ActivationReasoning: Logical Reasoning in Latent Activation Spaces
Pith reviewed 2026-05-18 05:40 UTC · model grok-4.3
The pith
ActivationReasoning embeds logical rules into the latent activations of language models to enable structured reasoning and control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
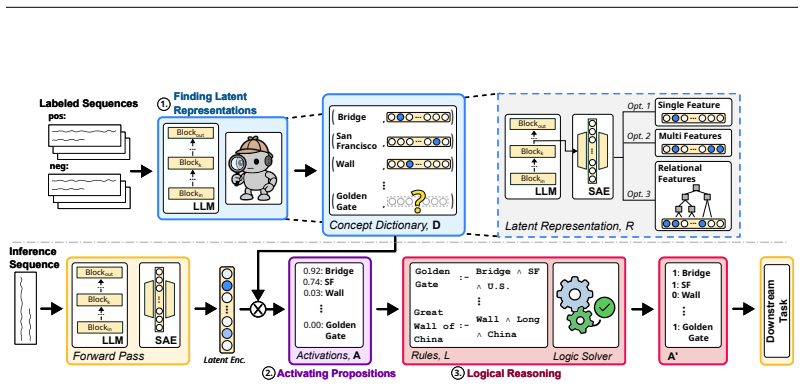
ActivationReasoning proceeds in three stages: first latent concept representations are identified via sparse autoencoders and organized into a dictionary; at inference time activating concepts are detected and mapped to logical propositions; logical rules are then applied over these propositions to infer higher-order structures, compose new concepts, and steer model behavior. Experiments on multi-hop reasoning, abstraction under indirect cues, diverse-language proof tasks, and context-sensitive safety show that the method scales with complexity, generalizes beyond training distributions, and transfers across model backbones.
What carries the argument
The three-stage ActivationReasoning process that converts sparse-autoencoder latent features into logical propositions and runs rule-based inference over them to control outputs.
If this is right
- The method scales robustly as reasoning depth increases.
- It generalizes to abstract concepts and context-sensitive safety constraints.
- Performance transfers across different LLM backbones.
- Grounding logic in activations improves transparency while supporting reliable control and alignment.
Where Pith is reading between the lines
- This approach could be combined with editing techniques to adjust individual logical steps inside the model rather than relying only on prompts.
- It opens a route to inspect and verify reasoning chains at the level of specific latent propositions.
- If the mapping remains stable under distribution shift, the framework might reduce the need for separate alignment fine-tuning on safety data.
Load-bearing premise
Latent features from sparse autoencoders can be mapped to logical propositions reliably and without distorting their meaning so that downstream rules produce valid inferences.
What would settle it
A test case in which the logical rules applied to the mapped propositions yield an output the base model does not produce or that human judges rate as incorrect for the given input.
Figures

read the original abstract
Large language models (LLMs) excel at generating fluent text, but their internal reasoning remains opaque and difficult to control. Sparse autoencoders (SAEs) make hidden activations more interpretable by exposing latent features that often align with human concepts. Yet, these features are fragile and passive, offering no mechanism for systematic reasoning or model control. To address this, we introduce ActivationReasoning (AR), a framework that embeds explicit logical reasoning into the latent space of LLMs. It proceeds in three stages: (1) Finding latent representations, first latent concept representations are identified (e.g., via SAEs) and organized into a dictionary; (2) Activating propositions, at inference time AR detects activating concepts and maps them to logical propositions; and (3)Logical reasoning, applying logical rules over these propositions to infer higher-order structures, compose new concepts, and steer model behavior. We evaluate AR on multi-hop reasoning (PrOntoQA), abstraction and robustness to indirect concept cues (Rail2Country), reasoning over natural and diverse language (ProverQA), and context-sensitive safety (BeaverTails). Across all tasks, AR scales robustly with reasoning complexity, generalizes to abstract and context-sensitive tasks, and transfers across model backbones. These results demonstrate that grounding logical structure in latent activations not only improves transparency but also enables structured reasoning, reliable control, and alignment with desired behaviors, providing a path toward more reliable and auditable AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ActivationReasoning (AR), a three-stage framework for embedding explicit logical reasoning into LLM latent activation spaces. Stage 1 identifies and dictionaries latent concept representations (e.g., via SAEs). Stage 2 detects activating concepts at inference and maps them to logical propositions. Stage 3 applies logical rules over these propositions to perform inference, compose concepts, and steer model outputs. Evaluations across PrOntoQA (multi-hop reasoning), Rail2Country (abstraction and robustness to indirect cues), ProverQA (natural-language reasoning), and BeaverTails (context-sensitive safety) claim robust scaling with reasoning complexity, generalization to abstract and context-sensitive tasks, and transfer across model backbones, thereby improving transparency, structured reasoning, control, and alignment.
Significance. If the central claims hold, the work would be a meaningful contribution to LLM interpretability and controllable reasoning. It attempts to move beyond passive SAE feature discovery by adding an explicit logical layer for inference and steering, with a multi-task evaluation that includes safety considerations. Credit is due for the breadth of tasks and the explicit attempt to combine interpretability techniques with formal logical operations, which could support more auditable AI if the mapping and inference steps prove reliable.
major comments (2)
- [§3.2] §3.2 (Stage 2 description): the mapping from detected latent activations to logical propositions is presented without a formal definition, consistency metric, or error bound on proposition fidelity. This assumption is load-bearing for all downstream claims, because if the mapping is approximate, many-to-one, or context-dependent, then the logical inferences in multi-hop reasoning (PrOntoQA) and safety steering (BeaverTails) lose soundness even when latents are correctly detected.
- [Evaluation sections] Evaluation sections (corresponding to the four tasks): the manuscript reports that AR 'scales robustly' and 'generalizes' but supplies no quantitative tables, error bars, baseline comparisons, or ablation on the proposition-mapping step. Without these, the support for the central claim that grounding logical structure in latents improves transparency and control cannot be verified.
minor comments (2)
- [Abstract] Abstract: the claim of 'robust scaling with reasoning complexity' would be clearer if accompanied by at least one key performance number or scaling curve reference.
- [§3] Notation: the distinction between 'latent concept representations' and 'activating concepts' is introduced without an explicit symbol or equation; a small notational table would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our framework. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Stage 2 description): the mapping from detected latent activations to logical propositions is presented without a formal definition, consistency metric, or error bound on proposition fidelity. This assumption is load-bearing for all downstream claims, because if the mapping is approximate, many-to-one, or context-dependent, then the logical inferences in multi-hop reasoning (PrOntoQA) and safety steering (BeaverTails) lose soundness even when latents are correctly detected.
Authors: We agree that a more rigorous formalization of the mapping in Stage 2 is necessary to support the soundness of the logical inferences. In the revised manuscript, we will introduce a formal definition of the mapping function M: A -> P, where A is the set of activating latents and P the propositions, along with a consistency metric computed as the agreement rate between multiple independent mappings on a validation set. We will also report empirical error bounds from experiments measuring proposition fidelity against human annotations. This addresses the load-bearing nature of the assumption and bolsters the claims for multi-hop and safety tasks. revision: yes
-
Referee: [Evaluation sections] Evaluation sections (corresponding to the four tasks): the manuscript reports that AR 'scales robustly' and 'generalizes' but supplies no quantitative tables, error bars, baseline comparisons, or ablation on the proposition-mapping step. Without these, the support for the central claim that grounding logical structure in latents improves transparency and control cannot be verified.
Authors: The manuscript does contain quantitative evaluations in the respective sections, including performance metrics on PrOntoQA, Rail2Country, ProverQA, and BeaverTails, with comparisons to baselines like vanilla LLMs and SAE-only steering. However, we acknowledge that error bars, detailed statistical analysis, and a specific ablation on the proposition-mapping step could be more prominently featured. In the revision, we will add error bars from 5 runs, include a new table for the ablation study removing the logical reasoning component, and provide baseline comparisons in a consolidated table. This will make the evidence for improved transparency and control more verifiable. revision: partial
Circularity Check
No circularity: empirical framework evaluated on external benchmarks
full rationale
The paper introduces ActivationReasoning as a three-stage pipeline (latent discovery via SAEs, proposition mapping, logical rule application) and reports performance on independent benchmarks including PrOntoQA, Rail2Country, ProverQA, and BeaverTails. No equations, fitted parameters, or predictions are defined in terms of the target outputs; the central claims rest on empirical generalization across tasks and model backbones rather than any self-referential reduction or self-citation chain that would force the results by construction. The mapping assumption is stated as a methodological choice but is not used to derive the reported gains tautologically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse autoencoder features align sufficiently with logical propositions to support valid inference.
Reference graph
Works this paper leans on
-
[1]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2205.09712 , year=
Antonia Creswell, Murray Shanahan, and Irina Higgins. Selection-inference: Exploiting large language models for interpretable logical reasoning.arXiv preprint arXiv:2205.09712,
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Quentin Delfosse, Jannis Blüml, Fabian Tatai, Théo Vincent, Bjarne Gregori, Elisabeth Dillies, Jan Peters, Constantin A. Rothkopf, and Kristian Kersting. Deep reinforcement learning agents are not even close to human intelligence.arXiv preprint arXiv:2505.21731,
-
[5]
Artificial Intelligence, Values and Alignment
Iason Gabriel. Artificial intelligence, values and alignment.arXiv preprint arXiv:2001.09768,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[6]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Measuring and guiding monosemanticity.arXiv preprint arXiv:2506.19382,
Ruben Härle, Felix Friedrich, Manuel Brack, Stephan Wäldchen, Björn Deiseroth, Patrick Schramowski, and Kristian Kersting. Measuring and guiding monosemanticity.arXiv preprint arXiv:2506.19382,
-
[8]
SLR: Automated Synthesis for Scalable Logical Reasoning
Lukas Helff, Ahmad Omar, Felix Friedrich, Antonia Wüst, Hikaru Shindo, Rupert Mitchell, Tim Woydt, Patrick Schramowski, Wolfgang Stammer, and Kristian Kersting. Slr: Automated synthesis for scalable logical reasoning.arXiv preprint arXiv:2506.15787,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset.arXiv preprint arXiv:2307.04657,
-
[10]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2.arXiv preprint arXiv:2408.05147,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2002.06177 , year=
Gary Marcus. The next decade in ai: four steps towards robust artificial intelligence.arXiv preprint arXiv:2002.06177,
-
[12]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models.arXiv preprint arXiv:2311.03658,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Kleinberg, Emma Pierson, and Nikhil Garg
Kenny Peng, Rajiv Movva, Jon M. Kleinberg, Emma Pierson, and Nikhil Garg. Use sparse autoencoders to discover unknown concepts, not to act on known concepts.arXiv preprint arXiv:2506.23845,
-
[14]
Abulhair Saparov, Richard Yuanzhe Pang, Vishakh Padmakumar, Nitish Joshi, Seyed Mehran Kazemi, Najoung Kim, and He He. Testing the general deductive reasoning capacity of large language models using OOD examples.arXiv preprint arXiv:2305.15269,
-
[15]
Stewart Shapiro and Teresa Kouri Kissel. Classical Logic. In Edward N. Zalta and Uri Nodelman (eds.),The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, Spring 2024 edition,
work page 2024
-
[16]
13 Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity.arXiv preprint arXiv:2506.06941,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Arseny Skryagin, Wolfgang Stammer, Daniel Ochs, Devendra Singh Dhami, and Kristian Kersting. Slash: embracing probabilistic circuits into neural answer set programming.arXiv preprint arXiv:2110.03395,
-
[18]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Rothkopf, and Kristian Kersting
Tim Woydt, Moritz Willig, Antonia Wüst, Lukas Helff, Wolfgang Stammer, Constantin A. Rothkopf, and Kristian Kersting. Fodor and pylyshyn’s legacy - still no human-like systematic compositional- ity in neural networks.arXiv preprint arXiv:2506.01820,
-
[20]
Y.; Li, B.; Ghazi, B.; and Kumar, R
Chulin Xie, Yangsibo Huang, Chiyuan Zhang, Da Yu, Xinyun Chen, Bill Yuchen Lin, Bo Li, Badih Ghazi, and Ravi Kumar. On memorization of large language models in logical reasoning.arXiv preprint arXiv:2410.23123,
-
[21]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
14 Supplementary Materials A EXPERIMENTALSETUP Models.For our experiments, AR is evaluated on two backbone models: Llama-3.1-8B AI@Meta (2024) with the EleutherAI sae-llama-3.1-8b-64x EleutherAI (2024) (width 262k) attached at layer 23 1, and Gemma-2-9B Team (2024) with the gemma-scope-9b-pt-res-canonical SAE Lieberum et al. (2024) (width
work page 2024
-
[23]
All experiments are conducted with greedy decoding. A.1 PRONTOQA EXPERIMENTALSETUP For the PrOntoQA experiments, we instantiate AR with multi-feature concept representations Rmulti. Unless otherwise noted, activations are aggregated using the mean operator and steering follows the mean-shift update rule. Llama.For the Llama experiments, concepts were retr...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.