gaps and their attribution to abrupt/noisy characteristics rather than implementation choices.
- [Dataset and Tasks sections] Dataset and Tasks sections: The dataset is collected from one 5G deployment; without additional analysis or cross-validation showing that zero-inflation, covariate scales, and variance patterns are representative of general enterprise observability (rather than telecom-specific artifacts), the claim that SOTA models struggle with characteristic observability dynamics rests on an untested proxy assumption.
minor comments (2)
- [Abstract] Abstract: The summary of benchmarking results does not name the specific models or tasks evaluated, reducing standalone clarity.
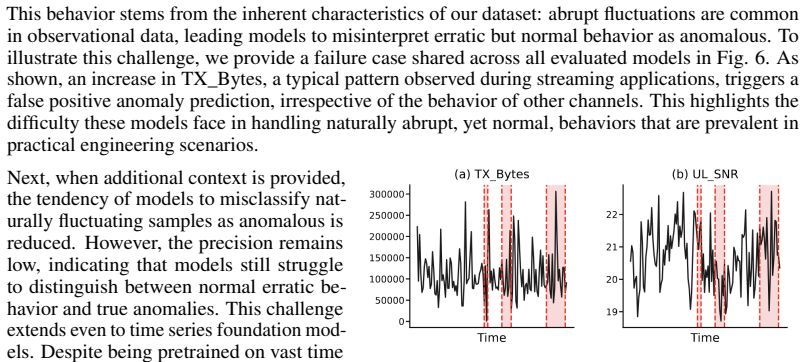
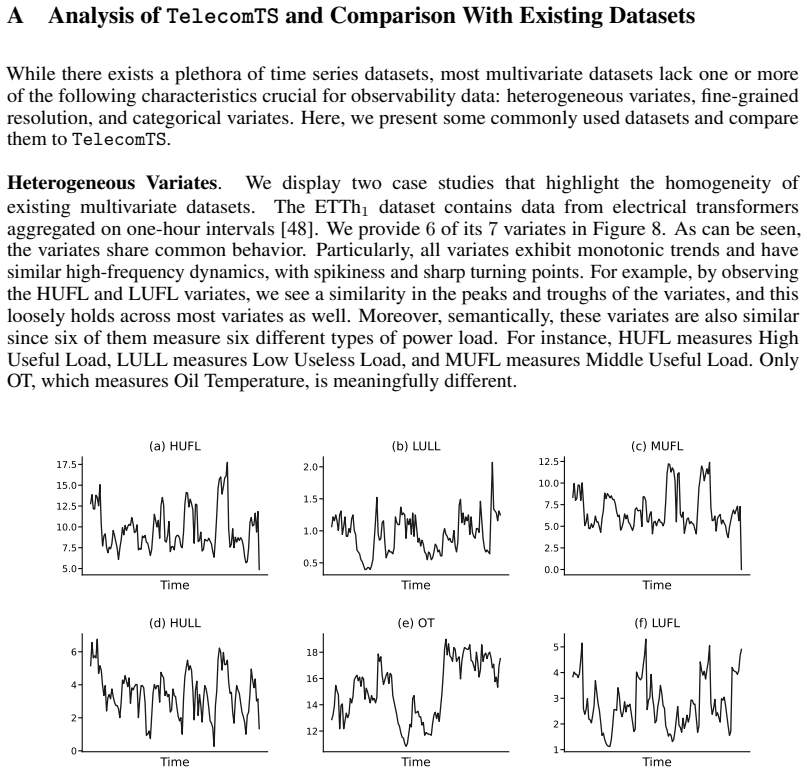
- [Figures] Figures: Time-series example plots would benefit from explicit scale annotations and legends to illustrate the absolute-scale preservation emphasized in the text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and describe the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: The benchmarking claims that models struggle with observability dynamics are presented without sufficient detail on model variants, exact evaluation metrics, hyperparameter choices, or statistical significance tests; this prevents verification of the performance gaps and their attribution to abrupt/noisy characteristics rather than implementation choices.
Authors: We agree that the current level of detail is insufficient for independent verification. In the revised manuscript we will expand the Experiments section with (i) an exhaustive table of all model variants including architecture, parameter count, and fine-tuning procedure, (ii) precise definitions and formulas for every evaluation metric, (iii) the full hyperparameter search space and final selected values, and (iv) results of statistical significance tests (bootstrap confidence intervals and paired Wilcoxon tests) that quantify the performance gaps. These additions will allow readers to attribute differences more confidently to data characteristics. revision: yes
-
Referee: [Dataset and Tasks sections] Dataset and Tasks sections: The dataset is collected from one 5G deployment; without additional analysis or cross-validation showing that zero-inflation, covariate scales, and variance patterns are representative of general enterprise observability (rather than telecom-specific artifacts), the claim that SOTA models struggle with characteristic observability dynamics rests on an untested proxy assumption.
Authors: We acknowledge that TelecomTS originates from a single network and that explicit cross-network validation is not feasible with the data we have access to. In the revision we will add a dedicated Limitations subsection that (a) qualifies the generalization claim, (b) cites domain literature indicating that zero-inflation, absolute-scale heterogeneity, and abrupt variance are common across enterprise observability platforms, and (c) positions TelecomTS as an initial public benchmark rather than a definitive universal proxy. We will also soften the language in the abstract and introduction to reflect this scope. revision: partial
Circularity Check
Dataset release and empirical benchmarking exhibit no circularity
full rationale
The paper's core contribution is the release of TelecomTS, a new 5G-derived observability dataset, together with downstream tasks (anomaly detection, root cause analysis, multi-modal QA) and benchmarking of existing foundation models. No derivation chain, equations, or fitted parameters are claimed; the reported model struggles are direct empirical observations on the released data rather than reductions to prior fits or self-citations. The work is self-contained against external benchmarks because the dataset and tasks are newly introduced and the evaluation uses standard public models without load-bearing self-referential premises.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Observability data are zero-inflated, highly stochastic, and exhibit minimal temporal structure.
Forward citations
Cited by 1 Pith paper
-
Towards Resilient and Autonomous Networks: A BlueSky Vision on AI-Native 6G
The paper envisions AI-native 6G networks anchored by a foundation model and multi-agent systems to shift network management to a unified multi-modal optimization problem.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.