REACT3D: Recovering Articulations for Interactive Physical 3D Scenes
Pith reviewed 2026-05-18 07:12 UTC · model grok-4.3
The pith
REACT3D converts static 3D scenes into interactive simulation models by automatically recovering articulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
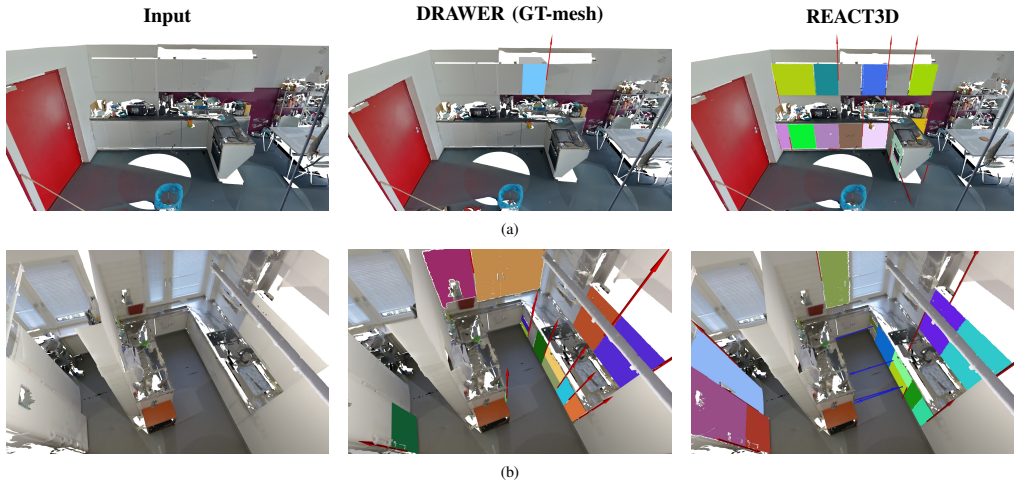
REACT3D recovers articulations from static 3D scenes through openable-object detection and segmentation, articulation estimation of joint types and motion parameters, hidden-geometry completion followed by interactive object assembly, and output integration in widely supported simulation formats, yielding consistent interactive replicas that require no scene-specific fine-tuning.
What carries the argument
The four-stage pipeline of openable-object detection and segmentation, articulation estimation, hidden-geometry completion with assembly, and export to standard simulation formats.
If this is right
- Static scene datasets become directly usable for interactive tasks without manual part segmentation or kinematic annotation.
- State-of-the-art results on detection, segmentation, and articulation metrics across diverse indoor scenes.
- Compatibility with standard simulation platforms is achieved through output in supported formats.
- The approach supplies a practical route to larger-scale articulated scene understanding for embodied intelligence research.
Where Pith is reading between the lines
- The same detection-plus-estimation steps could be chained with real-time 3D scanning pipelines to turn physical rooms into simulatable models on the fly.
- If the underlying openable-object detectors improve, the framework might extend to outdoor or industrial scenes without retraining.
- Large repositories of static 3D scans could be retroactively turned into interactive training environments for robotics and navigation agents.
Load-bearing premise
Off-the-shelf detectors and articulation estimators trained on other data will generalize reliably to the diverse indoor scenes seen at test time.
What would settle it
Running the pipeline on a held-out collection of varied indoor scenes and finding that the detected parts or estimated joints produce geometrically inconsistent or non-functional simulations in a standard physics engine.
Figures






read the original abstract
Interactive 3D scenes are increasingly vital for embodied intelligence, yet existing datasets remain limited due to the labor-intensive process of annotating part segmentation, kinematic types, and motion trajectories. We present REACT3D, a scalable zero-shot framework that converts static 3D scenes into simulation-ready interactive replicas with consistent geometry, enabling direct use in diverse downstream tasks. Our contributions include: (i) openable-object detection and segmentation to extract candidate movable parts from static scenes, (ii) articulation estimation that infers joint types and motion parameters, (iii) hidden-geometry completion followed by interactive object assembly, and (iv) interactive scene integration in widely supported formats to ensure compatibility with standard simulation platforms. We achieve state-of-the-art performance on detection/segmentation and articulation metrics across diverse indoor scenes, demonstrating the effectiveness of our framework and providing a practical foundation for scalable interactive scene generation, thereby lowering the barrier to large-scale research on articulated scene understanding. Our project page is https://react3d.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REACT3D, a scalable zero-shot framework that converts static 3D scenes into simulation-ready interactive replicas. The pipeline includes openable-object detection and segmentation to extract movable parts, articulation estimation to infer joint types and motion parameters, hidden-geometry completion followed by interactive object assembly, and integration into widely supported simulation formats. It reports state-of-the-art results on detection/segmentation and articulation metrics across diverse indoor scenes, with the goal of lowering barriers to large-scale articulated scene understanding and embodied AI research.
Significance. If the zero-shot components generalize reliably, the work would meaningfully advance the field by automating creation of physically consistent interactive 3D environments from static scans, reducing reliance on labor-intensive manual annotation, and providing directly usable assets for simulation platforms. The emphasis on end-to-end compatibility and consistent geometry is a practical contribution.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): The reported state-of-the-art numbers on detection/segmentation and articulation metrics provide no quantitative details on error bars, failure cases, or sensitivity to post-processing choices; this directly weakens the central scalability claim for zero-shot conversion of diverse indoor scenes.
- [§3.2] §3.2 (Articulation Estimation): The framework relies on off-the-shelf pre-trained models for joint-type inference and motion-parameter estimation without scene-specific fine-tuning or explicit propagation analysis; if segmentation or axis errors occur under distribution shift (occlusions, novel hinges), the resulting kinematics become invalid for downstream simulation, yet no targeted stress tests on this failure mode are shown.
minor comments (2)
- [Figure 3 and §3.3] Figure 3 and §3.3: The hidden-geometry completion step would be clearer with an additional diagram showing before/after geometry on a representative object with partial observations.
- [§3.1] Notation in §3.1: Define the joint-parameter vector (e.g., axis direction and angle range) explicitly with a small table to avoid ambiguity when readers compare against prior articulation estimators.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and indicate the changes planned for the revised version.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): The reported state-of-the-art numbers on detection/segmentation and articulation metrics provide no quantitative details on error bars, failure cases, or sensitivity to post-processing choices; this directly weakens the central scalability claim for zero-shot conversion of diverse indoor scenes.
Authors: We agree that the current results presentation would benefit from additional quantitative details to more robustly support the scalability claims. In the revised manuscript we will add error bars (standard deviations across scenes) to the reported metrics in Section 4, include a concise analysis of observed failure cases, and report sensitivity results for the main post-processing parameters via targeted ablations. These updates will be incorporated into the next version. revision: yes
-
Referee: [§3.2] §3.2 (Articulation Estimation): The framework relies on off-the-shelf pre-trained models for joint-type inference and motion-parameter estimation without scene-specific fine-tuning or explicit propagation analysis; if segmentation or axis errors occur under distribution shift (occlusions, novel hinges), the resulting kinematics become invalid for downstream simulation, yet no targeted stress tests on this failure mode are shown.
Authors: The zero-shot design intentionally uses off-the-shelf models to enable broad applicability without per-scene fine-tuning. We recognize the value of explicit error-propagation analysis. In the revision we will expand Section 3.2 with a discussion of how upstream errors affect final kinematics and add targeted experiments in Section 4 that evaluate performance under occlusions and novel joint types. These additions will illustrate robustness and limitations while preserving the zero-shot nature of the method. revision: yes
Circularity Check
Forward perception pipeline with no self-referential derivations or fitted predictions
full rationale
The REACT3D paper describes a modular pipeline that chains off-the-shelf openable-object detectors, part segmentation, joint-type inference, motion-parameter estimation, hidden-geometry completion, and scene assembly. No equations or first-principles derivations are presented whose outputs reduce by construction to quantities fitted on the same test scenes. Reported SOTA metrics on detection/segmentation and articulation are external benchmarks evaluated after the zero-shot pipeline runs; they are not tautologically recovered from the pipeline's own fitted parameters. Self-citations, if present for component models, are not load-bearing for the central claim of scalable interactive replica generation. The work therefore remains self-contained against external benchmarks with only minor circularity risk from reliance on pre-trained modules.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Off-the-shelf detectors and articulation estimators generalize to unseen indoor scenes without retraining.
Forward citations
Cited by 1 Pith paper
-
FunRec: Reconstructing Functional 3D Scenes from Egocentric Interaction Videos
FunRec reconstructs interactable 3D scenes with articulated parts from in-the-wild egocentric interaction videos, automatically discovering parts, estimating kinematics, and producing simulation-compatible meshes with...
Reference graph
Works this paper leans on
-
[1]
Habitat 3.0: A co-habitat for humans, avatars, and robots,
X. Puig, E. Undersander, A. Szot, M. D. Cote, T.-Y . Yang, R. Partsey, R. Desai, A. Clegg, M. Hlavac, S. Y . Min, V . V ondru ˇs, T. Gervet, V .-P. Berges, J. M. Turner, O. Maksymets, Z. Kira, M. Kalakrishnan, J. Malik, D. S. Chaplot, U. Jain, D. Batra, A. Rai, and R. Mottaghi, “Habitat 3.0: A co-habitat for humans, avatars, and robots,” inICLR, 2024
work page 2024
-
[2]
Scannet++: A high-fidelity dataset of 3d indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “Scannet++: A high-fidelity dataset of 3d indoor scenes,” inICCV, 2023, pp. 12–22
work page 2023
-
[3]
Echoscene: Indoor scene generation via information echo over scene graph diffusion,
G. Zhai, E. P. ¨Ornek, D. Z. Chen, R. Liao, Y . Di, N. Navab, F. Tombari, and B. Busam, “Echoscene: Indoor scene generation via information echo over scene graph diffusion,” inECCV. Springer, 2024, pp. 167–184
work page 2024
-
[4]
Drawer: Digital reconstruction and articulation with environment realism,
H. Xia, E. Su, M. Memmel, A. Jain, R. Yu, N. Mbiziwo-Tiapo, A. Farhadi, A. Gupta, S. Wang, and W.-C. Ma, “Drawer: Digital reconstruction and articulation with environment realism,” inCVPR, 06 2025, pp. 21 771–21 782
work page 2025
-
[5]
Mobility-trees for indoor scenes manipulation,
A. Sharf, H. Huang, C. Liang, J. Zhang, B. Chen, and M. Gong, “Mobility-trees for indoor scenes manipulation,”Comput. Graph. Forum, vol. 33, no. 1, p. 2–14, Feb. 2014
work page 2014
-
[6]
Opd: Single-view 3d openable part detection,
H. Jiang, Y . Mao, M. Savva, and A. X. Chang, “Opd: Single-view 3d openable part detection,” inECCV, 2022
work page 2022
-
[7]
Multiscan: Scalable rgbd scanning for 3d environments with articulated objects,
Y . Mao, Y . Zhang, H. Jiang, A. X. Chang, and M. Savva, “Multiscan: Scalable rgbd scanning for 3d environments with articulated objects,” inNeurIPS, 2022
work page 2022
-
[8]
Opdmulti: Openable part detection for multiple objects,
X. Sun, H. Jiang, M. Savva, and A. Chang, “Opdmulti: Openable part detection for multiple objects,” in2024 International Conference on 3D Vision (3DV), 2024, pp. 169–178
work page 2024
-
[9]
Understanding 3d object interaction from a single image,
S. Qian and D. F. Fouhey, “Understanding 3d object interaction from a single image,” inICCV, 2023
work page 2023
-
[10]
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask r-cnn,” inICCV, 2017, pp. 2980–2988
work page 2017
-
[11]
SceneFun3D: Fine-Grained Functionality and Affor- dance Understanding in 3D Scenes,
A. Delitzas, A. Takmaz, F. Tombari, R. Sumner, M. Pollefeys, and F. Engelmann, “SceneFun3D: Fine-Grained Functionality and Affor- dance Understanding in 3D Scenes,” inCVPR, 2024
work page 2024
-
[12]
Holistic understanding of 3d scenes as universal scene description,
A.-M. Halacheva, Y . Miao, J.-N. Zaech, X. Wang, L. V . Gool, and D. P. Paudel, “Holistic understanding of 3d scenes as universal scene description,” inICCV, 2025
work page 2025
-
[13]
Ditto: Building digital twins of articulated objects from interaction,
Z. Jiang, C.-C. Hsu, and Y . Zhu, “Ditto: Building digital twins of articulated objects from interaction,” inCVPR, 2022
work page 2022
-
[14]
PARIS: Part-level recon- struction and motion analysis for articulated objects,
J. Liu, A. Mahdavi-Amiri, and M. Savva, “PARIS: Part-level recon- struction and motion analysis for articulated objects,” inICCV, 2023
work page 2023
-
[15]
Neural implicit representation for building digital twins of unknown articulated objects,
Y . Weng, B. Wen, J. Tremblay, V . Blukis, D. Fox, L. Guibas, and S. Birchfield, “Neural implicit representation for building digital twins of unknown articulated objects,” inCVPR, 2024
work page 2024
-
[16]
Building inter- actable replicas of complex articulated objects via gaussian splatting,
Y . Liu, B. Jia, R. Lu, J. Ni, S.-C. Zhu, and S. Huang, “Building inter- actable replicas of complex articulated objects via gaussian splatting,” inICLR, 2025
work page 2025
-
[17]
Real2code: Reconstruct articulated objects via code generation,
Z. Mandi, Y . Weng, D. Bauer, and S. Song, “Real2code: Reconstruct articulated objects via code generation,” inICLR, 2025
work page 2025
-
[18]
L. Le, J. Xie, W. Liang, H.-J. Wang, Y . Yang, Y . J. Ma, K. Vedder, A. Krishna, D. Jayaraman, and E. Eaton, “Articulate-anything: Auto- matic modeling of articulated objects via a vision-language foundation model,” inICLR, 2024
work page 2024
-
[19]
Automated creation of digital cousins for robust policy learning,
T. Dai, J. Wong, Y . Jiang, C. Wang, C. Gokmen, R. Zhang, J. Wu, and L. Fei-Fei, “Automated creation of digital cousins for robust policy learning,” inConference on Robot Learning (CoRL), 2024
work page 2024
-
[20]
Urdformer: A pipeline for constructing articulated simulation environments from real-world images,
Q. Chen, A. Walsman, M. Memmel, K. Mo, A. Fang, D. Fox, and A. Gupta, “Urdformer: A pipeline for constructing articulated simulation environments from real-world images,” inProceedings of Robotics: Science and Systems (RSS), 07 2024
work page 2024
-
[21]
Category-level articulated object pose estimation,
X. Li, H. Wang, L. Yi, L. Guibas, A. L. Abbott, and S. Song, “Category-level articulated object pose estimation,”CVPR, 2020
work page 2020
-
[22]
Recognize anything: A strong image tagging model,
Y . Zhang, X. Huang, J. Ma, Z. Li, Z. Luo, Y . Xie, Y . Qin, T. Luo, Y . Li, S. Liu, Y . Guo, and L. Zhang, “Recognize anything: A strong image tagging model,” inCVPRW, 2024, pp. 1724–1732
work page 2024
-
[23]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” in NeurIPS, 2023
work page 2023
-
[24]
Grounded sam: Assembling open-world models for diverse visual tasks,
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yan, Z. Zeng, H. Zhang, F. Li, J. Yang, H. Li, Q. Jiang, and L. Zhang, “Grounded sam: Assembling open-world models for diverse visual tasks,” 2024
work page 2024
-
[25]
Mask3D: Mask Transformer for 3D Semantic Instance Segmen- tation,
J. Schult, F. Engelmann, A. Hermans, O. Litany, S. Tang, and B. Leibe, “Mask3D: Mask Transformer for 3D Semantic Instance Segmen- tation,” inInternational Conference on Robotics and Automation (ICRA), 2023
work page 2023
-
[26]
An improvement on the louvain algorithm using random walks,
D. Do and T. H. D. Phan, “An improvement on the louvain algorithm using random walks,”Journal of Combinatorial Optimization, 2025
work page 2025
-
[27]
M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,”Commun. ACM, June 1981
work page 1981
-
[28]
COMPAS: A framework for computational research in architecture and structures
T. V . Meleet al., “COMPAS: A framework for computational research in architecture and structures.” 2017-2019. [Online]. Available: https://doi.org/10.5281/zenodo.2594510
-
[29]
D. Ebert, “Instanttexture,” https://github.com/dylanebert/ InstantTexture, 2024, accessed: 2025-09-10
work page 2024
-
[30]
M. Worchel and M. Dawson-Haggerty, “xatlas,” https://github.com/ mworchel/xatlas-python, accessed: 2025-09-10
work page 2025
-
[31]
Pybullet, a python module for physics sim- ulation for games, robotics and machine learning,
E. Coumans and Y . Bai, “Pybullet, a python module for physics sim- ulation for games, robotics and machine learning,” http://pybullet.org, 2016–2021
work page 2016
-
[32]
Ros: an open-source robot operating system,
M. Quigley, K. Conley, B. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, A. Y . Ng,et al., “Ros: an open-source robot operating system,” inICRA workshop on open source software, 2009
work page 2009
- [33]
-
[34]
Open3D: A Modern Library for 3D Data Processing
Q.-Y . Zhou, J. Park, and V . Koltun, “Open3D: A modern library for 3D data processing,”arXiv:1801.09847, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.