DELTA: Dynamic Layer-Aware Token Attention for Efficient Long-Context Reasoning
Pith reviewed 2026-05-18 07:22 UTC · model grok-4.3
The pith
DELTA partitions transformer layers so a few early ones pick salient tokens for sparse attention later, matching full-attention accuracy on long reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DELTA is a training-free sparse attention design that keeps the complete KV cache but computes full attention only in the first layers and in a small set of Δ-layers; the Δ-layers produce an aggregated head-level attention map whose top tokens are then reused by all subsequent layers under sparse attention, thereby cutting the number of attended tokens without cumulative selection errors on extended reasoning chains.
What carries the argument
Δ-layers that aggregate head-level attention scores to identify a stable subset of salient tokens for reuse in all later sparse-attention layers.
If this is right
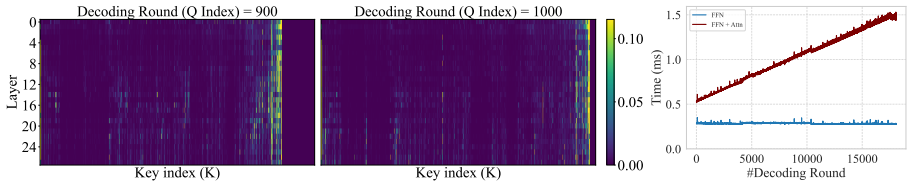
- Attended token count drops by up to 4.25 times while accuracy on AIME and GPQA-Diamond stays the same or improves.
- End-to-end decoding runs 1.54 times faster because full attention is avoided in the majority of layers.
- The full KV cache is retained in GPU memory so no eviction-induced errors accumulate.
- Selective reuse of intermediate attention maps from the Δ-layers supplies a practical route to efficient long-context reasoning.
Where Pith is reading between the lines
- The same layer-partition idea could be tested on non-reasoning long-context tasks to see whether token importance remains stable outside step-by-step derivations.
- Adjusting the fraction of layers assigned to the Δ-group might trade off selection quality against extra compute in a controllable way.
- Because the method is training-free, it can be applied immediately to any existing model whose attention maps are accessible.
Load-bearing premise
Attention scores computed once in the small set of Δ-layers remain accurate enough to mark which tokens stay important across the full length of a long reasoning derivation.
What would settle it
A clear accuracy drop versus full attention on a long-chain benchmark when the number or placement of Δ-layers is varied would show that token importance is not stable enough to be fixed after those layers.
Figures



read the original abstract
Large reasoning models (LRMs) achieve state-of-the-art performance on challenging benchmarks by generating long chains of intermediate steps, but their inference cost is dominated by decoding, where each new token must attend to the entire growing sequence. One approach to reduce this latency is to evict entries from the key-value (KV) cache, thereby reducing the active context used in attention computation. However, such sparse attention methods suffer from severe accuracy degradation on reasoning tasks due to cumulative selection errors and the evolving importance of tokens over long derivations. We present \textbf{DELTA}, a training-free sparse attention mechanism that improves computational efficiency without sacrificing model accuracy. DELTA partitions transformer layers into three groups: initial layers that use full attention, a small set of \emph{$\Delta$-layers} that identify salient tokens via aggregated head-level attention scores, and subsequent sparse-attention layers that attend only to the selected subset. This design preserves the full KV cache in GPU memory for accuracy, while avoiding expensive full-attention computation over many layers. On reasoning benchmarks such as AIME and GPQA-Diamond, DELTA matches or surpasses full attention in accuracy, while reducing the number of attended tokens by up to $4.25\times$ and delivering $1.54\times$ end-to-end speedup. Our results show that selective reuse of intermediate attention maps offers a robust path toward efficient long-context reasoning. The code is available at https://github.com/hoenza/DELTA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DELTA, a training-free sparse attention method for large reasoning models. It partitions transformer layers into initial full-attention layers, a small set of Δ-layers that compute aggregated head-level attention scores to select salient tokens, and subsequent sparse-attention layers that attend only to the selected subset while keeping the full KV cache in memory. On AIME and GPQA-Diamond, DELTA is reported to match or exceed full-attention accuracy while reducing attended tokens by up to 4.25× and achieving 1.54× end-to-end speedup.
Significance. If the empirical results hold, the work provides a practical, training-free route to faster inference on long reasoning traces without accuracy degradation. The open-source code and explicit algorithmic procedure (layer grouping plus score aggregation) are strengths that support reproducibility and allow direct testing of the efficiency-accuracy tradeoff.
major comments (2)
- [§3] §3 (method overview): The accuracy claim rests on the assumption that the token subset selected via aggregated attention scores in the Δ-layers remains sufficient for all later sparse-attention layers. In multi-step reasoning, token relevance can shift as new intermediate results appear; the manuscript does not provide an ablation or analysis quantifying how often such shifts occur or whether cumulative selection errors remain negligible across long derivations.
- [§4.2] §4.2 (experimental results): The reported matching or superior accuracy on AIME and GPQA-Diamond supports the central claim, yet the paper would benefit from explicit tests varying the number and placement of Δ-layers to confirm that the selection mechanism is robust rather than tuned to the evaluated benchmarks.
minor comments (2)
- [Method] The aggregation formula for head-level attention scores in the Δ-layers should be stated as an explicit equation to facilitate exact reproduction.
- [Abstract] Figure captions and the abstract could more clearly distinguish between reduction in attended tokens and end-to-end wall-clock speedup.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the work's significance, and recommendation for minor revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (method overview): The accuracy claim rests on the assumption that the token subset selected via aggregated attention scores in the Δ-layers remains sufficient for all later sparse-attention layers. In multi-step reasoning, token relevance can shift as new intermediate results appear; the manuscript does not provide an ablation or analysis quantifying how often such shifts occur or whether cumulative selection errors remain negligible across long derivations.
Authors: We appreciate the referee pointing out the potential issue of shifting token relevance in multi-step reasoning. The DELTA design uses the initial full-attention layers to process the early context and the Δ-layers to select salient tokens based on aggregated attention scores from those layers. Subsequent sparse layers then operate on this fixed selection while keeping the complete KV cache in memory to preserve accuracy. The fact that accuracy is maintained or improved on benchmarks with long reasoning chains provides evidence that selection errors do not significantly impact performance. However, we agree that an explicit analysis would be valuable, and we will add an ablation study in the revised manuscript that examines how token selections evolve (or remain stable) across the course of long derivations and quantifies any cumulative effects. revision: yes
-
Referee: [§4.2] §4.2 (experimental results): The reported matching or superior accuracy on AIME and GPQA-Diamond supports the central claim, yet the paper would benefit from explicit tests varying the number and placement of Δ-layers to confirm that the selection mechanism is robust rather than tuned to the evaluated benchmarks.
Authors: We concur that additional experiments varying the number and placement of the Δ-layers would help establish the robustness of the selection mechanism. Our current configuration was determined through initial explorations to optimize the efficiency-accuracy trade-off. In the revision, we will report results for alternative numbers and placements of Δ-layers to demonstrate that the observed benefits are not specific to the chosen setup on these benchmarks. revision: yes
Circularity Check
No significant circularity; method is self-contained algorithmic procedure evaluated on external benchmarks
full rationale
The paper defines DELTA as an explicit training-free procedure: partition layers into initial full-attention, a small Δ-layer group that computes aggregated head-level attention scores to select tokens, and subsequent sparse layers that reuse the fixed selection while preserving the full KV cache. Accuracy and speedup claims are measured directly against external reasoning benchmarks (AIME, GPQA-Diamond) rather than derived from any fitted parameter or self-referential equation. No load-bearing step reduces a reported result back to the method's own inputs by construction, and no self-citation chain is invoked to justify uniqueness or force the outcome. The central assumption about persistent token importance is a correctness risk, not a circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- number and placement of Δ-layers
Forward citations
Cited by 1 Pith paper
-
Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
The first survey on Attention Sink in Transformers structures the literature around fundamental utilization, mechanistic interpretation, and strategic mitigation.
Reference graph
Works this paper leans on
-
[1]
American invitational mathematics examination-aime 2024,
work page 2024
-
[2]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245. Iz Beltagy, Matthew E Peters, and Arman Cohan
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150. Zefan Cai, Wen Xiao, Hanshi Sun, Cheng Luo, Yikai Zhang, Ke Wan, Yucheng Li, Yeyang Zhou, Li- Wen Chang, Jiuxiang Gu, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever
R- kv: Redundancy-aware kv cache compression for training-free reasoning models acceleration.arXiv preprint arXiv:2505.24133. Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever
-
[5]
Generating long se- quences with sparse transformers.arXiv preprint arXiv:1904.10509. Tri Dao
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[6]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691. Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao
Seerattention-r: Sparse attention adaptation for long reasoning.arXiv preprint arXiv:2506.08889. Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao
-
[8]
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Model tells you what to discard: Adaptive kv cache compression for llms.arXiv preprint arXiv:2310.01801. Google DeepMind
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
https://blog.google/techno logy/google-deepmind/gemini-model-thinkin g-updates-march-2025/
Gemini 2.5: Our most intel- ligent ai model. https://blog.google/techno logy/google-deepmind/gemini-model-thinkin g-updates-march-2025/. Accessed: 2025-09-27. Albert Gu and Tri Dao
work page 2025
-
[10]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Jitai Hao, Yuke Zhu, Tian Wang, Jun Yu, Xin Xin, Bo Zheng, Zhaochun Ren, and Sheng Guo
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical prob- lem solving with the math dataset.arXiv preprint arXiv:2103.03874. Junhao Hu, Wenrui Huang, Weidong Wang, Zhenwen Li, Tiancheng Hu, Zhixia Liu, Xusheng Chen, Tao Xie, and Yizhou Shan
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Raas: Reasoning-aware attention sparsity for efficient llm reasoning.arXiv preprint arXiv:2502.11147. Hugging Face
-
[14]
Hugging face. https://huggin gface.co/. Accessed: 2025-09-27. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gon- zalez, Hao Zhang, and Ion Stoica
work page 2025
-
[15]
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Snapkv: Llm knows what you are looking for before gener- ation.Advances in Neural Information Processing Systems, 37:22947–22970. Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chen- gruidong Zhang, Bailu Ding, Kai Zhang, and 1 others. 2024a. Retrievalattention: Accelerating long-context llm inference via vector retriev...
work page internal anchor Pith review arXiv
-
[16]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Scis- sorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. Advances in Neural Information Processing Systems, 36:52342–52364. Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024b. Kivi: A tuning-free asymmet- ric 2bit quantization for kv cache....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Junyoung Park, Dalton Jones, Matthew J Morse, Raghavv Goel, Mingu Lee, and Chris Lott
Transformers are multi- state rnns.arXiv preprint arXiv:2401.06104. Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, and 1 others
-
[18]
RWKV: Reinventing RNNs for the Transformer Era
Rwkv: Reinventing rnns for the trans- former era.arXiv preprint arXiv:2305.13048. David Rein, Betty Li Hou, Asa Cooper Stickland, Jack- son Petty, Richard Yuanzhe Pang, Julien Dirani, Ju- lian Michael, and Samuel R Bowman
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Fast Transformer Decoding: One Write-Head is All You Need
Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150. Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[20]
Retentive Network: A Successor to Transformer for Large Language Models
Retentive network: A successor to trans- former for large language models.arXiv preprint arXiv:2307.08621. Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Quest: Query- aware sparsity for efficient long-context llm inference. arXiv preprint arXiv:2406.10774. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Efficient Streaming Language Models with Attention Sinks
Chain-of-thought prompting elic- its reasoning in large language models.Advances in neural information processing systems, 35:24824– 24837. Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023a. Smoothquant: Accurate and efficient post-training quantization for large language models. InInterna- tional conference on machine le...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Lijie Yang, Zhihao Zhang, Zhuofu Chen, Zikun Li, and Zhihao Jia
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
arXiv preprint arXiv:2410.05076
Tidaldecode: Fast and accurate llm decoding with position persistent sparse attention. arXiv preprint arXiv:2410.05076. Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He
-
[25]
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Flashinfer: Efficient and customiz- able attention engine for llm inference serving.arXiv preprint arXiv:2501.01005. Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, YX Wei, Lean Wang, Zhiping Xiao, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
Na- tive sparse attention: Hardware-aligned and na- tively trainable sparse attention.arXiv preprint arXiv:2502.11089. Linan Yue, Yichao Du, Yizhi Wang, Weibo Gao, Fangzhou Yao, Li Wang, Ye Liu, Ziyu Xu, Qi Liu, Shimin Di, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2508.02120
Don’t overthink it: A survey of efficient r1-style large reasoning models. arXiv preprint arXiv:2508.02120. Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago On- tanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and 1 others
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.