Sentra-Guard: A Real-Time Multilingual Defense Against Adversarial LLM Prompts
Pith reviewed 2026-05-18 04:18 UTC · model grok-4.3
The pith
Sentra-Guard detects adversarial LLM prompts with 99.96 percent accuracy across more than 100 languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
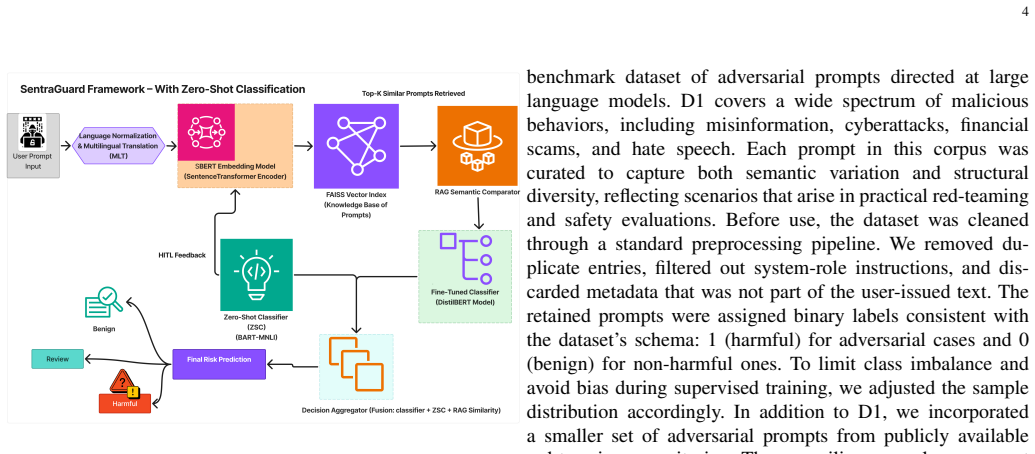
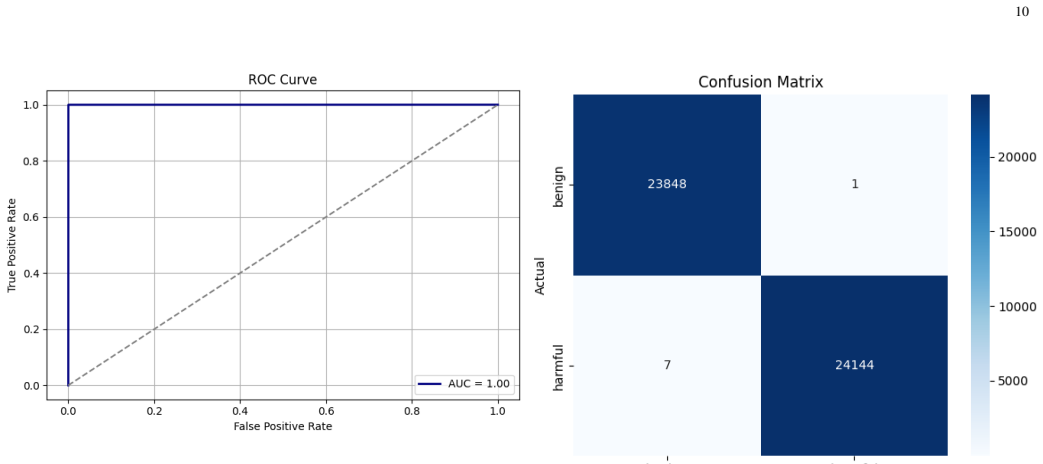
Sentra-Guard identifies adversarial prompts in both direct and obfuscated forms through a hybrid architecture that pairs FAISS-indexed SBERT embedding representations with fine-tuned transformer classifiers. Its classifier-retriever fusion module dynamically computes context-aware risk scores, and a language-agnostic preprocessing layer translates non-English inputs into English to enable detection across over 100 languages. A HITL feedback loop maintains an evolving dual-labeled knowledge base of benign and malicious prompts, yielding a 99.96 percent detection rate with AUC and F1 scores of 1.00 and an attack success rate of only 0.004 percent that outperforms baselines such as LlamaGuard-2
What carries the argument
The classifier-retriever fusion module, which combines semantic embeddings from FAISS-indexed SBERT with fine-tuned transformers to compute context-aware risk scores that flag adversarial intent.
If this is right
- The system supports fine-tuning and integration with diverse commercial and open-source LLM backends.
- Continuous human review reduces false positives while adapting to new attack patterns.
- Multilingual coverage through translation enables consistent protection without separate models per language.
- Modular design allows scalable deployment for real-time use in production environments.
Where Pith is reading between the lines
- Widespread adoption could make such hybrid defense layers a default component in public LLM APIs.
- The approach might generalize to new attack types if the knowledge base grows through ongoing feedback.
- Similar fusion techniques could apply to other AI safety tasks like detecting harmful content generation.
Load-bearing premise
Automatically translating non-English prompts into English preserves the semantic features that signal adversarial intent without distorting or losing attack signals.
What would settle it
Testing the full system on a fresh set of adversarial prompts written in a low-resource language where machine translation often alters subtle intent, then measuring whether detection rate drops below 99 percent.
Figures


read the original abstract
This paper presents a real-time modular defense system named Sentra-Guard. The system detects and mitigates jailbreak and prompt injection attacks targeting large language models (LLMs). The framework uses a hybrid architecture with FAISS-indexed SBERT embedding representations that capture the semantic meaning of prompts, combined with fine-tuned transformer classifiers, which are machine learning models specialized for distinguishing between benign and adversarial language inputs. It identifies adversarial prompts in both direct and obfuscated attack vectors. A core innovation is the classifier-retriever fusion module, which dynamically computes context-aware risk scores that estimate how likely a prompt is to be adversarial based on its content and context. The framework ensures multilingual resilience with a language-agnostic preprocessing layer. This component automatically translates non-English prompts into English for semantic evaluation, enabling consistent detection across over 100 languages. The system includes a HITL feedback loop, where decisions made by the automated system are reviewed by human experts for continual learning and rapid adaptation under adversarial pressure. Sentra-Guard maintains an evolving dual-labeled knowledge base of benign and malicious prompts, enhancing detection reliability and reducing false positives. Evaluation results show a 99.96% detection rate (AUC = 1.00, F1 = 1.00) and an attack success rate (ASR) of only 0.004%. This outperforms leading baselines such as LlamaGuard-2 (1.3%) and OpenAI Moderation (3.7%). Unlike black-box approaches, Sentra-Guard is transparent, fine-tunable, and compatible with diverse LLM backends. Its modular design supports scalable deployment in both commercial and open-source environments. The system establishes a new state-of-the-art in adversarial LLM defense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Sentra-Guard, a real-time modular defense system for detecting and mitigating jailbreak and prompt injection attacks on LLMs. It describes a hybrid architecture combining FAISS-indexed SBERT embeddings with fine-tuned transformer classifiers, a classifier-retriever fusion module for context-aware risk scores, a language-agnostic preprocessing layer that translates non-English prompts to English, an evolving dual-labeled knowledge base, and a HITL feedback loop. The central empirical claim is a 99.96% detection rate (AUC = 1.00, F1 = 1.00) with an attack success rate of 0.004%, outperforming baselines such as LlamaGuard-2 (1.3%) and OpenAI Moderation (3.7%).
Significance. If the performance claims are supported by properly separated evaluation data and rigorous methodology, the work would provide a practical, transparent, and multilingual contribution to LLM adversarial defense. The modular design and emphasis on continual adaptation via HITL and an evolving knowledge base are potentially useful for deployment. However, the near-perfect metrics require strong evidence of generalization to establish significance beyond the specific experimental conditions.
major comments (3)
- Abstract: The reported 99.96% detection rate, AUC = 1.00, F1 = 1.00, and ASR of 0.004% are presented without any information on dataset composition, attack diversity, train-test splits, or statistical significance testing. This omission is load-bearing because the central claim of outperforming baselines cannot be evaluated without these details.
- Classifier-retriever fusion module: The use of FAISS-indexed SBERT embeddings of the dual-labeled knowledge base to compute risk scores does not specify any temporal cutoff, embedding-distance threshold, or exclusion of evaluation prompts from the index. If test adversarial prompts are near-duplicates of indexed entries, the near-zero ASR would be an artifact of retrieval rather than generalization to novel jailbreaks.
- Language-agnostic preprocessing layer: The claim that automatic translation of non-English prompts to English preserves semantic features needed to detect adversarial intent lacks supporting ablation or error analysis. This assumption is load-bearing for the multilingual resilience claim across over 100 languages.
minor comments (2)
- Abstract: The specific ASR values for the baselines (LlamaGuard-2 at 1.3% and OpenAI Moderation at 3.7%) should be explicitly tied to the same evaluation protocol for fair comparison.
- Ensure all acronyms (SBERT, FAISS, HITL, ASR, AUC) are defined on first use and that the manuscript includes a dedicated evaluation section with full experimental details.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. Where revisions are needed to improve clarity or provide additional evidence, we indicate that changes will be made in the revised version.
read point-by-point responses
-
Referee: Abstract: The reported 99.96% detection rate, AUC = 1.00, F1 = 1.00, and ASR of 0.004% are presented without any information on dataset composition, attack diversity, train-test splits, or statistical significance testing. This omission is load-bearing because the central claim of outperforming baselines cannot be evaluated without these details.
Authors: We agree with the referee that the abstract should provide more context on the evaluation methodology to support the performance claims. In the revised version, we will modify the abstract to briefly note the dataset composition (including the mix of English and non-English prompts and attack categories), the use of held-out test sets with no overlap with training data, and the application of cross-validation for assessing statistical significance. This will allow readers to better evaluate the generalizability of the results without needing to refer to the full text immediately. revision: yes
-
Referee: Classifier-retriever fusion module: The use of FAISS-indexed SBERT embeddings of the dual-labeled knowledge base to compute risk scores does not specify any temporal cutoff, embedding-distance threshold, or exclusion of evaluation prompts from the index. If test adversarial prompts are near-duplicates of indexed entries, the near-zero ASR would be an artifact of retrieval rather than generalization to novel jailbreaks.
Authors: We thank the referee for highlighting this potential issue. Upon review, the current manuscript does not explicitly state the temporal cutoff or exclusion criteria. We will revise the description of the classifier-retriever fusion module to include: (1) a temporal cutoff ensuring the knowledge base contains only prompts from before the evaluation period, (2) an embedding-distance threshold for flagging near-duplicates, and (3) explicit exclusion of any evaluation prompts that match indexed entries above the threshold. This revision will demonstrate that the low ASR is due to generalization. revision: yes
-
Referee: Language-agnostic preprocessing layer: The claim that automatic translation of non-English prompts to English preserves semantic features needed to detect adversarial intent lacks supporting ablation or error analysis. This assumption is load-bearing for the multilingual resilience claim across over 100 languages.
Authors: We acknowledge that the manuscript lacks a dedicated ablation study or error analysis for the translation component. To address this, we will add a new subsection in the Experiments section providing an ablation study on the impact of the preprocessing layer, including performance metrics with and without translation for non-English prompts, and an analysis of translation errors and their effect on detection accuracy. This will strengthen the multilingual resilience claim. revision: yes
Circularity Check
No circularity: empirical system description with independent evaluation metrics
full rationale
The paper presents an architectural framework for Sentra-Guard using FAISS-indexed SBERT embeddings, fine-tuned transformers, a classifier-retriever fusion module, and a language-agnostic preprocessing layer, along with reported empirical results such as 99.96% detection rate and AUC=1.00. No equations, derivations, or self-definitional reductions are present in the provided text. The evolving dual-labeled knowledge base is described as an input to the system rather than a fitted output that forces the evaluation metrics. The high performance is framed as an outcome of testing against baselines, with no quoted mechanism showing that test prompts reduce by construction to indexed training entries or that results are renamed fitted parameters. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- risk score threshold
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid architecture with FAISS-indexed SBERT embedding representations... classifier-retriever fusion module... decision fusion aggregator
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multilingual normalization... evolving dual-labeled knowledge base
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Privacy in large language models: Attacks, defenses and future directions,
H. Li, Y . Chen, J. Luo, J. Wang, H. Peng, Y . Kang, X. Zhang, Q. Hu, C. Chan, Z. Xuet al., “Privacy in large language models: Attacks, defenses and future directions,”arXiv preprint arXiv:2310.10383, 2023
-
[2]
Unleashing the potential of prompt engineering for large language models,
B. Chen, Z. Zhang, N. Langren ´e, and S. Zhu, “Unleashing the potential of prompt engineering for large language models,”Patterns, 2025
work page 2025
-
[3]
Jailbreaking and mitigation of vulnerabilities in large language models,
B. Peng, K. Chen, Q. Niu, Z. Bi, M. Liu, P. Feng, T. Wang, L. K. Yan, Y . Wen, Y . Zhanget al., “Jailbreaking and mitigation of vulnerabilities in large language models,”arXiv preprint arXiv:2410.15236, 2024
-
[4]
Attack and defense techniques in large language models: A survey and new perspectives,
Z. Liao, K. Chen, Y . Lin, K. Li, Y . Liu, H. Chen, X. Huang, and Y . Yu, “Attack and defense techniques in large language models: A survey and new perspectives,”arXiv preprint arXiv:2505.00976, 2025
-
[5]
Large language models for cyber security: A systematic literature review,
H. Xu, S. Wang, N. Li, K. Wang, Y . Zhao, K. Chen, T. Yu, Y . Liu, and H. Wang, “Large language models for cyber security: A systematic literature review,”arXiv preprint arXiv:2405.04760, 2024
-
[6]
Jailguard: A universal detection framework for prompt-based attacks on llm systems,
X. Zhang, C. Zhang, T. Li, Y . Huang, X. Jia, M. Hu, J. Zhang, Y . Liu, S. Ma, and C. Shen, “Jailguard: A universal detection framework for prompt-based attacks on llm systems,”ACM Transactions on Software Engineering and Methodology, 2025
work page 2025
-
[7]
A survey on large language models with multilingualism: Recent advances and new frontiers,
K. Huang, F. Mo, X. Zhang, H. Li, Y . Li, Y . Zhang, W. Yi, Y . Mao, J. Liu, Y . Xuet al., “A survey on large language models with multilingualism: Recent advances and new frontiers,”arXiv preprint arXiv:2405.10936, 2024
-
[8]
The many faces of generalization: From traditional machine learning to llm safety,
S. Zhu, “The many faces of generalization: From traditional machine learning to llm safety,” Ph.D. dissertation, University of Maryland, College Park, 2025
work page 2025
-
[9]
Robustness in large language models: A survey of mitigation strategies and evaluation metrics,
P. Kumar and S. Mishra, “Robustness in large language models: A survey of mitigation strategies and evaluation metrics,”arXiv preprint arXiv:2505.18658, 2025
-
[10]
D. Woszczyk and S. Demetriou, “Didots: Knowledge distillation from large-language-models for dementia obfuscation in transcribed speech,” arXiv preprint arXiv:2410.04188, 2024
-
[11]
Adversarial prompt transformation for systematic jailbreaks of llms,
K. E. Awoufack, “Adversarial prompt transformation for systematic jailbreaks of llms,” Ph.D. dissertation, Massachusetts Institute of Tech- nology, 2024
work page 2024
-
[12]
E. Shayegani, M. A. A. Mamun, Y . Fu, P. Zaree, Y . Dong, and N. Abu- Ghazaleh, “Survey of vulnerabilities in large language models revealed by adversarial attacks,”arXiv preprint arXiv:2310.10844, 2023
-
[13]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
J. Luo, W. Zhang, Y . Yuan, Y . Zhao, J. Yang, Y . Gu, B. Wu, B. Chen, Z. Qiao, Q. Longet al., “Large language model agent: A survey on methodology, applications and challenges,”arXiv preprint arXiv:2503.21460, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
A state-of- the-art review on phishing website detection techniques,
W. Li, S. Manickam, Y .-W. Chong, W. Leng, and P. Nanda, “A state-of- the-art review on phishing website detection techniques,”IEEE Access, 2024
work page 2024
-
[15]
The role of transformer models in advancing blockchain technology: A systematic survey,
T. Liu, Y . Wang, J. Sun, Y . Tian, Y . Huang, T. Xue, P. Li, and Y . Liu, “The role of transformer models in advancing blockchain technology: A systematic survey,”arXiv preprint arXiv:2409.02139, 2024
-
[16]
J. P. Musial and J. S. Bojanowski, “Comparison of the novel probabilistic self-optimizing vectorized earth observation retrieval classifier with common machine learning algorithms,”Remote Sensing, vol. 14, no. 2, p. 378, 2022
work page 2022
-
[17]
F. Askari, A. Fateh, and M. R. Mohammadi, “Enhancing few-shot image classification through learnable multi-scale embedding and attention mechanisms,”Neural Networks, vol. 187, p. 107339, 2025
work page 2025
-
[18]
Retrieval-Augmented Generation with Graphs (GraphRAG)
H. Han, Y . Wang, H. Shomer, K. Guo, J. Ding, Y . Lei, M. Halappanavar, R. A. Rossi, S. Mukherjee, X. Tanget al., “Retrieval-augmented generation with graphs (graphrag),”arXiv preprint arXiv:2501.00309, 2024
work page internal anchor Pith review arXiv 2024
-
[19]
Autodefense: Multi-agent llm defense against jailbreak attacks,
Y . Zeng, Y . Wu, X. Zhang, H. Wang, and Q. Wu, “Autodefense: Multi-agent llm defense against jailbreak attacks,”arXiv preprint arXiv:2403.04783, 2024
-
[20]
Towards Measuring the Representation of Subjective Global Opinions in Language Models
E. Durmus, K. Nguyen, T. I. Liao, N. Schiefer, A. Askell, A. Bakhtin, C. Chen, Z. Hatfield-Dodds, D. Hernandez, N. Josephet al., “Towards measuring the representation of subjective global opinions in language models,”arXiv preprint arXiv:2306.16388, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testuggineet al., “Llama guard: Llm-based input-output safeguard for human-ai conversations,”arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Algorithms for adversarially robust deep learning,
A. B. Robey, “Algorithms for adversarially robust deep learning,” Ph.D. dissertation, University of Pennsylvania, 2024
work page 2024
-
[23]
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “” do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 1671–1685
work page 2024
-
[24]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
work page 2022
-
[25]
Red teaming contemporary ai models: Insights from spanish and basque perspectives,
M. Romero-Arjona, P. Valle, J. C. Alonso, A. B. S ´anchez, M. Ugarte, A. Cazalilla, V . Cambr´on, J. A. Parejo, A. Arrieta, and S. Segura, “Red teaming contemporary ai models: Insights from spanish and basque perspectives,”arXiv preprint arXiv:2503.10192, 2025
-
[26]
A cross-language investigation into jailbreak attacks in large language models,
J. Li, Y . Liu, C. Liu, L. Shi, X. Ren, Y . Zheng, Y . Liu, and Y . Xue, “A cross-language investigation into jailbreak attacks in large language models,”arXiv preprint arXiv:2401.16765, 2024
-
[27]
Goal-guided generative prompt injection attack on large language models,
C. Zhang, M. Jin, Q. Yu, C. Liu, H. Xue, and X. Jin, “Goal-guided generative prompt injection attack on large language models,” in2024 IEEE International Conference on Data Mining (ICDM). IEEE, 2024, pp. 941–946
work page 2024
-
[28]
from benign import toxic: Jailbreaking the language model via adversarial metaphors,
Y . Yan, S. Sun, Z. Duan, T. Liu, M. Liu, Z. Yin, J. Lei, and Q. Li, “from benign import toxic: Jailbreaking the language model via adversarial metaphors,”arXiv preprint arXiv:2503.00038, 2025
-
[29]
M. Hassanin and N. Moustafa, “A comprehensive overview of large lan- guage models (llms) for cyber defences: Opportunities and directions,” arXiv preprint arXiv:2405.14487, 2024
-
[30]
A comprehensive review of adversarial attacks and defense strategies in deep neural networks,
A. Abomakhelb, K. A. Jalil, A. G. Buja, A. Alhammadi, and A. M. Alenezi, “A comprehensive review of adversarial attacks and defense strategies in deep neural networks,”Technologies, vol. 13, no. 5, p. 202, 2025
work page 2025
-
[31]
A survey on backdoor threats in large language models (llms): Attacks, defenses, and evaluations,
Y . Zhou, T. Ni, W.-B. Lee, and Q. Zhao, “A survey on backdoor threats in large language models (llms): Attacks, defenses, and evaluations,” arXiv preprint arXiv:2502.05224, 2025
-
[32]
H. Jin, L. Hu, X. Li, P. Zhang, C. Chen, J. Zhuang, and H. Wang, “Jailbreakzoo: Survey, landscapes, and horizons in jailbreaking large lan- guage and vision-language models,”arXiv preprint arXiv:2407.01599, 2024
-
[33]
A survey on human-in-the-loop applications towards an internet of all,
D. S. Nunes, P. Zhang, and J. S. Silva, “A survey on human-in-the-loop applications towards an internet of all,”IEEE Communications Surveys & Tutorials, vol. 17, no. 2, pp. 944–965, 2015
work page 2015
-
[34]
Red Teaming Language Models with Language Models
E. Perez, S. Huang, F. Song, T. Cai, R. Ring, J. Aslanides, A. Glaese, N. McAleese, and G. Irving, “Red teaming language models with language models,”arXiv preprint arXiv:2202.03286, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Applications, challenges, and future directions of human-in-the-loop learning,
S. Kumar, S. Datta, V . Singh, D. Datta, S. K. Singh, and R. Sharma, “Applications, challenges, and future directions of human-in-the-loop learning,”IEEE Access, vol. 12, pp. 75 735–75 760, 2024
work page 2024
-
[36]
M. F. A. Sayeedi, M. B. Hossain, M. K. Hassan, S. Afrin, M. M. Sabit, and M. S. Hossain, “Jailbreaktracer: Explainable detection of jailbreaking prompts in llms using synthetic data generation,”IEEE Access, 2025
work page 2025
-
[37]
Llm-sentry: A model-agnostic human-in-the-loop framework for securing large language models,
S. Irtiza, K. A. Akbar, A. Yasmeen, L. Khan, O. Daescu, and B. Thurais- ingham, “Llm-sentry: A model-agnostic human-in-the-loop framework for securing large language models,” in2024 IEEE 6th International Conference on Trust, Privacy and Security in Intelligent Systems, and Applications (TPS-ISA). IEEE, 2024, pp. 245–254
work page 2024
-
[38]
S. Zhang, Y . Zhai, K. Guo, H. Hu, S. Guo, Z. Fang, L. Zhao, C. Shen, C. Wang, and Q. Wang, “Jbshield: Defending large language models from jailbreak attacks through activated concept analysis and manipulation,”arXiv preprint arXiv:2502.07557, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.