StableSketcher: Enhancing Diffusion Model for Pixel-based Sketch Generation via Visual Question Answering Feedback
Pith reviewed 2026-05-18 05:23 UTC · model grok-4.3
The pith
StableSketcher fine-tunes diffusion models with a VQA reward to generate sketches that match text prompts more closely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
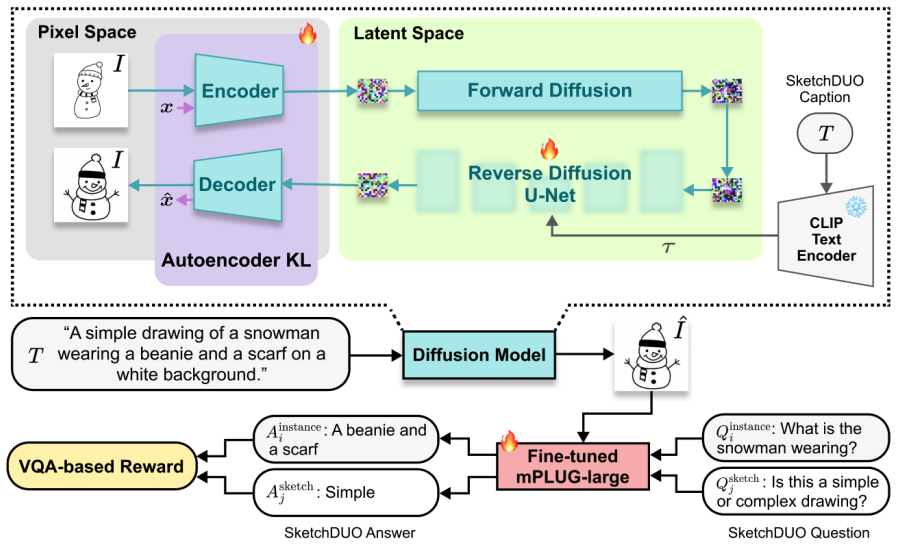
StableSketcher fine-tunes the variational autoencoder to optimize latent decoding for sketches and integrates a new reward function for reinforcement learning based on visual question answering, which improves text-image alignment and semantic consistency. Extensive experiments show that the resulting sketches achieve improved stylistic fidelity and better alignment with prompts than the Stable Diffusion baseline.
What carries the argument
The VQA-derived reward signal used inside reinforcement learning together with the fine-tuned variational autoencoder that improves sketch latent decoding.
If this is right
- Sketches generated by the method exhibit higher prompt fidelity than those from the unmodified Stable Diffusion pipeline.
- Text-image semantic consistency improves measurably through the closed-loop VQA feedback.
- The released SketchDUO dataset removes the prior reliance on image-label pairs and supplies paired captions plus QA data for sketch-specific training.
Where Pith is reading between the lines
- The same VQA reward approach could transfer to other sparse or abstract generation tasks such as icon or diagram synthesis.
- If the feedback loop proves robust, it may lessen dependence on large-scale human preference data for creative image models.
- Interactive versions could let users supply additional questions during generation to refine stylistic choices on the fly.
Load-bearing premise
The visual question answering model supplies an unbiased, reliable signal about semantic consistency and stylistic quality without injecting its own biases or hallucinations that could misdirect the diffusion process.
What would settle it
If side-by-side human ratings or independent alignment metrics show no measurable gain in sketch fidelity or prompt match over the plain Stable Diffusion baseline, the central claim would not hold.
Figures













read the original abstract
Although recent advancements in diffusion models have significantly enriched the quality of generated images, challenges remain in synthesizing pixel-based human-drawn sketches, a representative example of abstract expression. To combat these challenges, we propose StableSketcher, a novel framework that empowers diffusion models to generate hand-drawn sketches with high prompt fidelity. Within this framework, we fine-tune the variational autoencoder to optimize latent decoding, enabling it to better capture the characteristics of sketches. In parallel, we integrate a new reward function for reinforcement learning based on visual question answering, which improves text-image alignment and semantic consistency. Extensive experiments demonstrate that StableSketcher generates sketches with improved stylistic fidelity, achieving better alignment with prompts compared to the Stable Diffusion baseline. Additionally, we introduce SketchDUO, to the best of our knowledge, the first dataset comprising instance-level sketches paired with captions and question-answer pairs, thereby addressing the limitations of existing datasets that rely on image-label pairs. Our code and dataset will be made publicly available upon acceptance. Project page: https://zihos.github.io/StableSketcher
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes StableSketcher, a framework that fine-tunes the VAE component of a diffusion model to better capture sketch characteristics and introduces a VQA-based reward function within a reinforcement learning stage to improve text-to-sketch alignment and semantic consistency. It also releases the SketchDUO dataset pairing instance-level sketches with captions and QA pairs. Experiments claim superior prompt fidelity and stylistic quality relative to a Stable Diffusion baseline.
Significance. If the VQA reward reliably measures semantic and stylistic properties of sketches without domain-shift artifacts, the approach would provide a practical route to higher-fidelity pixel-based sketch generation and a useful new benchmark dataset for the community.
major comments (2)
- [§3.2] §3.2 (Reward Function): The manuscript does not report a calibration experiment measuring VQA accuracy on sketch inputs against human annotations. Because standard VQA models are pretrained on natural-image corpora, questions about object identity or spatial relations may produce systematic hallucinations on sparse line drawings; without this check the observed gains over the baseline could arise from reward hacking rather than genuine semantic improvement.
- [§4] §4 (Experiments): The paper asserts better prompt alignment but provides neither the exact set of VQA questions used in the reward nor statistical significance tests (e.g., p-values or confidence intervals) across multiple random seeds. These omissions make it impossible to assess whether the reported improvements are robust or merely high-level assertions.
minor comments (2)
- [Eq. 3] The description of the VAE fine-tuning objective (Eq. 3) could explicitly state the loss weighting between reconstruction and KL terms to allow exact reproduction.
- [Figure 3] Figure 3 caption should clarify whether the shown sketches are generated with the same random seed and prompt as the baseline for fair visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We appreciate the opportunity to address the concerns regarding the VQA reward calibration and experimental reporting. We outline our responses below and commit to revisions that will strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Reward Function): The manuscript does not report a calibration experiment measuring VQA accuracy on sketch inputs against human annotations. Because standard VQA models are pretrained on natural-image corpora, questions about object identity or spatial relations may produce systematic hallucinations on sparse line drawings; without this check the observed gains over the baseline could arise from reward hacking rather than genuine semantic improvement.
Authors: We agree that a dedicated calibration study is important to rule out domain-shift issues and potential reward hacking. In the revised manuscript we will add a new subsection reporting VQA accuracy on a held-out set of sketches against human annotations collected for the same questions. This will include quantitative agreement metrics and qualitative examples of any observed hallucinations, allowing readers to assess the reliability of the reward signal. revision: yes
-
Referee: [§4] §4 (Experiments): The paper asserts better prompt alignment but provides neither the exact set of VQA questions used in the reward nor statistical significance tests (e.g., p-values or confidence intervals) across multiple random seeds. These omissions make it impossible to assess whether the reported improvements are robust or merely high-level assertions.
Authors: We acknowledge these omissions limit the ability to evaluate robustness. We will release the complete list of VQA questions and prompts used for the reward in the supplementary material. In addition, we will rerun the main quantitative comparisons across at least three random seeds and report means with standard deviations; where appropriate we will also include p-values from paired statistical tests to demonstrate that the observed gains are statistically significant. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's claimed improvements rest on two independent additions: fine-tuning the VAE decoder to better capture sketch characteristics and defining an RL reward from outputs of an external VQA model, together with the release of the new SketchDUO dataset containing instance-level sketches, captions, and QA pairs. Neither step reduces to a self-definition, a fitted parameter renamed as a prediction, or a load-bearing self-citation; the VQA reward is computed from a separate pretrained model rather than from the target alignment metric itself, and all reported gains are measured against an external Stable Diffusion baseline. The derivation is therefore self-contained and does not collapse to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- VAE fine-tuning learning rate and epochs
- VQA reward weighting coefficient
axioms (1)
- domain assumption VQA model outputs provide a faithful proxy for prompt fidelity and semantic consistency in sketches
Reference graph
Works this paper leans on
-
[1]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforce- ment learning.arXiv preprint arXiv:2305.13301, 2023. 3, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedan- tam, Saurabh Gupta, Piotr Doll ´ar, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[3]
Pinaki Nath Chowdhury, Ayan Kumar Bhunia, Aneeshan Sain, Subhadeep Koley, Tao Xiang, and Yi-Zhe Song. What can human sketches do for object detection? InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15083–15094, 2023. 1
work page 2023
-
[4]
How do humans sketch objects?ACM Trans
Mathias Eitz, James Hays, and Marc Alexa. How do humans sketch objects?ACM Trans. Graph. (Proc. SIGGRAPH), 31 (4):44:1–44:10, 2012. 2, 3
work page 2012
-
[5]
A neural representation of sketch drawings
David Ha and Douglas Eck. A neural representation of sketch drawings. InInternational Conference on Learning Representations, 2018. 2, 3 12
work page 2018
-
[6]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning.arXiv preprint arXiv:2104.08718,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 8
work page 2017
-
[8]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 5, 7
work page 2020
-
[9]
Scale- adaptive diffusion model for complex sketch synthesis
Jijin Hu, Ke Li, Yonggang Qi, and Yi-Zhe Song. Scale- adaptive diffusion model for complex sketch synthesis. In The Twelfth International Conference on Learning Represen- tations, 2024. 2
work page 2024
-
[10]
Tifa: Accu- rate and interpretable text-to-image faithfulness evaluation with question answering
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accu- rate and interpretable text-to-image faithfulness evaluation with question answering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20406– 20417, 2023. 3, 5, 7, 8
work page 2023
-
[11]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabhar- wal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. Unifiedqa: Crossing format boundaries with a single qa sys- tem.arXiv preprint arXiv:2005.00700, 2020. 5
-
[13]
Auto-Encoding Variational Bayes
Diederik P Kingma. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013. 7
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
You’ll never walk alone: A sketch and text duet for fine- grained image retrieval
Subhadeep Koley, Ayan Kumar Bhunia, Aneeshan Sain, Pinaki Nath Chowdhury, Tao Xiang, and Yi-Zhe Song. You’ll never walk alone: A sketch and text duet for fine- grained image retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16509–16519, 2024. 1
work page 2024
-
[15]
It’s all about your sketch: Democratising sketch control in diffusion models
Subhadeep Koley, Ayan Kumar Bhunia, Deeptanshu Sekhri, Aneeshan Sain, Pinaki Nath Chowdhury, Tao Xiang, and Yi- Zhe Song. It’s all about your sketch: Democratising sketch control in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7204–7214, 2024. 2
work page 2024
-
[16]
Aligning Text-to-Image Models using Human Feedback
Sohee Lee, Zijian Liu, Kimin Sohn, Luyu Zhang, Jun Jia, Barret Zoph, Quoc Le, Mohammad Norouzi, and Alexan- der Kolesnikov. Aligning text-to-image models using human feedback.arXiv preprint arXiv:2302.12192, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Chenliang Li, Haiyang Xu, Junfeng Tian, Wei Wang, Ming Yan, Bin Bi, Jiabo Ye, Hehong Chen, Guohai Xu, Zheng Cao, et al. mplug: Effective and efficient vision-language learning by cross-modal skip-connections.arXiv preprint arXiv:2205.12005, 2022. 5, 8
-
[18]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 5
work page 2023
-
[19]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024. 7
work page 2024
-
[20]
Sketchffusion: Sketch-guided image editing with diffusion model
Weihang Mao, Bo Han, and Zihao Wang. Sketchffusion: Sketch-guided image editing with diffusion model. In2023 IEEE International Conference on Image Processing (ICIP), pages 790–794. IEEE, 2023. 1
work page 2023
-
[21]
Kushin Mukherjee, Holly Huey, Xuanchen Lu, Yael Vinker, Rio Aguina-Kang, Ariel Shamir, and Judith Fan. Seva: Leveraging sketches to evaluate alignment between human and machine visual abstraction.Advances in Neural Infor- mation Processing Systems, 36, 2024. 2
work page 2024
-
[22]
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazeb- nik. Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models. InPro- ceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015. 2
work page 2015
-
[23]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 5, 7, 8, 11
work page 2022
-
[24]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, Seyedeh Sara Mahdavi, Raphael Gontijo Lopes, et al. Photorealistic text-to-image diffusion models with deep language understanding.arXiv preprint arXiv:2205.11487, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Clip for all things zero-shot sketch-based image retrieval, fine- grained or not
Aneeshan Sain, Ayan Kumar Bhunia, Pinaki Nath Chowd- hury, Subhadeep Koley, Tao Xiang, and Yi-Zhe Song. Clip for all things zero-shot sketch-based image retrieval, fine- grained or not. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2765– 2775, 2023. 1
work page 2023
-
[26]
Generating images of rare concepts using pre- trained diffusion models
Dvir Samuel, Rami Ben-Ari, Simon Raviv, Nir Darshan, and Gal Chechik. Generating images of rare concepts using pre- trained diffusion models. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 4695–4703, 2024. 2
work page 2024
-
[27]
Patsorn Sangkloy, Nathan Burnell, Cusuh Ham, and James Hays. The sketchy database: learning to retrieve badly drawn bunnies.ACM Transactions on Graphics (TOG), 35(4):1–12,
-
[28]
Nakul Sharma, Aditay Tripathi, Anirban Chakraborty, and Anand Mishra. Sketch-guided image inpainting with partial discrete diffusion process.arXiv preprint arXiv:2404.11949,
-
[29]
Richard S Sutton and Andrew G Barto.Reinforcement Learning: An Introduction. MIT Press, 2018. 6
work page 2018
-
[30]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Yael Vinker, Ehsan Pajouheshgar, Jessica Y Bo, Ro- man Christian Bachmann, Amit Haim Bermano, Daniel Cohen-Or, Amir Zamir, and Ariel Shamir. Clipasso: 13 Semantically-aware object sketching.ACM Transactions on Graphics (TOG), 41(4):1–11, 2022. 2
work page 2022
-
[32]
Sketch-guided text-to-image diffusion models
Andrey V oynov, Kfir Aberman, and Daniel Cohen-Or. Sketch-guided text-to-image diffusion models. InACM SIG- GRAPH 2023 Conference Proceedings, pages 1–11, 2023. 1
work page 2023
-
[33]
Qiang Wang, Di Kong, Fengyin Lin, and Yonggang Qi. Diffsketching: Sketch control image synthesis with diffusion models.arXiv preprint arXiv:2305.18812, 2023. 2
-
[34]
Peng Xu, Timothy M Hospedales, Qiyue Yin, Yi-Zhe Song, Tao Xiang, and Liang Wang. Deep learning for free-hand sketch: A survey.IEEE transactions on pattern analysis and machine intelligence, 45(1):285–312, 2022. 1
work page 2022
-
[35]
Draw2edit: Mask-free sketch-guided image manipulation
Yiwen Xu, Ruoyu Guo, Maurice Pagnucco, and Yang Song. Draw2edit: Mask-free sketch-guided image manipulation. In Proceedings of the 31st ACM International Conference on Multimedia, pages 7205–7215, 2023. 1
work page 2023
-
[36]
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.arXiv preprint arXiv:2408.04840, 2024. 5
work page internal anchor Pith review arXiv 2024
-
[37]
Diffu- sion models need visual priors for image generation.arXiv preprint arXiv:2410.08531, 2024
Xiaoyu Yue, Zidong Wang, Zeyu Lu, Shuyang Sun, Meng Wei, Wanli Ouyang, Lei Bai, and Luping Zhou. Diffu- sion models need visual priors for image generation.arXiv preprint arXiv:2410.08531, 2024. 2
-
[38]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 7, 8
work page 2018
-
[39]
Sketch-guided text-to-image generation with spatial control
Tianyu Zhang and Haoran Xie. Sketch-guided text-to-image generation with spatial control. In2024 2nd International Conference on Computer Graphics and Image Processing (CGIP), pages 153–159. IEEE, 2024. 1
work page 2024
-
[40]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Wein- berger, and Yoav Artzi. Bertscore: Evaluating text genera- tion with bert.arXiv preprint arXiv:1904.09675, 2019. 3, 7, 8 14 Appendix: Qualitative Evaluation Results Figure 12. Qualitative comparison of images generated by different models based on the input text prompts. “Ours” denotes results from th...
work page internal anchor Pith review Pith/arXiv arXiv 1904
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.