SLR: Automated Synthesis for Scalable Logical Reasoning
Pith reviewed 2026-05-19 08:43 UTC · model grok-4.3
The pith
SLR automatically synthesizes logical reasoning tasks with built-in validation programs to enable scalable curriculum training for LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
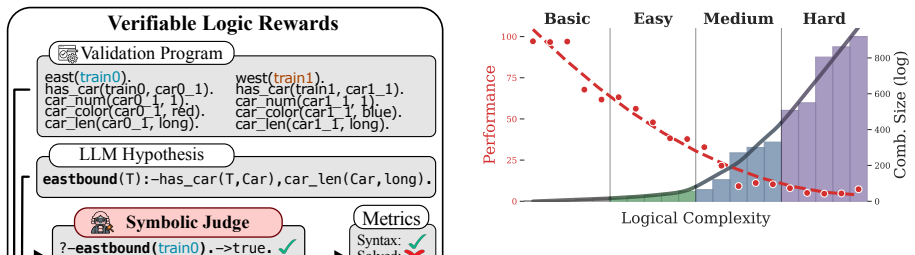
SLR is an end-to-end automated framework that, given a user's task specification, produces an instruction prompt for an inductive reasoning task, a validation program that scores model outputs against a latent ground-truth rule, and the rule itself. The framework requires no human annotations and supplies precise control over difficulty. Using it, the authors build SLR-Bench with 19k prompts in 20 curriculum stages. Curriculum learning on SLR data doubles Llama-3-8B accuracy on the benchmark to match Gemini-Flash-Thinking at a fraction of the cost, and the resulting capabilities transfer to a broad set of standard reasoning benchmarks.
What carries the argument
SLR synthesis engine that generates a prompt, an executable validator, and a latent ground-truth rule from a task specification to supply verifiable reward signals for logical reasoning training.
If this is right
- Models can be trained on progressively harder reasoning problems without any manual data labeling.
- Smaller models reach performance parity with high-compute reasoning models at substantially reduced inference cost.
- Reasoning improvements from the curriculum transfer to multiple established benchmarks beyond SLR-Bench.
- Current LLMs can output syntactically correct rules yet still fail logical inference, and this gap can be measured at scale.
- Test-time reasoning costs exceeding hundreds of dollars per thousand prompts can be replaced by cheaper training.
Where Pith is reading between the lines
- The same synthesis approach could be applied to generate training data for mathematical proof construction or code verification tasks.
- If validators remain reliable at higher complexity, the method could support iterative self-improvement loops in which models generate and validate their own next training tasks.
- The twenty curriculum levels may expose precise failure modes, such as breakdowns at particular recursion depths or arithmetic relations, that current models share.
- Generalization to other benchmarks suggests the learned reasoning routines are not narrowly tied to the synthesized task format.
Load-bearing premise
The automatically created validation programs must correctly identify whether a model's output rule matches the hidden ground-truth rule on every example without introducing false positives or negatives that corrupt the training signal.
What would settle it
Run the same curriculum training on Llama-3-8B but replace SLR validators with random or noisy scoring; if accuracy gains disappear or fail to generalize to other benchmarks, the claim that verifiable synthesis drives the improvement is false.
Figures




read the original abstract
We introduce SLR, an end-to-end framework for systematic evaluation and training of Large Language Models (LLMs) via Scalable Logical Reasoning. Given a user's task specification, SLR automatically synthesizes (i) an instruction prompt for an inductive reasoning task, (ii) a validation program, executable on model outputs to provide verifiable rewards, and (iii) the latent ground-truth rule. This process is fully automated, scalable, requires no human annotations, and offers precise control over task difficulty. Using SLR, we create SLR-Bench, a benchmark comprising 19k prompts organized into 20 curriculum levels that progressively increase in relational, arithmetic, and recursive complexity. Large-scale evaluation reveals that contemporary LLMs readily produce syntactically valid rules, yet often fail at correct logical inference. Recent reasoning LLMs demonstrate improved performance but incur very high test-time computation, with costs exceeding $300 for just 1,000 prompts. Finally, curriculum learning via SLR doubles Llama-3-8B accuracy on SLR-Bench, achieving parity with Gemini-Flash-Thinking at a fraction of computational cost. Moreover, these reasoning capabilities generalize to a wide range of established benchmarks, underscoring the effectiveness of SLR for downstream reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SLR, an automated end-to-end framework that, given a task specification, synthesizes an instruction prompt for an inductive reasoning task, an executable validation program to provide verifiable rewards, and the latent ground-truth rule. Using this, the authors construct SLR-Bench comprising 19k prompts across 20 curriculum levels of progressively increasing relational, arithmetic, and recursive complexity. Large-scale evaluations show that current LLMs produce syntactically valid but often logically incorrect rules, that reasoning models incur high test-time costs, and that curriculum learning with SLR doubles Llama-3-8B accuracy on SLR-Bench to reach parity with Gemini-Flash-Thinking at lower cost while generalizing to other established benchmarks.
Significance. If the synthesized validation programs are reliable, the work offers a scalable, annotation-free pipeline for both benchmarking and training logical reasoning in LLMs. This could substantially reduce reliance on expensive test-time compute while improving reasoning performance, with the reported generalization suggesting utility beyond the new benchmark.
major comments (2)
- [Abstract and experimental results] Abstract and experimental results: The central claim that curriculum learning doubles Llama-3-8B accuracy on SLR-Bench (and reaches parity with Gemini-Flash-Thinking) depends on the auto-generated validation programs supplying a faithful binary reward signal that passes only when the model's output rule exactly matches the latent ground-truth rule. No sample audit, formal verification, error bounds, or comparison against human-written oracles is reported to quantify false-positive or false-negative rates in the checkers. Any systematic bias in these programs would distort the reward signal and artifactually inflate the curriculum gains.
- [SLR-Bench construction] SLR-Bench construction: The abstract states that SLR offers precise control over task difficulty and organizes prompts into 20 curriculum levels, yet provides no details on how difficulty levels were validated, how examples were generated, or whether the validation programs were manually inspected for correctness. This information is required to support the claim that the curriculum progressively increases in relational, arithmetic, and recursive complexity.
minor comments (1)
- [Abstract] The cost figure of exceeding $300 for 1,000 prompts would be clearer with an explicit breakdown of the components included in the calculation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions that will be incorporated to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental results: The central claim that curriculum learning doubles Llama-3-8B accuracy on SLR-Bench (and reaches parity with Gemini-Flash-Thinking) depends on the auto-generated validation programs supplying a faithful binary reward signal that passes only when the model's output rule exactly matches the latent ground-truth rule. No sample audit, formal verification, error bounds, or comparison against human-written oracles is reported to quantify false-positive or false-negative rates in the checkers. Any systematic bias in these programs would distort the reward signal and artifactually inflate the curriculum gains.
Authors: We agree that a quantitative assessment of the validation programs' reliability is essential to support the reported gains. The programs are synthesized directly from the latent ground-truth rule and task specification, so that the checker executes the model's output rule on held-out inputs and verifies behavioral equivalence. While the submitted manuscript did not include an explicit audit or error bounds, we will add a new subsection that reports the results of a manual audit performed on a random sample of 200 validation programs (with inter-annotator agreement), together with the observed false-positive and false-negative rates and the formal verification steps used during synthesis. These additions will bound any potential bias in the reward signal and clarify that the curriculum improvements are not artifacts of checker errors. revision: yes
-
Referee: [SLR-Bench construction] SLR-Bench construction: The abstract states that SLR offers precise control over task difficulty and organizes prompts into 20 curriculum levels, yet provides no details on how difficulty levels were validated, how examples were generated, or whether the validation programs were manually inspected for correctness. This information is required to support the claim that the curriculum progressively increases in relational, arithmetic, and recursive complexity.
Authors: We concur that explicit documentation of the difficulty-control mechanism and validation steps is required. Task difficulty is modulated by parameters in the specification that govern the number and arity of relations, the depth of arithmetic expressions, and the recursion limit. Prompts and validation programs are generated programmatically from these parameters. In the revised manuscript we will expand the SLR-Bench construction section with (i) the precise parameter ranges used for each of the 20 levels, (ii) the procedure used to confirm monotonic increase in complexity (including both syntactic metrics and pilot human difficulty ratings), and (iii) confirmation that a development subset of validation programs received manual inspection for correctness before the full benchmark was generated. revision: yes
Circularity Check
No circularity: empirical performance claims on synthesized benchmark
full rationale
The paper describes an automated end-to-end synthesis pipeline for logical reasoning tasks and reports direct empirical measurements of LLM accuracy on the resulting SLR-Bench under curriculum learning. No mathematical derivations, equations, fitted parameters, or self-citations that reduce the central claims to internal definitions are present. The reported gains (doubling Llama-3-8B accuracy and parity with Gemini-Flash-Thinking) are measured outcomes on externally generated prompts rather than quantities forced by construction from the synthesis process itself. The evaluation is therefore self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Executable programs can be synthesized that correctly validate whether a model's output rule matches the latent ground-truth rule for every example.
invented entities (1)
-
SLR synthesis pipeline
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SLR automatically synthesizes (i) an instruction prompt... (ii) a validation program... (iii) the latent ground-truth rule... Using SLR, we create SLR-Bench, a benchmark comprising 19k prompts organized into 20 curriculum levels
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The SYMBOLIC JUDGE... checks whether all positive examples (E+) are entailed and all negative examples (E−) are not entailed
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
ActivationReasoning: Logical Reasoning in Latent Activation Spaces
ActivationReasoning grounds logical reasoning in LLM latent activations via SAEs to enable structured inference, concept composition, and behavior steering on multi-hop, abstraction, and safety tasks.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning. Preprint, arXiv:2501.12948. Quentin Delfosse, Jannis Blüml, Fabian Tatai, Théo Vincent, Bjarne Gregori, Elisabeth Dillies, Jan Pe- ters, Constantin Rothkopf, and Kristian Kersting
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Deep reinforcement learning agents are not even close to human intelligence. Preprint, arXiv:2505.21731. Siqi Fan, Peng Han, Shuo Shang, Yequan Wang, and Aixin Sun. 2025. Cothink: Token-efficient reason- ing via instruct models guiding reasoning models. Preprint, arXiv:2505.22017. Clémentine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Szafer, and Tho...
-
[3]
Wildbench: Benchmarking llms with chal- lenging tasks from real users in the wild. Preprint, arXiv:2406.04770. Hanmeng Liu, Jian Liu, Leyang Cui, Zhiyang Teng, Nan Duan, Ming Zhou, and Yue Zhang. 2023. Logiqa 2.0—an improved dataset for logical reasoning in natural language understanding. IEEE/ACM Trans- actions on Audio, Speech, and Language Processing, ...
-
[4]
Llamafactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 3: System Demonstra- tions), Bangkok, Thailand. Association for Computa- tional Linguistics. Yujun Zhou, Jiayi Ye, Zipeng Ling, Yufei Han, Yue Huang, Haomin Zhuang, Zhenwen Liang, Kehan G...
-
[5]
1 eastbound(Train) :- 2 has_car(Train, Car), 3 car_color(Car, red), 4 car_len(Car, short)
Conjunction with Existential Quantification: There exists a red short car There is at least one car that is both short and red. 1 eastbound(Train) :- 2 has_car(Train, Car), 3 car_color(Car, red), 4 car_len(Car, short)
-
[6]
At least one car is either white or yellow
Disjunction: Some car is white or yellow. At least one car is either white or yellow. 1 eastbound(Train) :- 2 has_car(Train, Car), 3 (car_color(Car, white) ; car_color( Car, yellow))
-
[7]
1 eastbound(Train) :- 2 \+ (has_car(Train, Car), car_color( Car, red))
Negation: The train does not contain any red cars No car on the train is red. 1 eastbound(Train) :- 2 \+ (has_car(Train, Car), car_color( Car, red))
-
[8]
Inequality/Distinctness: Two cars must have different colors There are at least two cars on the train with different colors. 1 eastbound(Train) :- 2 has_car(Train, CarA), 3 has_car(Train, CarB), 4 CarA \= CarB, 5 car_color(CarA, Color1), 6 car_color(CarB, Color2), 7 Color1 \= Color2
-
[9]
Aggregation/Counting: There are more green cars than yellow cars The train contains more green cars than yellow cars. 1 eastbound(Train) :- 2 findall(Car, (has_car(Train, Car), car_color(Car, green)), Greens), 3 findall(Car, (has_car(Train, Car), car_color(Car, yellow)), Yellows), 4 length(Greens, G), 5 length(Yellows, Y), 6 G > Y. 15 Table 5: Model Prici...
work page 2025
-
[10]
Mutual Exclusion: Only one car is yellow; all others are not yellow There is exactly one yellow car; all others are not yellow. 1 eastbound(Train) :- 2 findall(Car, (has_car(Train, Car), car_color(Car, yellow)), [YellowCar ]), 3 forall( 4 (has_car(Train, Car), Car \= YellowCar), 5 (car_color(Car, NotYellow), 6 NotYellow \= yellow) 7 )
-
[11]
Uniqueness: No two cars have the same color All cars have unique colors. 1 eastbound(Train) :- 2 findall(Color, (has_car(Train, Car), car_color(Car, Color)), Colors), 3 sort(Colors, UniqueColors), 4 length(Colors, N), 5 length(UniqueColors, N)
-
[12]
1 eastbound(Train) :- 2 findall(Car, has_car(Train, Car), Cars), 3 length(Cars, 2)
No-Other/Uniqueness: Only two cars in the train Only two cars are present in the train. 1 eastbound(Train) :- 2 findall(Car, has_car(Train, Car), Cars), 3 length(Cars, 2)
-
[13]
Universal Quantification: Every full-wall car is long All cars with a full wall must be long. 1 eastbound(Train) :- 2 forall( 3 (has_car(Train, Car), has_wall( Car, full)), 4 car_len(Car, long) 5 )
-
[14]
Conditional Implication: All long cars are either red or blue Every long car is either red or blue. 1 eastbound(Train) :- 2 forall( 16 3 (has_car(Train, Car), car_len( Car, long)), 4 (car_color(Car, Color), (Color = red ; Color = blue)) 5 )
-
[15]
Conditional Aggregation: All long cars are either red or blue Every long car is either red or blue. 1 eastbound(Train) :- 2 forall( 3 (has_car(Train, Car), car_len( Car, long)), 4 (car_color(Car, Color), (Color = red ; Color = blue)) 5 )
-
[16]
Pattern Matching: All full-wall cars are white Every full-wall car is white. 1 eastbound(Train) :- 2 forall( 3 (has_car(Train, Car), has_wall(Car , full)), 4 car_color(Car, white) 5 )
-
[17]
Symmetry: Two cars are neighbors with same color CarA and CarB are neighbors on the train and have the same color. 1 eastbound(Train) :- 2 has_car(Train, CarA), 3 has_car(Train, CarB), 4 CarA \= CarB, 5 car_num(CarA, N1), 6 car_num(CarB, N2), 7 (N2 =:= N1 + 1 ; N2 =:= N1 - 1), 8 car_color(CarA, Color), 9 car_color(CarB, Color)
-
[18]
Combinatorial Group: Exactly two short yellow cars There are exactly two yellow cars, and both are short. 1 eastbound(Train) :- 2 findall(Car, (has_car(Train, Car), car_color(Car, yellow), car_len(Car, short)), L), 3 length(L, 2)
-
[19]
1 eastbound([Car|Cars]) :- 2 car_len(Car, long) 3 ; 4 eastbound(Cars)
Recursion: At least one long car in the train The train has at least one long car. 1 eastbound([Car|Cars]) :- 2 car_len(Car, long) 3 ; 4 eastbound(Cars)
-
[20]
Existence of a Structure (Sublist Pattern Matching) Exists three cars in sequence: Num, Num+1, Num+2, matching pattern. 1 eastbound(Train) :- 2 has_car(Train, Car1), car_num(Car1, N), 3 car_len(Car1, short), 4 N2 is N+1, N3 is N+2, 5 has_car(Train, Car2), car_num(Car2, N2), car_len(Car2, long), 6 has_car(Train, Car3), car_num(Car3, N3), car_len(Car3, short)
-
[21]
Min/Max and Extremal Values A short car followed by a long car followed by a short car, anywhere in the train. 1 eastbound(Train) :- 2 findall(N, (has_car(Train, Car), car_num(Car, N)), Numbers), 3 max_list(Numbers, Max), 4 has_car(Train, LastCar), 5 car_num(LastCar, Max), 6 car_color(LastCar, white)
-
[22]
Subset/Superset Constraints All full-wall cars are among the first three cars. 1 eastbound(Train) :- 2 forall( 3 (has_car(Train, Car), has_wall(Car , full)), 4 (car_num(Car, N), N =< 3) 5 )
-
[23]
Projection/Aggregation Over Multiple Properties All pairs of cars have different (color, length) tu- ples. 1 eastbound(Train) :- 2 has_car(Train, CarA), has_car(Train, CarB), CarA \= CarB, 3 car_color(CarA, ColA), car_len(CarA, LenA), 4 car_color(CarB, ColB), car_len(CarB, LenB), 5 (ColA \= ColB ; LenA \= LenB)
-
[24]
All-Different on Multiple Attributes Enforce all car colors are different, AND all car numbers are different (car numbers are unique by assumption, but see structure). 1 eastbound(Train) :- 2 findall(Color, (has_car(Train, Car), car_color(Car, Color)), Colors), 3 sort(Colors, UniqueColors), 4 length(Colors, N), length( UniqueColors, N). 17 F First-Order L...
work page 2024
-
[25]
Rule Synthesis: The RULE GENERATOR produces a latent ground-truth rule R⋆: is_red_train(T) :- has_car(T, C), car_color(C, red)
-
[26]
car_color(c1, red).‘ • Assign Label: Query q1 = is_red_train(t1)
Background Synthesis (Loop): Iteration 1 (finds a positive example): • Sample Background (b1): ‘has_car(t1, c1). car_color(c1, red).‘ • Assign Label: Query q1 = is_red_train(t1). Entailment b1 ∪ R⋆ |= q1 holds. Result: (1, q1). • Accept/Reject: |E+| < κpos, sample is accepted. B ← b1, E+ ← {q1}. Iteration 2 (finds a negative example): • Sample Background ...
-
[27]
Latent Ground-Truth Rule (R⋆): is_red_train(T) :- has_car(T, C), car_color(C, red)
-
[28]
Validation Program (B, E +, E−): has_car(t1, c1). car_color(c1, red). has_car(t2, c2). car_color(c2, blue). is_red_train(t1)
-
[29]
Instruction Prompt (example formats): (a) Prolog-style Prompt: % Given the following background knowledge: has_car(t1, c1). car_color(c1, red). has_car(t2, c2). car_color(c2, blue). is_red_train(t1). % Your task is to find a rule "is_red_train(T) :-" that solves the bk. (b) Natural Language Prompt: % Given the following background knowledge: Train t1 has ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.